 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Global Relation Modeling and Refinement for Bottom-Up Human Pose Estimation
Mar 27, 2023
In this paper, we concern on the bottom-up paradigm in multi-person pose estimation (MPPE). Most previous bottom-up methods try to consider the relation of instances to identify different body parts during the post processing, while ignoring to model the relation among instances or environment in the feature learning process. In addition, most existing works adopt the operations of upsampling and downsampling. During the sampling process, there will be a problem of misalignment with the source features, resulting in deviations in the keypoint features learned by the model. To overcome the above limitations, we propose a convolutional neural network for bottom-up human pose estimation. It invovles two basic modules: (i) Global Relation Modeling (GRM) module globally learns relation (e.g., environment context, instance interactive information) among region of image by fusing multiple stages features in the feature learning process. It combines with the spatial-channel attention mechanism, which focuses on achieving adaptability in spatial and channel dimensions. (ii) Multi-branch Feature Align (MFA) module aggregates features from multiple branches to align fused feature and obtain refined local keypoint representation. Our model has the ability to focus on different granularity from local to global regions, which significantly boosts the performance of the multi-person pose estimation. Our results on the COCO and CrowdPose datasets demonstrate that it is an efficient framework for multi-person pose estimation.
Detecting Everything in the Open World: Towards Universal Object Detection
Mar 27, 2023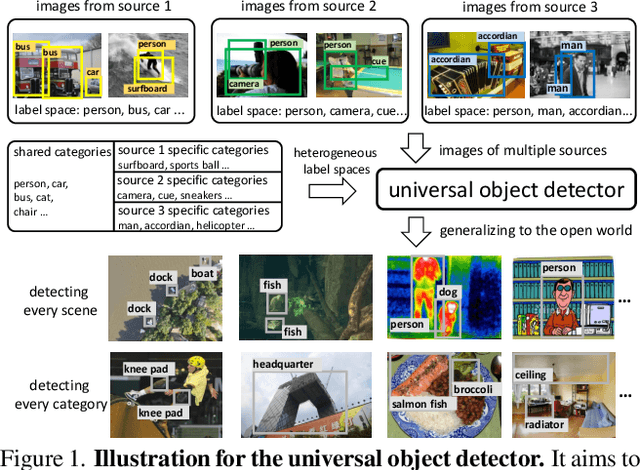
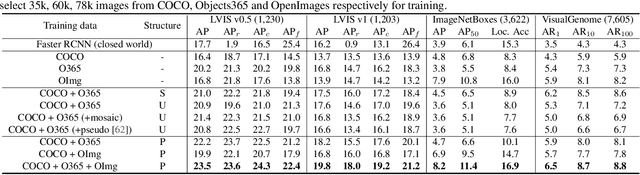
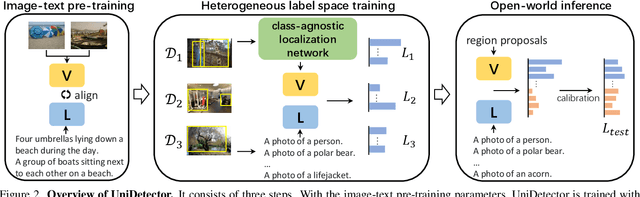
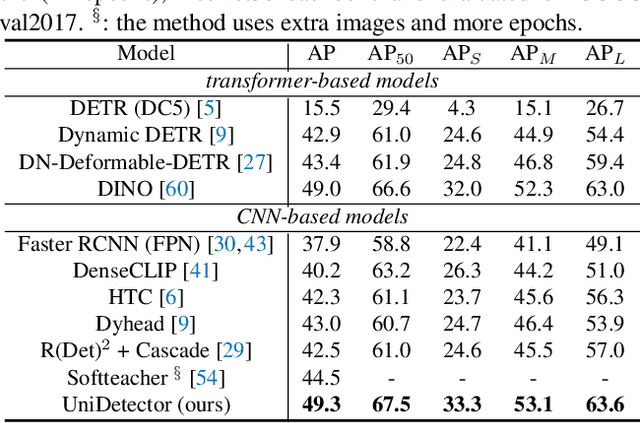
In this paper, we formally address universal object detection, which aims to detect every scene and predict every category. The dependence on human annotations, the limited visual information, and the novel categories in the open world severely restrict the universality of traditional detectors. We propose UniDetector, a universal object detector that has the ability to recognize enormous categories in the open world. The critical points for the universality of UniDetector are: 1) it leverages images of multiple sources and heterogeneous label spaces for training through the alignment of image and text spaces, which guarantees sufficient information for universal representations. 2) it generalizes to the open world easily while keeping the balance between seen and unseen classes, thanks to abundant information from both vision and language modalities. 3) it further promotes the generalization ability to novel categories through our proposed decoupling training manner and probability calibration. These contributions allow UniDetector to detect over 7k categories, the largest measurable category size so far, with only about 500 classes participating in training. Our UniDetector behaves the strong zero-shot generalization ability on large-vocabulary datasets like LVIS, ImageNetBoxes, and VisualGenome - it surpasses the traditional supervised baselines by more than 4\% on average without seeing any corresponding images. On 13 public detection datasets with various scenes, UniDetector also achieves state-of-the-art performance with only a 3\% amount of training data.
3D Surface Reconstruction in the Wild by Deforming Shape Priors from Synthetic Data
Feb 24, 2023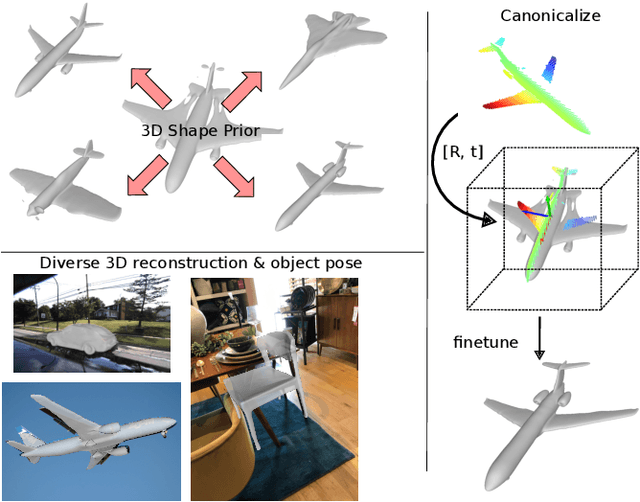
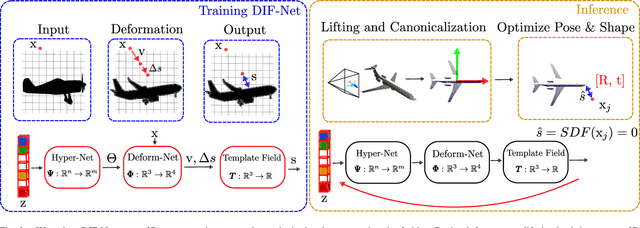


Reconstructing the underlying 3D surface of an object from a single image is a challenging problem that has received extensive attention from the computer vision community. Many learning-based approaches tackle this problem by learning a 3D shape prior from either ground truth 3D data or multi-view observations. To achieve state-of-the-art results, these methods assume that the objects are specified with respect to a fixed canonical coordinate frame, where instances of the same category are perfectly aligned. In this work, we present a new method for joint category-specific 3D reconstruction and object pose estimation from a single image. We show that one can leverage shape priors learned on purely synthetic 3D data together with a point cloud pose canonicalization method to achieve high-quality 3D reconstruction in the wild. Given a single depth image at test time, we first transform this partial point cloud into a learned canonical frame. Then, we use a neural deformation field to reconstruct the 3D surface of the object. Finally, we jointly optimize object pose and 3D shape to fit the partial depth observation. Our approach achieves state-of-the-art reconstruction performance across several real-world datasets, even when trained only on synthetic data. We further show that our method generalizes to different input modalities, from dense depth images to sparse and noisy LIDAR scans.
Linearly Mapping from Image to Text Space
Sep 30, 2022
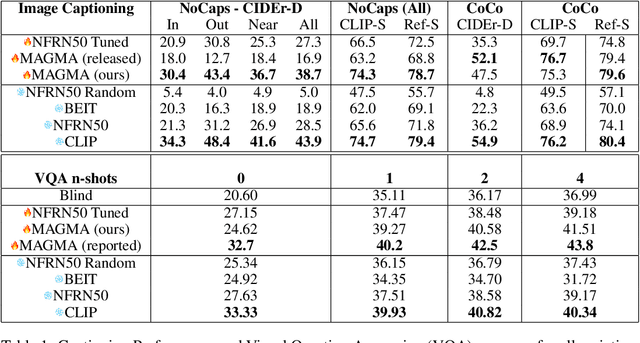

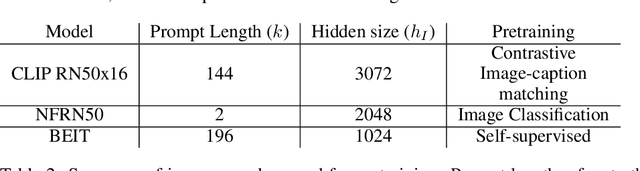
The extent to which text-only language models (LMs) learn to represent the physical, non-linguistic world is an open question. Prior work has shown that pretrained LMs can be taught to ``understand'' visual inputs when the models' parameters are updated on image captioning tasks. We test a stronger hypothesis: that the conceptual representations learned by text-only models are functionally equivalent (up to a linear transformation) to those learned by models trained on vision tasks. Specifically, we show that the image representations from vision models can be transferred as continuous prompts to frozen LMs by training only a single linear projection. Using these to prompt the LM achieves competitive performance on captioning and visual question answering tasks compared to models that tune both the image encoder and text decoder (such as the MAGMA model). We compare three image encoders with increasing amounts of linguistic supervision seen during pretraining: BEIT (no linguistic information), NF-ResNET (lexical category information), and CLIP (full natural language descriptions). We find that all three encoders perform equally well at transferring visual property information to the language model (e.g., whether an animal is large or small), but that image encoders pretrained with linguistic supervision more saliently encode category information (e.g., distinguishing hippo vs.\ elephant) and thus perform significantly better on benchmark language-and-vision tasks. Our results indicate that LMs encode conceptual information structurally similarly to vision-based models, even those that are solely trained on images.
Image augmentation with conformal mappings for a convolutional neural network
Dec 10, 2022

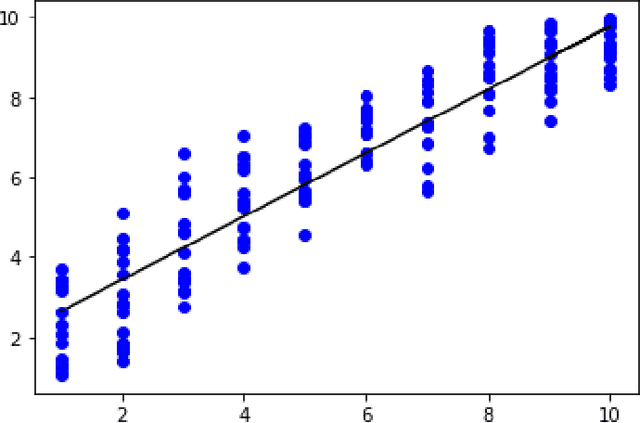
For augmentation of the square-shaped image data of a convolutional neural network (CNN), we introduce a new method, in which the original images are mapped onto a disk with a conformal mapping, rotated around the center of this disk and mapped under such a M\"obius transformation that preserves the disk, and then mapped back onto their original square shape. This process does not result the loss of information caused by removing areas from near the edges of the original images unlike the typical transformations used in the data augmentation for a CNN. We offer here the formulas of all the mappings needed together with detailed instructions how to write a code for transforming the images. The new method is also tested with simulated data and, according the results, using this method to augment the training data of 10 images into 40 images decreases the amount of the error in the predictions by a CNN for a test set of 160 images in a statistically significant way (p-value=0.0360).
Efficient Diffusion Training via Min-SNR Weighting Strategy
Mar 16, 2023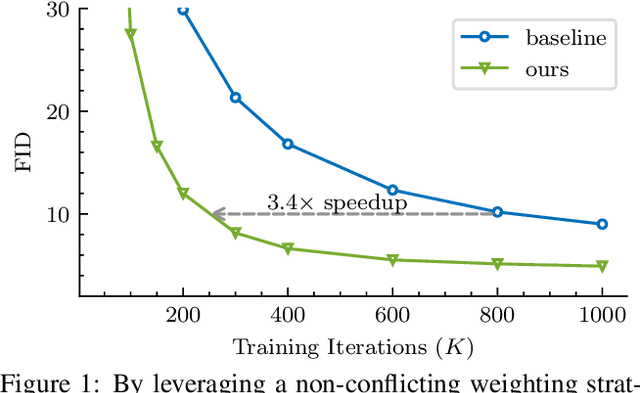
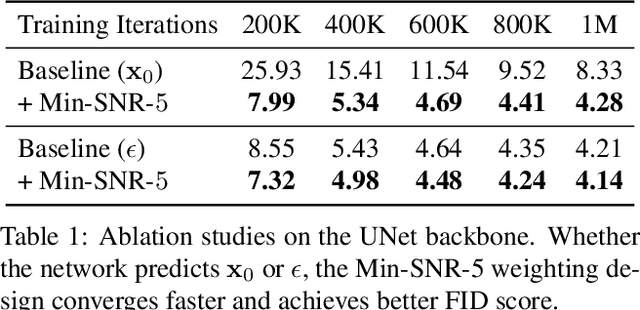
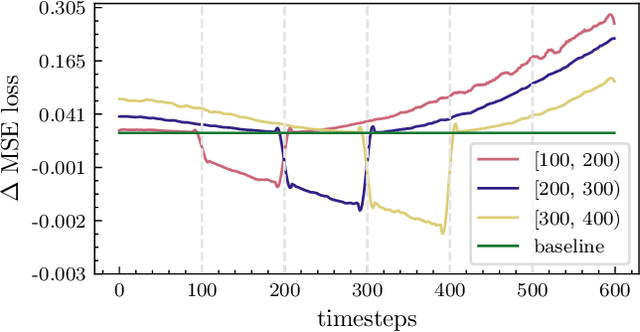
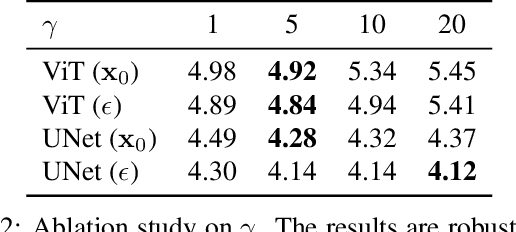
Denoising diffusion models have been a mainstream approach for image generation, however, training these models often suffers from slow convergence. In this paper, we discovered that the slow convergence is partly due to conflicting optimization directions between timesteps. To address this issue, we treat the diffusion training as a multi-task learning problem, and introduce a simple yet effective approach referred to as Min-SNR-$\gamma$. This method adapts loss weights of timesteps based on clamped signal-to-noise ratios, which effectively balances the conflicts among timesteps. Our results demonstrate a significant improvement in converging speed, 3.4$\times$ faster than previous weighting strategies. It is also more effective, achieving a new record FID score of 2.06 on the ImageNet $256\times256$ benchmark using smaller architectures than that employed in previous state-of-the-art.
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection trough attention deep learning for CT Scan
Mar 16, 2023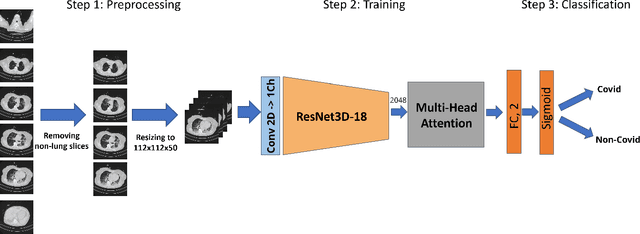
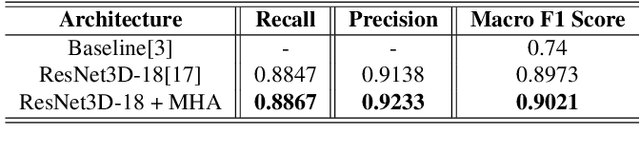
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
Vision Transformer for Adaptive Image Transmission over MIMO Channels
Oct 27, 2022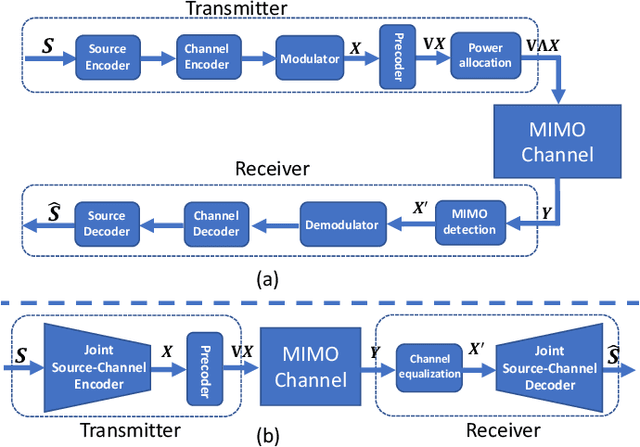
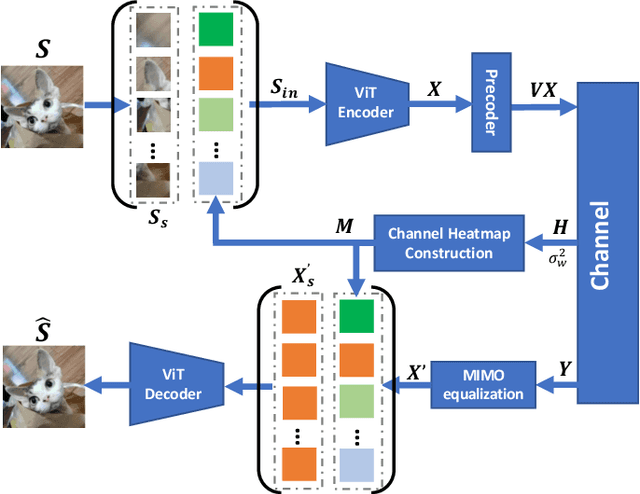
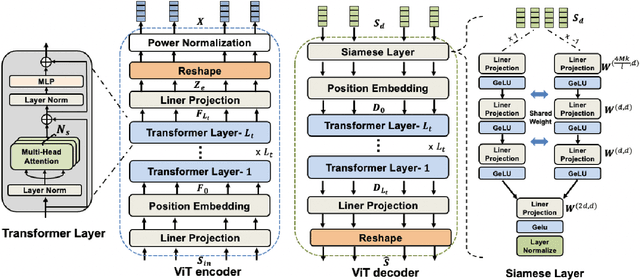
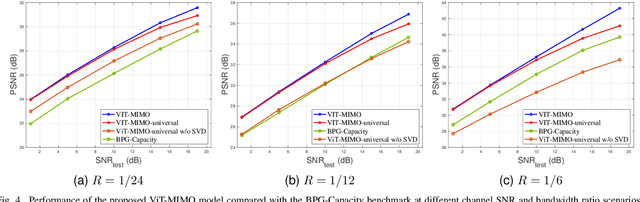
This paper presents a vision transformer (ViT) based joint source and channel coding (JSCC) scheme for wireless image transmission over multiple-input multiple-output (MIMO) systems, called ViT-MIMO. The proposed ViT-MIMO architecture, in addition to outperforming separation-based benchmarks, can flexibly adapt to different channel conditions without requiring retraining. Specifically, exploiting the self-attention mechanism of the ViT enables the proposed ViT-MIMO model to adaptively learn the feature mapping and power allocation based on the source image and channel conditions. Numerical experiments show that ViT-MIMO can significantly improve the transmission quality cross a large variety of scenarios, including varying channel conditions, making it an attractive solution for emerging semantic communication systems.
Depth- and Semantics-aware Multi-modal Domain Translation: Generating 3D Panoramic Color Images from LiDAR Point Clouds
Feb 15, 2023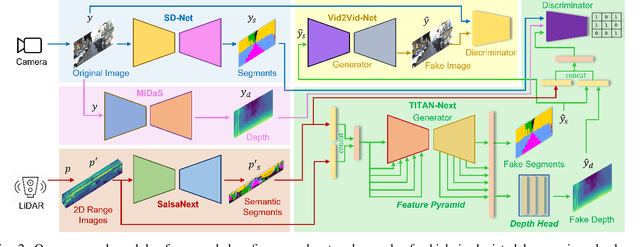



This work presents a new depth- and semantics-aware conditional generative model, named TITAN-Next, for cross-domain image-to-image translation in a multi-modal setup between LiDAR and camera sensors. The proposed model leverages scene semantics as a mid-level representation and is able to translate raw LiDAR point clouds to RGB-D camera images by solely relying on semantic scene segments. We claim that this is the first framework of its kind and it has practical applications in autonomous vehicles such as providing a fail-safe mechanism and augmenting available data in the target image domain. The proposed model is evaluated on the large-scale and challenging Semantic-KITTI dataset, and experimental findings show that it considerably outperforms the original TITAN-Net and other strong baselines by 23.7$\%$ margin in terms of IoU.
Spatio-Temporal Pixel-Level Contrastive Learning-based Source-Free Domain Adaptation for Video Semantic Segmentation
Mar 25, 2023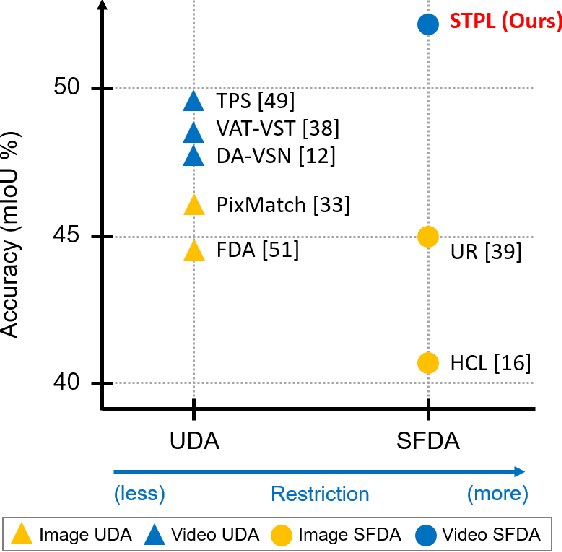

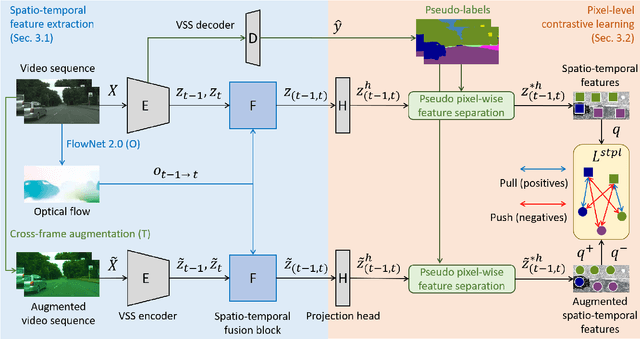
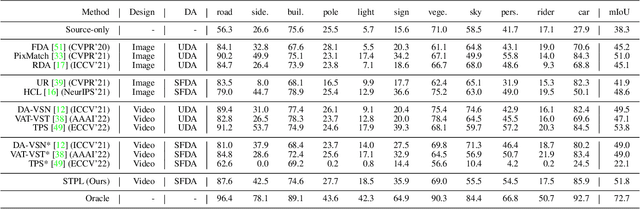
Unsupervised Domain Adaptation (UDA) of semantic segmentation transfers labeled source knowledge to an unlabeled target domain by relying on accessing both the source and target data. However, the access to source data is often restricted or infeasible in real-world scenarios. Under the source data restrictive circumstances, UDA is less practical. To address this, recent works have explored solutions under the Source-Free Domain Adaptation (SFDA) setup, which aims to adapt a source-trained model to the target domain without accessing source data. Still, existing SFDA approaches use only image-level information for adaptation, making them sub-optimal in video applications. This paper studies SFDA for Video Semantic Segmentation (VSS), where temporal information is leveraged to address video adaptation. Specifically, we propose Spatio-Temporal Pixel-Level (STPL) contrastive learning, a novel method that takes full advantage of spatio-temporal information to tackle the absence of source data better. STPL explicitly learns semantic correlations among pixels in the spatio-temporal space, providing strong self-supervision for adaptation to the unlabeled target domain. Extensive experiments show that STPL achieves state-of-the-art performance on VSS benchmarks compared to current UDA and SFDA approaches. Code is available at: https://github.com/shaoyuanlo/STPL