 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Soft Augmentation for Image Classification
Nov 09, 2022
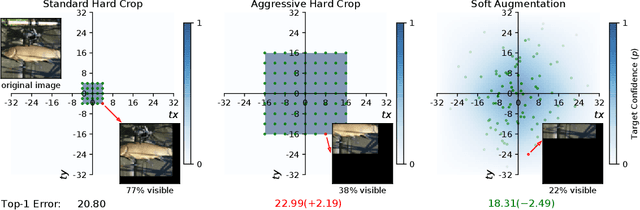
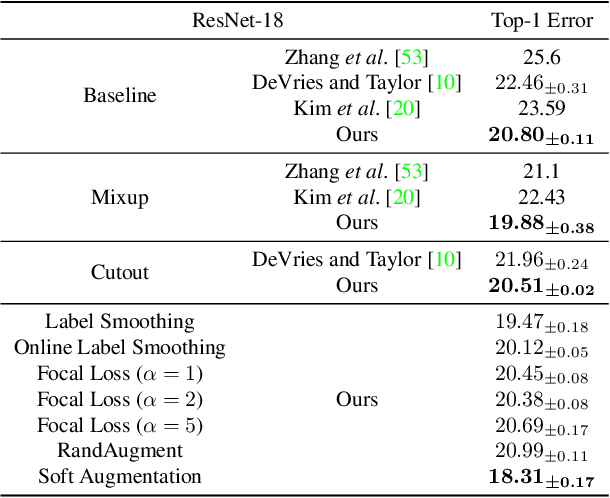

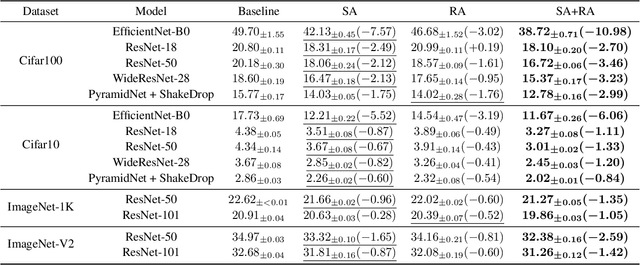
Modern neural networks are over-parameterized and thus rely on strong regularization such as data augmentation and weight decay to reduce overfitting and improve generalization. The dominant form of data augmentation applies invariant transforms, where the learning target of a sample is invariant to the transform applied to that sample. We draw inspiration from human visual classification studies and propose generalizing augmentation with invariant transforms to soft augmentation where the learning target softens non-linearly as a function of the degree of the transform applied to the sample: e.g., more aggressive image crop augmentations produce less confident learning targets. We demonstrate that soft targets allow for more aggressive data augmentation, offer more robust performance boosts, work with other augmentation policies, and interestingly, produce better calibrated models (since they are trained to be less confident on aggressively cropped/occluded examples). Combined with existing aggressive augmentation strategies, soft target 1) doubles the top-1 accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2) improves model occlusion performance by up to $4\times$, and 3) halves the expected calibration error (ECE). Finally, we show that soft augmentation generalizes to self-supervised classification tasks.
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
Mar 04, 2023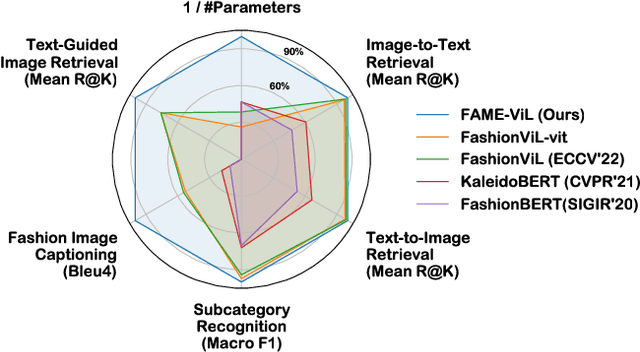
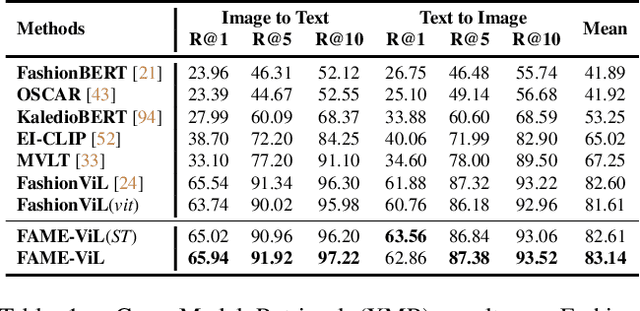

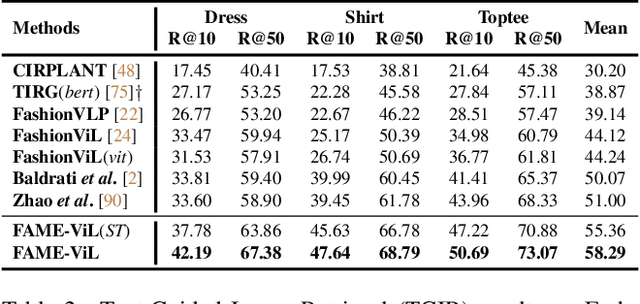
In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL.
Whole-slide-imaging Cancer Metastases Detection and Localization with Limited Tumorous Data
Mar 18, 2023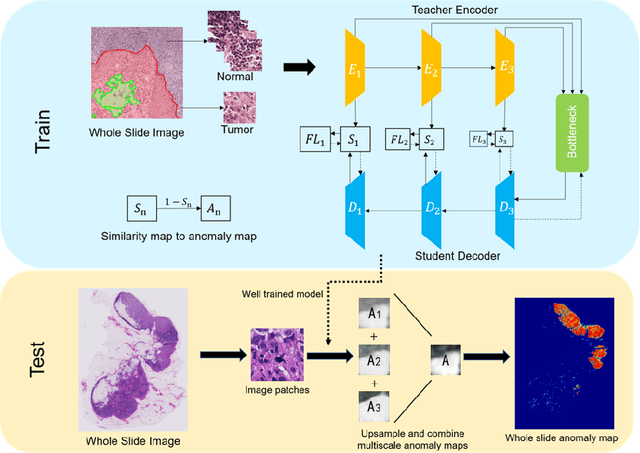
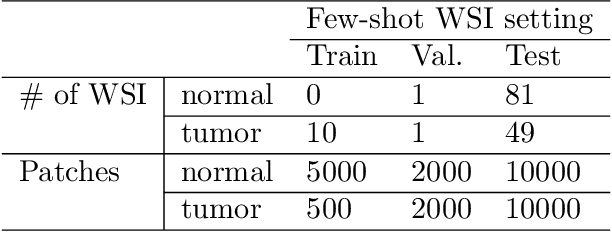

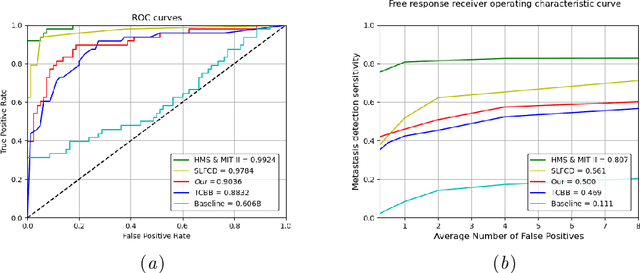
Recently, various deep learning methods have shown significant successes in medical image analysis, especially in the detection of cancer metastases in hematoxylin and eosin (H&E) stained whole-slide images (WSIs). However, in order to obtain good performance, these research achievements rely on hundreds of well-annotated WSIs. In this study, we tackle the tumor localization and detection problem under the setting of few labeled whole slide images and introduce a patch-based analysis pipeline based on the latest reverse knowledge distillation architecture. To address the extremely unbalanced normal and tumorous samples in training sample collection, we applied the focal loss formula to the representation similarity metric for model optimization. Compared with prior arts, our method achieves similar performance by less than ten percent of training samples on the public Camelyon16 dataset. In addition, this is the first work that show the great potential of the knowledge distillation models in computational histopathology.
LossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023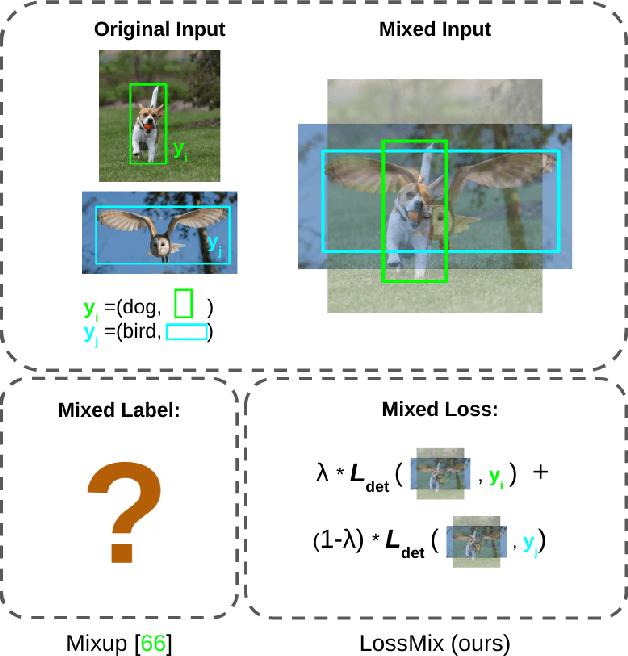
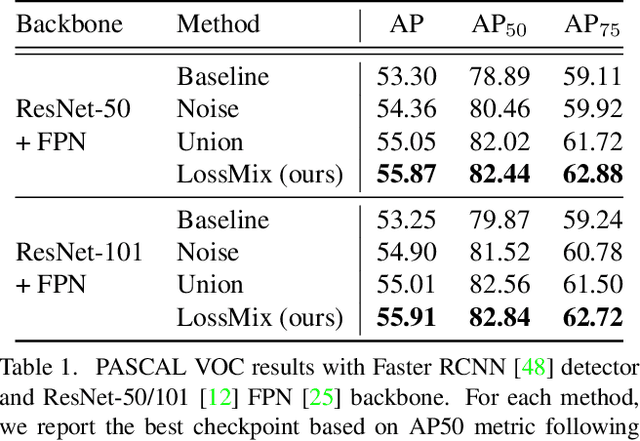
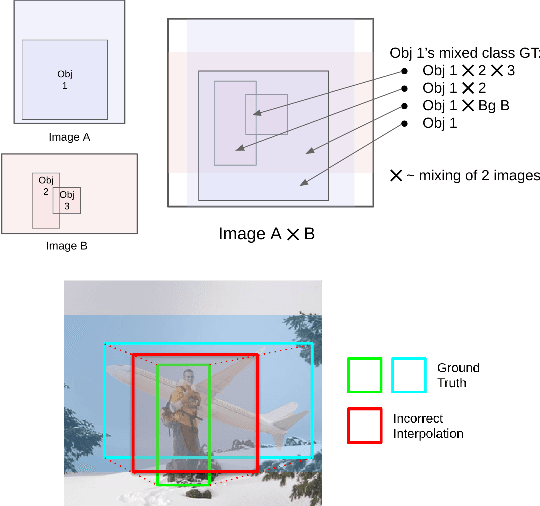
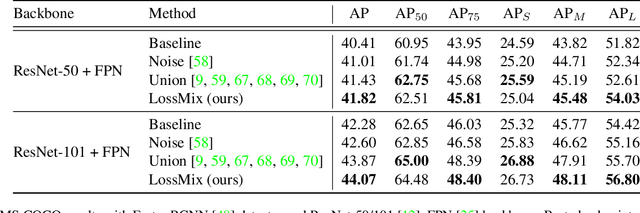
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
Meta-Learning Initializations for Interactive Medical Image Registration
Oct 27, 2022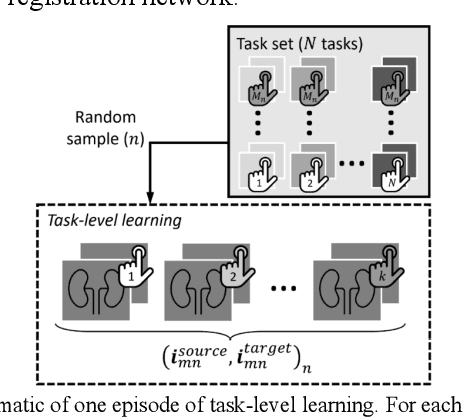
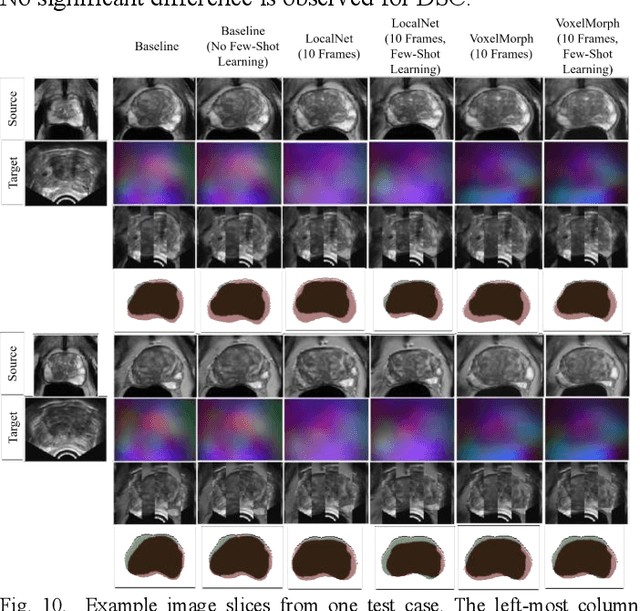
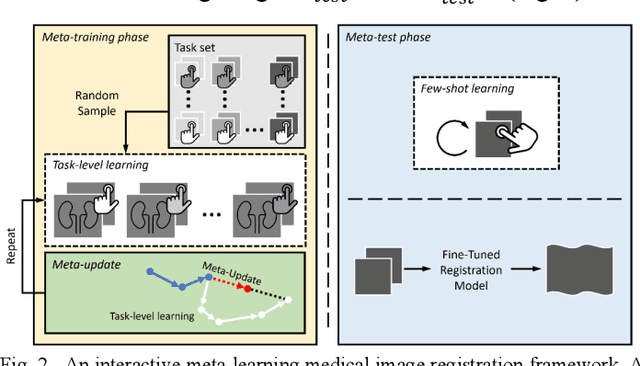
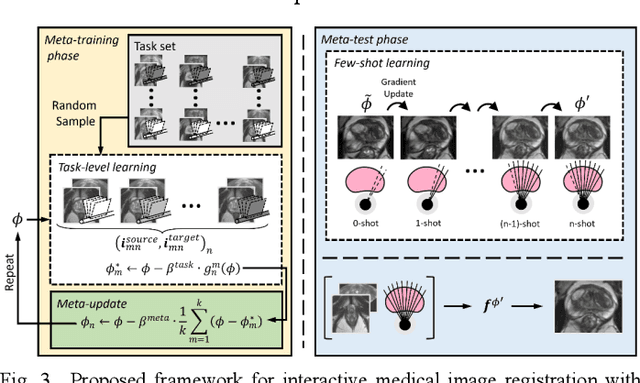
We present a meta-learning framework for interactive medical image registration. Our proposed framework comprises three components: a learning-based medical image registration algorithm, a form of user interaction that refines registration at inference, and a meta-learning protocol that learns a rapidly adaptable network initialization. This paper describes a specific algorithm that implements the registration, interaction and meta-learning protocol for our exemplar clinical application: registration of magnetic resonance (MR) imaging to interactively acquired, sparsely-sampled transrectal ultrasound (TRUS) images. Our approach obtains comparable registration error (4.26 mm) to the best-performing non-interactive learning-based 3D-to-3D method (3.97 mm) while requiring only a fraction of the data, and occurring in real-time during acquisition. Applying sparsely sampled data to non-interactive methods yields higher registration errors (6.26 mm), demonstrating the effectiveness of interactive MR-TRUS registration, which may be applied intraoperatively given the real-time nature of the adaptation process.
Empirical Assessment of End-to-End Iris Recognition System Capacity
Mar 20, 2023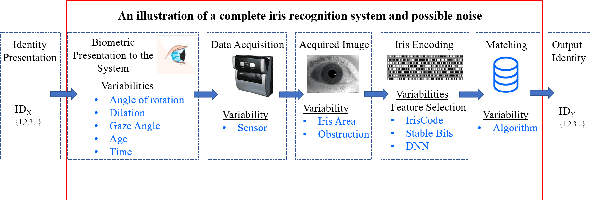
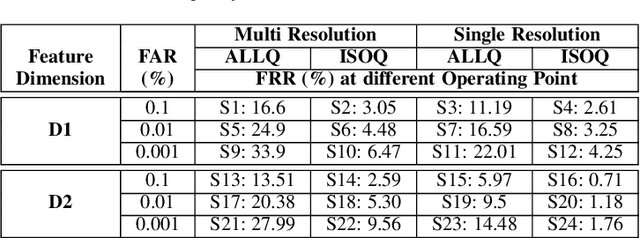
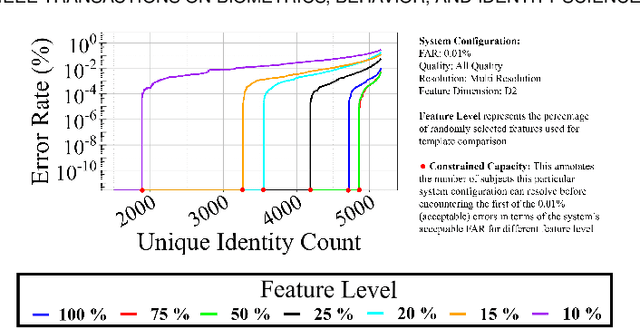
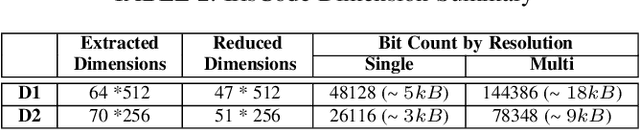
Iris is an established modality in biometric recognition applications including consumer electronics, e-commerce, border security, forensics, and de-duplication of identity at a national scale. In light of the expanding usage of biometric recognition, identity clash (when templates from two different people match) is an imperative factor of consideration for a system's deployment. This study explores system capacity estimation by empirically estimating the constrained capacity of an end-to-end iris recognition system (NIR systems with Daugman-based feature extraction) operating at an acceptable error rate i.e. the number of subjects a system can resolve before encountering an error. We study the impact of six system parameters on an iris recognition system's constrained capacity -- number of enrolled identities, image quality, template dimension, random feature elimination, filter resolution, and system operating point. In our assessment, we analyzed 13.2 million comparisons from 5158 unique identities for each of 24 different system configurations. This work provides a framework to better understand iris recognition system capacity as a function of biometric system configurations beyond the operating point, for large-scale applications.
A closer look at the training dynamics of knowledge distillation
Mar 20, 2023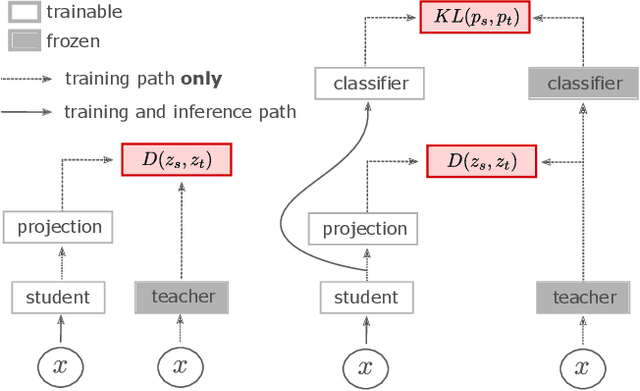
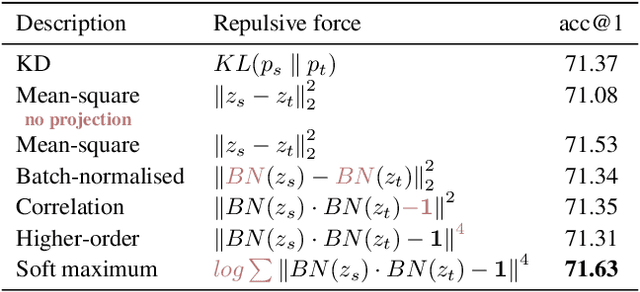
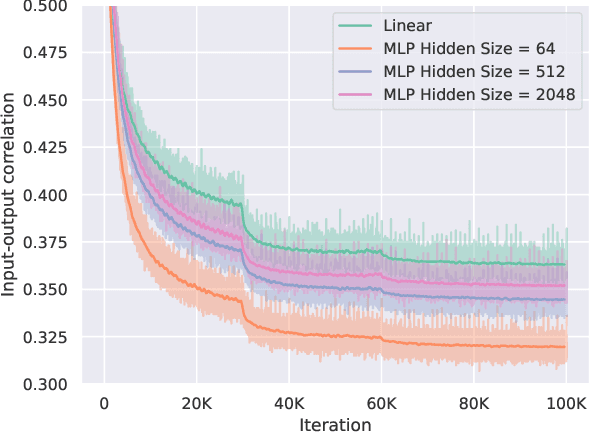

In this paper we revisit the efficacy of knowledge distillation as a function matching and metric learning problem. In doing so we verify three important design decisions, namely the normalisation, soft maximum function, and projection layers as key ingredients. We theoretically show that the projector implicitly encodes information on past examples, enabling relational gradients for the student. We then show that the normalisation of representations is tightly coupled with the training dynamics of this projector, which can have a large impact on the students performance. Finally, we show that a simple soft maximum function can be used to address any significant capacity gap problems. Experimental results on various benchmark datasets demonstrate that using these insights can lead to superior or comparable performance to state-of-the-art knowledge distillation techniques, despite being much more computationally efficient. In particular, we obtain these results across image classification (CIFAR100 and ImageNet), object detection (COCO2017), and on more difficult distillation objectives, such as training data efficient transformers, whereby we attain a 77.2% top-1 accuracy with DeiT-Ti on ImageNet.
Internal Structure Attention Network for Fingerprint Presentation Attack Detection from Optical Coherence Tomography
Mar 20, 2023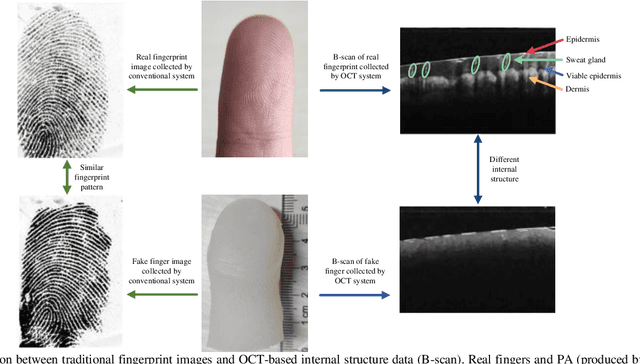
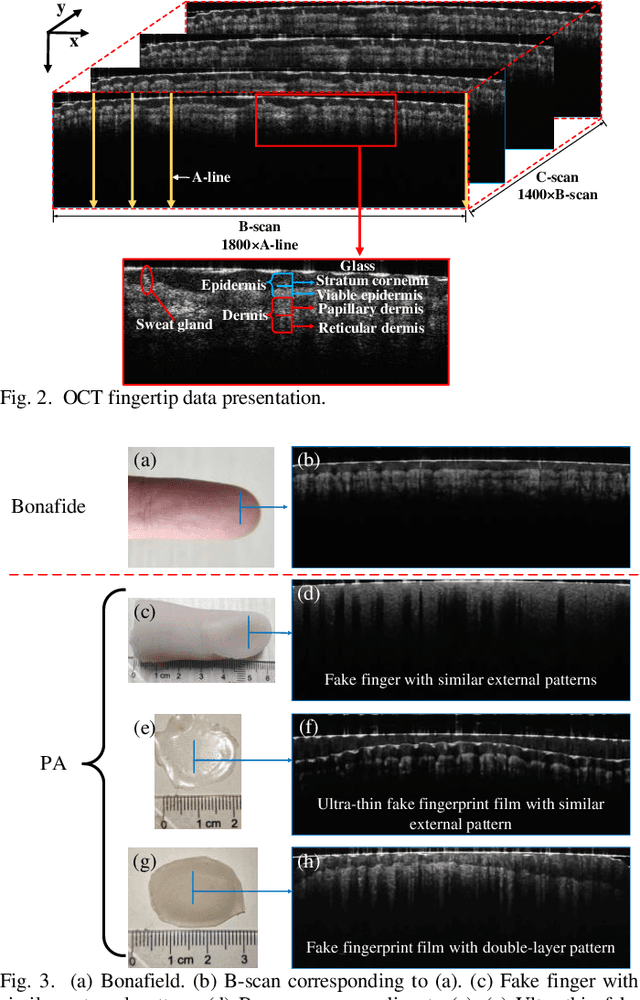
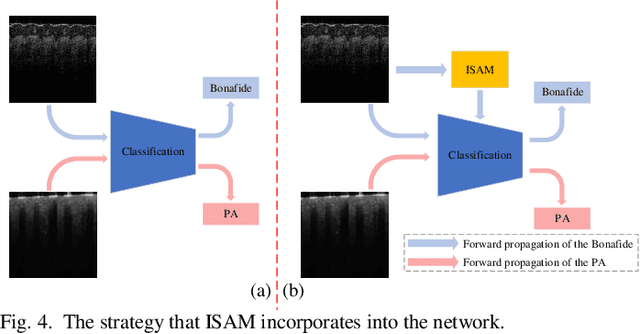
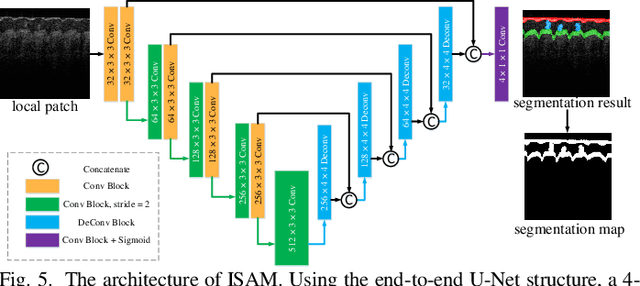
As a non-invasive optical imaging technique, optical coherence tomography (OCT) has proven promising for automatic fingerprint recognition system (AFRS) applications. Diverse approaches have been proposed for OCT-based fingerprint presentation attack detection (PAD). However, considering the complexity and variety of PA samples, it is extremely challenging to increase the generalization ability with the limited PA dataset. To solve the challenge, this paper presents a novel supervised learning-based PAD method, denoted as ISAPAD, which applies prior knowledge to guide network training and enhance the generalization ability. The proposed dual-branch architecture can not only learns global features from the OCT image, but also concentrate on layered structure feature which comes from the internal structure attention module (ISAM). The simple yet effective ISAM enables the proposed network to obtain layered segmentation features belonging only to Bonafide from noisy OCT volume data directly. Combined with effective training strategies and PAD score generation rules, ISAPAD obtains optimal PAD performance in limited training data. Domain generalization experiments and visualization analysis validate the effectiveness of the proposed method for OCT PAD.
Bridging CLIP and StyleGAN through Latent Alignment for Image Editing
Oct 10, 2022

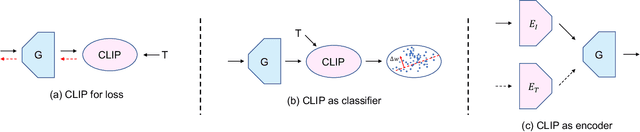
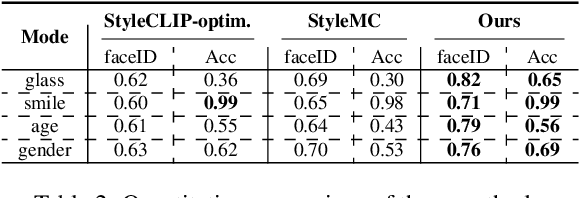
Text-driven image manipulation is developed since the vision-language model (CLIP) has been proposed. Previous work has adopted CLIP to design a text-image consistency-based objective to address this issue. However, these methods require either test-time optimization or image feature cluster analysis for single-mode manipulation direction. In this paper, we manage to achieve inference-time optimization-free diverse manipulation direction mining by bridging CLIP and StyleGAN through Latent Alignment (CSLA). More specifically, our efforts consist of three parts: 1) a data-free training strategy to train latent mappers to bridge the latent space of CLIP and StyleGAN; 2) for more precise mapping, temporal relative consistency is proposed to address the knowledge distribution bias problem among different latent spaces; 3) to refine the mapped latent in s space, adaptive style mixing is also proposed. With this mapping scheme, we can achieve GAN inversion, text-to-image generation and text-driven image manipulation. Qualitative and quantitative comparisons are made to demonstrate the effectiveness of our method.
RePrompt: Automatic Prompt Editing to Refine AI-Generative Art Towards Precise Expressions
Feb 25, 2023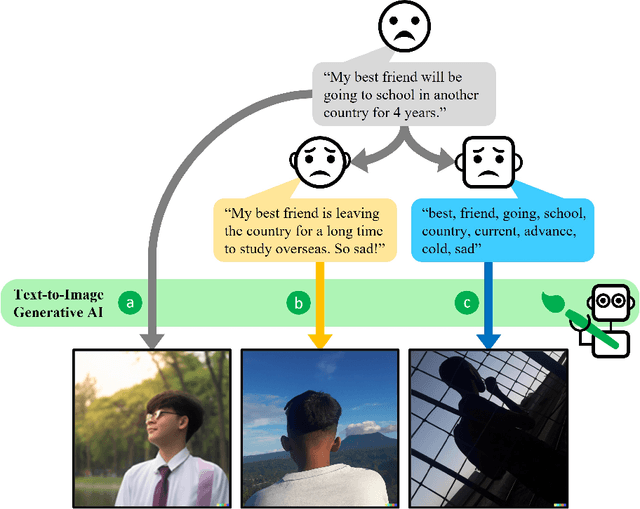
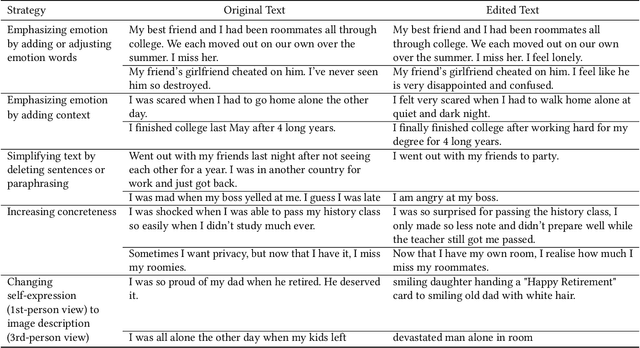
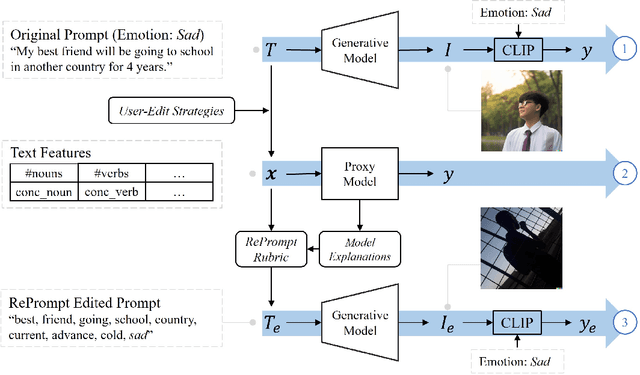

Generative AI models have shown impressive ability to produce images with text prompts, which could benefit creativity in visual art creation and self-expression. However, it is unclear how precisely the generated images express contexts and emotions from the input texts. We explored the emotional expressiveness of AI-generated images and developed RePrompt, an automatic method to refine text prompts toward precise expression of the generated images. Inspired by crowdsourced editing strategies, we curated intuitive text features, such as the number and concreteness of nouns, and trained a proxy model to analyze the feature effects on the AI-generated image. With model explanations of the proxy model, we curated a rubric to adjust text prompts to optimize image generation for precise emotion expression. We conducted simulation and user studies, which showed that RePrompt significantly improves the emotional expressiveness of AI-generated images, especially for negative emotions.