 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Apr 05, 2023
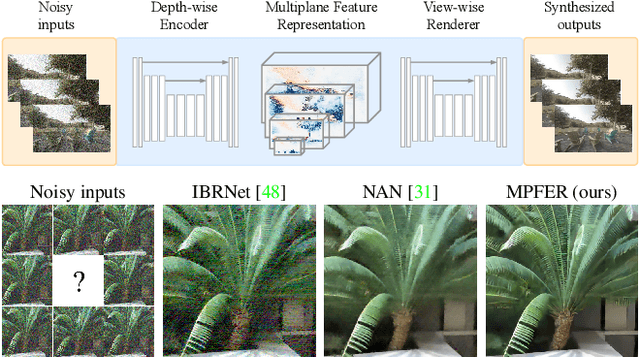
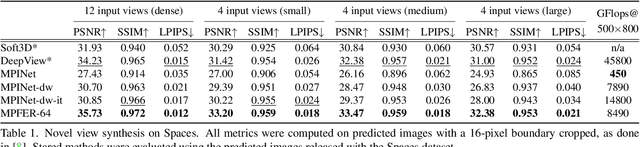
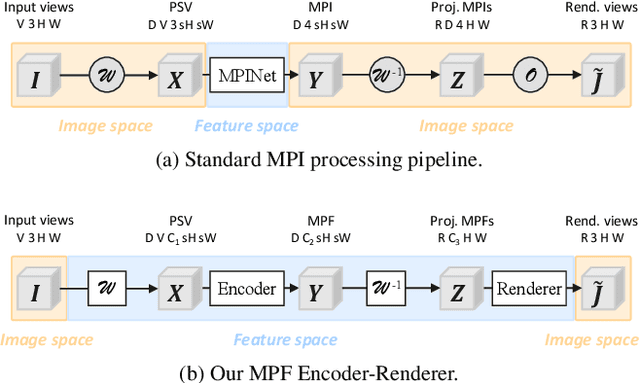
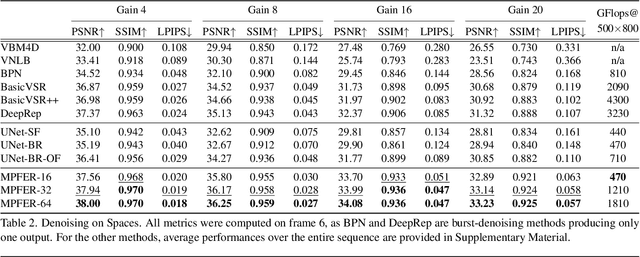
While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.
Exploring the Utility of Self-Supervised Pretraining Strategies for the Detection of Absent Lung Sliding in M-Mode Lung Ultrasound
Apr 05, 2023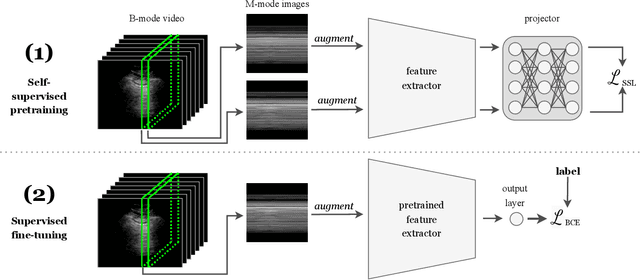
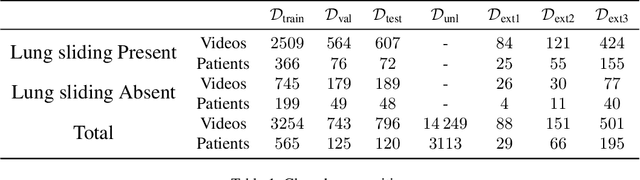
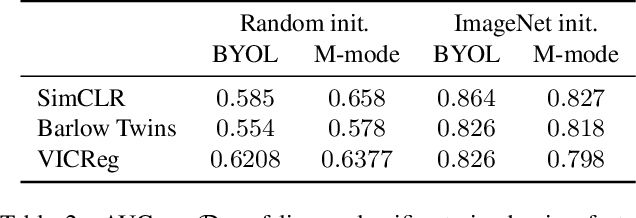
Self-supervised pretraining has been observed to improve performance in supervised learning tasks in medical imaging. This study investigates the utility of self-supervised pretraining prior to conducting supervised fine-tuning for the downstream task of lung sliding classification in M-mode lung ultrasound images. We propose a novel pairwise relationship that couples M-mode images constructed from the same B-mode image and investigate the utility of data augmentation procedure specific to M-mode lung ultrasound. The results indicate that self-supervised pretraining yields better performance than full supervision, most notably for feature extractors not initialized with ImageNet-pretrained weights. Moreover, we observe that including a vast volume of unlabelled data results in improved performance on external validation datasets, underscoring the value of self-supervision for improving generalizability in automatic ultrasound interpretation. To the authors' best knowledge, this study is the first to characterize the influence of self-supervised pretraining for M-mode ultrasound.
1st Place Solution for ECCV 2022 OOD-CV Challenge Image Classification Track
Jan 12, 2023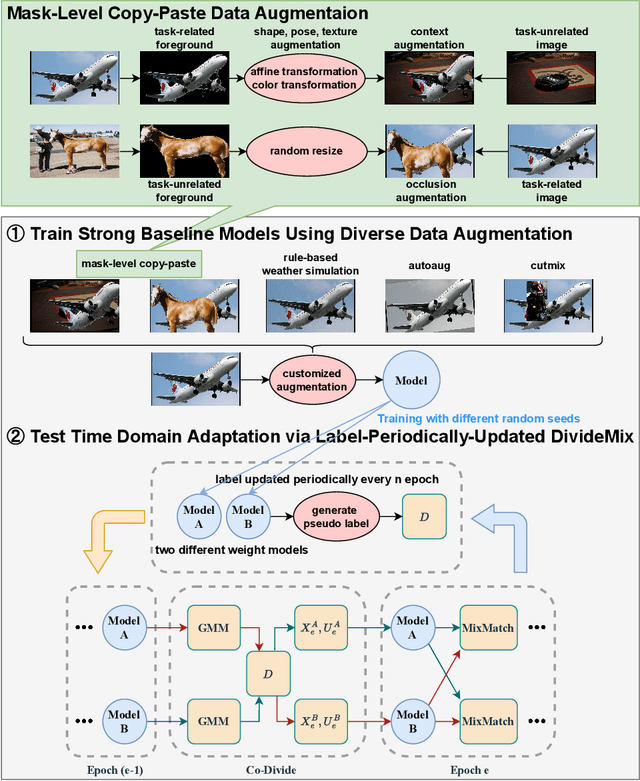
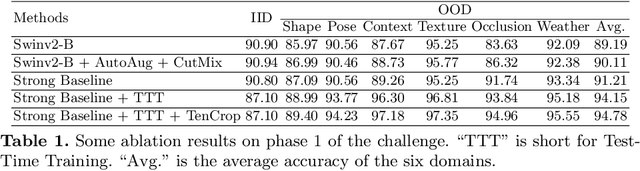
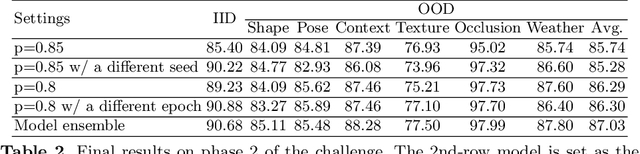

OOD-CV challenge is an out-of-distribution generalization task. In this challenge, our core solution can be summarized as that Noisy Label Learning Is A Strong Test-Time Domain Adaptation Optimizer. Briefly speaking, our main pipeline can be divided into two stages, a pre-training stage for domain generalization and a test-time training stage for domain adaptation. We only exploit labeled source data in the pre-training stage and only exploit unlabeled target data in the test-time training stage. In the pre-training stage, we propose a simple yet effective Mask-Level Copy-Paste data augmentation strategy to enhance out-of-distribution generalization ability so as to resist shape, pose, context, texture, occlusion, and weather domain shifts in this challenge. In the test-time training stage, we use the pre-trained model to assign noisy label for the unlabeled target data, and propose a Label-Periodically-Updated DivideMix method for noisy label learning. After integrating Test-Time Augmentation and Model Ensemble strategies, our solution ranks the first place on the Image Classification Leaderboard of the OOD-CV Challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Nov 21, 2022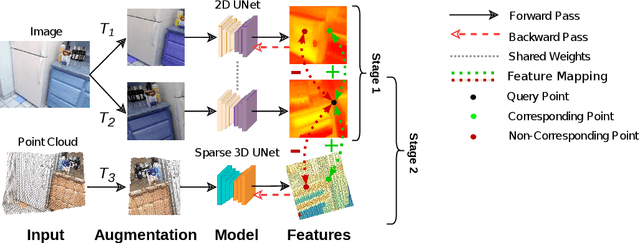
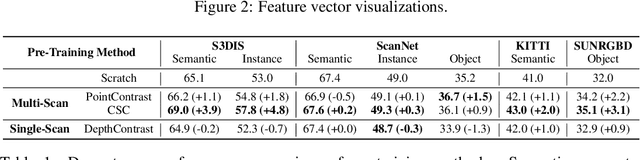

Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Multimodal Pre-training Framework for Sequential Recommendation via Contrastive Learning
Mar 21, 2023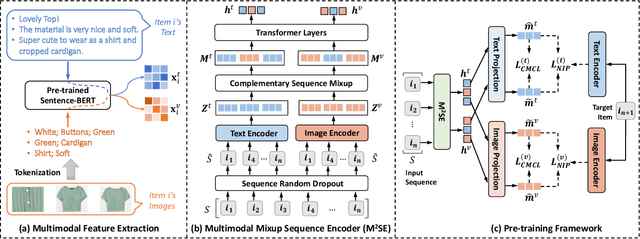
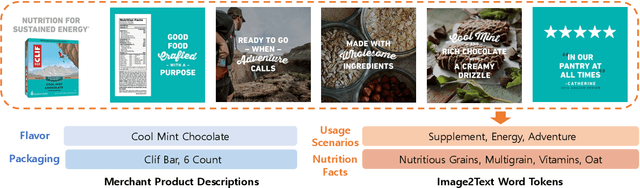
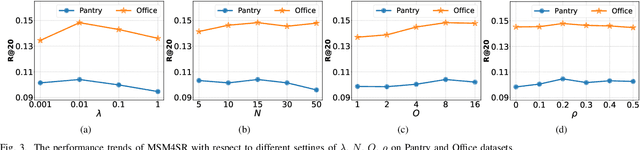
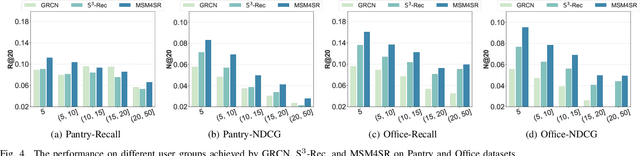
Sequential recommendation systems utilize the sequential interactions of users with items as their main supervision signals in learning users' preferences. However, existing methods usually generate unsatisfactory results due to the sparsity of user behavior data. To address this issue, we propose a novel pre-training framework, named Multimodal Sequence Mixup for Sequential Recommendation (MSM4SR), which leverages both users' sequential behaviors and items' multimodal content (\ie text and images) for effectively recommendation. Specifically, MSM4SR tokenizes each item image into multiple textual keywords and uses the pre-trained BERT model to obtain initial textual and visual features of items, for eliminating the discrepancy between the text and image modalities. A novel backbone network, \ie Multimodal Mixup Sequence Encoder (M$^2$SE), is proposed to bridge the gap between the item multimodal content and the user behavior, using a complementary sequence mixup strategy. In addition, two contrastive learning tasks are developed to assist M$^2$SE in learning generalized multimodal representations of the user behavior sequence. Extensive experiments on real-world datasets demonstrate that MSM4SR outperforms state-of-the-art recommendation methods. Moreover, we further verify the effectiveness of MSM4SR on other challenging tasks including cold-start and cross-domain recommendation.
Visual Representation Learning from Unlabeled Video using Contrastive Masked Autoencoders
Mar 21, 2023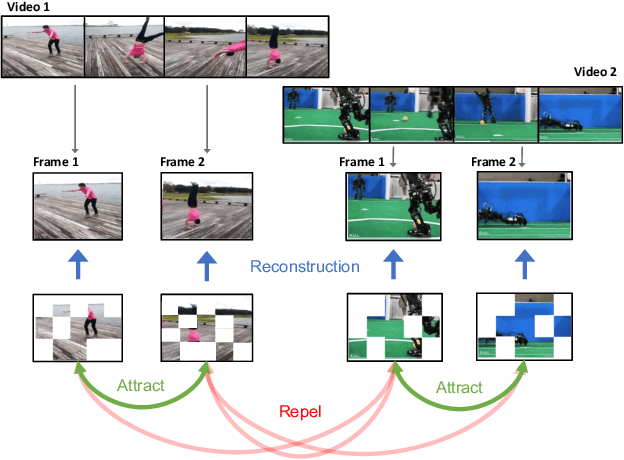
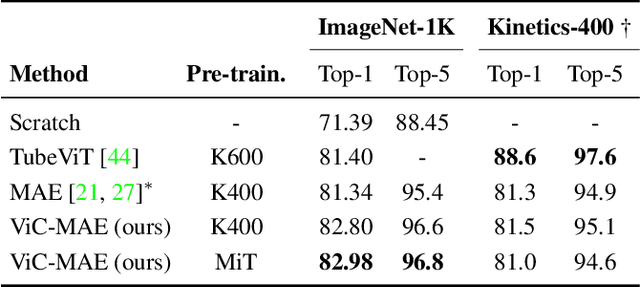
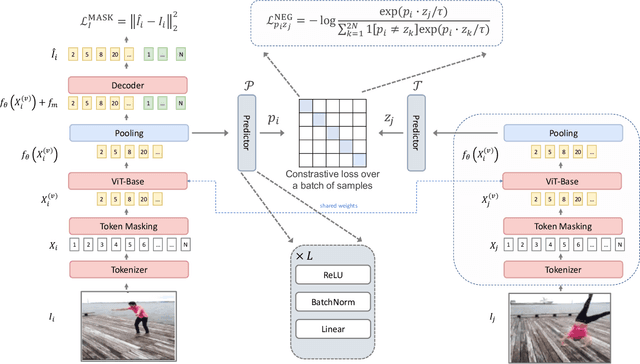

Masked Autoencoders (MAEs) learn self-supervised representations by randomly masking input image patches and a reconstruction loss. Alternatively, contrastive learning self-supervised methods encourage two versions of the same input to have a similar representation, while pulling apart the representations for different inputs. We propose ViC-MAE, a general method that combines both MAE and contrastive learning by pooling the local feature representations learned under the MAE reconstruction objective and leveraging this global representation under a contrastive objective across video frames. We show that visual representations learned under ViC-MAE generalize well to both video classification and image classification tasks. Using a backbone ViT-B/16 network pre-trained on the Moments in Time (MiT) dataset, we obtain state-of-the-art transfer learning from video to images on Imagenet-1k by improving 1.58% in absolute top-1 accuracy from a recent previous work. Moreover, our method maintains a competitive transfer-learning performance of 81.50% top-1 accuracy on the Kinetics-400 video classification benchmark. In addition, we show that despite its simplicity, ViC-MAE yields improved results compared to combining MAE pre-training with previously proposed contrastive objectives such as VicReg and SiamSiam.
Learning-based Framework for US Signals Super-resolution
Apr 17, 2023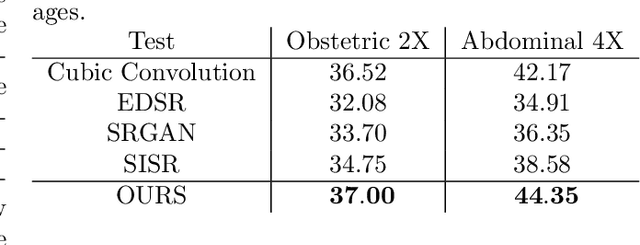
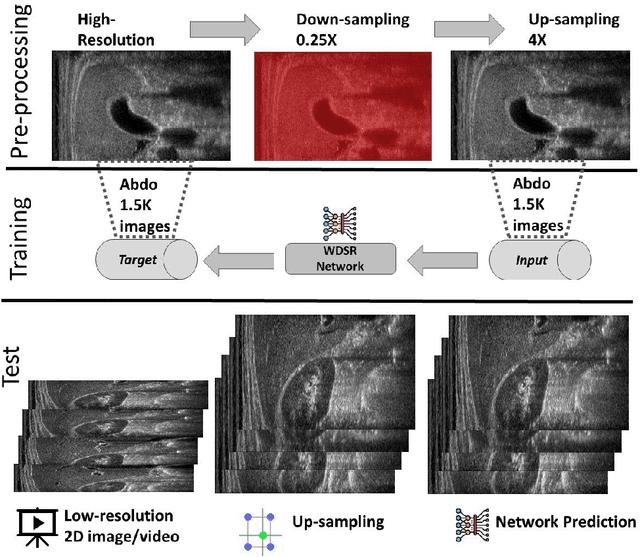

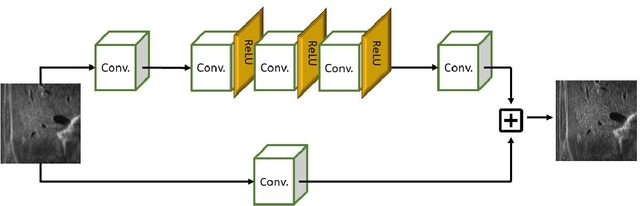
We propose a novel deep-learning framework for super-resolution ultrasound images and videos in terms of spatial resolution and line reconstruction. We up-sample the acquired low-resolution image through a vision-based interpolation method; then, we train a learning-based model to improve the quality of the up-sampling. We qualitatively and quantitatively test our model on different anatomical districts (e.g., cardiac, obstetric) images and with different up-sampling resolutions (i.e., 2X, 4X). Our method improves the PSNR median value with respect to SOTA methods of $1.7\%$ on obstetric 2X raw images, $6.1\%$ on cardiac 2X raw images, and $4.4\%$ on abdominal raw 4X images; it also improves the number of pixels with a low prediction error of $9.0\%$ on obstetric 4X raw images, $5.2\%$ on cardiac 4X raw images, and $6.2\%$ on abdominal 4X raw images. The proposed method is then applied to the spatial super-resolution of 2D videos, by optimising the sampling of lines acquired by the probe in terms of the acquisition frequency. Our method specialises trained networks to predict the high-resolution target through the design of the network architecture and the loss function, taking into account the anatomical district and the up-sampling factor and exploiting a large ultrasound data set. The use of deep learning on large data sets overcomes the limitations of vision-based algorithms that are general and do not encode the characteristics of the data. Furthermore, the data set can be enriched with images selected by medical experts to further specialise the individual networks. Through learning and high-performance computing, our super-resolution is specialised to different anatomical districts by training multiple networks. Furthermore, the computational demand is shifted to centralised hardware resources with a real-time execution of the network's prediction on local devices.
Fast Random Approximation of Multi-channel Room Impulse Response
Apr 17, 2023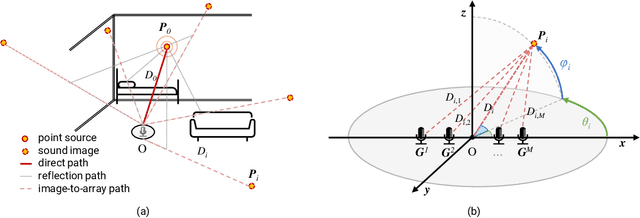
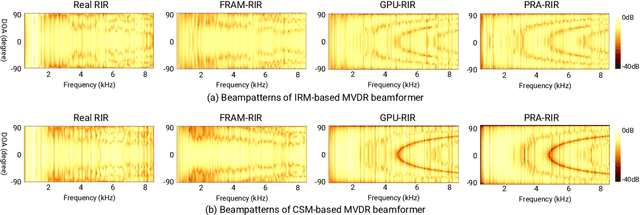
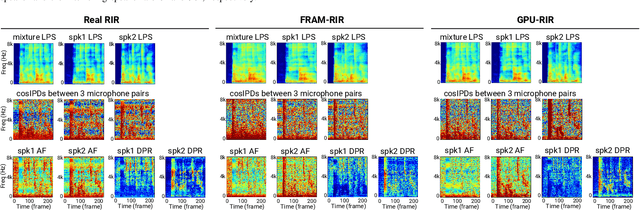
Modern neural-network-based speech processing systems are typically required to be robust against reverberation, and the training of such systems thus needs a large amount of reverberant data. During the training of the systems, on-the-fly simulation pipeline is nowadays preferred as it allows the model to train on infinite number of data samples without pre-generating and saving them on harddisk. An RIR simulation method thus needs to not only generate more realistic artificial room impulse response (RIR) filters, but also generate them in a fast way to accelerate the training process. Existing RIR simulation tools have proven effective in a wide range of speech processing tasks and neural network architectures, but their usage in on-the-fly simulation pipeline remains questionable due to their computational complexity or the quality of the generated RIR filters. In this paper, we propose FRAM-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic multi-channel RIR filters. FRAM-RIR bypasses the explicit calculation of sound propagation paths in ISM-based algorithms by randomly sampling the location and number of reflections of each virtual sound source based on several heuristic assumptions, while still maintains accurate direction-of-arrival (DOA) information of all sound sources. Visualization of oracle beampatterns and directional features shows that FRAM-RIR can generate more realistic RIR filters than existing widely-used ISM-based tools, and experiment results on multi-channel noisy speech separation and dereverberation tasks with a wide range of neural network architectures show that models trained with FRAM-RIR can also achieve on par or better performance on real RIRs compared to other RIR simulation tools with a significantly accelerated training procedure. A Python implementation of FRAM-RIR is released.
QuantArt: Quantizing Image Style Transfer Towards High Visual Fidelity
Dec 20, 2022
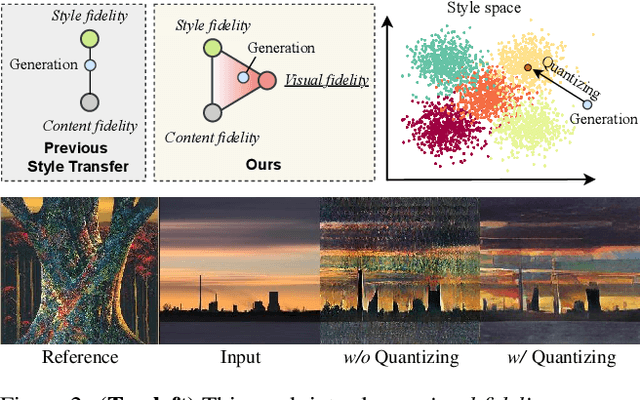
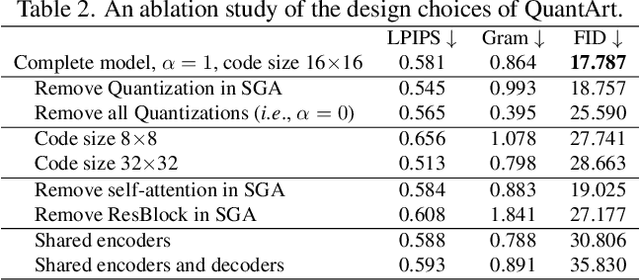
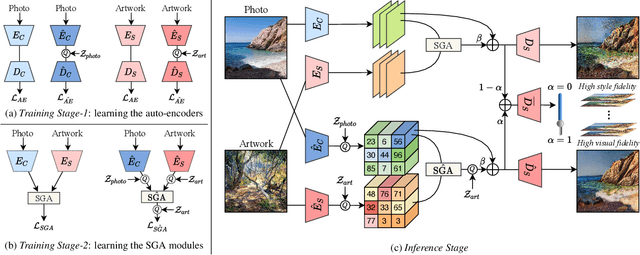
The mechanism of existing style transfer algorithms is by minimizing a hybrid loss function to push the generated image toward high similarities in both content and style. However, this type of approach cannot guarantee visual fidelity, i.e., the generated artworks should be indistinguishable from real ones. In this paper, we devise a new style transfer framework called QuantArt for high visual-fidelity stylization. QuantArt pushes the latent representation of the generated artwork toward the centroids of the real artwork distribution with vector quantization. By fusing the quantized and continuous latent representations, QuantArt allows flexible control over the generated artworks in terms of content preservation, style similarity, and visual fidelity. Experiments on various style transfer settings show that our QuantArt framework achieves significantly higher visual fidelity compared with the existing style transfer methods.
DiffusionAD: Denoising Diffusion for Anomaly Detection
Mar 19, 2023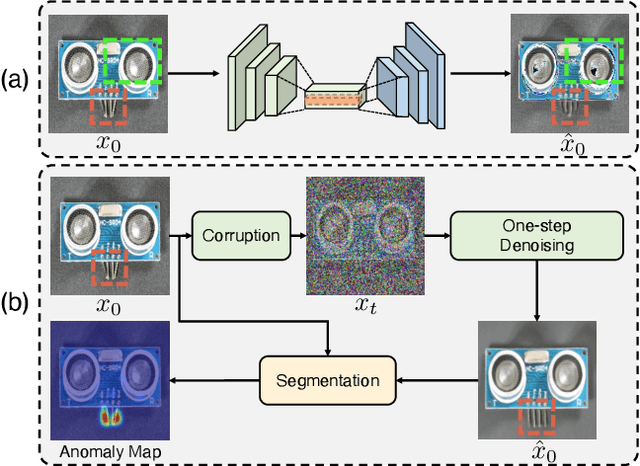
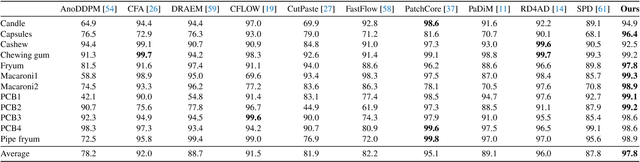
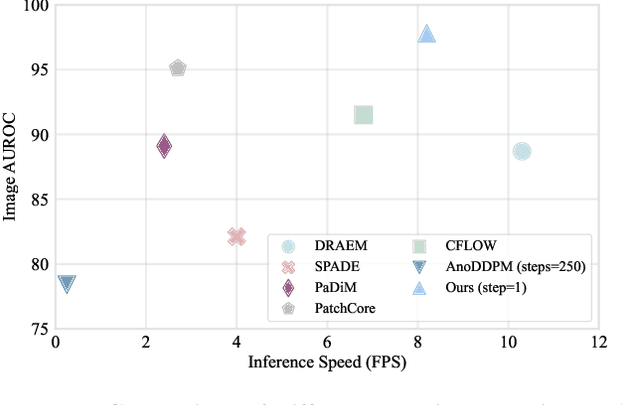
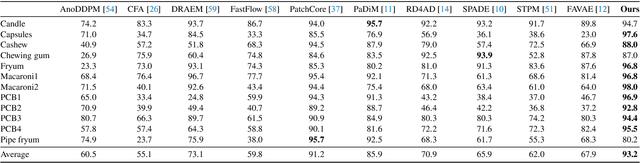
Anomaly detection is widely applied due to its remarkable effectiveness and efficiency in meeting the needs of real-world industrial manufacturing. We introduce a new pipeline, DiffusionAD, to anomaly detection. We frame anomaly detection as a ``noise-to-norm'' paradigm, in which anomalies are identified as inconsistencies between a query image and its flawless approximation. Our pipeline achieves this by restoring the anomalous regions from the noisy corrupted query image while keeping the normal regions unchanged. DiffusionAD includes a denoising sub-network and a segmentation sub-network, which work together to provide intuitive anomaly detection and localization in an end-to-end manner, without the need for complicated post-processing steps. Remarkably, during inference, this framework delivers satisfactory performance with just one diffusion reverse process step, which is tens to hundreds of times faster than general diffusion methods. Extensive evaluations on standard and challenging benchmarks including VisA and DAGM show that DiffusionAD outperforms current state-of-the-art paradigms, demonstrating the effectiveness and generalizability of the proposed pipeline.