 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Extraction Matters More: Universal Deepfake Disruption through Attacking Ensemble Feature Extractors
Mar 01, 2023

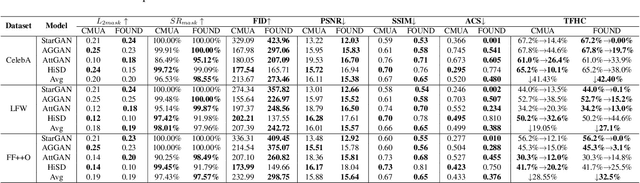
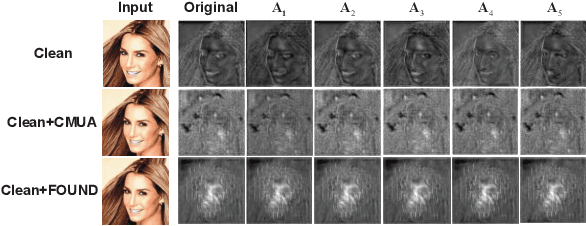

Adversarial example is a rising way of protecting facial privacy security from deepfake modification. To prevent massive facial images from being illegally modified by various deepfake models, it is essential to design a universal deepfake disruptor. However, existing works treat deepfake disruption as an End-to-End process, ignoring the functional difference between feature extraction and image reconstruction, which makes it difficult to generate a cross-model universal disruptor. In this work, we propose a novel Feature-Output ensemble UNiversal Disruptor (FOUND) against deepfake networks, which explores a new opinion that considers attacking feature extractors as the more critical and general task in deepfake disruption. We conduct an effective two-stage disruption process. We first disrupt multi-model feature extractors through multi-feature aggregation and individual-feature maintenance, and then develop a gradient-ensemble algorithm to enhance the disruption effect by simplifying the complex optimization problem of disrupting multiple End-to-End models. Extensive experiments demonstrate that FOUND can significantly boost the disruption effect against ensemble deepfake benchmark models. Besides, our method can fast obtain a cross-attribute, cross-image, and cross-model universal deepfake disruptor with only a few training images, surpassing state-of-the-art universal disruptors in both success rate and efficiency.
BiSTNet: Semantic Image Prior Guided Bidirectional Temporal Feature Fusion for Deep Exemplar-based Video Colorization
Dec 05, 2022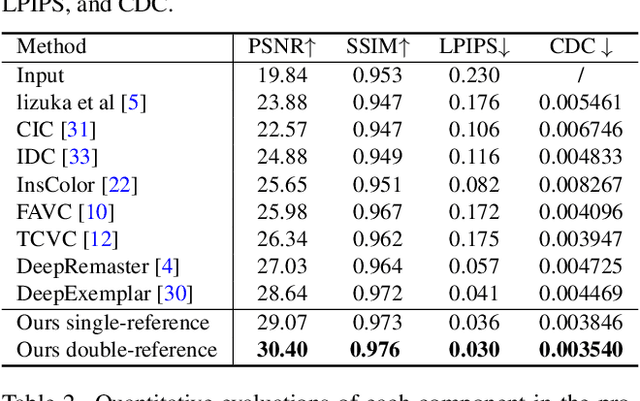
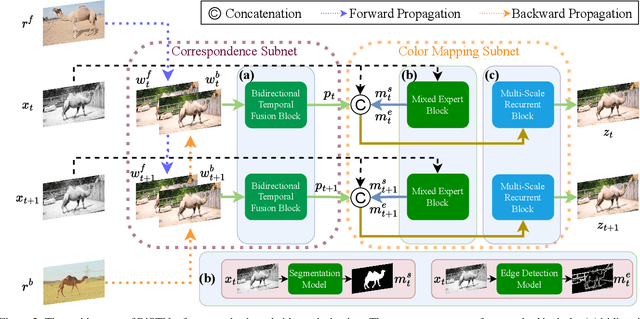
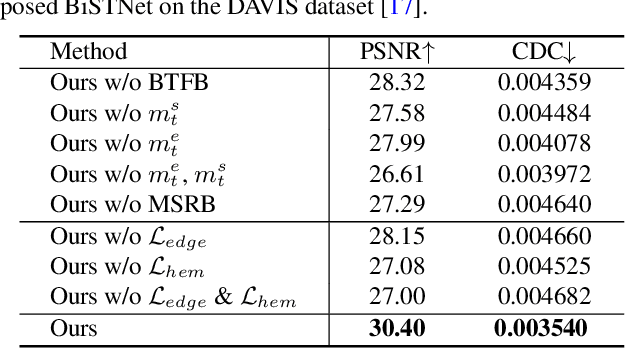

How to effectively explore the colors of reference exemplars and propagate them to colorize each frame is vital for exemplar-based video colorization. In this paper, we present an effective BiSTNet to explore colors of reference exemplars and utilize them to help video colorization by a bidirectional temporal feature fusion with the guidance of semantic image prior. We first establish the semantic correspondence between each frame and the reference exemplars in deep feature space to explore color information from reference exemplars. Then, to better propagate the colors of reference exemplars into each frame and avoid the inaccurate matches colors from exemplars we develop a simple yet effective bidirectional temporal feature fusion module to better colorize each frame. We note that there usually exist color-bleeding artifacts around the boundaries of the important objects in videos. To overcome this problem, we further develop a mixed expert block to extract semantic information for modeling the object boundaries of frames so that the semantic image prior can better guide the colorization process for better performance. In addition, we develop a multi-scale recurrent block to progressively colorize frames in a coarse-to-fine manner. Extensive experimental results demonstrate that the proposed BiSTNet performs favorably against state-of-the-art methods on the benchmark datasets. Our code will be made available at \url{https://yyang181.github.io/BiSTNet/}
High-resolution semantically-consistent image-to-image translation
Sep 13, 2022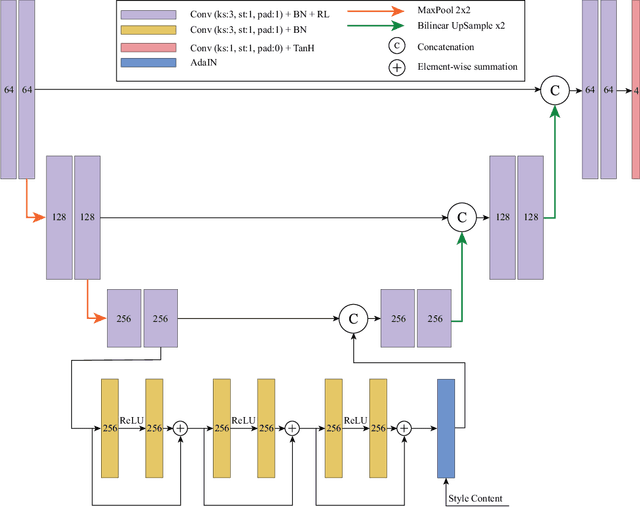
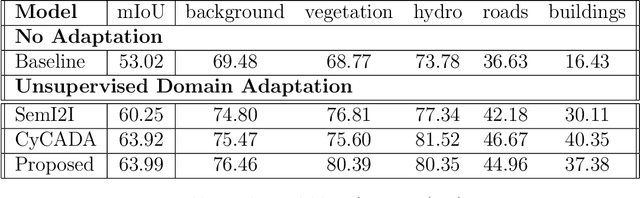
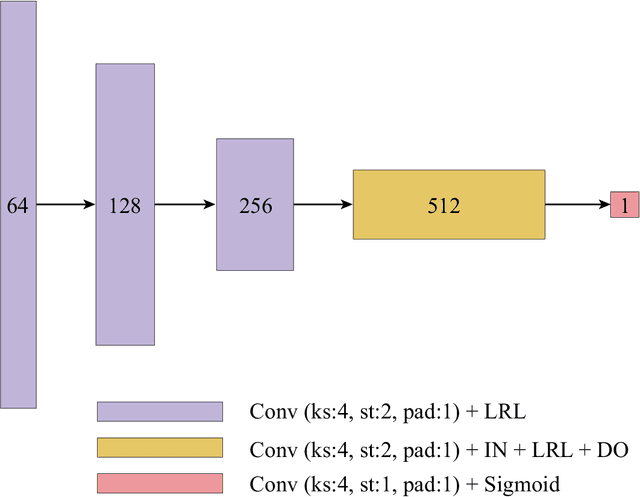
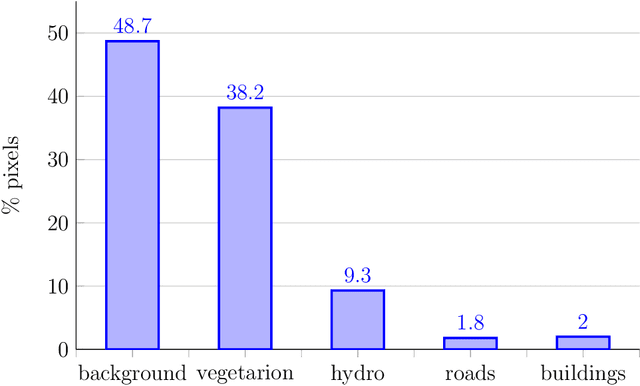
Deep learning has become one of remote sensing scientists' most efficient computer vision tools in recent years. However, the lack of training labels for the remote sensing datasets means that scientists need to solve the domain adaptation problem to narrow the discrepancy between satellite image datasets. As a result, image segmentation models that are then trained, could better generalize and use an existing set of labels instead of requiring new ones. This work proposes an unsupervised domain adaptation model that preserves semantic consistency and per-pixel quality for the images during the style-transferring phase. This paper's major contribution is proposing the improved architecture of the SemI2I model, which significantly boosts the proposed model's performance and makes it competitive with the state-of-the-art CyCADA model. A second contribution is testing the CyCADA model on the remote sensing multi-band datasets such as WorldView-2 and SPOT-6. The proposed model preserves semantic consistency and per-pixel quality for the images during the style-transferring phase. Thus, the semantic segmentation model, trained on the adapted images, shows substantial performance gain compared to the SemI2I model and reaches similar results as the state-of-the-art CyCADA model. The future development of the proposed method could include ecological domain transfer, {\em a priori} evaluation of dataset quality in terms of data distribution, or exploration of the inner architecture of the domain adaptation model.
Focusing On Targets For Improving Weakly Supervised Visual Grounding
Feb 22, 2023
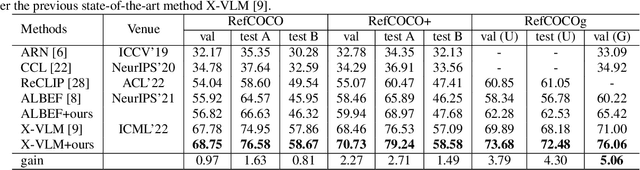
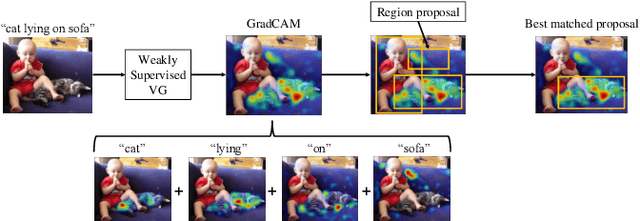
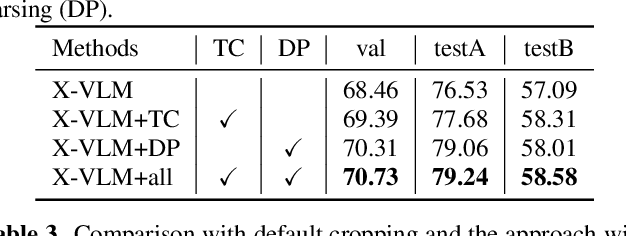
Weakly supervised visual grounding aims to predict the region in an image that corresponds to a specific linguistic query, where the mapping between the target object and query is unknown in the training stage. The state-of-the-art method uses a vision language pre-training model to acquire heatmaps from Grad-CAM, which matches every query word with an image region, and uses the combined heatmap to rank the region proposals. In this paper, we propose two simple but efficient methods for improving this approach. First, we propose a target-aware cropping approach to encourage the model to learn both object and scene level semantic representations. Second, we apply dependency parsing to extract words related to the target object, and then put emphasis on these words in the heatmap combination. Our method surpasses the previous SOTA methods on RefCOCO, RefCOCO+, and RefCOCOg by a notable margin.
Patch of Invisibility: Naturalistic Black-Box Adversarial Attacks on Object Detectors
Mar 09, 2023

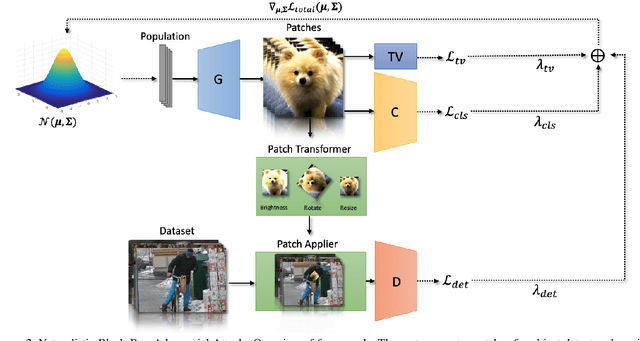

Adversarial attacks on deep-learning models have been receiving increased attention in recent years. Work in this area has mostly focused on gradient-based techniques, so-called white-box attacks, wherein the attacker has access to the targeted model's internal parameters; such an assumption is usually unrealistic in the real world. Some attacks additionally use the entire pixel space to fool a given model, which is neither practical nor physical (i.e., real-world). On the contrary, we propose herein a gradient-free method that uses the learned image manifold of a pretrained generative adversarial network (GAN) to generate naturalistic physical adversarial patches for object detectors. We show that our proposed method works both digitally and physically.
Learning to Super-Resolve Blurry Images with Events
Feb 27, 2023
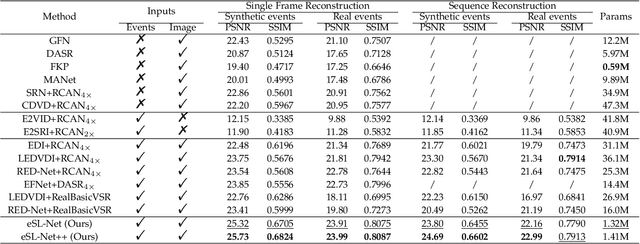
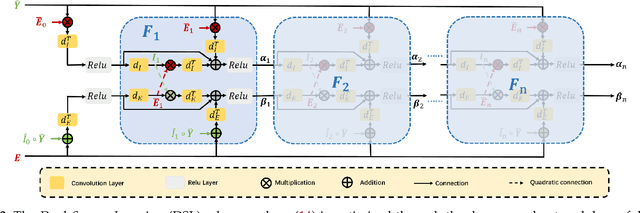
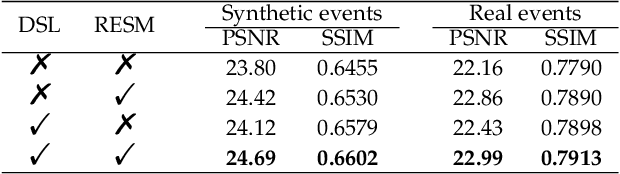
Super-Resolution from a single motion Blurred image (SRB) is a severely ill-posed problem due to the joint degradation of motion blurs and low spatial resolution. In this paper, we employ events to alleviate the burden of SRB and propose an Event-enhanced SRB (E-SRB) algorithm, which can generate a sequence of sharp and clear images with High Resolution (HR) from a single blurry image with Low Resolution (LR). To achieve this end, we formulate an event-enhanced degeneration model to consider the low spatial resolution, motion blurs, and event noises simultaneously. We then build an event-enhanced Sparse Learning Network (eSL-Net++) upon a dual sparse learning scheme where both events and intensity frames are modeled with sparse representations. Furthermore, we propose an event shuffle-and-merge scheme to extend the single-frame SRB to the sequence-frame SRB without any additional training process. Experimental results on synthetic and real-world datasets show that the proposed eSL-Net++ outperforms state-of-the-art methods by a large margin. Datasets, codes, and more results are available at https://github.com/ShinyWang33/eSL-Net-Plusplus.
UKnow: A Unified Knowledge Protocol for Common-Sense Reasoning and Vision-Language Pre-training
Feb 14, 2023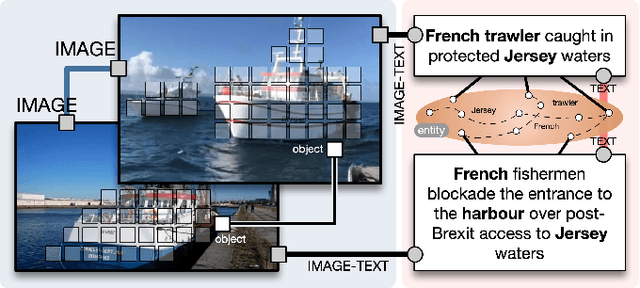
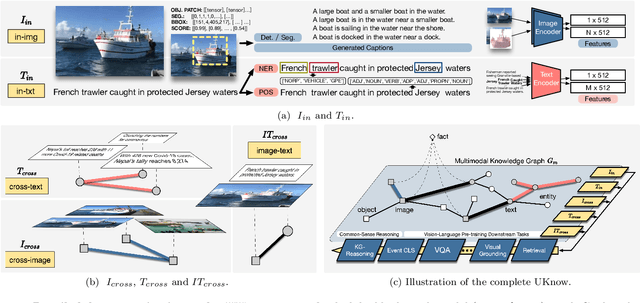
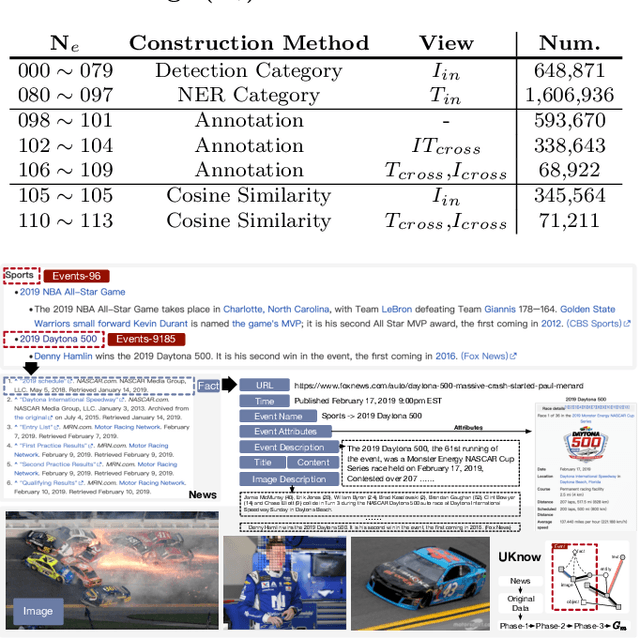
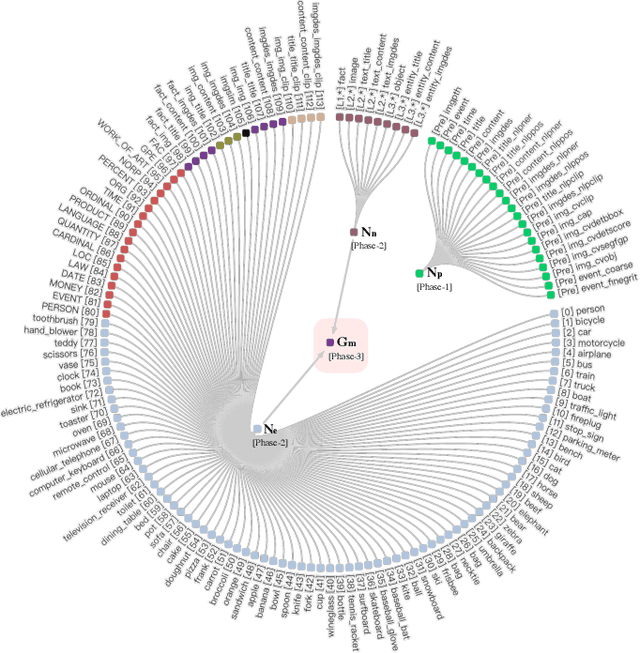
This work presents a unified knowledge protocol, called UKnow, which facilitates knowledge-based studies from the perspective of data. Particularly focusing on visual and linguistic modalities, we categorize data knowledge into five unit types, namely, in-image, in-text, cross-image, cross-text, and image-text. Following this protocol, we collect, from public international news, a large-scale multimodal knowledge graph dataset that consists of 1,388,568 nodes (with 571,791 vision-related ones) and 3,673,817 triplets. The dataset is also annotated with rich event tags, including 96 coarse labels and 9,185 fine labels, expanding its potential usage. To further verify that UKnow can serve as a standard protocol, we set up an efficient pipeline to help reorganize existing datasets under UKnow format. Finally, we benchmark the performance of some widely-used baselines on the tasks of common-sense reasoning and vision-language pre-training. Results on both our new dataset and the reformatted public datasets demonstrate the effectiveness of UKnow in knowledge organization and method evaluation. Code, dataset, conversion tool, and baseline models will be made public.
MoWE: Mixture of Weather Experts for Multiple Adverse Weather Removal
Mar 24, 2023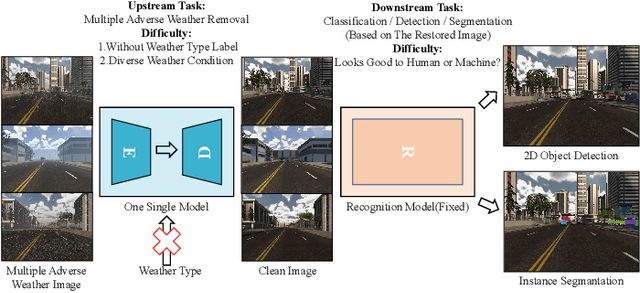
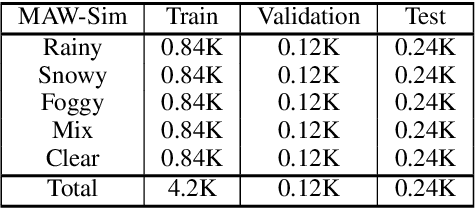
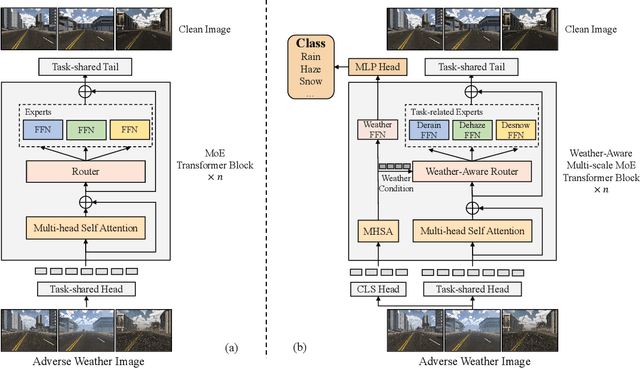
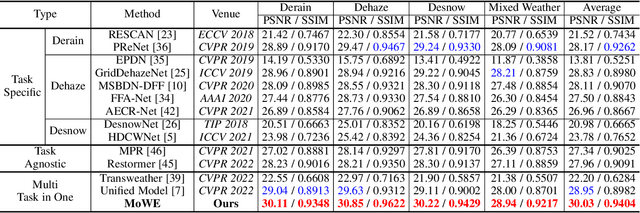
Currently, most adverse weather removal tasks are handled independently, such as deraining, desnowing, and dehazing. However, in autonomous driving scenarios, the type, intensity, and mixing degree of the weather are unknown, so the separated task setting cannot deal with these complex conditions well. Besides, the vision applications in autonomous driving often aim at high-level tasks, but existing weather removal methods neglect the connection between performance on perceptual tasks and signal fidelity. To this end, in upstream task, we propose a novel \textbf{Mixture of Weather Experts(MoWE)} Transformer framework to handle complex weather removal in a perception-aware fashion. We design a \textbf{Weather-aware Router} to make the experts targeted more relevant to weather types while without the need for weather type labels during inference. To handle diverse weather conditions, we propose \textbf{Multi-scale Experts} to fuse information among neighbor tokens. In downstream task, we propose a \textbf{Label-free Perception-aware Metric} to measure whether the outputs of image processing models are suitable for high level perception tasks without the demand for semantic labels. We collect a syntactic dataset \textbf{MAW-Sim} towards autonomous driving scenarios to benchmark the multiple weather removal performance of existing methods. Our MoWE achieves SOTA performance in upstream task on the proposed dataset and two public datasets, i.e. All-Weather and Rain/Fog-Cityscapes, and also have better perceptual results in downstream segmentation task compared to other methods. Our codes and datasets will be released after acceptance.
A Simple and Generic Framework for Feature Distillation via Channel-wise Transformation
Mar 24, 2023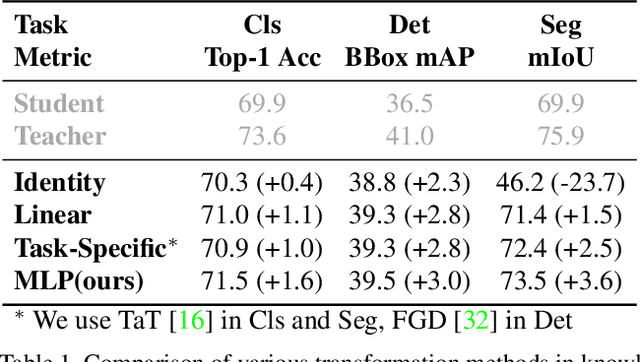
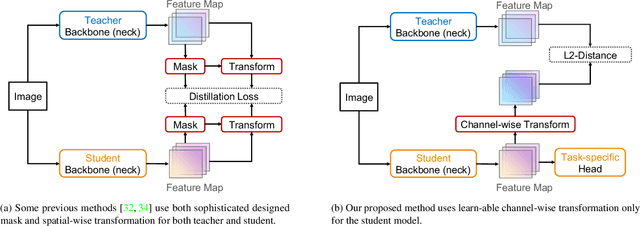
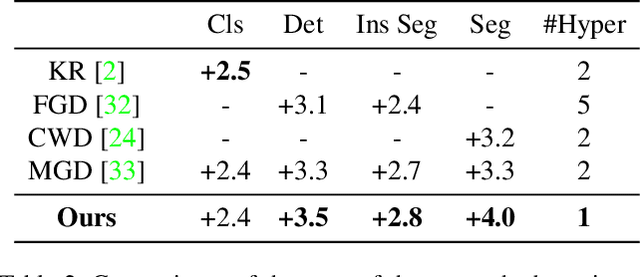
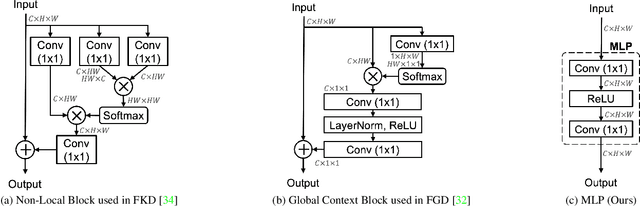
Knowledge distillation is a popular technique for transferring the knowledge from a large teacher model to a smaller student model by mimicking. However, distillation by directly aligning the feature maps between teacher and student may enforce overly strict constraints on the student thus degrade the performance of the student model. To alleviate the above feature misalignment issue, existing works mainly focus on spatially aligning the feature maps of the teacher and the student, with pixel-wise transformation. In this paper, we newly find that aligning the feature maps between teacher and student along the channel-wise dimension is also effective for addressing the feature misalignment issue. Specifically, we propose a learnable nonlinear channel-wise transformation to align the features of the student and the teacher model. Based on it, we further propose a simple and generic framework for feature distillation, with only one hyper-parameter to balance the distillation loss and the task specific loss. Extensive experimental results show that our method achieves significant performance improvements in various computer vision tasks including image classification (+3.28% top-1 accuracy for MobileNetV1 on ImageNet-1K), object detection (+3.9% bbox mAP for ResNet50-based Faster-RCNN on MS COCO), instance segmentation (+2.8% Mask mAP for ResNet50-based Mask-RCNN), and semantic segmentation (+4.66% mIoU for ResNet18-based PSPNet in semantic segmentation on Cityscapes), which demonstrates the effectiveness and the versatility of the proposed method. The code will be made publicly available.
CompoNeRF: Text-guided Multi-object Compositional NeRF with Editable 3D Scene Layout
Mar 24, 2023

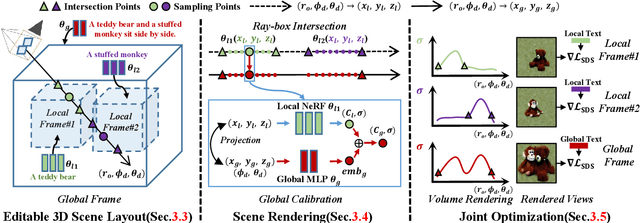

Recent research endeavors have shown that combining neural radiance fields (NeRFs) with pre-trained diffusion models holds great potential for text-to-3D generation.However, a hurdle is that they often encounter guidance collapse when rendering complex scenes from multi-object texts. Because the text-to-image diffusion models are inherently unconstrained, making them less competent to accurately associate object semantics with specific 3D structures. To address this issue, we propose a novel framework, dubbed CompoNeRF, that explicitly incorporates an editable 3D scene layout to provide effective guidance at the single object (i.e., local) and whole scene (i.e., global) levels. Firstly, we interpret the multi-object text as an editable 3D scene layout containing multiple local NeRFs associated with the object-specific 3D box coordinates and text prompt, which can be easily collected from users. Then, we introduce a global MLP to calibrate the compositional latent features from local NeRFs, which surprisingly improves the view consistency across different local NeRFs. Lastly, we apply the text guidance on global and local levels through their corresponding views to avoid guidance ambiguity. This way, our CompoNeRF allows for flexible scene editing and re-composition of trained local NeRFs into a new scene by manipulating the 3D layout or text prompt. Leveraging the open-source Stable Diffusion model, our CompoNeRF can generate faithful and editable text-to-3D results while opening a potential direction for text-guided multi-object composition via the editable 3D scene layout.