 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression using Discrete Multi-Level Divisor Transform for Heterogeneous Sensor Data
Oct 18, 2024In recent years, multiple sensor-based devices and systems have been deployed in smart agriculture, industrial automation, E-Health, etc. The diversity of sensor data types and the amount of data pose critical challenges for data transmission and storage. The conventional data compression methods are tuned for a data type, e.g., OGG for audio. Due to such limitations, traditional compression algorithms may not be suitable for a system with multiple sensors. In this paper, we present a novel transform named as discrete multi-level divisor transform (DMDT). A signal compression algorithm is proposed for one-dimensional signals using the DMDT. The universality of the proposed compression algorithm is demonstrated by considering various types of signals, such as audio, electrocardiogram, accelerometer, magnetometer, photoplethysmography, and gyroscope. The proposed DMDT-based signal compression algorithm is also compared with the state-of-the-art compression algorithms.
Near Lossless Time Series Data Compression Methods using Statistics and Deviation
Sep 30, 2022
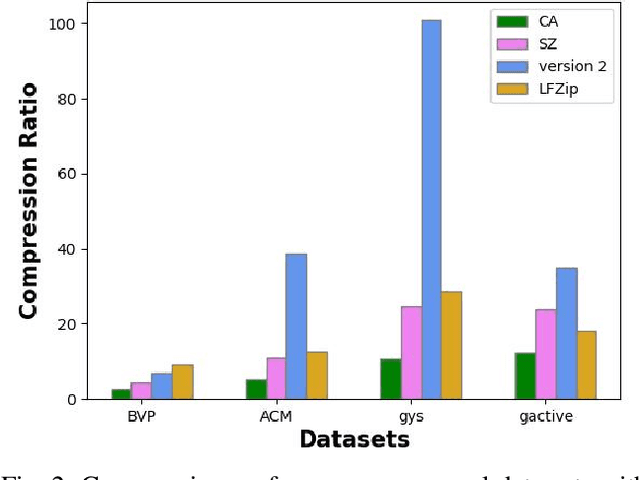

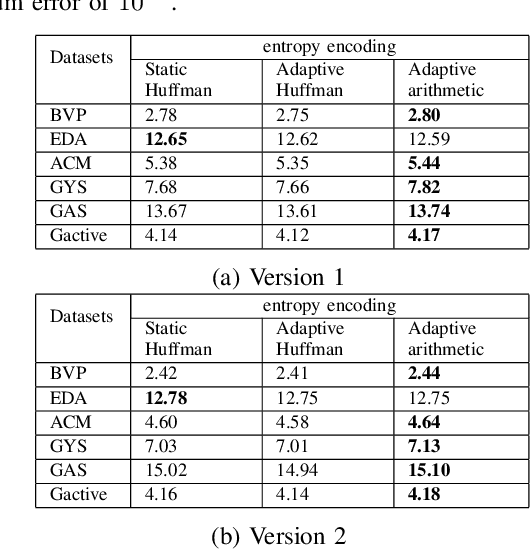
The last two decades have seen tremendous growth in data collections because of the realization of recent technologies, including the internet of things (IoT), E-Health, industrial IoT 4.0, autonomous vehicles, etc. The challenge of data transmission and storage can be handled by utilizing state-of-the-art data compression methods. Recent data compression methods are proposed using deep learning methods, which perform better than conventional methods. However, these methods require a lot of data and resources for training. Furthermore, it is difficult to materialize these deep learning-based solutions on IoT devices due to the resource-constrained nature of IoT devices. In this paper, we propose lightweight data compression methods based on data statistics and deviation. The proposed method performs better than the deep learning method in terms of compression ratio (CR). We simulate and compare the proposed data compression methods for various time series signals, e.g., accelerometer, gas sensor, gyroscope, electrical power consumption, etc. In particular, it is observed that the proposed method achieves 250.8\%, 94.3\%, and 205\% higher CR than the deep learning method for the GYS, Gactive, and ACM datasets, respectively. The code and data are available at https://github.com/vidhi0206/data-compression .
Image Classification using Sequence of Pixels
Sep 23, 2022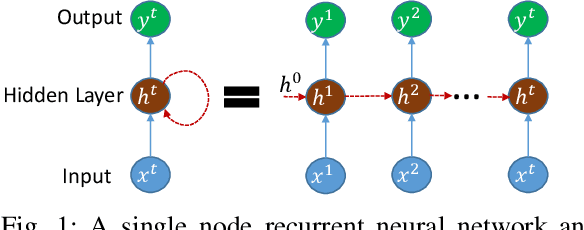
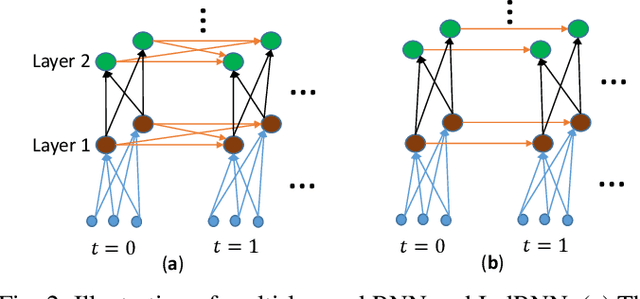

This study compares sequential image classification methods based on recurrent neural networks. We describe methods based on recurrent neural networks such as Long-Short-Term memory(LSTM), bidirectional Long-Short-Term memory(BiLSTM) architectures, etc. We also review the state-of-the-art sequential image classification architectures. We mainly focus on LSTM, BiLSTM, temporal convolution network, and independent recurrent neural network architecture in the study. It is known that RNN lacks in learning long-term dependencies in the input sequence. We use a simple feature construction method using orthogonal Ramanujan periodic transform on the input sequence. Experiments demonstrate that if these features are given to LSTM or BiLSTM networks, the performance increases drastically. Our focus in this study is to increase the training accuracy simultaneously reducing the training time for the LSTM and BiLSTM architecture, but not on pushing the state-of-the-art results, so we use simple LSTM/BiLSTM architecture. We compare sequential input with the constructed feature as input to single layer LSTM and BiLSTM network for MNIST and CIFAR datasets. We observe that sequential input to the LSTM network with 128 hidden unit training for five epochs results in training accuracy of 33% whereas constructed features as input to the same LSTM network results in training accuracy of 90% with 1/3 lesser time.