 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Degrees of Freedom of Gridded Control Points in Learning-Based Medical Image Registration
Mar 15, 2026Many registration problems are ill-posed in homogeneous or noisy regions, and dense voxel-wise decoders can be unnecessarily high-dimensional. A sparse control-point parameterisation provides a compact, smooth deformation representation while reducing memory and improving stability. This work investigates the required control points for learning-based registration network development. We present GridReg, a learning-based registration framework that replaces dense voxel-wise decoding with displacement predictions at a sparse grid of control points. This design substantially cuts the parameter count and memory while retaining registration accuracy. Multiscale 3D encoder feature maps are flattened into a 1D token sequence with positional encoding to retain spatial context. The model then predicts a sparse gridded deformation field using a cross-attention module. We further introduce grid-adaptive training, enabling an adaptive model to operate at multiple grid sizes at inference without retraining. This work quantitatively demonstrates the benefits of using sparse grids. Using three data sets for registering prostate gland, pelvic organs and neurological structures, the results suggested a significant improvement with the usage of grid-controled displacement field. Alternatively, the superior registration performance was obtained using the proposed approach, with a similar or less computational cost, compared with existing algorithms that predict DDFs or displacements sampled on scattered key points.
Deep EM with Hierarchical Latent Label Modelling for Multi-Site Prostate Lesion Segmentation
Mar 15, 2026Label variability is a major challenge for prostate lesion segmentation. In multi-site datasets, annotations often reflect centre-specific contouring protocols, causing segmentation networks to overfit to local styles and generalise poorly to unseen sites in inference. We treat each observed annotation as a noisy observation of an underlying latent 'clean' lesion mask, and propose a hierarchical expectation-maximisation (HierEM) framework that alternates between: (1) inferring a voxel-wise posterior distribution over the latent mask, and (2) training a CNN using this posterior as a soft target and estimate site-specific sensitivity and specificity under a hierarchical prior. This hierarchical prior decomposes label-quality into a global mean with site- and case-level deviations, reducing site-specific bias by penalising the likelihood term contributed only by site deviations. Experiments on three cohorts demonstrate that the proposed hierarchical EM framework enhances cross-site generalisation compared to state-of-the-art methods. For pooled-dataset evaluation, the per-site mean DSC ranges from 29.50% to 39.69%; for leave-one-site-out generalisation, it ranges from 27.91% to 32.67%, yielding statistically significant improvements over comparison methods (p<0.039). The method also produces interpretable per-site latent label-quality estimates (sensitivity alpha ranges from 31.5% to 47.3% at specificity beta approximates 0.99), supporting post-hoc analyses of cross-site annotation variability. These results indicate that explicitly modelling site-dependent annotation can improve cross-site generalisation.
ProFound: A moderate-sized vision foundation model for multi-task prostate imaging
Mar 04, 2026Many diagnostic and therapeutic clinical tasks for prostate cancer increasingly rely on multi-parametric MRI. Automating these tasks is challenging because they necessitate expert interpretations, which are difficult to scale to capitalise on modern deep learning. Although modern automated systems achieve expert-level performance in isolated tasks, their general clinical utility remains limited by the requirement of large task-specific labelled datasets. In this paper, we present ProFound, a domain-specialised vision foundation model for volumetric prostate mpMRI. ProFound is pre-trained using several variants of self-supervised approaches on a diverse, multi-institutional collection of 5,000 patients, with a total of over 22,000 unique 3D MRI volumes (over 1,800,000 2D image slices). We conducted a systematic evaluation of ProFound across a broad spectrum of $11$ downstream clinical tasks on over 3,000 independent patients, including prostate cancer detection, Gleason grading, lesion localisation, gland volume estimation, zonal and surrounding structure segmentation. Experimental results demonstrate that finetuned ProFound consistently outperforms or remains competitive with state-of-the-art specialised models and existing medical vision foundation models trained/finetuned on the same data.
Understanding the Transfer Limits of Vision Foundation Models
Jan 22, 2026Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.
Tell2Reg: Establishing spatial correspondence between images by the same language prompts
Feb 05, 2025Spatial correspondence can be represented by pairs of segmented regions, such that the image registration networks aim to segment corresponding regions rather than predicting displacement fields or transformation parameters. In this work, we show that such a corresponding region pair can be predicted by the same language prompt on two different images using the pre-trained large multimodal models based on GroundingDINO and SAM. This enables a fully automated and training-free registration algorithm, potentially generalisable to a wide range of image registration tasks. In this paper, we present experimental results using one of the challenging tasks, registering inter-subject prostate MR images, which involves both highly variable intensity and morphology between patients. Tell2Reg is training-free, eliminating the need for costly and time-consuming data curation and labelling that was previously required for this registration task. This approach outperforms unsupervised learning-based registration methods tested, and has a performance comparable to weakly-supervised methods. Additional qualitative results are also presented to suggest that, for the first time, there is a potential correlation between language semantics and spatial correspondence, including the spatial invariance in language-prompted regions and the difference in language prompts between the obtained local and global correspondences. Code is available at https://github.com/yanwenCi/Tell2Reg.git.
SAMReg: SAM-enabled Image Registration with ROI-based Correspondence
Oct 17, 2024



This paper describes a new spatial correspondence representation based on paired regions-of-interest (ROIs), for medical image registration. The distinct properties of the proposed ROI-based correspondence are discussed, in the context of potential benefits in clinical applications following image registration, compared with alternative correspondence-representing approaches, such as those based on sampled displacements and spatial transformation functions. These benefits include a clear connection between learning-based image registration and segmentation, which in turn motivates two cases of image registration approaches using (pre-)trained segmentation networks. Based on the segment anything model (SAM), a vision foundation model for segmentation, we develop a new registration algorithm SAMReg, which does not require any training (or training data), gradient-based fine-tuning or prompt engineering. The proposed SAMReg models are evaluated across five real-world applications, including intra-subject registration tasks with cardiac MR and lung CT, challenging inter-subject registration scenarios with prostate MR and retinal imaging, and an additional evaluation with a non-clinical example with aerial image registration. The proposed methods outperform both intensity-based iterative algorithms and DDF-predicting learning-based networks across tested metrics including Dice and target registration errors on anatomical structures, and further demonstrates competitive performance compared to weakly-supervised registration approaches that rely on fully-segmented training data. Open source code and examples are available at: https://github.com/sqhuang0103/SAMReg.git.
Poisson Ordinal Network for Gleason Group Estimation Using Bi-Parametric MRI
Jul 08, 2024



The Gleason groups serve as the primary histological grading system for prostate cancer, providing crucial insights into the cancer's potential for growth and metastasis. In clinical practice, pathologists determine the Gleason groups based on specimens obtained from ultrasound-guided biopsies. In this study, we investigate the feasibility of directly estimating the Gleason groups from MRI scans to reduce otherwise required biopsies. We identify two characteristics of this task, ordinality and the resulting dependent yet unknown variances between Gleason groups. In addition to the inter- / intra- observer variability in a multi-step Gleason scoring process based on the interpretation of Gleason patterns, our MR-based prediction is also subject to specimen sampling variance and, to a lesser degree, varying MR imaging protocols. To address this challenge, we propose a novel Poisson ordinal network (PON). PONs model the prediction using a Poisson distribution and leverages Poisson encoding and Poisson focal loss to capture a learnable dependency between ordinal classes (here, Gleason groups), rather than relying solely on the numerical ground-truth (e.g. Gleason Groups 1-5 or Gleason Scores 6-10). To improve this modelling efficacy, PONs also employ contrastive learning with a memory bank to regularise intra-class variance, decoupling the memory requirement of contrast learning from the batch size. Experimental results based on the images labelled by saturation biopsies from 265 prior-biopsy-blind patients, across two tasks demonstrate the superiority and effectiveness of our proposed method.
One registration is worth two segmentations
May 17, 2024



The goal of image registration is to establish spatial correspondence between two or more images, traditionally through dense displacement fields (DDFs) or parametric transformations (e.g., rigid, affine, and splines). Rethinking the existing paradigms of achieving alignment via spatial transformations, we uncover an alternative but more intuitive correspondence representation: a set of corresponding regions-of-interest (ROI) pairs, which we demonstrate to have sufficient representational capability as other correspondence representation methods.Further, it is neither necessary nor sufficient for these ROIs to hold specific anatomical or semantic significance. In turn, we formulate image registration as searching for the same set of corresponding ROIs from both moving and fixed images - in other words, two multi-class segmentation tasks on a pair of images. For a general-purpose and practical implementation, we integrate the segment anything model (SAM) into our proposed algorithms, resulting in a SAM-enabled registration (SAMReg) that does not require any training data, gradient-based fine-tuning or engineered prompts. We experimentally show that the proposed SAMReg is capable of segmenting and matching multiple ROI pairs, which establish sufficiently accurate correspondences, in three clinical applications of registering prostate MR, cardiac MR and abdominal CT images. Based on metrics including Dice and target registration errors on anatomical structures, the proposed registration outperforms both intensity-based iterative algorithms and DDF-predicting learning-based networks, even yielding competitive performance with weakly-supervised registration which requires fully-segmented training data.
Meta-Learning Initializations for Interactive Medical Image Registration
Oct 27, 2022



We present a meta-learning framework for interactive medical image registration. Our proposed framework comprises three components: a learning-based medical image registration algorithm, a form of user interaction that refines registration at inference, and a meta-learning protocol that learns a rapidly adaptable network initialization. This paper describes a specific algorithm that implements the registration, interaction and meta-learning protocol for our exemplar clinical application: registration of magnetic resonance (MR) imaging to interactively acquired, sparsely-sampled transrectal ultrasound (TRUS) images. Our approach obtains comparable registration error (4.26 mm) to the best-performing non-interactive learning-based 3D-to-3D method (3.97 mm) while requiring only a fraction of the data, and occurring in real-time during acquisition. Applying sparsely sampled data to non-interactive methods yields higher registration errors (6.26 mm), demonstrating the effectiveness of interactive MR-TRUS registration, which may be applied intraoperatively given the real-time nature of the adaptation process.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022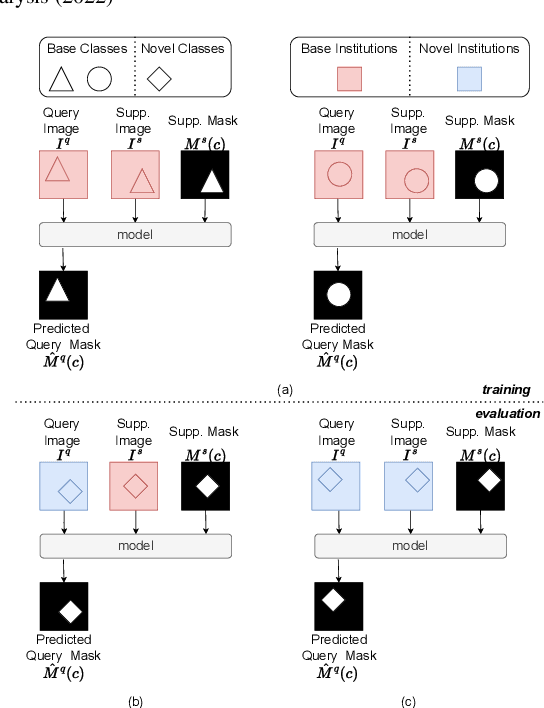

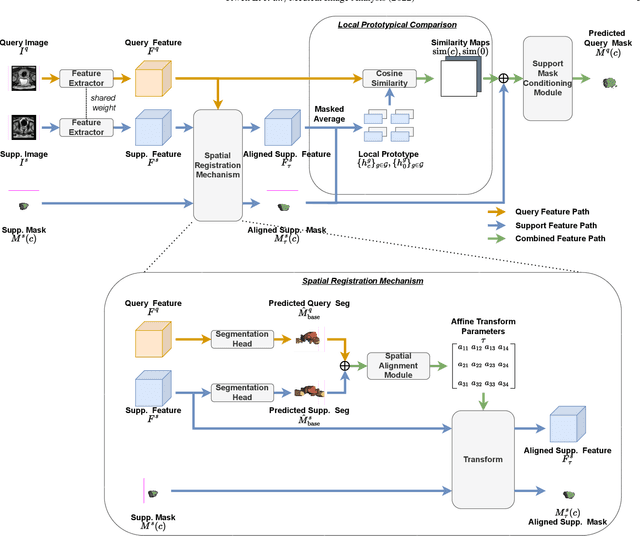

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.