 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
One step closer to EEG based eye tracking
Mar 03, 2023

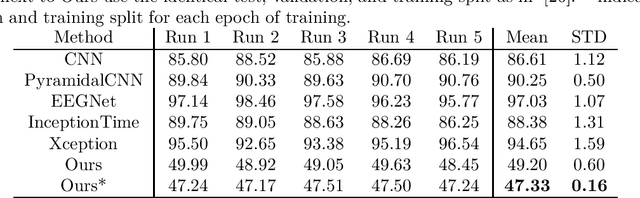

In this paper, we present two approaches and algorithms that adapt areas of interest We present a new deep neural network (DNN) that can be used to directly determine gaze position using EEG data. EEG-based eye tracking is a new and difficult research topic in the field of eye tracking, but it provides an alternative to image-based eye tracking with an input data set comparable to conventional image processing. The presented DNN exploits spatial dependencies of the EEG signal and uses convolutions similar to spatial filtering, which is used for preprocessing EEG signals. By this, we improve the direct gaze determination from the EEG signal compared to the state of the art by 3.5 cm MAE (Mean absolute error), but unfortunately still do not achieve a directly applicable system, since the inaccuracy is still significantly higher compared to image-based eye trackers. Link: https://es-cloud.cs.uni-tuebingen.de/d/8e2ab8c3fdd444e1a135/?p=%2FEEGGaze&mode=list
LIGHT: Joint Individual Building Extraction and Height Estimation from Satellite Images through a Unified Multitask Learning Network
Apr 03, 2023
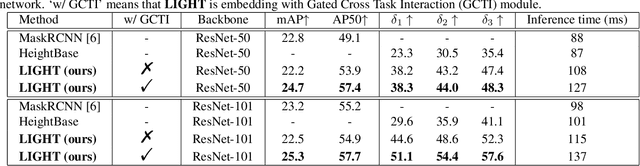
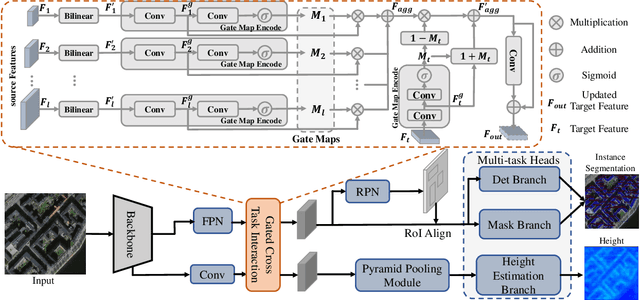

Building extraction and height estimation are two important basic tasks in remote sensing image interpretation, which are widely used in urban planning, real-world 3D construction, and other fields. Most of the existing research regards the two tasks as independent studies. Therefore the height information cannot be fully used to improve the accuracy of building extraction and vice versa. In this work, we combine the individuaL buIlding extraction and heiGHt estimation through a unified multiTask learning network (LIGHT) for the first time, which simultaneously outputs a height map, bounding boxes, and a segmentation mask map of buildings. Specifically, LIGHT consists of an instance segmentation branch and a height estimation branch. In particular, so as to effectively unify multi-scale feature branches and alleviate feature spans between branches, we propose a Gated Cross Task Interaction (GCTI) module that can efficiently perform feature interaction between branches. Experiments on the DFC2023 dataset show that our LIGHT can achieve superior performance, and our GCTI module with ResNet101 as the backbone can significantly improve the performance of multitask learning by 2.8% AP50 and 6.5% delta1, respectively.
TRAK: Attributing Model Behavior at Scale
Apr 03, 2023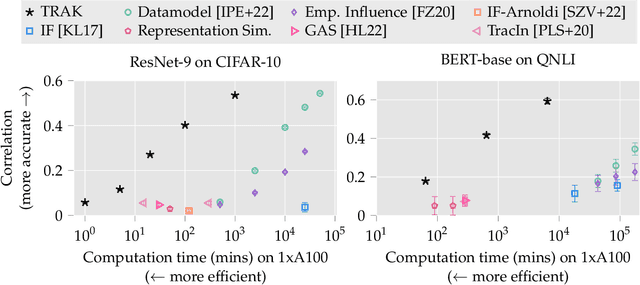
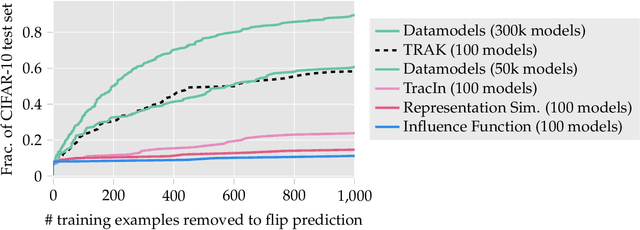
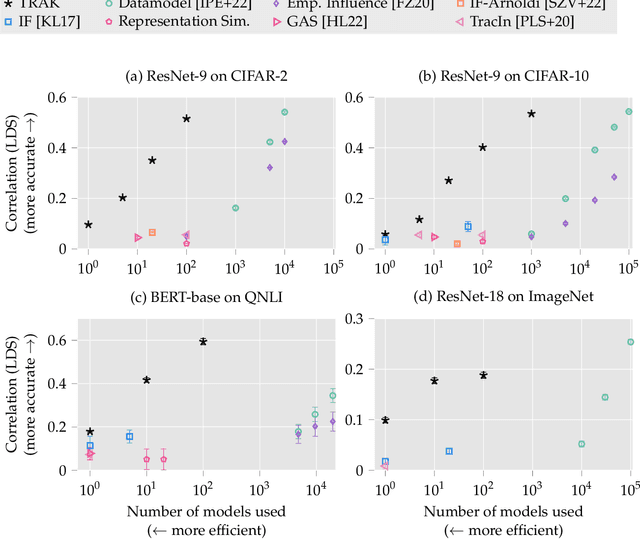

The goal of data attribution is to trace model predictions back to training data. Despite a long line of work towards this goal, existing approaches to data attribution tend to force users to choose between computational tractability and efficacy. That is, computationally tractable methods can struggle with accurately attributing model predictions in non-convex settings (e.g., in the context of deep neural networks), while methods that are effective in such regimes require training thousands of models, which makes them impractical for large models or datasets. In this work, we introduce TRAK (Tracing with the Randomly-projected After Kernel), a data attribution method that is both effective and computationally tractable for large-scale, differentiable models. In particular, by leveraging only a handful of trained models, TRAK can match the performance of attribution methods that require training thousands of models. We demonstrate the utility of TRAK across various modalities and scales: image classifiers trained on ImageNet, vision-language models (CLIP), and language models (BERT and mT5). We provide code for using TRAK (and reproducing our work) at https://github.com/MadryLab/trak .
Knowledge Accumulation in Continually Learned Representations and the Issue of Feature Forgetting
Apr 03, 2023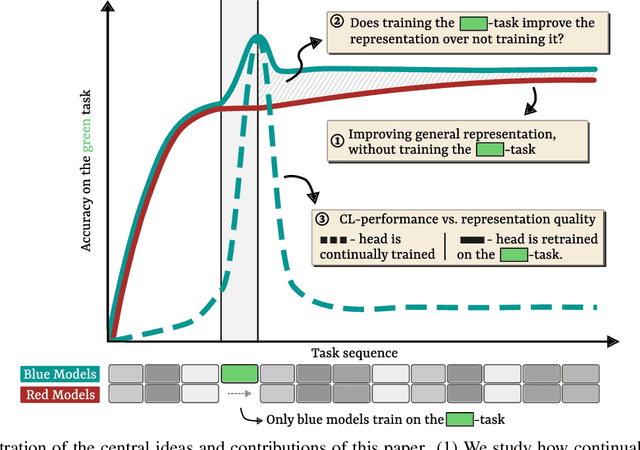

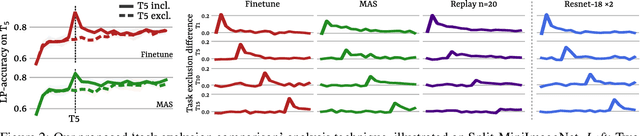
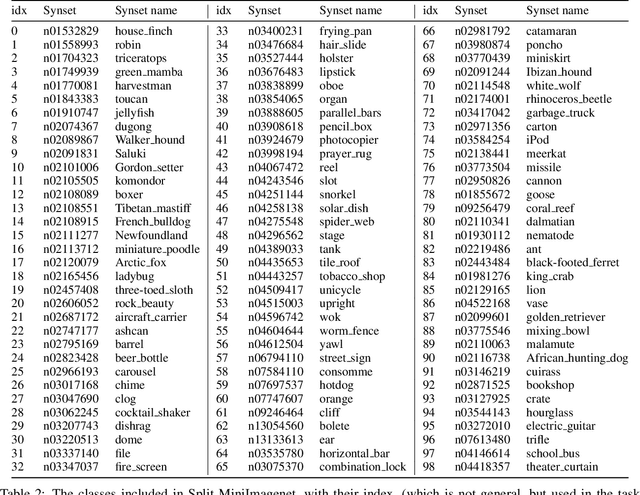
By default, neural networks learn on all training data at once. When such a model is trained on sequential chunks of new data, it tends to catastrophically forget how to handle old data. In this work we investigate how continual learners learn and forget representations. We observe two phenomena: knowledge accumulation, i.e. the improvement of a representation over time, and feature forgetting, i.e. the loss of task-specific representations. To better understand both phenomena, we introduce a new analysis technique called task exclusion comparison. If a model has seen a task and it has not forgotten all the task-specific features, then its representation for that task should be better than that of a model that was trained on similar tasks, but not that exact one. Our image classification experiments show that most task-specific features are quickly forgotten, in contrast to what has been suggested in the past. Further, we demonstrate how some continual learning methods, like replay, and ideas from representation learning affect a continually learned representation. We conclude by observing that representation quality is tightly correlated with continual learning performance.
MetaHead: An Engine to Create Realistic Digital Head
Apr 03, 2023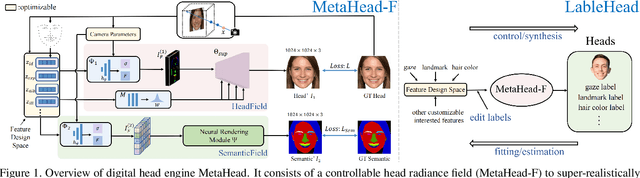
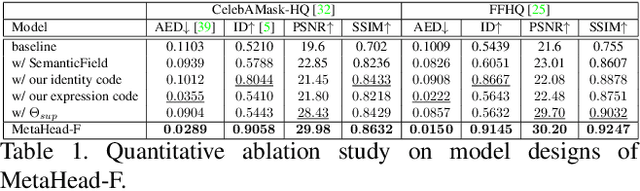
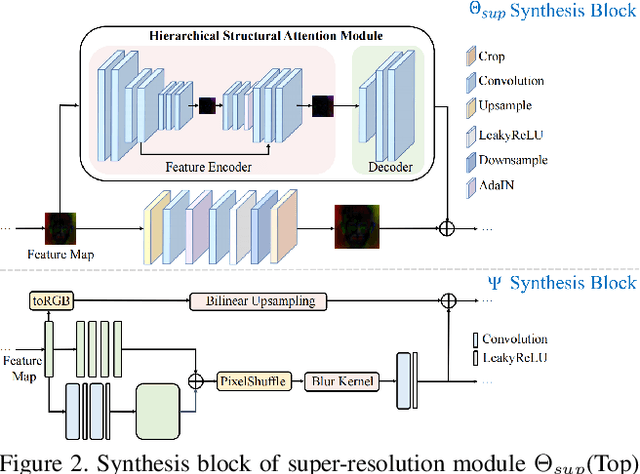
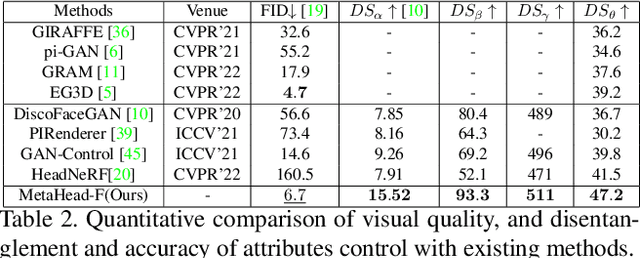
Collecting and labeling training data is one important step for learning-based methods because the process is time-consuming and biased. For face analysis tasks, although some generative models can be used to generate face data, they can only achieve a subset of generation diversity, reconstruction accuracy, 3D consistency, high-fidelity visual quality, and easy editability. One recent related work is the graphics-based generative method, but it can only render low realism head with high computation cost. In this paper, we propose MetaHead, a unified and full-featured controllable digital head engine, which consists of a controllable head radiance field(MetaHead-F) to super-realistically generate or reconstruct view-consistent 3D controllable digital heads and a generic top-down image generation framework LabelHead to generate digital heads consistent with the given customizable feature labels. Experiments validate that our controllable digital head engine achieves the state-of-the-art generation visual quality and reconstruction accuracy. Moreover, the generated labeled data can assist real training data and significantly surpass the labeled data generated by graphics-based methods in terms of training effect.
Unbiased Scene Graph Generation in Videos
Apr 03, 2023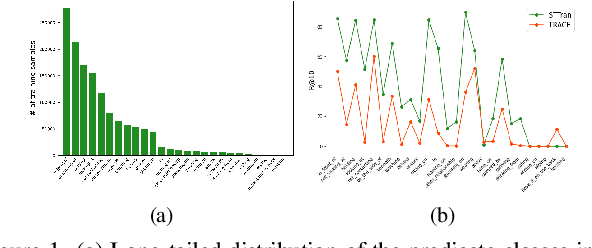
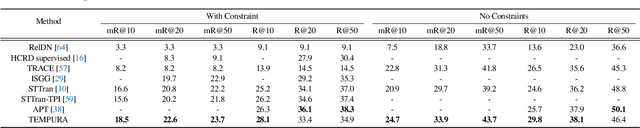
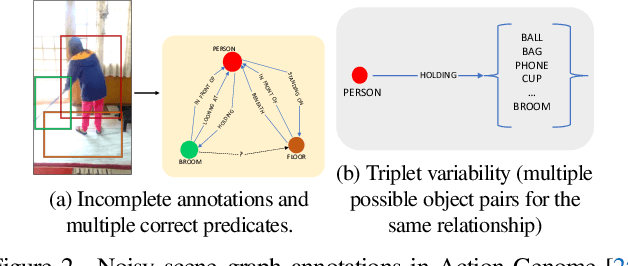

The task of dynamic scene graph generation (SGG) from videos is complicated and challenging due to the inherent dynamics of a scene, temporal fluctuation of model predictions, and the long-tailed distribution of the visual relationships in addition to the already existing challenges in image-based SGG. Existing methods for dynamic SGG have primarily focused on capturing spatio-temporal context using complex architectures without addressing the challenges mentioned above, especially the long-tailed distribution of relationships. This often leads to the generation of biased scene graphs. To address these challenges, we introduce a new framework called TEMPURA: TEmporal consistency and Memory Prototype guided UnceRtainty Attenuation for unbiased dynamic SGG. TEMPURA employs object-level temporal consistencies via transformer-based sequence modeling, learns to synthesize unbiased relationship representations using memory-guided training, and attenuates the predictive uncertainty of visual relations using a Gaussian Mixture Model (GMM). Extensive experiments demonstrate that our method achieves significant (up to 10% in some cases) performance gain over existing methods highlighting its superiority in generating more unbiased scene graphs.
On the Importance of Image Encoding in Automated Chest X-Ray Report Generation
Nov 24, 2022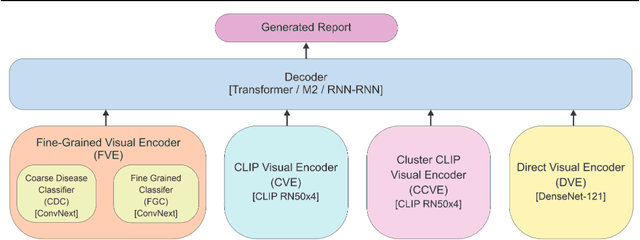
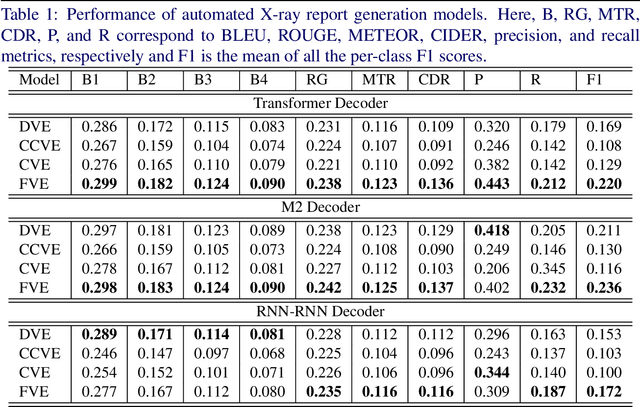
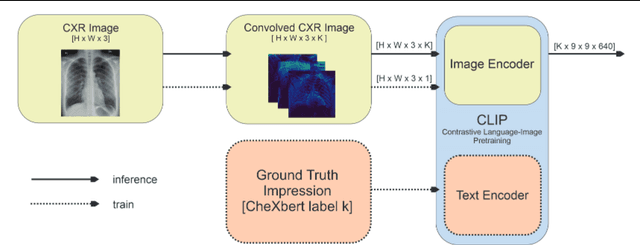
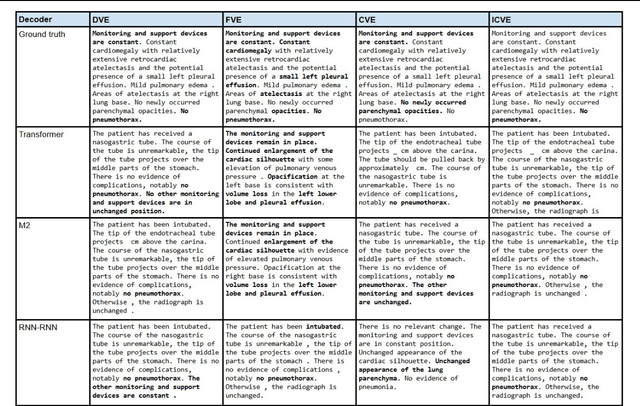
Chest X-ray is one of the most popular medical imaging modalities due to its accessibility and effectiveness. However, there is a chronic shortage of well-trained radiologists who can interpret these images and diagnose the patient's condition. Therefore, automated radiology report generation can be a very helpful tool in clinical practice. A typical report generation workflow consists of two main steps: (i) encoding the image into a latent space and (ii) generating the text of the report based on the latent image embedding. Many existing report generation techniques use a standard convolutional neural network (CNN) architecture for image encoding followed by a Transformer-based decoder for medical text generation. In most cases, CNN and the decoder are trained jointly in an end-to-end fashion. In this work, we primarily focus on understanding the relative importance of encoder and decoder components. Towards this end, we analyze four different image encoding approaches: direct, fine-grained, CLIP-based, and Cluster-CLIP-based encodings in conjunction with three different decoders on the large-scale MIMIC-CXR dataset. Among these encoders, the cluster CLIP visual encoder is a novel approach that aims to generate more discriminative and explainable representations. CLIP-based encoders produce comparable results to traditional CNN-based encoders in terms of NLP metrics, while fine-grained encoding outperforms all other encoders both in terms of NLP and clinical accuracy metrics, thereby validating the importance of image encoder to effectively extract semantic information. GitHub repository: https://github.com/mudabek/encoding-cxr-report-gen
Predictive Heterogeneity: Measures and Applications
Apr 01, 2023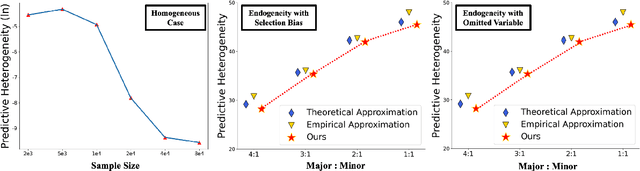

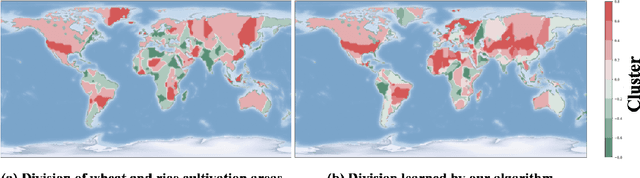
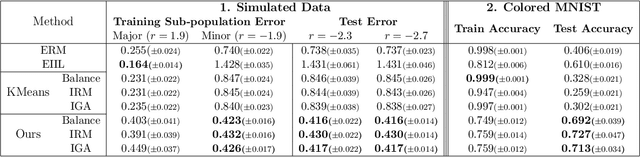
As an intrinsic and fundamental property of big data, data heterogeneity exists in a variety of real-world applications, such as precision medicine, autonomous driving, financial applications, etc. For machine learning algorithms, the ignorance of data heterogeneity will greatly hurt the generalization performance and the algorithmic fairness, since the prediction mechanisms among different sub-populations are likely to differ from each other. In this work, we focus on the data heterogeneity that affects the prediction of machine learning models, and firstly propose the \emph{usable predictive heterogeneity}, which takes into account the model capacity and computational constraints. We prove that it can be reliably estimated from finite data with probably approximately correct (PAC) bounds. Additionally, we design a bi-level optimization algorithm to explore the usable predictive heterogeneity from data. Empirically, the explored heterogeneity provides insights for sub-population divisions in income prediction, crop yield prediction and image classification tasks, and leveraging such heterogeneity benefits the out-of-distribution generalization performance.
Self-supervised video pretraining yields strong image representations
Oct 12, 2022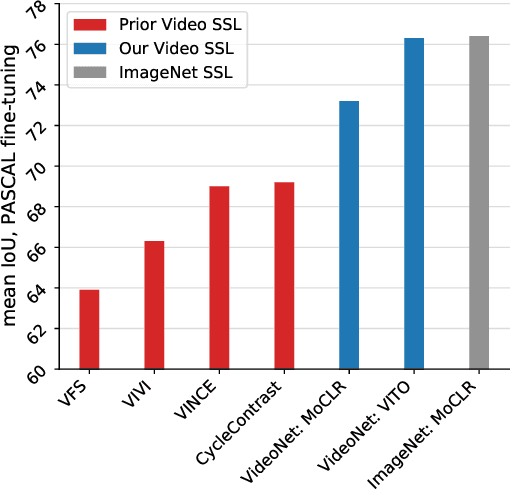
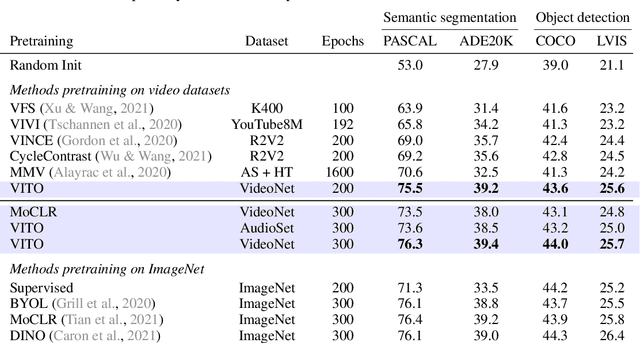
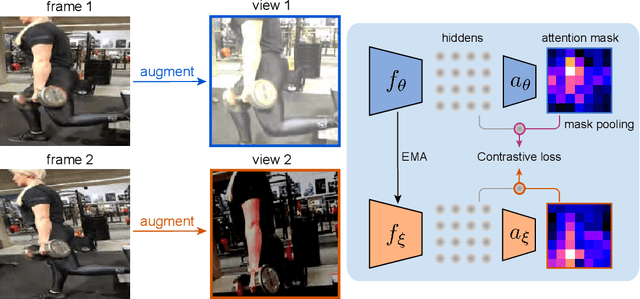
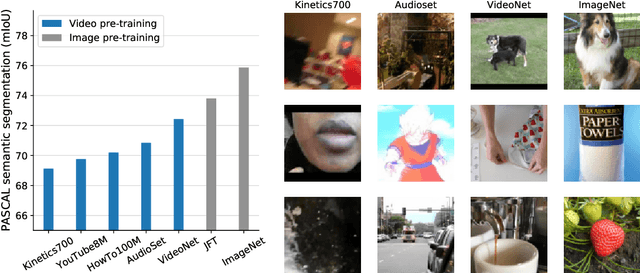
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.
DiffusionAD: Denoising Diffusion for Anomaly Detection
Mar 15, 2023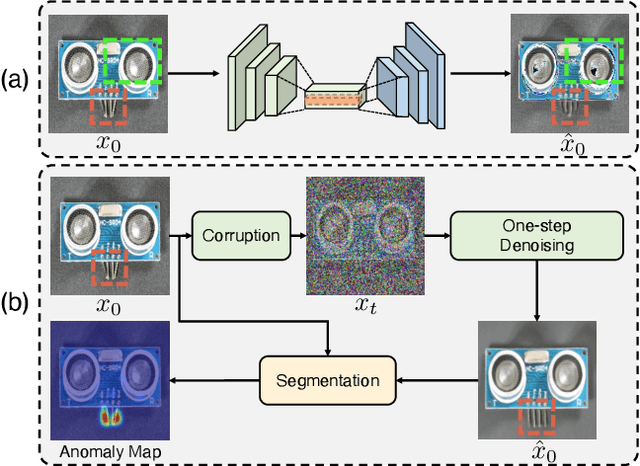
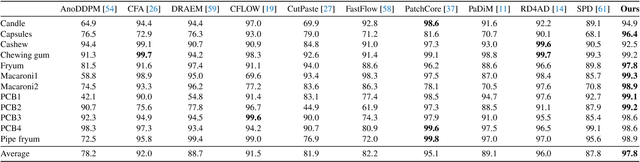
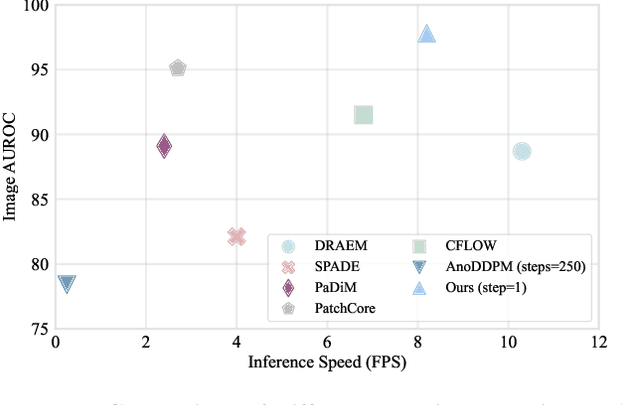
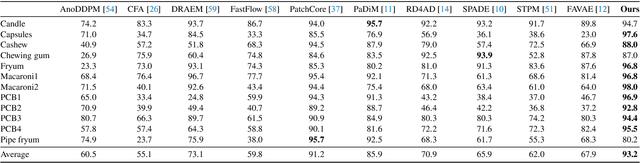
Anomaly detection is widely applied due to its remarkable effectiveness and efficiency in meeting the needs of real-world industrial manufacturing. We introduce a new pipeline, DiffusionAD, to anomaly detection. We frame anomaly detection as a ``noise-to-norm'' paradigm, in which anomalies are identified as inconsistencies between a query image and its flawless approximation. Our pipeline achieves this by restoring the anomalous regions from the noisy corrupted query image while keeping the normal regions unchanged. DiffusionAD includes a denoising sub-network and a segmentation sub-network, which work together to provide intuitive anomaly detection and localization in an end-to-end manner, without the need for complicated post-processing steps. Remarkably, during inference, this framework delivers satisfactory performance with just one diffusion reverse process step, which is tens to hundreds of times faster than general diffusion methods. Extensive evaluations on standard and challenging benchmarks including VisA and DAGM show that DiffusionAD outperforms current state-of-the-art paradigms, demonstrating the effectiveness and generalizability of the proposed pipeline.