 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Control to Foresight: Simulation as a New Paradigm for Human-Agent Collaboration
Mar 12, 2026Large Language Models (LLMs) are increasingly used to power autonomous agents for complex, multi-step tasks. However, human-agent interaction remains pointwise and reactive: users approve or correct individual actions to mitigate immediate risks, without visibility into subsequent consequences. This forces users to mentally simulate long-term effects, a cognitively demanding and often inaccurate process. Users have control over individual steps but lack the foresight to make informed decisions. We argue that effective collaboration requires foresight, not just control. We propose simulation-in-the-loop, an interaction paradigm that enables users and agents to explore simulated future trajectories before committing to decisions. Simulation transforms intervention from reactive guesswork into informed exploration, while helping users discover latent constraints and preferences along the way. This perspective paper characterizes the limitations of current paradigms, introduces a conceptual framework for simulation-based collaboration, and illustrates its potential through concrete human-agent collaboration scenarios.
Transferable XAI: Relating Understanding Across Domains with Explanation Transfer
Feb 14, 2026Current Explainable AI (XAI) focuses on explaining a single application, but when encountering related applications, users may rely on their prior understanding from previous explanations. This leads to either overgeneralization and AI overreliance, or burdensome independent memorization. Indeed, related decision tasks can share explanatory factors, but with some notable differences; e.g., body mass index (BMI) affects the risks for heart disease and diabetes at the same rate, but chest pain is more indicative of heart disease. Similarly, models using different attributes for the same task still share signals; e.g., temperature and pressure affect air pollution but in opposite directions due to the ideal gas law. Leveraging transfer of learning, we propose Transferable XAI to enable users to transfer understanding across related domains by explaining the relationship between domain explanations using a general affine transformation framework applied to linear factor explanations. The framework supports explanation transfer across various domain types: translation for data subspace (subsuming prior work on Incremental XAI), scaling for decision task, and mapping for attributes. Focusing on task and attributes domain types, in formative and summative user studies, we investigated how well participants could understand AI decisions from one domain to another. Compared to single-domain and domain-independent explanations, Transferable XAI was the most helpful for understanding the second domain, leading to the best decision faithfulness, factor recall, and ability to relate explanations between domains. This framework contributes to improving the reusability of explanations across related AI applications by explaining factor relationships between subspaces, tasks, and attributes.
Incremental XAI: Memorable Understanding of AI with Incremental Explanations
Apr 10, 2024



Many explainable AI (XAI) techniques strive for interpretability by providing concise salient information, such as sparse linear factors. However, users either only see inaccurate global explanations, or highly-varying local explanations. We propose to provide more detailed explanations by leveraging the human cognitive capacity to accumulate knowledge by incrementally receiving more details. Focusing on linear factor explanations (factors $\times$ values = outcome), we introduce Incremental XAI to automatically partition explanations for general and atypical instances by providing Base + Incremental factors to help users read and remember more faithful explanations. Memorability is improved by reusing base factors and reducing the number of factors shown in atypical cases. In modeling, formative, and summative user studies, we evaluated the faithfulness, memorability and understandability of Incremental XAI against baseline explanation methods. This work contributes towards more usable explanation that users can better ingrain to facilitate intuitive engagement with AI.
IRIS: Interpretable Rubric-Informed Segmentation for Action Quality Assessment
Mar 16, 2023



AI-driven Action Quality Assessment (AQA) of sports videos can mimic Olympic judges to help score performances as a second opinion or for training. However, these AI methods are uninterpretable and do not justify their scores, which is important for algorithmic accountability. Indeed, to account for their decisions, instead of scoring subjectively, sports judges use a consistent set of criteria - rubric - on multiple actions in each performance sequence. Therefore, we propose IRIS to perform Interpretable Rubric-Informed Segmentation on action sequences for AQA. We investigated IRIS for scoring videos of figure skating performance. IRIS predicts (1) action segments, (2) technical element score differences of each segment relative to base scores, (3) multiple program component scores, and (4) the summed final score. In a modeling study, we found that IRIS performs better than non-interpretable, state-of-the-art models. In a formative user study, practicing figure skaters agreed with the rubric-informed explanations, found them useful, and trusted AI judgments more. This work highlights the importance of using judgment rubrics to account for AI decisions.
RePrompt: Automatic Prompt Editing to Refine AI-Generative Art Towards Precise Expressions
Feb 25, 2023



Generative AI models have shown impressive ability to produce images with text prompts, which could benefit creativity in visual art creation and self-expression. However, it is unclear how precisely the generated images express contexts and emotions from the input texts. We explored the emotional expressiveness of AI-generated images and developed RePrompt, an automatic method to refine text prompts toward precise expression of the generated images. Inspired by crowdsourced editing strategies, we curated intuitive text features, such as the number and concreteness of nouns, and trained a proxy model to analyze the feature effects on the AI-generated image. With model explanations of the proxy model, we curated a rubric to adjust text prompts to optimize image generation for precise emotion expression. We conducted simulation and user studies, which showed that RePrompt significantly improves the emotional expressiveness of AI-generated images, especially for negative emotions.
Diagrammatization: Rationalizing with diagrammatic AI explanations for abductive reasoning on hypotheses
Feb 02, 2023



Many visualizations have been developed for explainable AI (XAI), but they often require further reasoning by users to interpret. We argue that XAI should support abductive reasoning - inference to the best explanation - with diagrammatic reasoning to convey hypothesis generation and evaluation. Inspired by Peircean diagrammatic reasoning and the 5-step abduction process, we propose Diagrammatization, an approach to provide diagrammatic, abductive explanations based on domain hypotheses. We implemented DiagramNet for a clinical application to predict diagnoses from heart auscultation, and explain with shape-based murmur diagrams. In modeling studies, we found that DiagramNet not only provides faithful murmur shape explanations, but also has better prediction performance than baseline models. We further demonstrate the usefulness of diagrammatic explanations in a qualitative user study with medical students, showing that clinically-relevant, diagrammatic explanations are preferred over technical saliency map explanations. This work contributes insights into providing domain-conventional abductive explanations for user-centric XAI.
Debiased-CAM to mitigate systematic error with faithful visual explanations of machine learning
Jan 30, 2022Model explanations such as saliency maps can improve user trust in AI by highlighting important features for a prediction. However, these become distorted and misleading when explaining predictions of images that are subject to systematic error (bias). Furthermore, the distortions persist despite model fine-tuning on images biased by different factors (blur, color temperature, day/night). We present Debiased-CAM to recover explanation faithfulness across various bias types and levels by training a multi-input, multi-task model with auxiliary tasks for explanation and bias level predictions. In simulation studies, the approach not only enhanced prediction accuracy, but also generated highly faithful explanations about these predictions as if the images were unbiased. In user studies, debiased explanations improved user task performance, perceived truthfulness and perceived helpfulness. Debiased training can provide a versatile platform for robust performance and explanation faithfulness for a wide range of applications with data biases.
Towards Relatable Explainable AI with the Perceptual Process
Dec 28, 2021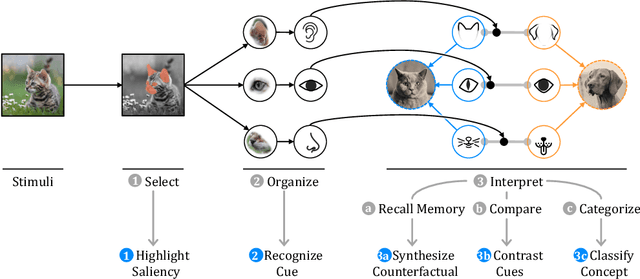
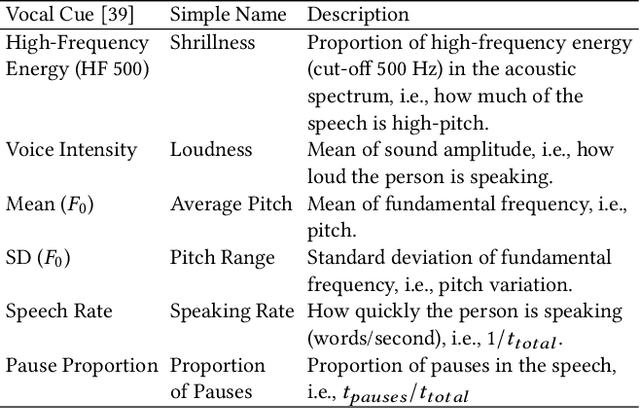
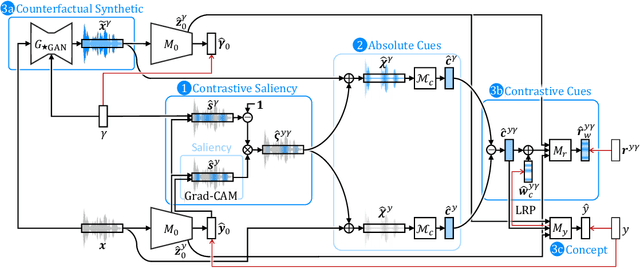
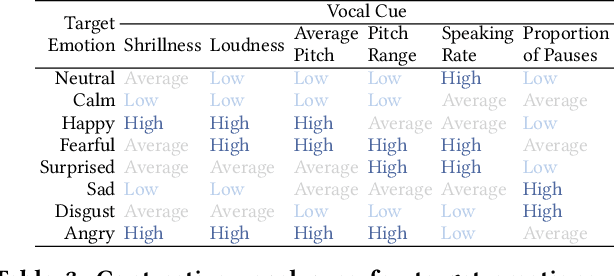
Machine learning models need to provide contrastive explanations, since people often seek to understand why a puzzling prediction occurred instead of some expected outcome. Current contrastive explanations are rudimentary comparisons between examples or raw features, which remain difficult to interpret, since they lack semantic meaning. We argue that explanations must be more relatable to other concepts, hypotheticals, and associations. Inspired by the perceptual process from cognitive psychology, we propose the XAI Perceptual Processing Framework and RexNet model for relatable explainable AI with Contrastive Saliency, Counterfactual Synthetic, and Contrastive Cues explanations. We investigated the application of vocal emotion recognition, and implemented a modular multi-task deep neural network to predict and explain emotions from speech. From think-aloud and controlled studies, we found that counterfactual explanations were useful and further enhanced with semantic cues, but not saliency explanations. This work provides insights into providing and evaluating relatable contrastive explainable AI for perception applications.
Interpretable Directed Diversity: Leveraging Model Explanations for Iterative Crowd Ideation
Sep 21, 2021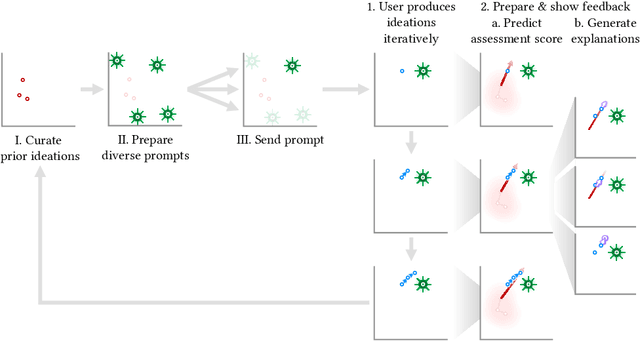
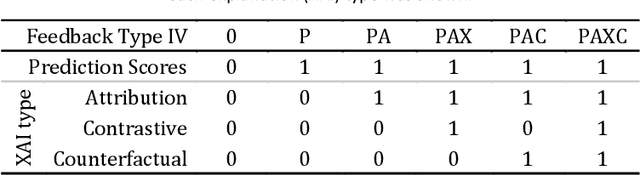
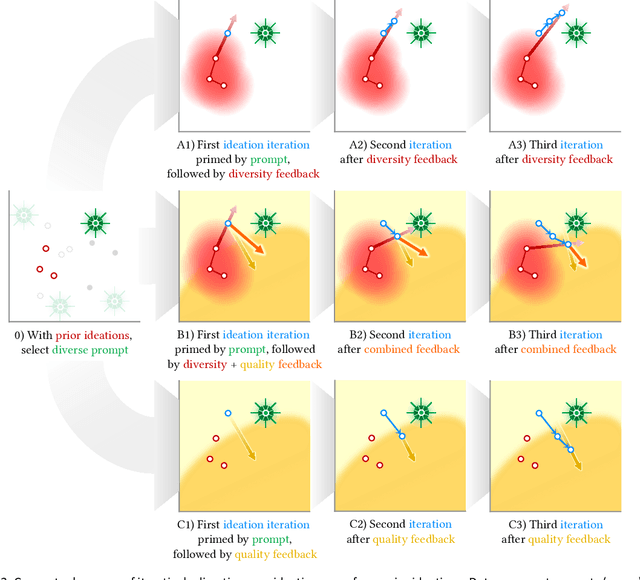
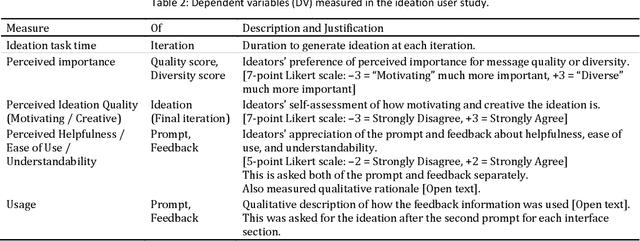
Feedback can help crowdworkers to improve their ideations. However, current feedback methods require human assessment from facilitators or peers. This is not scalable to large crowds. We propose Interpretable Directed Diversity to automatically predict ideation quality and diversity scores, and provide AI explanations - Attribution, Contrastive Attribution, and Counterfactual Suggestions - for deeper feedback on why ideations were scored (low), and how to get higher scores. These explanations provide multi-faceted feedback as users iteratively improve their ideation. We conducted think aloud and controlled user studies to understand how various explanations are used, and evaluated whether explanations improve ideation diversity and quality. Users appreciated that explanation feedback helped focus their efforts and provided directions for improvement. This resulted in explanations improving diversity compared to no feedback or feedback with predictions only. Hence, our approach opens opportunities for explainable AI towards scalable and rich feedback for iterative crowd ideation.
Exploiting Explanations for Model Inversion Attacks
Apr 26, 2021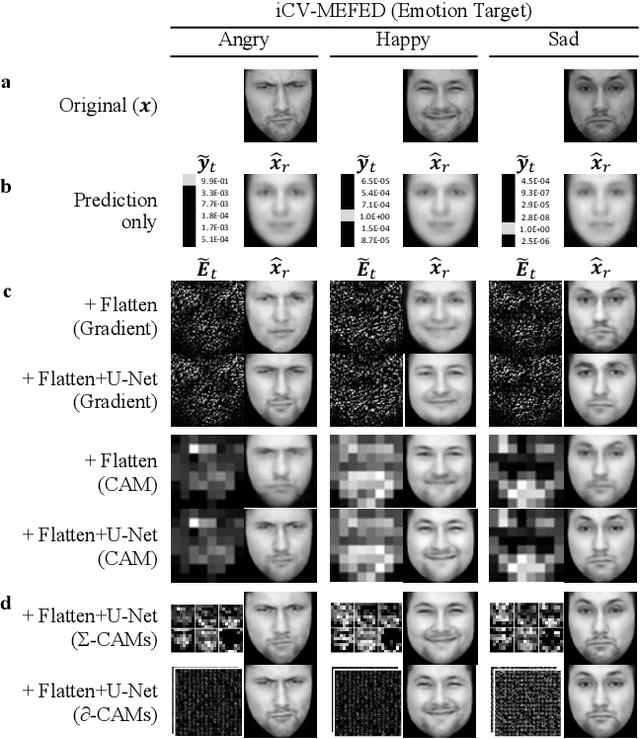
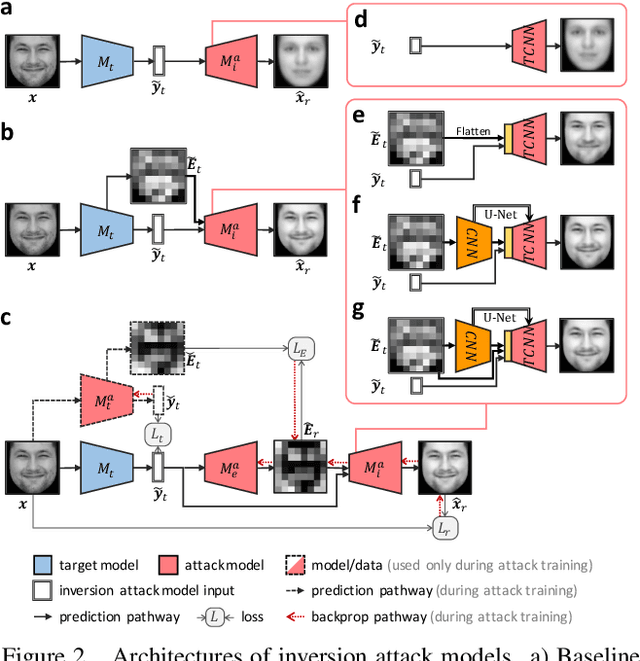

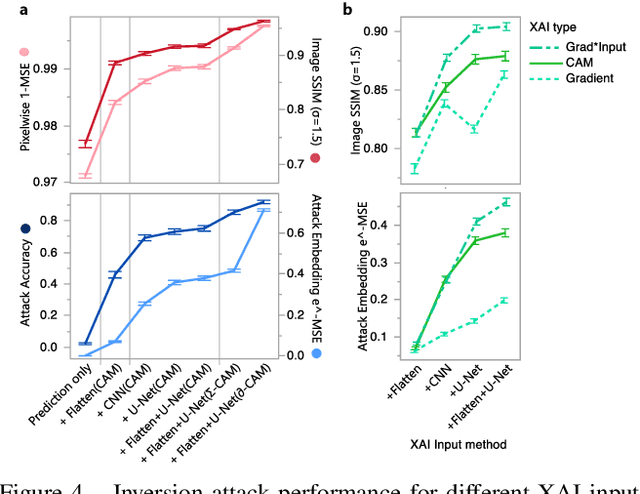
The successful deployment of artificial intelligence (AI) in many domains from healthcare to hiring requires their responsible use, particularly in model explanations and privacy. Explainable artificial intelligence (XAI) provides more information to help users to understand model decisions, yet this additional knowledge exposes additional risks for privacy attacks. Hence, providing explanation harms privacy. We study this risk for image-based model inversion attacks and identified several attack architectures with increasing performance to reconstruct private image data from model explanations. We have developed several multi-modal transposed CNN architectures that achieve significantly higher inversion performance than using the target model prediction only. These XAI-aware inversion models were designed to exploit the spatial knowledge in image explanations. To understand which explanations have higher privacy risk, we analyzed how various explanation types and factors influence inversion performance. In spite of some models not providing explanations, we further demonstrate increased inversion performance even for non-explainable target models by exploiting explanations of surrogate models through attention transfer. This method first inverts an explanation from the target prediction, then reconstructs the target image. These threats highlight the urgent and significant privacy risks of explanations and calls attention for new privacy preservation techniques that balance the dual-requirement for AI explainability and privacy.