 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Hypercontraction Error Correction Using Regression
Feb 27, 2026Wavefunction-based quantum methods are some of the most accurate tools for predicting and analyzing the electronic structure of molecules, in particular for accounting for dynamical electron correlation. However, most methods of including dynamical correlation beyond the simple second-order Møller-Plesset perturbation theory (MP2) level are too computationally expensive to apply to large molecules. Approximations which reduce scaling with system size are a potential remedy, such as the tensor hyper-contraction (THC) technique of Hohenstein et al., but also result in additional sources of error. In this work, we correct errors in THC-approximated methods using machine learning. Specifically, we apply THC to third-order Møller-Plesset theory (MP3) as a simplified model for coupled cluster with single and double excitations (CCSD), and train several regression models on observed THC errors from the Main Group Chemistry Database (MGCDB84). We compare performance of multiple linear regression models and non-linear Kernel Ridge regression models. We also investigate correlation procedures using absolute and relative corrections and evaluate the corrections for both molecule and reaction energies. We discuss the potential for using regression techniques to correct THC-MP3 errors by comparing it to the "canonical" MP3 reference values and find the optimum technique based on accuracy. We find that non-linear regression models reduced root mean squared errors between THC- and canonical MP3 by a factor of 6-9$\times$ for total molecular energies and 2-3$\times$ for reaction energies.
2Mamba2Furious: Linear in Complexity, Competitive in Accuracy
Feb 19, 2026Linear attention transformers have become a strong alternative to softmax attention due to their efficiency. However, linear attention tends to be less expressive and results in reduced accuracy compared to softmax attention. To bridge the accuracy gap between softmax attention and linear attention, we manipulate Mamba-2, a very strong linear attention variant. We first simplify Mamba-2 down to its most fundamental and important components, evaluating which specific choices make it most accurate. From this simplified Mamba variant (Mamba-2S), we improve the A-mask and increase the order of the hidden state, resulting in a method, which we call 2Mamba, that is nearly as accurate as softmax attention, yet much more memory efficient for long context lengths. We also investigate elements to Mamba-2 that help surpass softmax attention accuracy. Code is provided for all our experiments
On the Expressiveness of Softmax Attention: A Recurrent Neural Network Perspective
Jul 31, 2025



Since its introduction, softmax attention has become the backbone of modern transformer architectures due to its expressiveness and scalability across a wide range of tasks. However, the main drawback of softmax attention is the quadratic memory requirement and computational complexity with respect to the sequence length. By replacing the softmax nonlinearity, linear attention and similar methods have been introduced to avoid the quadratic bottleneck of softmax attention. Despite these linear forms of attention being derived from the original softmax formulation, they typically lag in terms of downstream accuracy. While strong intuition of the softmax nonlinearity on the query and key inner product suggests that it has desirable properties compared to other nonlinearities, the question of why this discrepancy exists still remains unanswered. This work demonstrates that linear attention is an approximation of softmax attention by deriving the recurrent form of softmax attention. Using this form, each part of softmax attention can be described in the language of recurrent neural networks (RNNs). Describing softmax attention as an RNN allows for the ablation of the components of softmax attention to understand the importance of each part and how they interact. In this way, our work helps explain why softmax attention is more expressive than its counterparts.
Equitable Electronic Health Record Prediction with FAME: Fairness-Aware Multimodal Embedding
Jun 16, 2025



Electronic Health Record (EHR) data encompass diverse modalities -- text, images, and medical codes -- that are vital for clinical decision-making. To process these complex data, multimodal AI (MAI) has emerged as a powerful approach for fusing such information. However, most existing MAI models optimize for better prediction performance, potentially reinforcing biases across patient subgroups. Although bias-reduction techniques for multimodal models have been proposed, the individual strengths of each modality and their interplay in both reducing bias and optimizing performance remain underexplored. In this work, we introduce FAME (Fairness-Aware Multimodal Embeddings), a framework that explicitly weights each modality according to its fairness contribution. FAME optimizes both performance and fairness by incorporating a combined loss function. We leverage the Error Distribution Disparity Index (EDDI) to measure fairness across subgroups and propose a sign-agnostic aggregation method to balance fairness across subgroups, ensuring equitable model outcomes. We evaluate FAME with BEHRT and BioClinicalBERT, combining structured and unstructured EHR data, and demonstrate its effectiveness in terms of performance and fairness compared with other baselines across multiple EHR prediction tasks.
Cottention: Linear Transformers With Cosine Attention
Sep 27, 2024



Attention mechanisms, particularly softmax attention, have been instrumental in the success of transformer-based models such as GPT. However, the quadratic memory complexity of softmax attention with respect to sequence length poses significant challenges for processing longer sequences. We introduce Cottention, a novel attention mechanism that replaces the softmax operation with cosine similarity. By leveraging the properties of cosine similarity and rearranging the attention equation, Cottention achieves native linear memory complexity with respect to sequence length, making it inherently more memory-efficient than softmax attention. We demonstrate that Cottention can be reformulated as a recurrent neural network (RNN) with a finite hidden state, allowing for constant memory usage during inference. We evaluate Cottention on both the bidirectional BERT and causal GPT tasks, demonstrating comparable performance to softmax attention while significantly reducing memory requirements. To ensure efficient computation, we develop a custom CUDA kernel for Cottention. Our results show that Cottention is a promising alternative to softmax attention, enabling the processing of longer sequences without sacrificing performance, due to its native linear memory complexity and ability to maintain a constant memory footprint during inference.
Scaling Continuous Kernels with Sparse Fourier Domain Learning
Sep 15, 2024



We address three key challenges in learning continuous kernel representations: computational efficiency, parameter efficiency, and spectral bias. Continuous kernels have shown significant potential, but their practical adoption is often limited by high computational and memory demands. Additionally, these methods are prone to spectral bias, which impedes their ability to capture high-frequency details. To overcome these limitations, we propose a novel approach that leverages sparse learning in the Fourier domain. Our method enables the efficient scaling of continuous kernels, drastically reduces computational and memory requirements, and mitigates spectral bias by exploiting the Gibbs phenomenon.
Digit Recognition using Multimodal Spiking Neural Networks
Aug 31, 2024


Spiking neural networks (SNNs) are the third generation of neural networks that are biologically inspired to process data in a fashion that emulates the exchange of signals in the brain. Within the Computer Vision community SNNs have garnered significant attention due in large part to the availability of event-based sensors that produce a spatially resolved spike train in response to changes in scene radiance. SNNs are used to process event-based data due to their neuromorphic nature. The proposed work examines the neuromorphic advantage of fusing multiple sensory inputs in classification tasks. Specifically we study the performance of a SNN in digit classification by passing in a visual modality branch (Neuromorphic-MNIST [N-MNIST]) and an auditory modality branch (Spiking Heidelberg Digits [SHD]) from datasets that were created using event-based sensors to generate a series of time-dependent events. It is observed that multi-modal SNNs outperform unimodal visual and unimodal auditory SNNs. Furthermore, it is observed that the process of sensory fusion is insensitive to the depth at which the visual and auditory branches are combined. This work achieves a 98.43% accuracy on the combined N-MNIST and SHD dataset using a multimodal SNN that concatenates the visual and auditory branches at a late depth.
A Photonic Physically Unclonable Function's Resilience to Multiple-Valued Machine Learning Attacks
Mar 02, 2024



Physically unclonable functions (PUFs) identify integrated circuits using nonlinearly-related challenge-response pairs (CRPs). Ideally, the relationship between challenges and corresponding responses is unpredictable, even if a subset of CRPs is known. Previous work developed a photonic PUF offering improved security compared to non-optical counterparts. Here, we investigate this PUF's susceptibility to Multiple-Valued-Logic-based machine learning attacks. We find that approximately 1,000 CRPs are necessary to train models that predict response bits better than random chance. Given the significant challenge of acquiring a vast number of CRPs from a photonic PUF, our results demonstrate photonic PUF resilience against such attacks.
CNN-Assisted Steganography -- Integrating Machine Learning with Established Steganographic Techniques
Apr 25, 2023



We propose a method to improve steganography by increasing the resilience of stego-media to discovery through steganalysis. Our approach enhances a class of steganographic approaches through the inclusion of a steganographic assistant convolutional neural network (SA-CNN). Previous research showed success in discovering the presence of hidden information within stego-images using trained neural networks as steganalyzers that are applied to stego-images. Our results show that such steganalyzers are less effective when SA-CNN is employed during the generation of a stego-image. We also explore the advantages and disadvantages of representing all the possible outputs of our SA-CNN within a smaller, discrete space, rather than a continuous space. Our SA-CNN enables certain classes of parametric steganographic algorithms to be customized based on characteristics of the cover media in which information is to be embedded. Thus, SA-CNN is adaptive in the sense that it enables the core steganographic algorithm to be especially configured for each particular instance of cover media. Experimental results are provided that employ a recent steganographic technique, S-UNIWARD, both with and without the use of SA-CNN. We then apply both sets of stego-images, those produced with and without SA-CNN, to an exmaple steganalyzer, Yedroudj-Net, and we compare the results. We believe that this approach for the integration of neural networks with hand-crafted algorithms increases the reliability and adaptability of steganographic algorithms.
Smartphone Camera Oximetry in an Induced Hypoxemia Study
Mar 31, 2021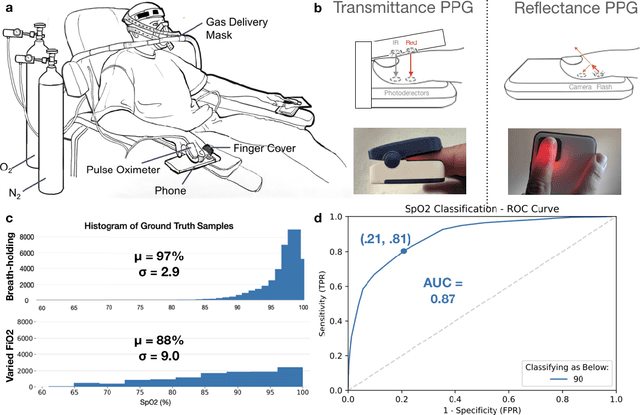
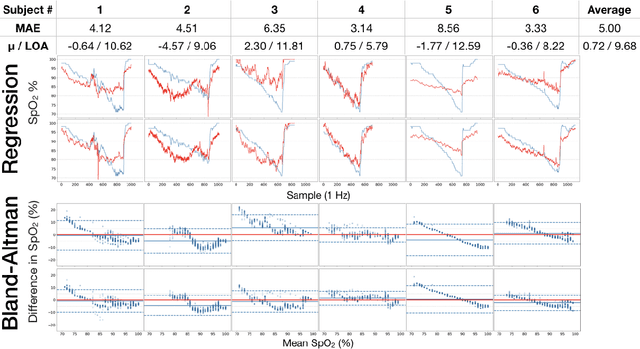
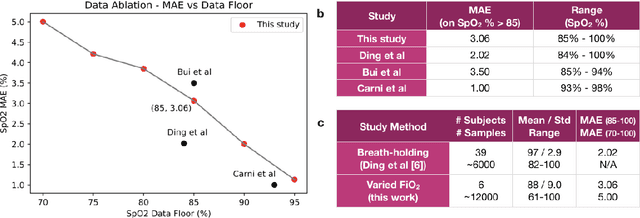
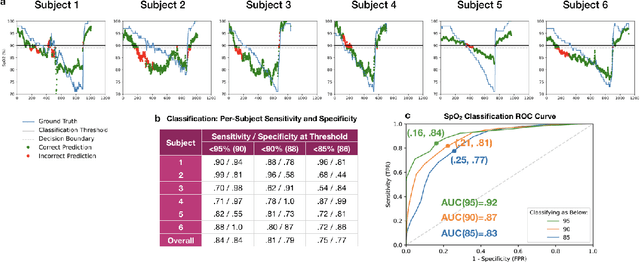
Hypoxemia, a medical condition that occurs when the blood is not carrying enough oxygen to adequately supply the tissues, is a leading indicator for dangerous complications of respiratory diseases like asthma, COPD, and COVID-19. While purpose-built pulse oximeters can provide accurate blood-oxygen saturation (SpO$_2$) readings that allow for diagnosis of hypoxemia, enabling this capability in unmodified smartphone cameras via a software update could give more people access to important information about their health, as well as improve physicians' ability to remotely diagnose and treat respiratory conditions. In this work, we take a step towards this goal by performing the first clinical development validation on a smartphone-based SpO$_2$ sensing system using a varied fraction of inspired oxygen (FiO$_2$) protocol, creating a clinically relevant validation dataset for solely smartphone-based methods on a wide range of SpO$_2$ values (70%-100%) for the first time. This contrasts with previous studies, which evaluated performance on a far smaller range (85%-100%). We build a deep learning model using this data to demonstrate accurate reporting of SpO$_2$ level with an overall MAE=5.00% SpO$_2$ and identifying positive cases of low SpO$_2$<90% with 81% sensitivity and 79% specificity. We ground our analysis with a summary of recent literature in smartphone-based SpO2 monitoring, and we provide the data from the FiO$_2$ study in open-source format, so that others may build on this work.