 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bent & Broken Bicycles: Leveraging synthetic data for damaged object re-identification
Apr 16, 2023
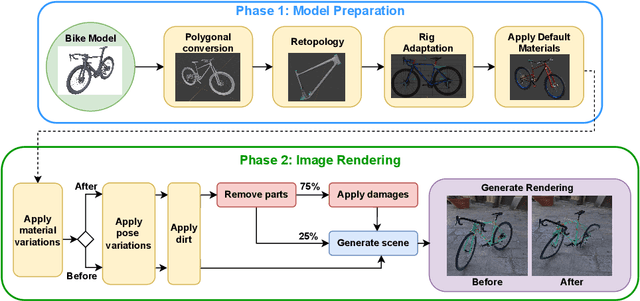
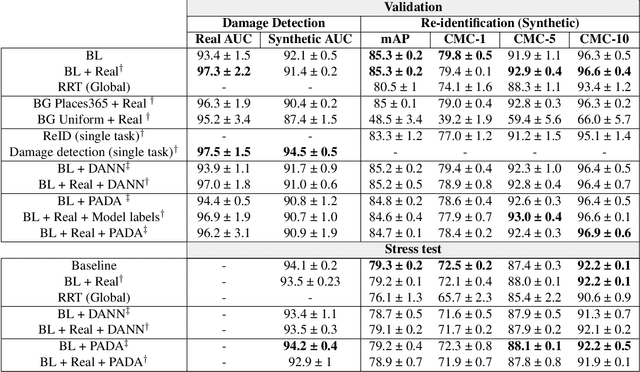
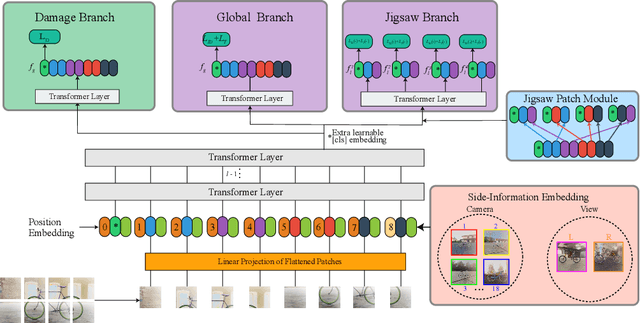
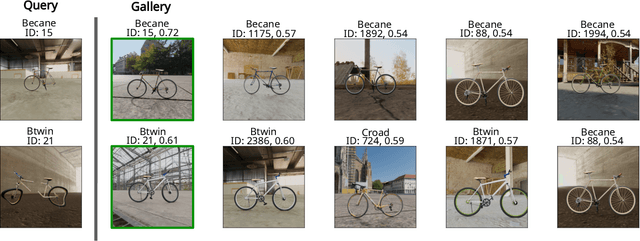
Instance-level object re-identification is a fundamental computer vision task, with applications from image retrieval to intelligent monitoring and fraud detection. In this work, we propose the novel task of damaged object re-identification, which aims at distinguishing changes in visual appearance due to deformations or missing parts from subtle intra-class variations. To explore this task, we leverage the power of computer-generated imagery to create, in a semi-automatic fashion, high-quality synthetic images of the same bike before and after a damage occurs. The resulting dataset, Bent & Broken Bicycles (BBBicycles), contains 39,200 images and 2,800 unique bike instances spanning 20 different bike models. As a baseline for this task, we propose TransReI3D, a multi-task, transformer-based deep network unifying damage detection (framed as a multi-label classification task) with object re-identification. The BBBicycles dataset is available at https://huggingface.co/datasets/GrainsPolito/BBBicycles
CNN-Assisted Steganography -- Integrating Machine Learning with Established Steganographic Techniques
Apr 25, 2023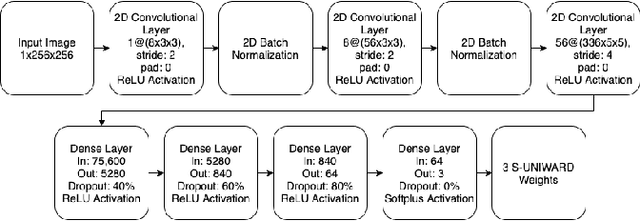
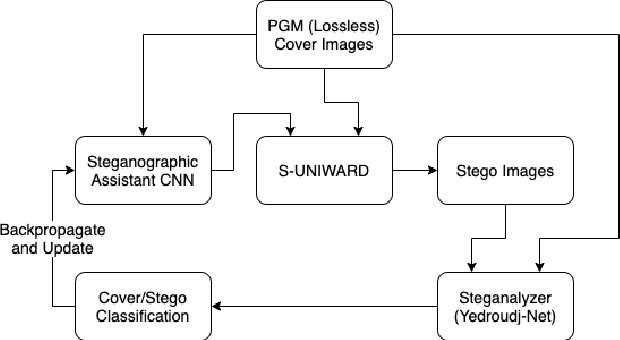


We propose a method to improve steganography by increasing the resilience of stego-media to discovery through steganalysis. Our approach enhances a class of steganographic approaches through the inclusion of a steganographic assistant convolutional neural network (SA-CNN). Previous research showed success in discovering the presence of hidden information within stego-images using trained neural networks as steganalyzers that are applied to stego-images. Our results show that such steganalyzers are less effective when SA-CNN is employed during the generation of a stego-image. We also explore the advantages and disadvantages of representing all the possible outputs of our SA-CNN within a smaller, discrete space, rather than a continuous space. Our SA-CNN enables certain classes of parametric steganographic algorithms to be customized based on characteristics of the cover media in which information is to be embedded. Thus, SA-CNN is adaptive in the sense that it enables the core steganographic algorithm to be especially configured for each particular instance of cover media. Experimental results are provided that employ a recent steganographic technique, S-UNIWARD, both with and without the use of SA-CNN. We then apply both sets of stego-images, those produced with and without SA-CNN, to an exmaple steganalyzer, Yedroudj-Net, and we compare the results. We believe that this approach for the integration of neural networks with hand-crafted algorithms increases the reliability and adaptability of steganographic algorithms.
Explainable GeoAI: Can saliency maps help interpret artificial intelligence's learning process? An empirical study on natural feature detection
Mar 16, 2023
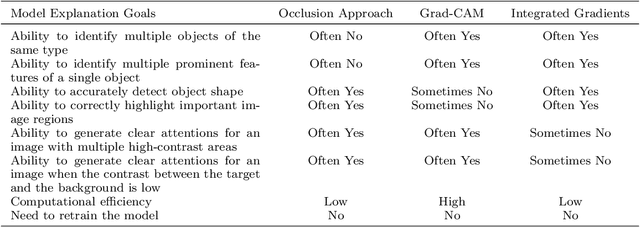
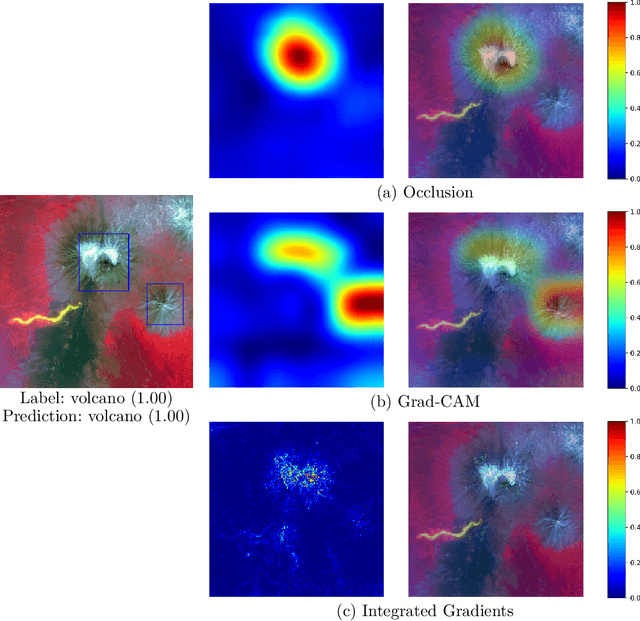
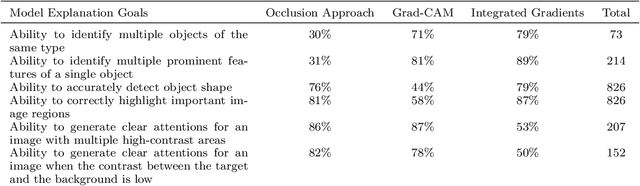
Improving the interpretability of geospatial artificial intelligence (GeoAI) models has become critically important to open the "black box" of complex AI models, such as deep learning. This paper compares popular saliency map generation techniques and their strengths and weaknesses in interpreting GeoAI and deep learning models' reasoning behaviors, particularly when applied to geospatial analysis and image processing tasks. We surveyed two broad classes of model explanation methods: perturbation-based and gradient-based methods. The former identifies important image areas, which help machines make predictions by modifying a localized area of the input image. The latter evaluates the contribution of every single pixel of the input image to the model's prediction results through gradient backpropagation. In this study, three algorithms-the occlusion method, the integrated gradients method, and the class activation map method-are examined for a natural feature detection task using deep learning. The algorithms' strengths and weaknesses are discussed, and the consistency between model-learned and human-understandable concepts for object recognition is also compared. The experiments used two GeoAI-ready datasets to demonstrate the generalizability of the research findings.
Inheriting Bayer's Legacy-Joint Remosaicing and Denoising for Quad Bayer Image Sensor
Mar 23, 2023Pixel binning based Quad sensors have emerged as a promising solution to overcome the hardware limitations of compact cameras in low-light imaging. However, binning results in lower spatial resolution and non-Bayer CFA artifacts. To address these challenges, we propose a dual-head joint remosaicing and denoising network (DJRD), which enables the conversion of noisy Quad Bayer and standard noise-free Bayer pattern without any resolution loss. DJRD includes a newly designed Quad Bayer remosaicing (QB-Re) block, integrated denoising modules based on Swin-transformer and multi-scale wavelet transform. The QB-Re block constructs the convolution kernel based on the CFA pattern to achieve a periodic color distribution in the perceptual field, which is used to extract exact spectral information and reduce color misalignment. The integrated Swin-Transformer and multi-scale wavelet transform capture non-local dependencies, frequency and location information to effectively reduce practical noise. By identifying challenging patches utilizing Moire and zipper detection metrics, we enable our model to concentrate on difficult patches during the post-training phase, which enhances the model's performance in hard cases. Our proposed model outperforms competing models by approximately 3dB, without additional complexity in hardware or software.
Removing supervision in semantic segmentation with local-global matching and area balancing
Mar 30, 2023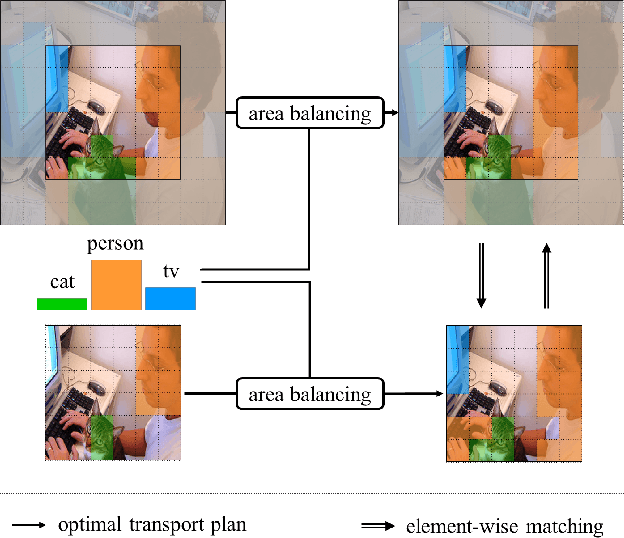
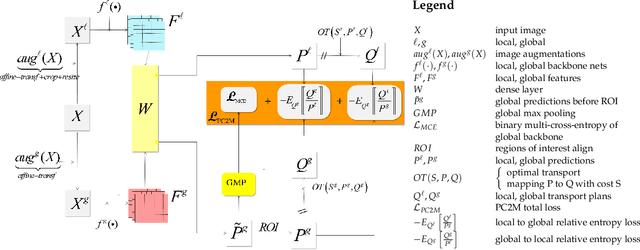
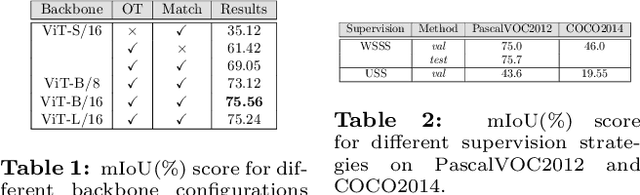

Removing supervision in semantic segmentation is still tricky. Current approaches can deal with common categorical patterns yet resort to multi-stage architectures. We design a novel end-to-end model leveraging local-global patch matching to predict categories, good localization, area and shape of objects for semantic segmentation. The local-global matching is, in turn, compelled by optimal transport plans fulfilling area constraints nearing a solution for exact shape prediction. Our model attains state-of-the-art in Weakly Supervised Semantic Segmentation, only image-level labels, with 75% mIoU on PascalVOC2012 val set and 46% on MS-COCO2014 val set. Dropping the image-level labels and clustering self-supervised learned features to yield pseudo-multi-level labels, we obtain an unsupervised model for semantic segmentation. We also attain state-of-the-art on Unsupervised Semantic Segmentation with 43.6% mIoU on PascalVOC2012 val set and 19.4% on MS-COCO2014 val set. The code is available at https://github.com/deepplants/PC2M.
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Mar 30, 2023
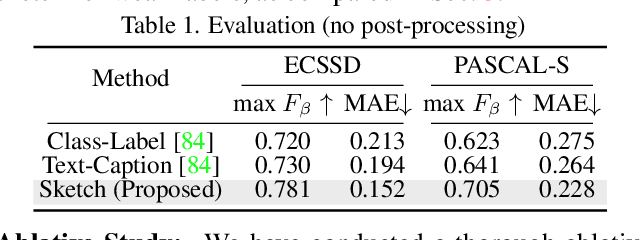

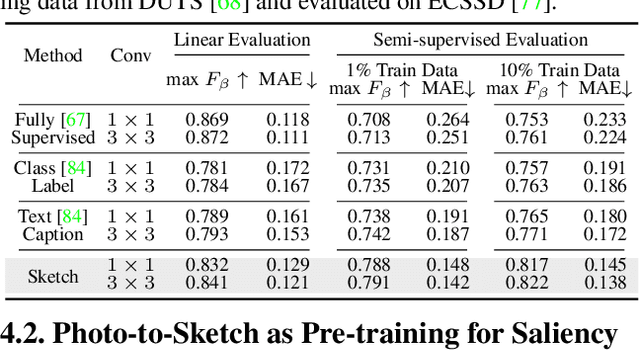
Human sketch has already proved its worth in various visual understanding tasks (e.g., retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of sketches - that they are also salient. This is intuitive as sketching is a natural attentive process at its core. More specifically, we aim to study how sketches can be used as a weak label to detect salient objects present in an image. To this end, we propose a novel method that emphasises on how "salient object" could be explained by hand-drawn sketches. To accomplish this, we introduce a photo-to-sketch generation model that aims to generate sequential sketch coordinates corresponding to a given visual photo through a 2D attention mechanism. Attention maps accumulated across the time steps give rise to salient regions in the process. Extensive quantitative and qualitative experiments prove our hypothesis and delineate how our sketch-based saliency detection model gives a competitive performance compared to the state-of-the-art.
Token Merging for Fast Stable Diffusion
Mar 30, 2023
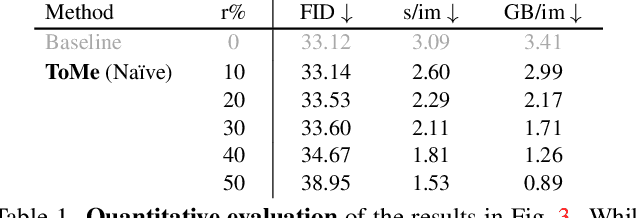
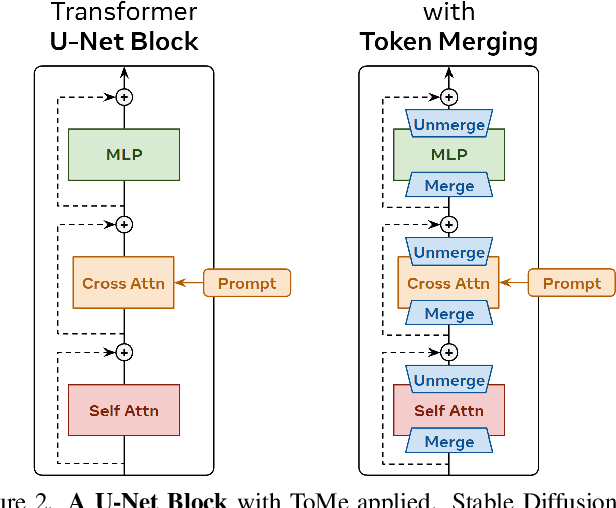

The landscape of image generation has been forever changed by open vocabulary diffusion models. However, at their core these models use transformers, which makes generation slow. Better implementations to increase the throughput of these transformers have emerged, but they still evaluate the entire model. In this paper, we instead speed up diffusion models by exploiting natural redundancy in generated images by merging redundant tokens. After making some diffusion-specific improvements to Token Merging (ToMe), our ToMe for Stable Diffusion can reduce the number of tokens in an existing Stable Diffusion model by up to 60% while still producing high quality images without any extra training. In the process, we speed up image generation by up to 2x and reduce memory consumption by up to 5.6x. Furthermore, this speed-up stacks with efficient implementations such as xFormers, minimally impacting quality while being up to 5.4x faster for large images. Code is available at https://github.com/dbolya/tomesd.
NaviNeRF: NeRF-based 3D Representation Disentanglement by Latent Semantic Navigation
Apr 22, 2023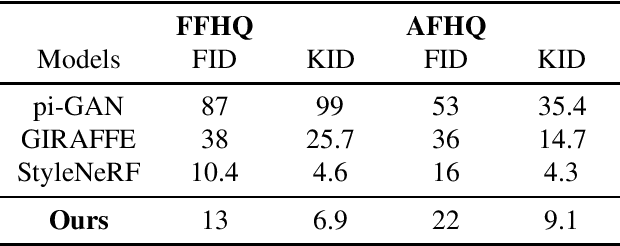
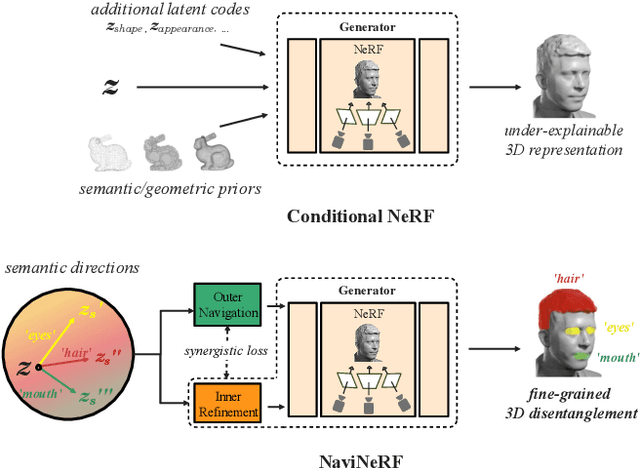
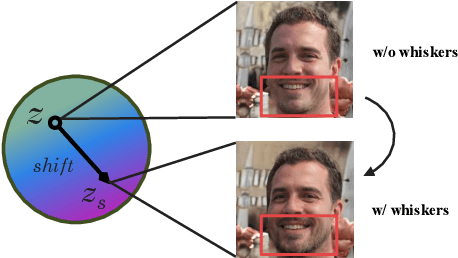
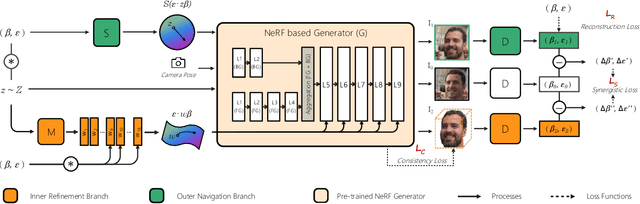
3D representation disentanglement aims to identify, decompose, and manipulate the underlying explanatory factors of 3D data, which helps AI fundamentally understand our 3D world. This task is currently under-explored and poses great challenges: (i) the 3D representations are complex and in general contains much more information than 2D image; (ii) many 3D representations are not well suited for gradient-based optimization, let alone disentanglement. To address these challenges, we use NeRF as a differentiable 3D representation, and introduce a self-supervised Navigation to identify interpretable semantic directions in the latent space. To our best knowledge, this novel method, dubbed NaviNeRF, is the first work to achieve fine-grained 3D disentanglement without any priors or supervisions. Specifically, NaviNeRF is built upon the generative NeRF pipeline, and equipped with an Outer Navigation Branch and an Inner Refinement Branch. They are complementary -- the outer navigation is to identify global-view semantic directions, and the inner refinement dedicates to fine-grained attributes. A synergistic loss is further devised to coordinate two branches. Extensive experiments demonstrate that NaviNeRF has a superior fine-grained 3D disentanglement ability than the previous 3D-aware models. Its performance is also comparable to editing-oriented models relying on semantic or geometry priors.
Implicit Diffusion Models for Continuous Super-Resolution
Mar 29, 2023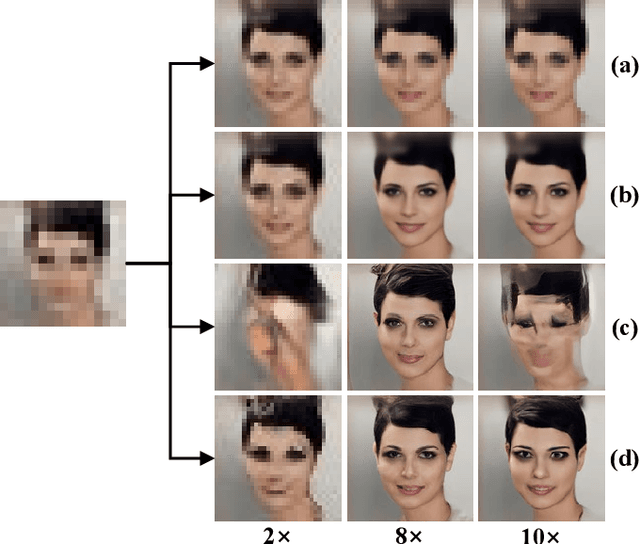


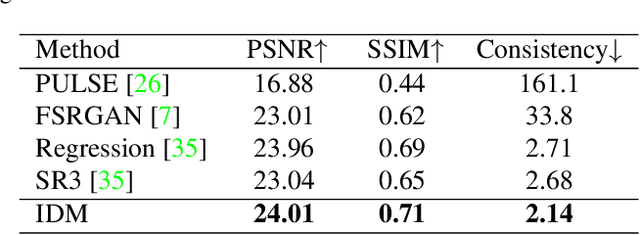
Image super-resolution (SR) has attracted increasing attention due to its wide applications. However, current SR methods generally suffer from over-smoothing and artifacts, and most work only with fixed magnifications. This paper introduces an Implicit Diffusion Model (IDM) for high-fidelity continuous image super-resolution. IDM integrates an implicit neural representation and a denoising diffusion model in a unified end-to-end framework, where the implicit neural representation is adopted in the decoding process to learn continuous-resolution representation. Furthermore, we design a scale-controllable conditioning mechanism that consists of a low-resolution (LR) conditioning network and a scaling factor. The scaling factor regulates the resolution and accordingly modulates the proportion of the LR information and generated features in the final output, which enables the model to accommodate the continuous-resolution requirement. Extensive experiments validate the effectiveness of our IDM and demonstrate its superior performance over prior arts.
Scale space radon transform-based inertia axis and object central symmetry estimation
Mar 22, 2023Inertia Axes are involved in many techniques for image content measurement when involving information obtained from lines, angles, centroids... etc. We investigate, here, the estimation of the main axis of inertia of an object in the image. We identify the coincidence conditions of the Scale Space Radon Transform (SSRT) maximum and the inertia main axis. We show, that by choosing the appropriate scale parameter, it is possible to match the SSRT maximum and the main axis of inertia location and orientation of the embedded object in the image. Furthermore, an example of use case is presented where binary objects central symmetry computation is derived by means of SSRT projections and the axis of inertia orientation. To this end, some SSRT characteristics have been highlighted and exploited. The experimentations show the SSRT-based main axis of inertia computation effectiveness. Concerning the central symmetry, results are very satisfying as experimentations carried out on randomly created images dataset and existing datasets have permitted to divide successfully these images bases into centrally symmetric and non-centrally symmetric objects.