 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Classification using Sequence of Pixels
Sep 23, 2022
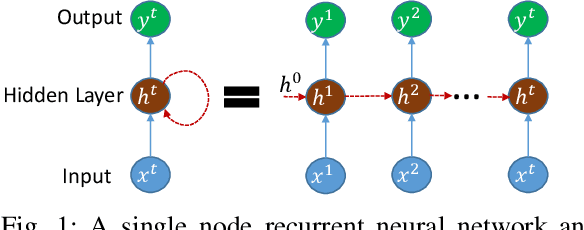
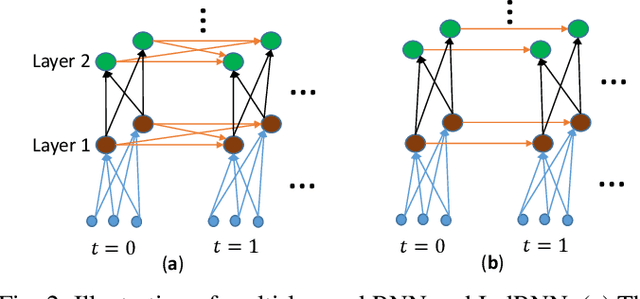
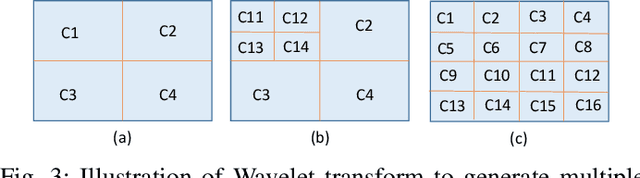

This study compares sequential image classification methods based on recurrent neural networks. We describe methods based on recurrent neural networks such as Long-Short-Term memory(LSTM), bidirectional Long-Short-Term memory(BiLSTM) architectures, etc. We also review the state-of-the-art sequential image classification architectures. We mainly focus on LSTM, BiLSTM, temporal convolution network, and independent recurrent neural network architecture in the study. It is known that RNN lacks in learning long-term dependencies in the input sequence. We use a simple feature construction method using orthogonal Ramanujan periodic transform on the input sequence. Experiments demonstrate that if these features are given to LSTM or BiLSTM networks, the performance increases drastically. Our focus in this study is to increase the training accuracy simultaneously reducing the training time for the LSTM and BiLSTM architecture, but not on pushing the state-of-the-art results, so we use simple LSTM/BiLSTM architecture. We compare sequential input with the constructed feature as input to single layer LSTM and BiLSTM network for MNIST and CIFAR datasets. We observe that sequential input to the LSTM network with 128 hidden unit training for five epochs results in training accuracy of 33% whereas constructed features as input to the same LSTM network results in training accuracy of 90% with 1/3 lesser time.
Generative Diffusions in Augmented Spaces: A Complete Recipe
Mar 03, 2023
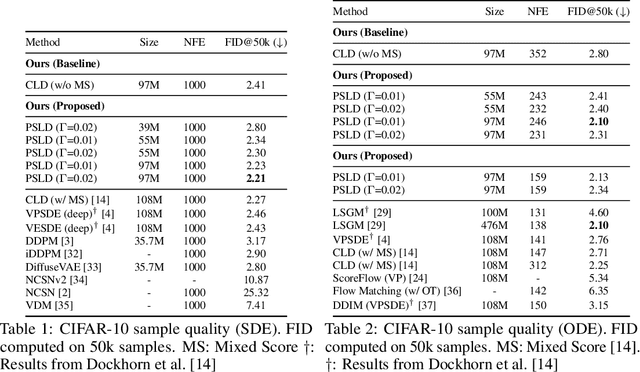

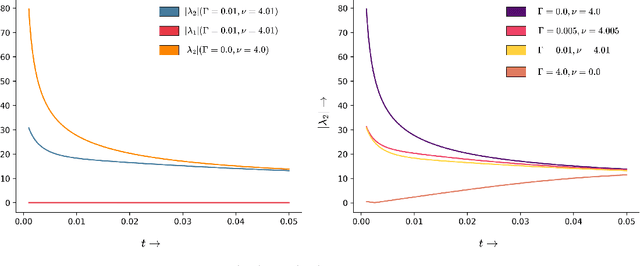
Score-based Generative Models (SGMs) have achieved state-of-the-art synthesis results on diverse tasks. However, the current design space of the forward diffusion process is largely unexplored and often relies on physical intuition or simplifying assumptions. Leveraging results from the design of scalable Bayesian posterior samplers, we present a complete recipe for constructing forward processes in SGMs, all of which are guaranteed to converge to the target distribution of interest. We show that several existing SGMs can be cast as specific instantiations of this parameterization. Furthermore, building on this recipe, we construct a novel SGM: Phase Space Langevin Diffusion (PSLD), which performs score-based modeling in a space augmented with auxiliary variables akin to a physical phase space. We show that PSLD outperforms competing baselines in terms of sample quality and the speed-vs-quality tradeoff across different samplers on various standard image synthesis benchmarks. Moreover, we show that PSLD achieves sample quality comparable to state-of-the-art SGMs (FID: 2.10 on unconditional CIFAR-10 generation), providing an attractive alternative as an SGM backbone for further development. We will publish our code and model checkpoints for reproducibility at https://github.com/mandt-lab/PSLD.
AI-Generated Incentive Mechanism and Full-Duplex Semantic Communications for Information Sharing
Mar 03, 2023
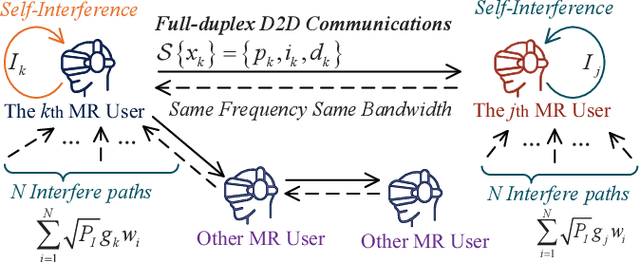

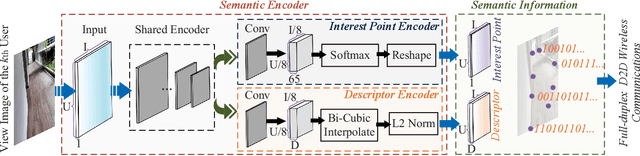
The next generation of Internet services, such as Metaverse, rely on mixed reality (MR) technology to provide immersive user experiences. However, the limited computation power of MR headset-mounted devices (HMDs) hinders the deployment of such services. Therefore, we propose an efficient information sharing scheme based on full-duplex device-to-device (D2D) semantic communications to address this issue. Our approach enables users to avoid heavy and repetitive computational tasks, such as artificial intelligence-generated content (AIGC) in the view images of all MR users. Specifically, a user can transmit the generated content and semantic information extracted from their view image to nearby users, who can then use this information to obtain the spatial matching of computation results under their view images. We analyze the performance of full-duplex D2D communications, including the achievable rate and bit error probability, by using generalized small-scale fading models. To facilitate semantic information sharing among users, we design a contract theoretic AI-generated incentive mechanism. The proposed diffusion model generates the optimal contract design, outperforming two deep reinforcement learning algorithms, i.e., proximal policy optimization and soft actor-critic algorithms. Our numerical analysis experiment proves the effectiveness of our proposed methods.
Spring: A High-Resolution High-Detail Dataset and Benchmark for Scene Flow, Optical Flow and Stereo
Mar 03, 2023
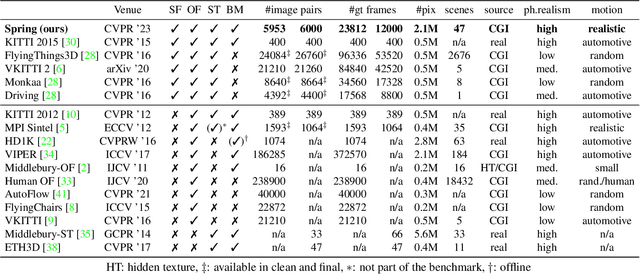

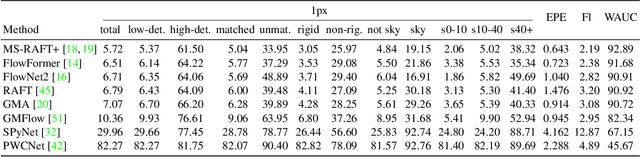
While recent methods for motion and stereo estimation recover an unprecedented amount of details, such highly detailed structures are neither adequately reflected in the data of existing benchmarks nor their evaluation methodology. Hence, we introduce Spring $-$ a large, high-resolution, high-detail, computer-generated benchmark for scene flow, optical flow, and stereo. Based on rendered scenes from the open-source Blender movie "Spring", it provides photo-realistic HD datasets with state-of-the-art visual effects and ground truth training data. Furthermore, we provide a website to upload, analyze and compare results. Using a novel evaluation methodology based on a super-resolved UHD ground truth, our Spring benchmark can assess the quality of fine structures and provides further detailed performance statistics on different image regions. Regarding the number of ground truth frames, Spring is 60$\times$ larger than the only scene flow benchmark, KITTI 2015, and 15$\times$ larger than the well-established MPI Sintel optical flow benchmark. Initial results for recent methods on our benchmark show that estimating fine details is indeed challenging, as their accuracy leaves significant room for improvement. The Spring benchmark and the corresponding datasets are available at http://spring-benchmark.org.
DisCO: Portrait Distortion Correction with Perspective-Aware 3D GANs
Feb 23, 2023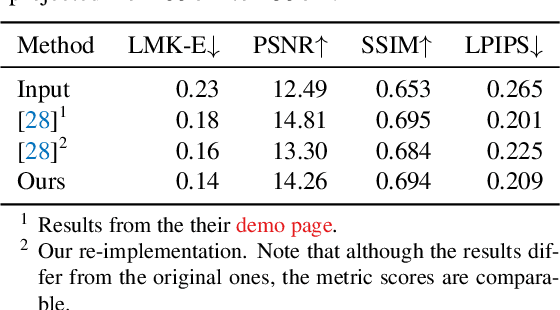

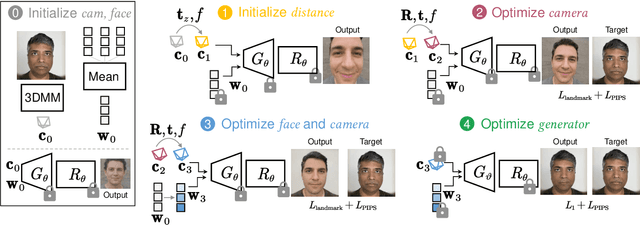
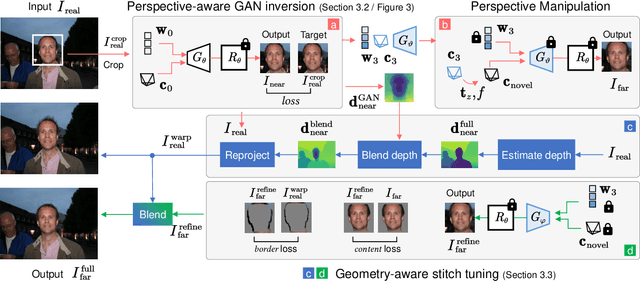
Close-up facial images captured at close distances often suffer from perspective distortion, resulting in exaggerated facial features and unnatural/unattractive appearances. We propose a simple yet effective method for correcting perspective distortions in a single close-up face. We first perform GAN inversion using a perspective-distorted input facial image by jointly optimizing the camera intrinsic/extrinsic parameters and face latent code. To address the ambiguity of joint optimization, we develop focal length reparametrization, optimization scheduling, and geometric regularization. Re-rendering the portrait at a proper focal length and camera distance effectively corrects these distortions and produces more natural-looking results. Our experiments show that our method compares favorably against previous approaches regarding visual quality. We showcase numerous examples validating the applicability of our method on portrait photos in the wild.
Unbiased Multi-Modality Guidance for Image Inpainting
Aug 25, 2022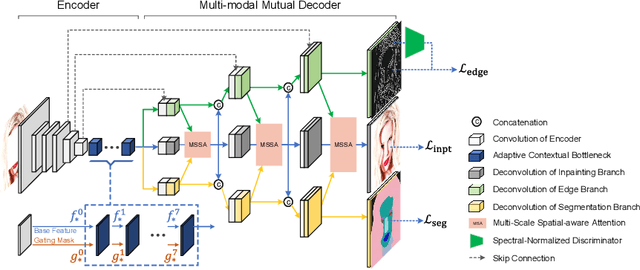
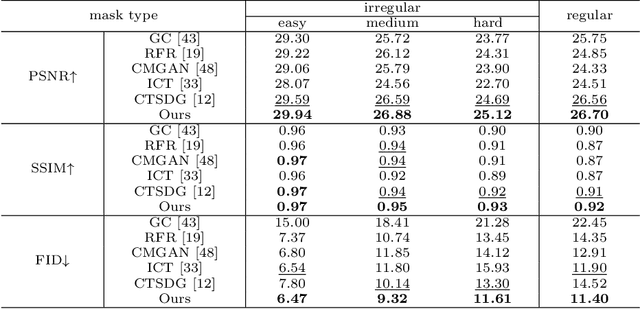
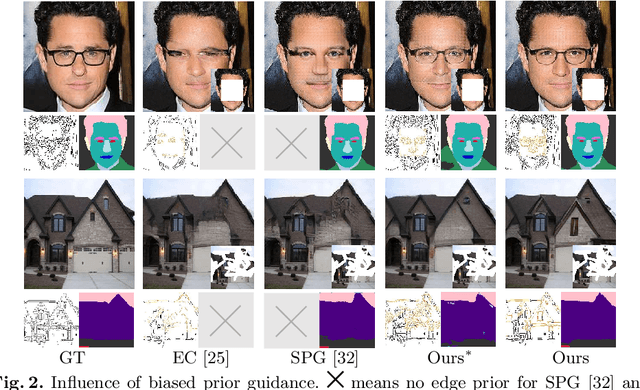
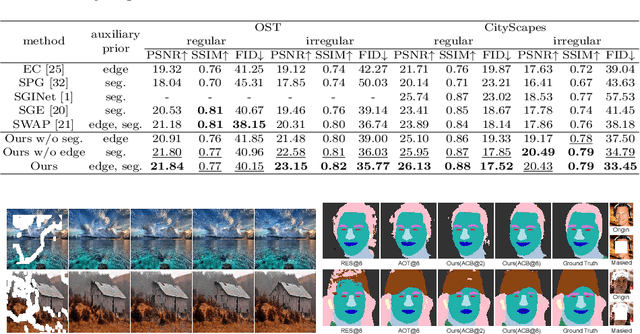
Image inpainting is an ill-posed problem to recover missing or damaged image content based on incomplete images with masks. Previous works usually predict the auxiliary structures (e.g., edges, segmentation and contours) to help fill visually realistic patches in a multi-stage fashion. However, imprecise auxiliary priors may yield biased inpainted results. Besides, it is time-consuming for some methods to be implemented by multiple stages of complex neural networks. To solve this issue, we develop an end-to-end multi-modality guided transformer network, including one inpainting branch and two auxiliary branches for semantic segmentation and edge textures. Within each transformer block, the proposed multi-scale spatial-aware attention module can learn the multi-modal structural features efficiently via auxiliary denormalization. Different from previous methods relying on direct guidance from biased priors, our method enriches semantically consistent context in an image based on discriminative interplay information from multiple modalities. Comprehensive experiments on several challenging image inpainting datasets show that our method achieves state-of-the-art performance to deal with various regular/irregular masks efficiently.
Driver Drowsiness Detection System: An Approach By Machine Learning Application
Mar 11, 2023The majority of human deaths and injuries are caused by traffic accidents. A million people worldwide die each year due to traffic accident injuries, consistent with the World Health Organization. Drivers who do not receive enough sleep, rest, or who feel weary may fall asleep behind the wheel, endangering both themselves and other road users. The research on road accidents specified that major road accidents occur due to drowsiness while driving. These days, it is observed that tired driving is the main reason to occur drowsiness. Now, drowsiness becomes the main principle for to increase in the number of road accidents. This becomes a major issue in a world which is very important to resolve as soon as possible. The predominant goal of all devices is to improve the performance to detect drowsiness in real time. Many devices were developed to detect drowsiness, which depend on different artificial intelligence algorithms. So, our research is also related to driver drowsiness detection which can identify the drowsiness of a driver by identifying the face and then followed by eye tracking. The extracted eye image is matched with the dataset by the system. With the help of the dataset, the system detected that if eyes were close for a certain range, it could ring an alarm to alert the driver and if the eyes were open after the alert, then it could continue tracking. If the eyes were open then the score that we set decreased and if the eyes were closed then the score increased. This paper focus to resolve the problem of drowsiness detection with an accuracy of 80% and helps to reduce road accidents.
Data Consistent Deep Rigid MRI Motion Correction
Jan 25, 2023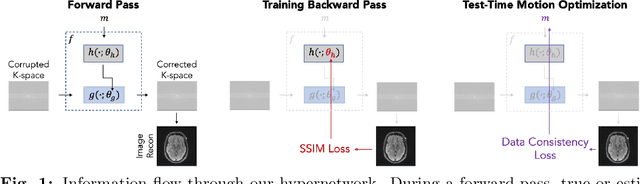
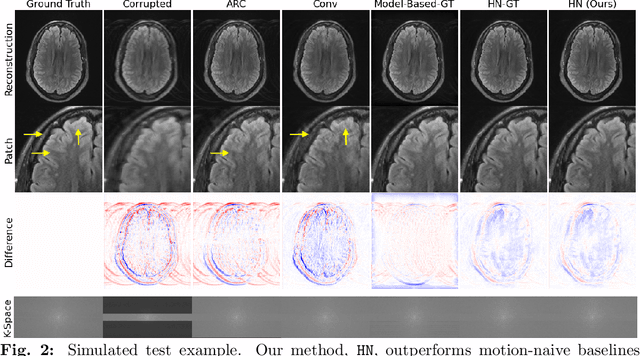
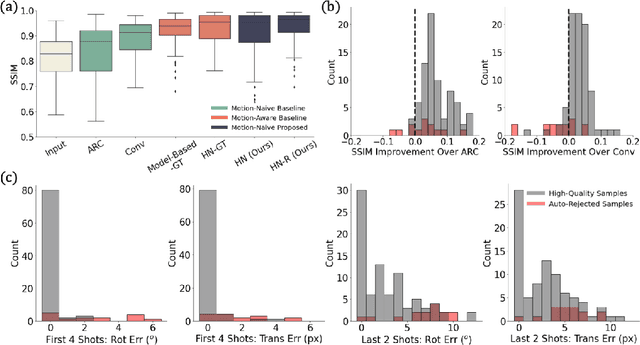
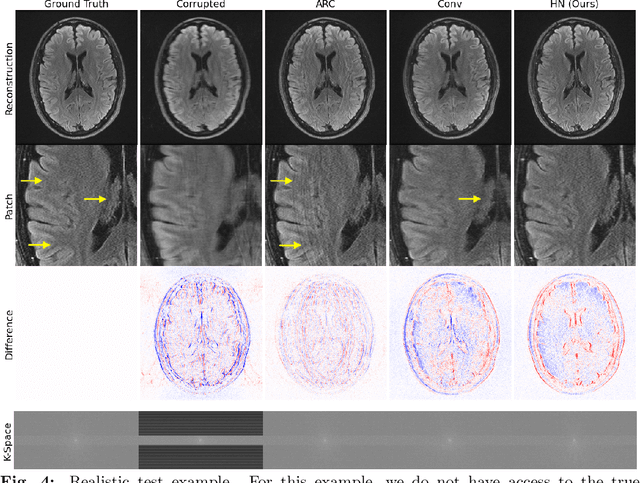
Motion artifacts are a pervasive problem in MRI, leading to misdiagnosis or mischaracterization in population-level imaging studies. Current retrospective rigid intra-slice motion correction techniques jointly optimize estimates of the image and the motion parameters. In this paper, we use a deep network to reduce the joint image-motion parameter search to a search over rigid motion parameters alone. Our network produces a reconstruction as a function of two inputs: corrupted k-space data and motion parameters. We train the network using simulated, motion-corrupted k-space data generated from known motion parameters. At test-time, we estimate unknown motion parameters by minimizing a data consistency loss between the motion parameters, the network-based image reconstruction given those parameters, and the acquired measurements. Intra-slice motion correction experiments on simulated and realistic 2D fast spin echo brain MRI achieve high reconstruction fidelity while retaining the benefits of explicit data consistency-based optimization. Our code is publicly available at https://www.github.com/nalinimsingh/neuroMoCo.
$α$ DARTS Once More: Enhancing Differentiable Architecture Search by Masked Image Modeling
Nov 18, 2022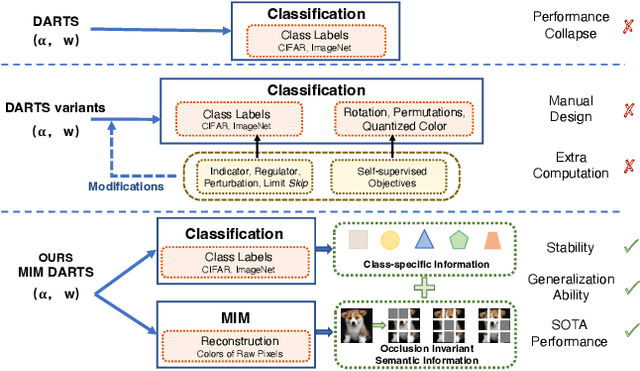
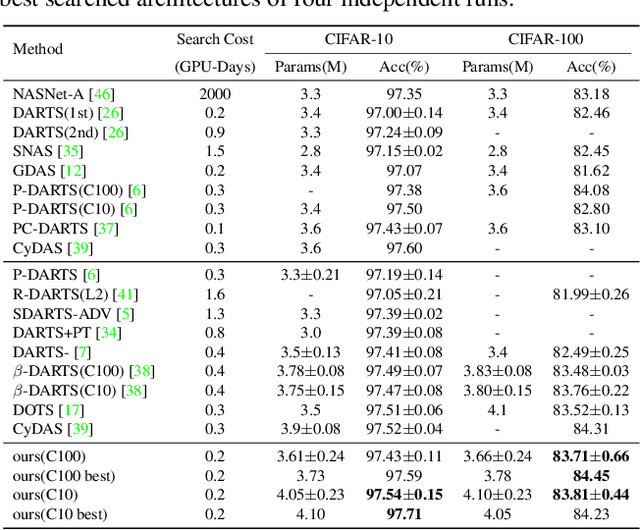
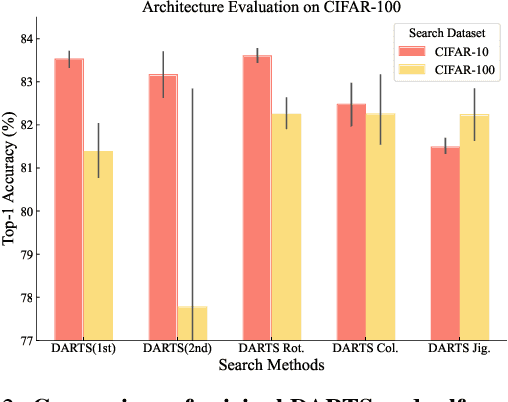
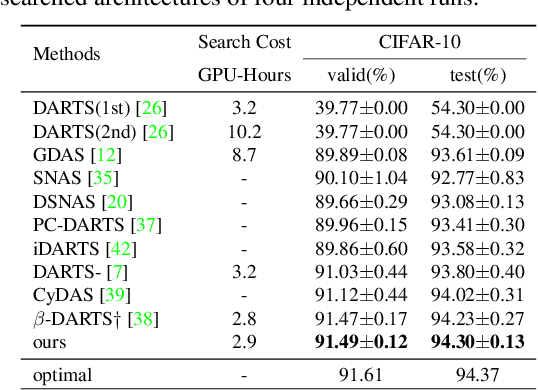
Differentiable architecture search (DARTS) has been a mainstream direction in automatic machine learning. Since the discovery that original DARTS will inevitably converge to poor architectures, recent works alleviate this by either designing rule-based architecture selection techniques or incorporating complex regularization techniques, abandoning the simplicity of the original DARTS that selects architectures based on the largest parametric value, namely $\alpha$. Moreover, we find that all the previous attempts only rely on classification labels, hence learning only single modal information and limiting the representation power of the shared network. To this end, we propose to additionally inject semantic information by formulating a patch recovery approach. Specifically, we exploit the recent trending masked image modeling and do not abandon the guidance from the downstream tasks during the search phase. Our method surpasses all previous DARTS variants and achieves state-of-the-art results on CIFAR-10, CIFAR-100, and ImageNet without complex manual-designed strategies.
Cross-modal Learning for Image-Guided Point Cloud Shape Completion
Sep 20, 2022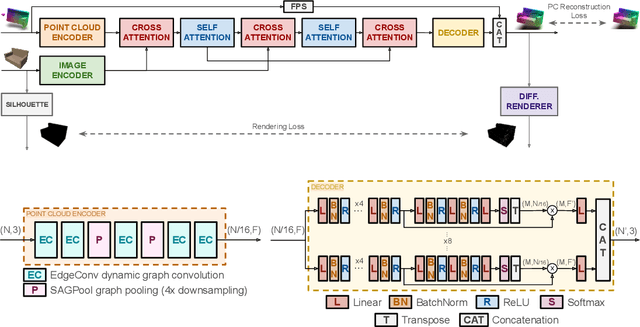
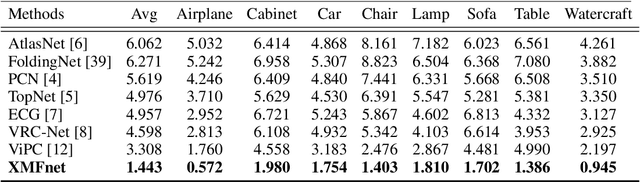
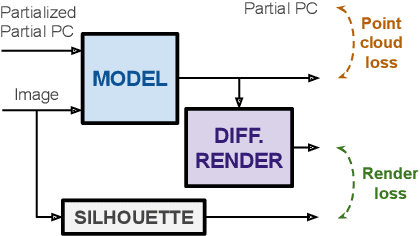
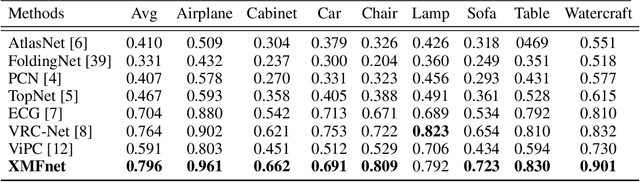
In this paper we explore the recent topic of point cloud completion, guided by an auxiliary image. We show how it is possible to effectively combine the information from the two modalities in a localized latent space, thus avoiding the need for complex point cloud reconstruction methods from single views used by the state-of-the-art. We also investigate a novel weakly-supervised setting where the auxiliary image provides a supervisory signal to the training process by using a differentiable renderer on the completed point cloud to measure fidelity in the image space. Experiments show significant improvements over state-of-the-art supervised methods for both unimodal and multimodal completion. We also show the effectiveness of the weakly-supervised approach which outperforms a number of supervised methods and is competitive with the latest supervised models only exploiting point cloud information.