 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Context-Preserving Model-Aware Deep Clustering for Hyperspectral Images
Jun 12, 2025Subspace clustering has become widely adopted for the unsupervised analysis of hyperspectral images (HSIs). Recent model-aware deep subspace clustering methods often use a two-stage framework, involving the calculation of a self-representation matrix with complexity of O(n^2), followed by spectral clustering. However, these methods are computationally intensive, generally incorporating solely either local or non-local spatial structure constraints, and their structural constraints fall short of effectively supervising the entire clustering process. We propose a scalable, context-preserving deep clustering method based on basis representation, which jointly captures local and non-local structures for efficient HSI clustering. To preserve local structure (i.e., spatial continuity within subspaces), we introduce a spatial smoothness constraint that aligns clustering predictions with their spatially filtered versions. For non-local structure (i.e., spectral continuity), we employ a mini-cluster-based scheme that refines predictions at the group level, encouraging spectrally similar pixels to belong to the same subspace. Notably, these two constraints are jointly optimized to reinforce each other. Specifically, our model is designed as an one-stage approach in which the structural constraints are applied to the entire clustering process. The time and space complexity of our method is O(n), making it applicable to large-scale HSI data. Experiments on real-world datasets show that our method outperforms state-of-the-art techniques. Our code is available at: https://github.com/lxlscut/SCDSC
Efficient One-Step Diffusion Refinement for Snapshot Compressive Imaging
Sep 11, 2024



Coded Aperture Snapshot Spectral Imaging (CASSI) is a crucial technique for capturing three-dimensional multispectral images (MSIs) through the complex inverse task of reconstructing these images from coded two-dimensional measurements. Current state-of-the-art methods, predominantly end-to-end, face limitations in reconstructing high-frequency details and often rely on constrained datasets like KAIST and CAVE, resulting in models with poor generalizability. In response to these challenges, this paper introduces a novel one-step Diffusion Probabilistic Model within a self-supervised adaptation framework for Snapshot Compressive Imaging (SCI). Our approach leverages a pretrained SCI reconstruction network to generate initial predictions from two-dimensional measurements. Subsequently, a one-step diffusion model produces high-frequency residuals to enhance these initial predictions. Additionally, acknowledging the high costs associated with collecting MSIs, we develop a self-supervised paradigm based on the Equivariant Imaging (EI) framework. Experimental results validate the superiority of our model compared to previous methods, showcasing its simplicity and adaptability to various end-to-end or unfolding techniques.
Contextuality Helps Representation Learning for Generalized Category Discovery
Jul 29, 2024



This paper introduces a novel approach to Generalized Category Discovery (GCD) by leveraging the concept of contextuality to enhance the identification and classification of categories in unlabeled datasets. Drawing inspiration from human cognition's ability to recognize objects within their context, we propose a dual-context based method. Our model integrates two levels of contextuality: instance-level, where nearest-neighbor contexts are utilized for contrastive learning, and cluster-level, employing prototypical contrastive learning based on category prototypes. The integration of the contextual information effectively improves the feature learning and thereby the classification accuracy of all categories, which better deals with the real-world datasets. Different from the traditional semi-supervised and novel category discovery techniques, our model focuses on a more realistic and challenging scenario where both known and novel categories are present in the unlabeled data. Extensive experimental results on several benchmark data sets demonstrate that the proposed model outperforms the state-of-the-art. Code is available at: https://github.com/Clarence-CV/Contexuality-GCD
Unfolding ADMM for Enhanced Subspace Clustering of Hyperspectral Images
Apr 10, 2024



Deep subspace clustering methods are now prominent in clustering, typically using fully connected networks and a self-representation loss function. However, these methods often struggle with overfitting and lack interpretability. In this paper, we explore an alternative clustering approach based on deep unfolding. By unfolding iterative optimization methods into neural networks, this approach offers enhanced interpretability and reliability compared to data-driven deep learning methods, and greater adaptability and generalization than model-based approaches. Hence, unfolding has become widely used in inverse imaging problems, such as image restoration, reconstruction, and super-resolution, but has not been sufficiently explored yet in the context of clustering. In this work, we introduce an innovative clustering architecture for hyperspectral images (HSI) by unfolding an iterative solver based on the Alternating Direction Method of Multipliers (ADMM) for sparse subspace clustering. To our knowledge, this is the first attempt to apply unfolding ADMM for computing the self-representation matrix in subspace clustering. Moreover, our approach captures well the structural characteristics of HSI data by employing the K nearest neighbors algorithm as part of a structure preservation module. Experimental evaluation of three established HSI datasets shows clearly the potential of the unfolding approach in HSI clustering and even demonstrates superior performance compared to state-of-the-art techniques.
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023



Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
MSFA-Frequency-Aware Transformer for Hyperspectral Images Demosaicing
Mar 23, 2023



Hyperspectral imaging systems that use multispectral filter arrays (MSFA) capture only one spectral component in each pixel. Hyperspectral demosaicing is used to recover the non-measured components. While deep learning methods have shown promise in this area, they still suffer from several challenges, including limited modeling of non-local dependencies, lack of consideration of the periodic MSFA pattern that could be linked to periodic artifacts, and difficulty in recovering high-frequency details. To address these challenges, this paper proposes a novel de-mosaicing framework, the MSFA-frequency-aware Transformer network (FDM-Net). FDM-Net integrates a novel MSFA-frequency-aware multi-head self-attention mechanism (MaFormer) and a filter-based Fourier zero-padding method to reconstruct high pass components with greater difficulty and low pass components with relative ease, separately. The advantage of Maformer is that it can leverage the MSFA information and non-local dependencies present in the data. Additionally, we introduce a joint spatial and frequency loss to transfer MSFA information and enhance training on frequency components that are hard to recover. Our experimental results demonstrate that FDM-Net outperforms state-of-the-art methods with 6dB PSNR, and reconstructs high-fidelity details successfully.
Inheriting Bayer's Legacy-Joint Remosaicing and Denoising for Quad Bayer Image Sensor
Mar 23, 2023Pixel binning based Quad sensors have emerged as a promising solution to overcome the hardware limitations of compact cameras in low-light imaging. However, binning results in lower spatial resolution and non-Bayer CFA artifacts. To address these challenges, we propose a dual-head joint remosaicing and denoising network (DJRD), which enables the conversion of noisy Quad Bayer and standard noise-free Bayer pattern without any resolution loss. DJRD includes a newly designed Quad Bayer remosaicing (QB-Re) block, integrated denoising modules based on Swin-transformer and multi-scale wavelet transform. The QB-Re block constructs the convolution kernel based on the CFA pattern to achieve a periodic color distribution in the perceptual field, which is used to extract exact spectral information and reduce color misalignment. The integrated Swin-Transformer and multi-scale wavelet transform capture non-local dependencies, frequency and location information to effectively reduce practical noise. By identifying challenging patches utilizing Moire and zipper detection metrics, we enable our model to concentrate on difficult patches during the post-training phase, which enhances the model's performance in hard cases. Our proposed model outperforms competing models by approximately 3dB, without additional complexity in hardware or software.
Low-rank Meets Sparseness: An Integrated Spatial-Spectral Total Variation Approach to Hyperspectral Denoising
Apr 27, 2022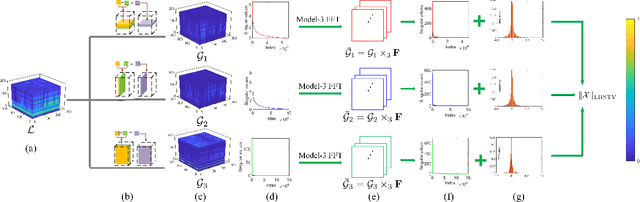

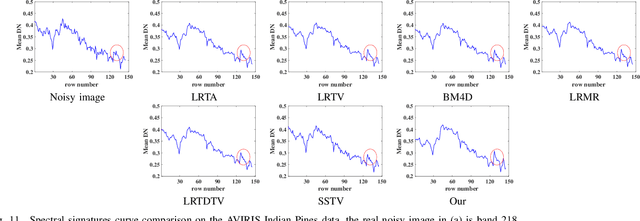

Spatial-Spectral Total Variation (SSTV) can quantify local smoothness of image structures, so it is widely used in hyperspectral image (HSI) processing tasks. Essentially, SSTV assumes a sparse structure of gradient maps calculated along the spatial and spectral directions. In fact, these gradient tensors are not only sparse, but also (approximately) low-rank under FFT, which we have verified by numerical tests and theoretical analysis. Based on this fact, we propose a novel TV regularization to simultaneously characterize the sparsity and low-rank priors of the gradient map (LRSTV). The new regularization not only imposes sparsity on the gradient map itself, but also penalize the rank on the gradient map after Fourier transform along the spectral dimension. It naturally encodes the sparsity and lowrank priors of the gradient map, and thus is expected to reflect the inherent structure of the original image more faithfully. Further, we use LRSTV to replace conventional SSTV and embed it in the HSI processing model to improve its performance. Experimental results on multiple public data-sets with heavy mixed noise show that the proposed model can get 1.5dB improvement of PSNR.