 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise2Contrast: Multi-Contrast Fusion Enables Self-Supervised Tomographic Image Denoising
Dec 09, 2022
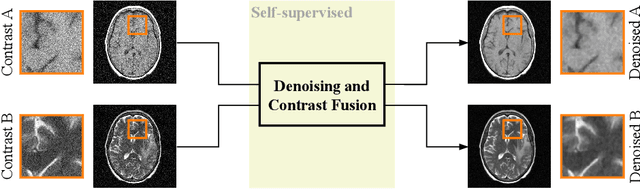
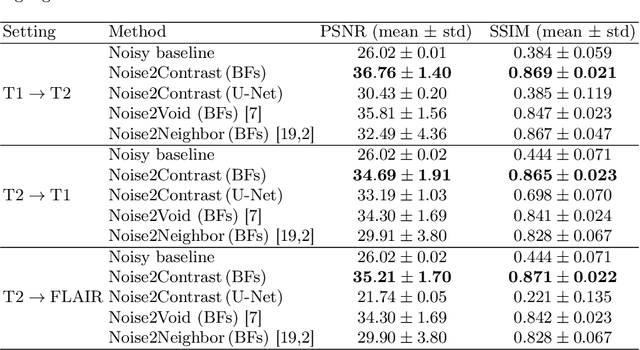
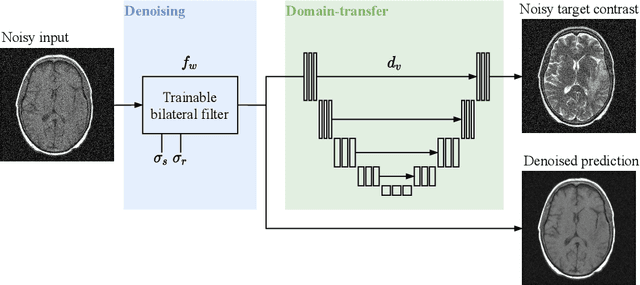

Self-supervised image denoising techniques emerged as convenient methods that allow training denoising models without requiring ground-truth noise-free data. Existing methods usually optimize loss metrics that are calculated from multiple noisy realizations of similar images, e.g., from neighboring tomographic slices. However, those approaches fail to utilize the multiple contrasts that are routinely acquired in medical imaging modalities like MRI or dual-energy CT. In this work, we propose the new self-supervised training scheme Noise2Contrast that combines information from multiple measured image contrasts to train a denoising model. We stack denoising with domain-transfer operators to utilize the independent noise realizations of different image contrasts to derive a self-supervised loss. The trained denoising operator achieves convincing quantitative and qualitative results, outperforming state-of-the-art self-supervised methods by 4.7-11.0%/4.8-7.3% (PSNR/SSIM) on brain MRI data and by 43.6-50.5%/57.1-77.1% (PSNR/SSIM) on dual-energy CT X-ray microscopy data with respect to the noisy baseline. Our experiments on different real measured data sets indicate that Noise2Contrast training generalizes to other multi-contrast imaging modalities.
HIVE: Harnessing Human Feedback for Instructional Visual Editing
Mar 16, 2023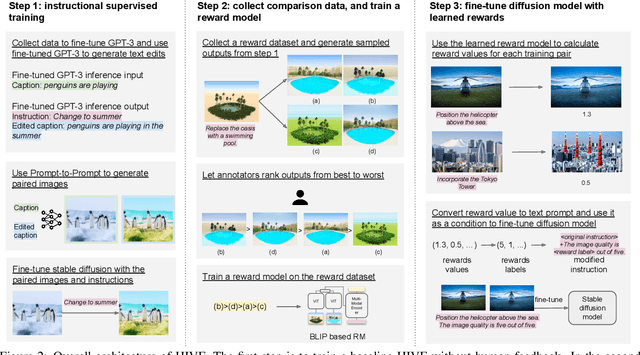
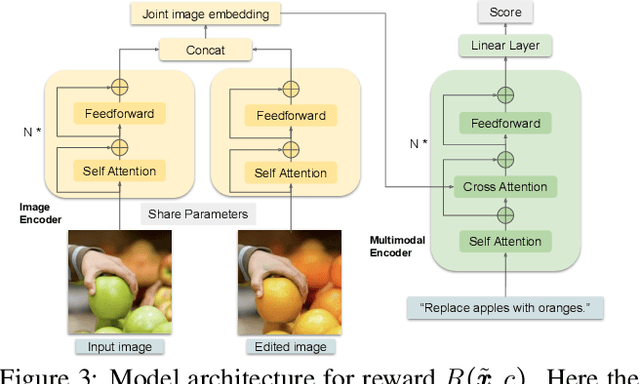


Incorporating human feedback has been shown to be crucial to align text generated by large language models to human preferences. We hypothesize that state-of-the-art instructional image editing models, where outputs are generated based on an input image and an editing instruction, could similarly benefit from human feedback, as their outputs may not adhere to the correct instructions and preferences of users. In this paper, we present a novel framework to harness human feedback for instructional visual editing (HIVE). Specifically, we collect human feedback on the edited images and learn a reward function to capture the underlying user preferences. We then introduce scalable diffusion model fine-tuning methods that can incorporate human preferences based on the estimated reward. Besides, to mitigate the bias brought by the limitation of data, we contribute a new 1M training dataset, a 3.6K reward dataset for rewards learning, and a 1K evaluation dataset to boost the performance of instructional image editing. We conduct extensive empirical experiments quantitatively and qualitatively, showing that HIVE is favored over previous state-of-the-art instructional image editing approaches by a large margin.
Ensuring Trustworthy Medical Artificial Intelligencethrough Ethical and Philosophical Principles
Apr 25, 2023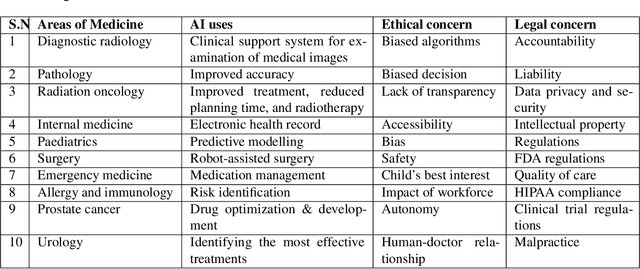
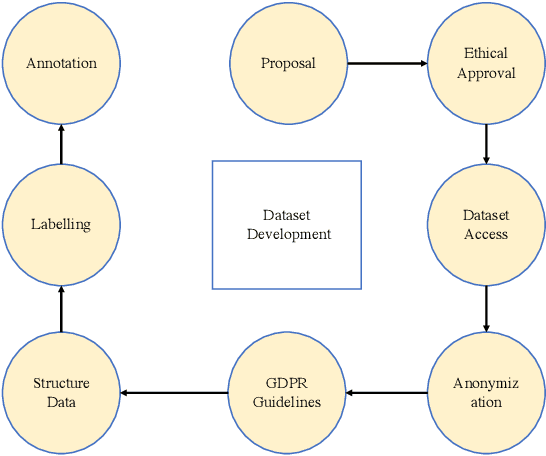

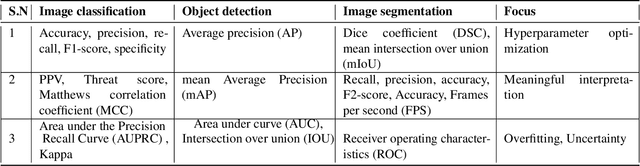
Artificial intelligence (AI) methods have great potential to revolutionize numerous medical care by enhancing the experience of medical experts and patients. AI based computer-assisted diagnosis tools can have a tremendous benefit if they can outperform or perform similarly to the level of a clinical expert. As a result, advanced healthcare services can be affordable in developing nations, and the problem of a lack of expert medical practitioners can be addressed. AI based tools can save time, resources, and overall cost for patient treatment. Furthermore, in contrast to humans, AI can uncover complex relations in the data from a large set of inputs and even lead to new evidence-based knowledge in medicine. However, integrating AI in healthcare raises several ethical and philosophical concerns, such as bias, transparency, autonomy, responsibility and accountability, which must be addressed before integrating such tools into clinical settings. In this article, we emphasize recent advances in AI-assisted medical image analysis, existing standards, and the significance of comprehending ethical issues and best practices for the applications of AI in clinical settings. We cover the technical and ethical challenges of AI and the implications of deploying AI in hospitals and public organizations. We also discuss promising key measures and techniques to address the ethical challenges, data scarcity, racial bias, lack of transparency, and algorithmic bias. Finally, we provide our recommendation and future directions for addressing the ethical challenges associated with AI in healthcare applications, with the goal of deploying AI into the clinical settings to make the workflow more efficient, accurate, accessible, transparent, and reliable for the patient worldwide.
Patch-aware Batch Normalization for Improving Cross-domain Robustness
Apr 06, 2023
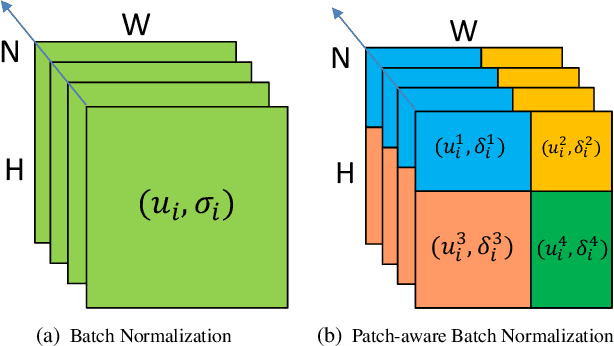
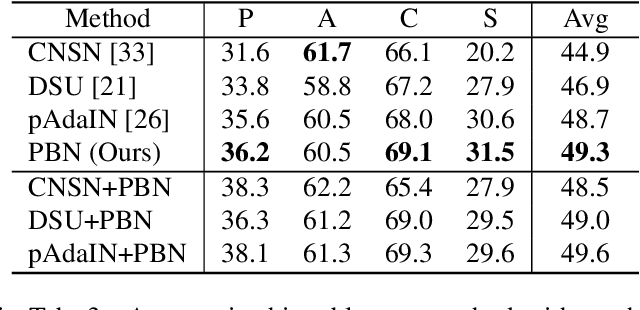
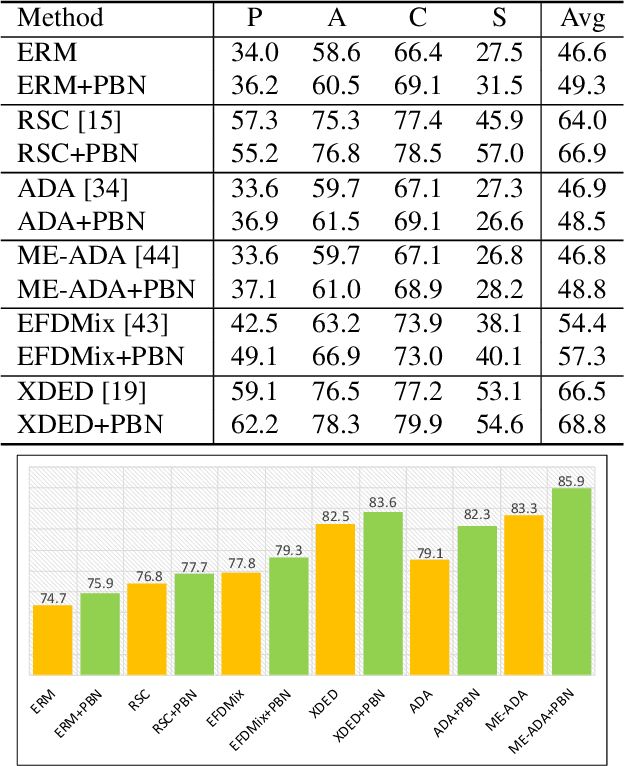
Despite the significant success of deep learning in computer vision tasks, cross-domain tasks still present a challenge in which the model's performance will degrade when the training set and the test set follow different distributions. Most existing methods employ adversarial learning or instance normalization for achieving data augmentation to solve this task. In contrast, considering that the batch normalization (BN) layer may not be robust for unseen domains and there exist the differences between local patches of an image, we propose a novel method called patch-aware batch normalization (PBN). To be specific, we first split feature maps of a batch into non-overlapping patches along the spatial dimension, and then independently normalize each patch to jointly optimize the shared BN parameter at each iteration. By exploiting the differences between local patches of an image, our proposed PBN can effectively enhance the robustness of the model's parameters. Besides, considering the statistics from each patch may be inaccurate due to their smaller size compared to the global feature maps, we incorporate the globally accumulated statistics with the statistics from each batch to obtain the final statistics for normalizing each patch. Since the proposed PBN can replace the typical BN, it can be integrated into most existing state-of-the-art methods. Extensive experiments and analysis demonstrate the effectiveness of our PBN in multiple computer vision tasks, including classification, object detection, instance retrieval, and semantic segmentation.
Isolated Sign Language Recognition based on Tree Structure Skeleton Images
Apr 10, 2023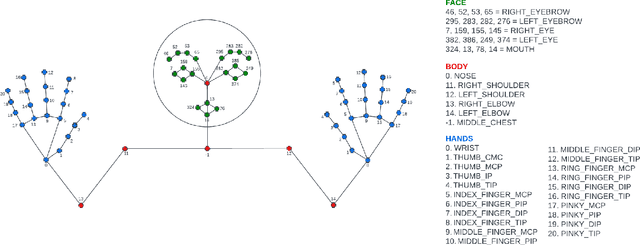
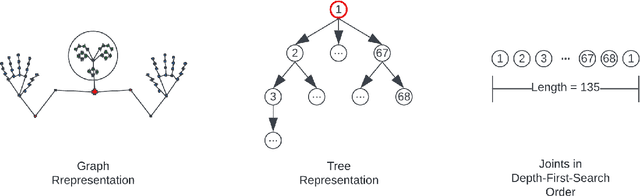

Sign Language Recognition (SLR) systems aim to be embedded in video stream platforms to recognize the sign performed in front of a camera. SLR research has taken advantage of recent advances in pose estimation models to use skeleton sequences estimated from videos instead of RGB information to predict signs. This approach can make HAR-related tasks less complex and more robust to diverse backgrounds, lightning conditions, and physical appearances. In this work, we explore the use of a spatio-temporal skeleton representation such as Tree Structure Skeleton Image (TSSI) as an alternative input to improve the accuracy of skeleton-based models for SLR. TSSI converts a skeleton sequence into an RGB image where the columns represent the joints of the skeleton in a depth-first tree traversal order, the rows represent the temporal evolution of the joints, and the three channels represent the (x, y, z) coordinates of the joints. We trained a DenseNet-121 using this type of input and compared it with other skeleton-based deep learning methods using a large-scale American Sign Language (ASL) dataset, WLASL. Our model (SL-TSSI-DenseNet) overcomes the state-of-the-art of other skeleton-based models. Moreover, when including data augmentation our proposal achieves better results than both skeleton-based and RGB-based models. We evaluated the effectiveness of our model on the Ankara University Turkish Sign Language (TSL) dataset, AUTSL, and a Mexican Sign Language (LSM) dataset. On the AUTSL dataset, the model achieves similar results to the state-of-the-art of other skeleton-based models. On the LSM dataset, the model achieves higher results than the baseline. Code has been made available at: https://github.com/davidlainesv/SL-TSSI-DenseNet.
Good helper is around you: Attention-driven Masked Image Modeling
Dec 01, 2022

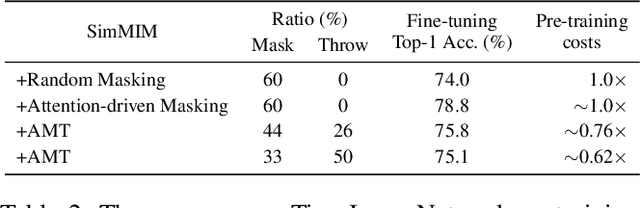
It has been witnessed that masked image modeling (MIM) has shown a huge potential in self-supervised learning in the past year. Benefiting from the universal backbone vision transformer, MIM learns self-supervised visual representations through masking a part of patches of the image while attempting to recover the missing pixels. Most previous works mask patches of the image randomly, which underutilizes the semantic information that is beneficial to visual representation learning. On the other hand, due to the large size of the backbone, most previous works have to spend much time on pre-training. In this paper, we propose \textbf{Attention-driven Masking and Throwing Strategy} (AMT), which could solve both problems above. We first leverage the self-attention mechanism to obtain the semantic information of the image during the training process automatically without using any supervised methods. Masking strategy can be guided by that information to mask areas selectively, which is helpful for representation learning. Moreover, a redundant patch throwing strategy is proposed, which makes learning more efficient. As a plug-and-play module for masked image modeling, AMT improves the linear probing accuracy of MAE by $2.9\% \sim 5.9\%$ on CIFAR-10/100, STL-10, Tiny ImageNet, and ImageNet-1K, and obtains an improved performance with respect to fine-tuning accuracy of MAE and SimMIM. Moreover, this design also achieves superior performance on downstream detection and segmentation tasks. Code is available at https://github.com/guijiejie/AMT.
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
Apr 10, 2023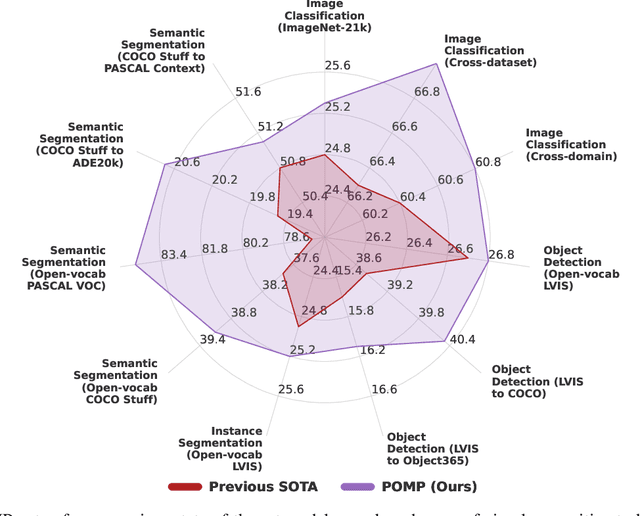
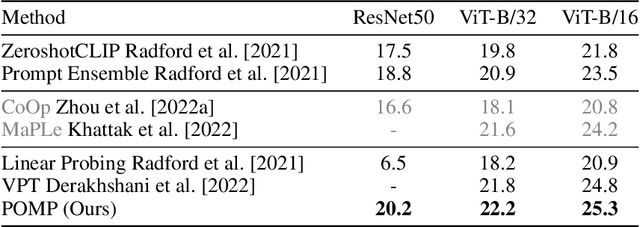
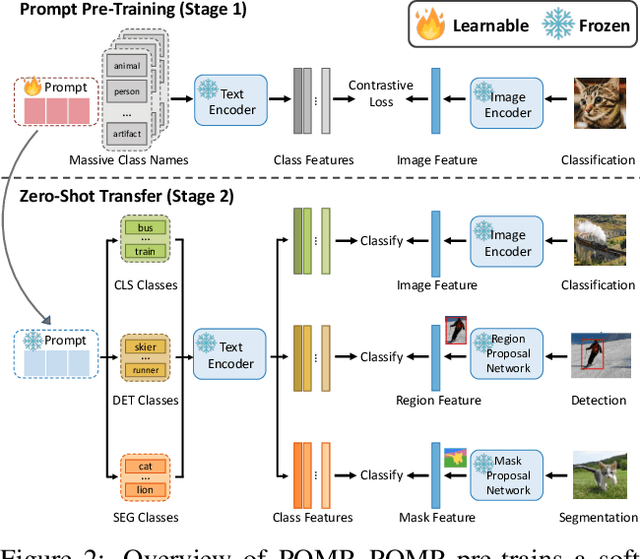
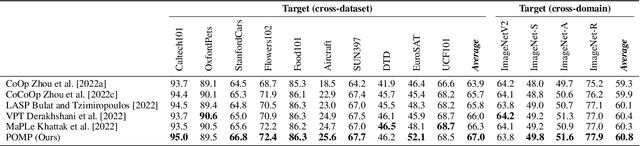
This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 downstream datasets, e.g., 67.0% average accuracy on 10 classification dataset (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg).
Coupling Global Context and Local Contents for Weakly-Supervised Semantic Segmentation
Apr 26, 2023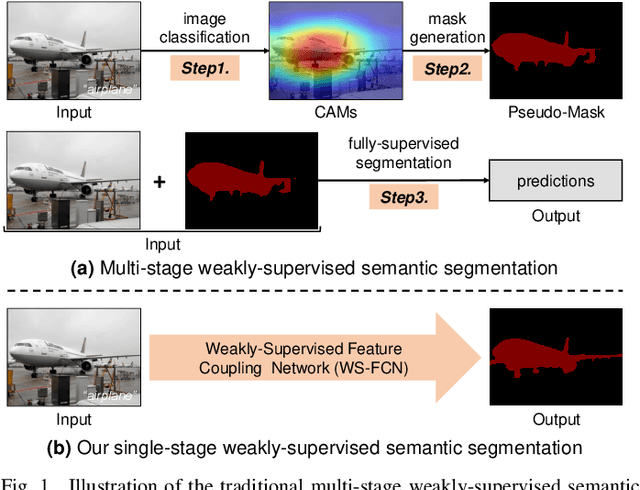

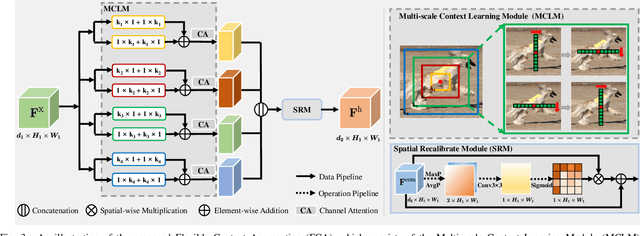
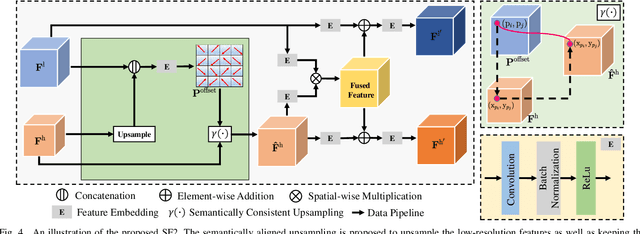
Thanks to the advantages of the friendly annotations and the satisfactory performance, Weakly-Supervised Semantic Segmentation (WSSS) approaches have been extensively studied. Recently, the single-stage WSSS was awakened to alleviate problems of the expensive computational costs and the complicated training procedures in multi-stage WSSS. However, results of such an immature model suffer from problems of background incompleteness and object incompleteness. We empirically find that they are caused by the insufficiency of the global object context and the lack of the local regional contents, respectively. Under these observations, we propose a single-stage WSSS model with only the image-level class label supervisions, termed as Weakly Supervised Feature Coupling Network (WS-FCN), which can capture the multi-scale context formed from the adjacent feature grids, and encode the fine-grained spatial information from the low-level features into the high-level ones. Specifically, a flexible context aggregation module is proposed to capture the global object context in different granular spaces. Besides, a semantically consistent feature fusion module is proposed in a bottom-up parameter-learnable fashion to aggregate the fine-grained local contents. Based on these two modules, WS-FCN lies in a self-supervised end-to-end training fashion. Extensive experimental results on the challenging PASCAL VOC 2012 and MS COCO 2014 demonstrate the effectiveness and efficiency of WS-FCN, which can achieve state-of-the-art results by 65.02\% and 64.22\% mIoU on PASCAL VOC 2012 val set and test set, 34.12\% mIoU on MS COCO 2014 val set, respectively. The code and weight have been released at:https://github.com/ChunyanWang1/ws-fcn.
Latent Fingerprint Recognition: Fusion of Local and Global Embeddings
Apr 26, 2023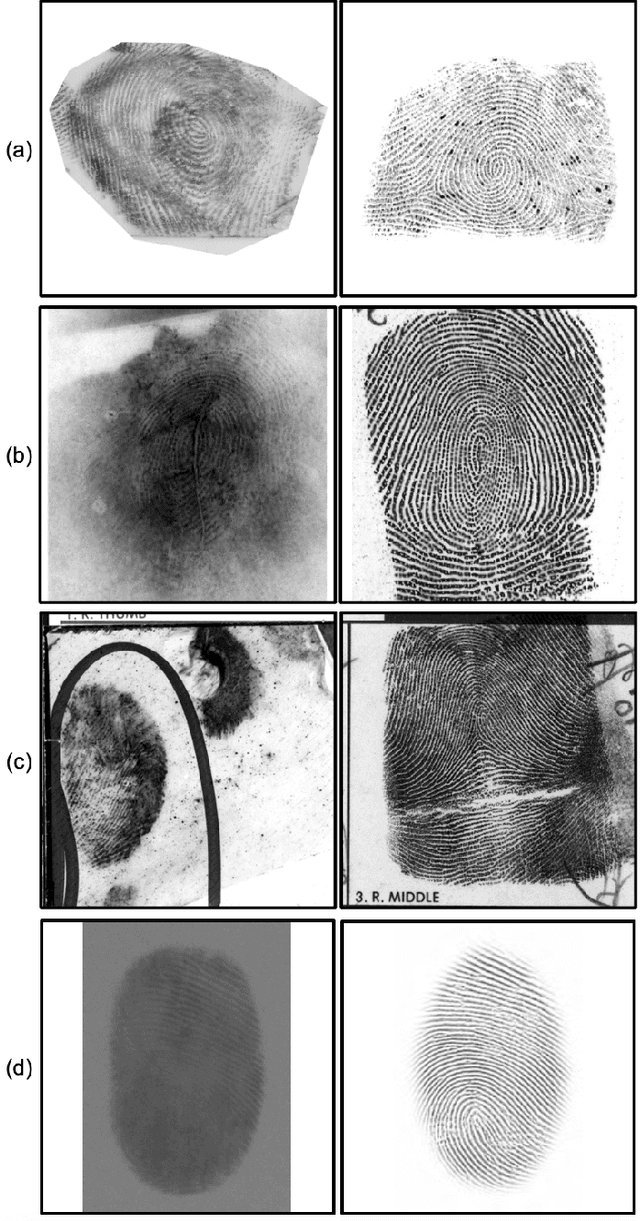
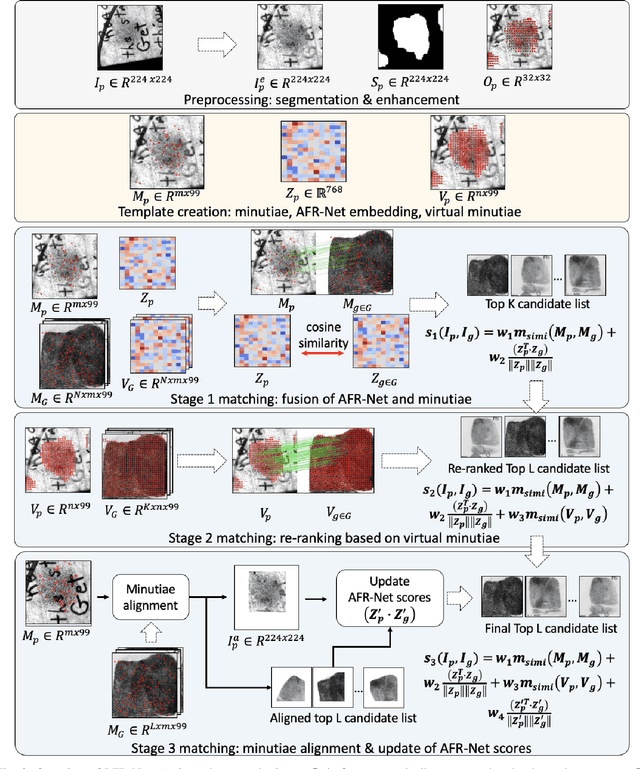


One of the most challenging problems in fingerprint recognition continues to be establishing the identity of a suspect associated with partial and smudgy fingerprints left at a crime scene (i.e., latent prints or fingermarks). Despite the success of fixed-length embeddings for rolled and slap fingerprint recognition, the features learned for latent fingerprint matching have mostly been limited to local minutiae-based embeddings and have not directly leveraged global representations for matching. In this paper, we combine global embeddings with local embeddings for state-of-the-art latent to rolled matching accuracy with high throughput. The combination of both local and global representations leads to improved recognition accuracy across NIST SD 27, NIST SD 302, MSP, MOLF DB1/DB4, and MOLF DB2/DB4 latent fingerprint datasets for both closed-set (84.11%, 54.36%, 84.35%, 70.43%, 62.86% rank-1 retrieval rate, respectively) and open-set (0.50, 0.74, 0.44, 0.60, 0.68 FNIR at FPIR=0.02, respectively) identification scenarios on a gallery of 100K rolled fingerprints. Not only do we fuse the complimentary representations, we also use the local features to guide the global representations to focus on discriminatory regions in two fingerprint images to be compared. This leads to a multi-stage matching paradigm in which subsets of the retrieved candidate lists for each probe image are passed to subsequent stages for further processing, resulting in a considerable reduction in latency (requiring just 0.068 ms per latent to rolled comparison on a AMD EPYC 7543 32-Core Processor, roughly 15K comparisons per second). Finally, we show the generalizability of the fused representations for improving authentication accuracy across several rolled, plain, and contactless fingerprint datasets.
Masked Transformer for image Anomaly Localization
Oct 27, 2022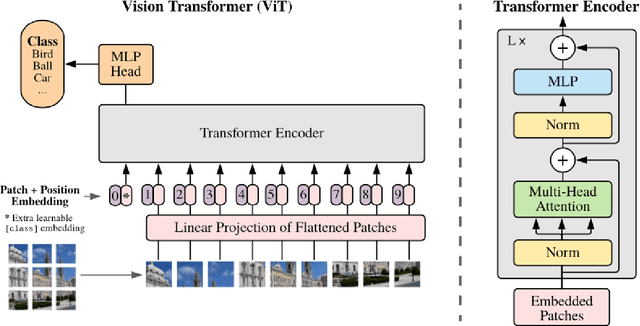

Image anomaly detection consists in detecting images or image portions that are visually different from the majority of the samples in a dataset. The task is of practical importance for various real-life applications like biomedical image analysis, visual inspection in industrial production, banking, traffic management, etc. Most of the current deep learning approaches rely on image reconstruction: the input image is projected in some latent space and then reconstructed, assuming that the network (mostly trained on normal data) will not be able to reconstruct the anomalous portions. However, this assumption does not always hold. We thus propose a new model based on the Vision Transformer architecture with patch masking: the input image is split in several patches, and each patch is reconstructed only from the surrounding data, thus ignoring the potentially anomalous information contained in the patch itself. We then show that multi-resolution patches and their collective embeddings provide a large improvement in the model's performance compared to the exclusive use of the traditional square patches. The proposed model has been tested on popular anomaly detection datasets such as MVTec and head CT and achieved good results when compared to other state-of-the-art approaches.