 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Incremental 3D Semantic Scene Graph Prediction from RGB Sequences
May 04, 2023
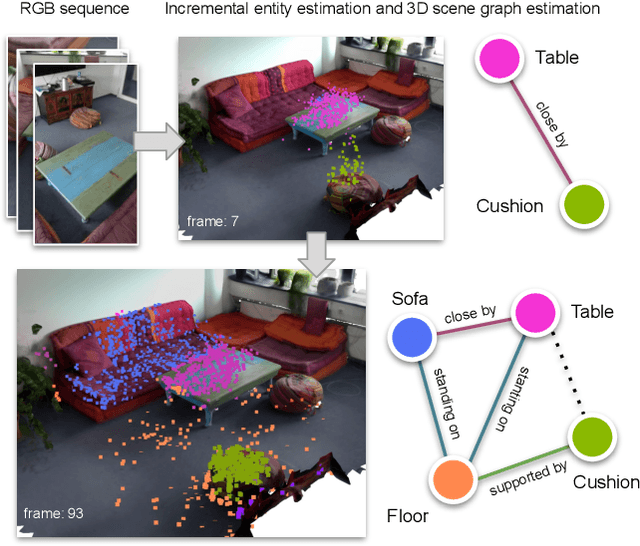
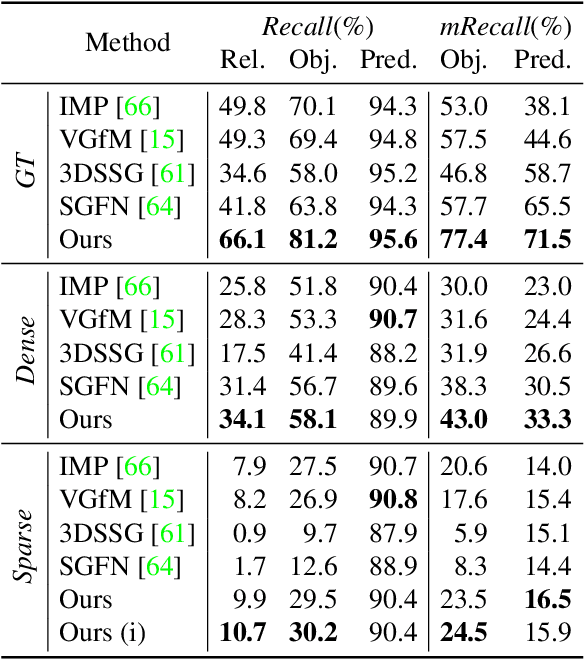
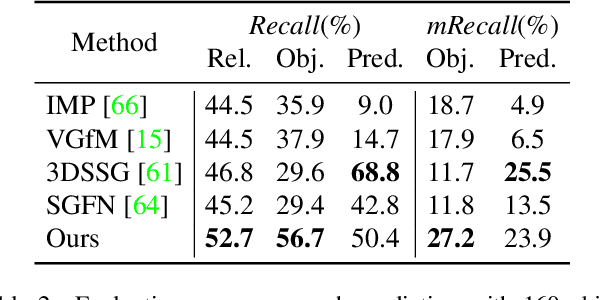
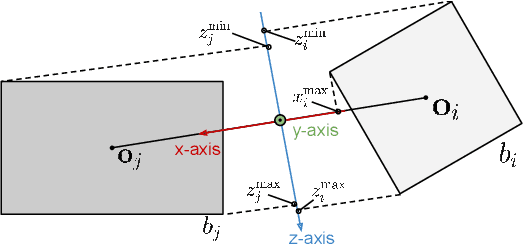
D semantic scene graphs are a powerful holistic representation as they describe the individual objects and depict the relation between them. They are compact high-level graphs that enable many tasks requiring scene reasoning. In real-world settings, existing 3D estimation methods produce robust predictions that mostly rely on dense inputs. In this work, we propose a real-time framework that incrementally builds a consistent 3D semantic scene graph of a scene given an RGB image sequence. Our method consists of a novel incremental entity estimation pipeline and a scene graph prediction network. The proposed pipeline simultaneously reconstructs a sparse point map and fuses entity estimation from the input images. The proposed network estimates 3D semantic scene graphs with iterative message passing using multi-view and geometric features extracted from the scene entities. Extensive experiments on the 3RScan dataset show the effectiveness of the proposed method in this challenging task, outperforming state-of-the-art approaches.
Analyzing the Domain Shift Immunity of Deep Homography Estimation
Apr 19, 2023



Homography estimation is a basic image-alignment method in many applications. Recently, with the development of convolutional neural networks (CNNs), some learning based approaches have shown great success in this task. However, the performance across different domains has never been researched. Unlike other common tasks (\eg, classification, detection, segmentation), CNN based homography estimation models show a domain shift immunity, which means a model can be trained on one dataset and tested on another without any transfer learning. To explain this unusual performance, we need to determine how CNNs estimate homography. In this study, we first show the domain shift immunity of different deep homography estimation models. We then use a shallow network with a specially designed dataset to analyze the features used for estimation. The results show that networks use low-level texture information to estimate homography. We also design some experiments to compare the performance between different texture densities and image features distorted on some common datasets to demonstrate our findings. Based on these findings, we provide an explanation of the domain shift immunity of deep homography estimation.
ContraCluster: Learning to Classify without Labels by Contrastive Self-Supervision and Prototype-Based Semi-Supervision
Apr 19, 2023
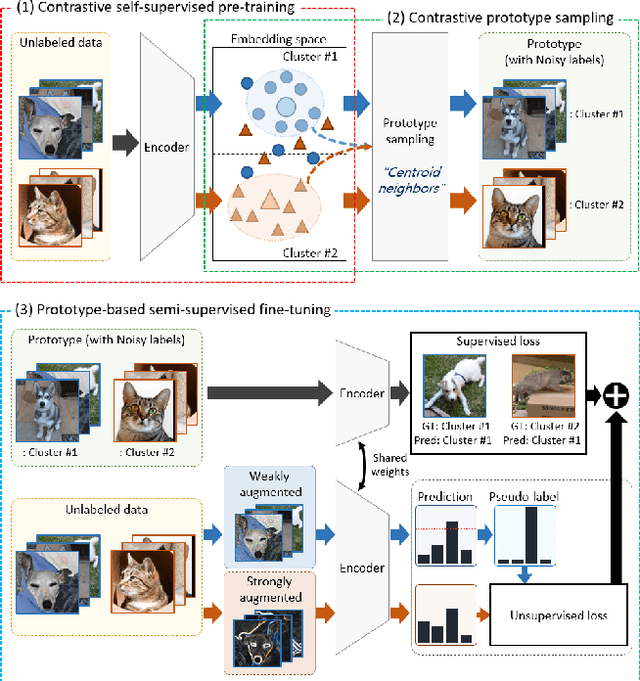
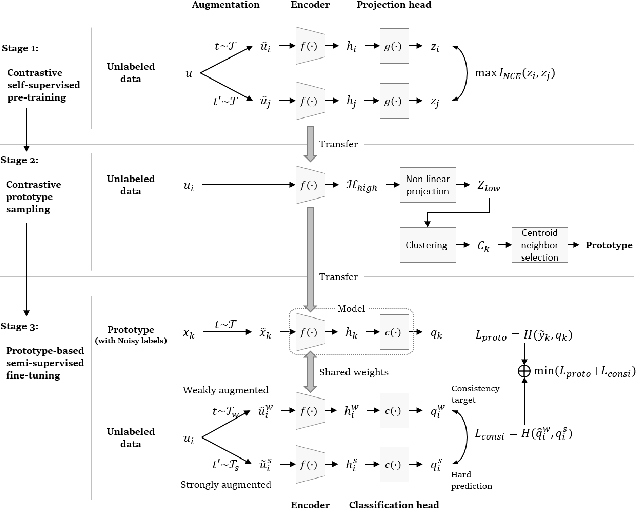
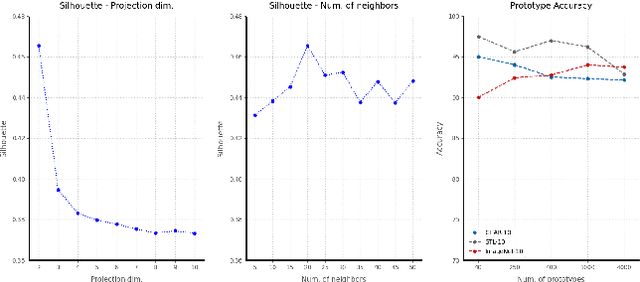
The recent advances in representation learning inspire us to take on the challenging problem of unsupervised image classification tasks in a principled way. We propose ContraCluster, an unsupervised image classification method that combines clustering with the power of contrastive self-supervised learning. ContraCluster consists of three stages: (1) contrastive self-supervised pre-training (CPT), (2) contrastive prototype sampling (CPS), and (3) prototype-based semi-supervised fine-tuning (PB-SFT). CPS can select highly accurate, categorically prototypical images in an embedding space learned by contrastive learning. We use sampled prototypes as noisy labeled data to perform semi-supervised fine-tuning (PB-SFT), leveraging small prototypes and large unlabeled data to further enhance the accuracy. We demonstrate empirically that ContraCluster achieves new state-of-the-art results for standard benchmark datasets including CIFAR-10, STL-10, and ImageNet-10. For example, ContraCluster achieves about 90.8% accuracy for CIFAR-10, which outperforms DAC (52.2%), IIC (61.7%), and SCAN (87.6%) by a large margin. Without any labels, ContraCluster can achieve a 90.8% accuracy that is comparable to 95.8% by the best supervised counterpart.
* Accepted at ICPR 2022
AV-SAM: Segment Anything Model Meets Audio-Visual Localization and Segmentation
May 03, 2023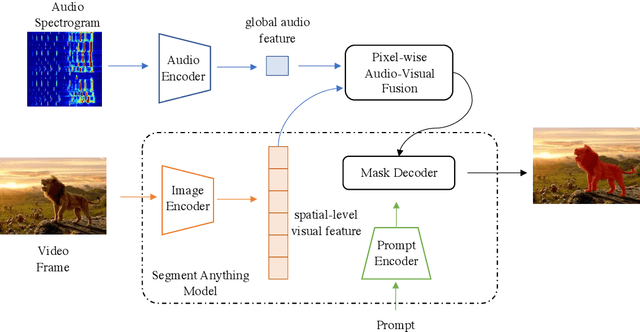
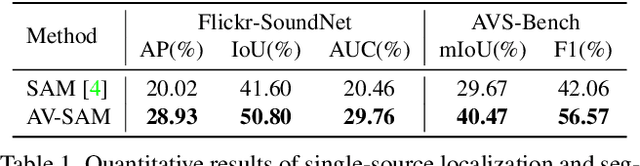


Segment Anything Model (SAM) has recently shown its powerful effectiveness in visual segmentation tasks. However, there is less exploration concerning how SAM works on audio-visual tasks, such as visual sound localization and segmentation. In this work, we propose a simple yet effective audio-visual localization and segmentation framework based on the Segment Anything Model, namely AV-SAM, that can generate sounding object masks corresponding to the audio. Specifically, our AV-SAM simply leverages pixel-wise audio-visual fusion across audio features and visual features from the pre-trained image encoder in SAM to aggregate cross-modal representations. Then, the aggregated cross-modal features are fed into the prompt encoder and mask decoder to generate the final audio-visual segmentation masks. We conduct extensive experiments on Flickr-SoundNet and AVSBench datasets. The results demonstrate that the proposed AV-SAM can achieve competitive performance on sounding object localization and segmentation.
Pay Attention: Accuracy Versus Interpretability Trade-off in Fine-tuned Diffusion Models
Mar 31, 2023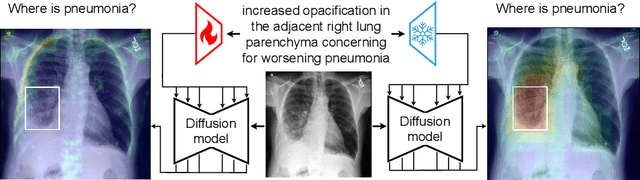
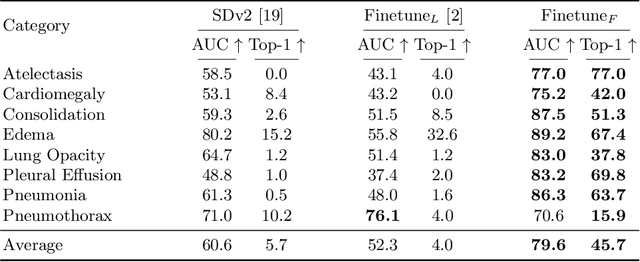
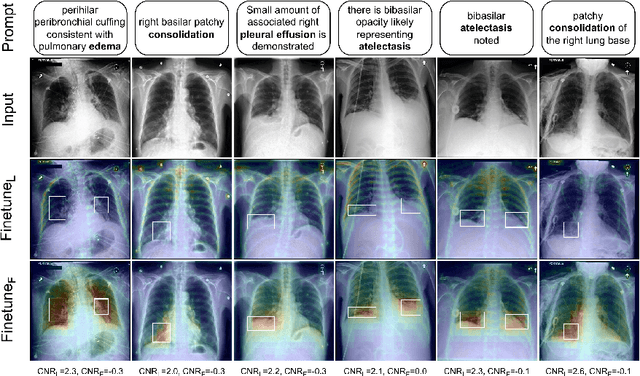
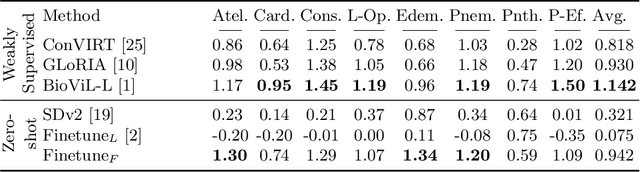
The recent progress of diffusion models in terms of image quality has led to a major shift in research related to generative models. Current approaches often fine-tune pre-trained foundation models using domain-specific text-to-image pairs. This approach is straightforward for X-ray image generation due to the high availability of radiology reports linked to specific images. However, current approaches hardly ever look at attention layers to verify whether the models understand what they are generating. In this paper, we discover an important trade-off between image fidelity and interpretability in generative diffusion models. In particular, we show that fine-tuning text-to-image models with learnable text encoder leads to a lack of interpretability of diffusion models. Finally, we demonstrate the interpretability of diffusion models by showing that keeping the language encoder frozen, enables diffusion models to achieve state-of-the-art phrase grounding performance on certain diseases for a challenging multi-label segmentation task, without any additional training. Code and models will be available at https://github.com/MischaD/chest-distillation.
LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation
Apr 22, 2023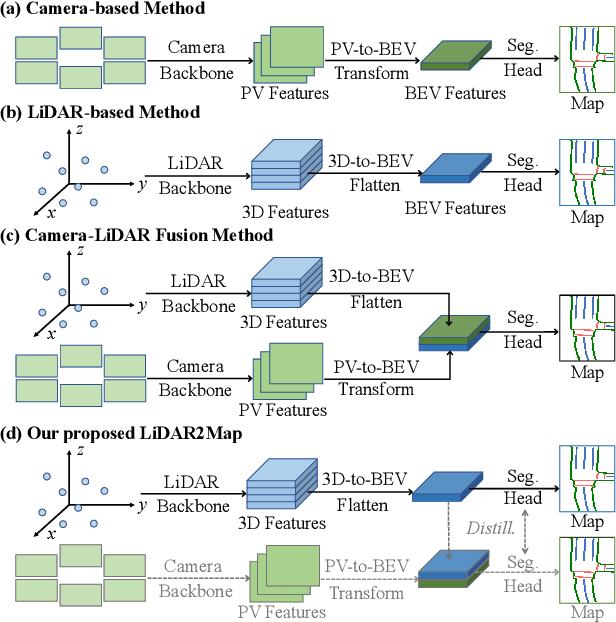
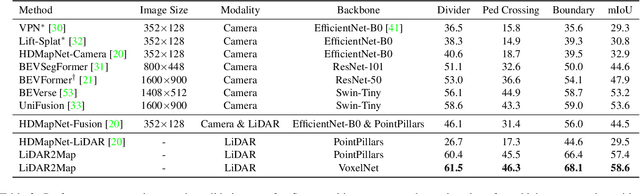
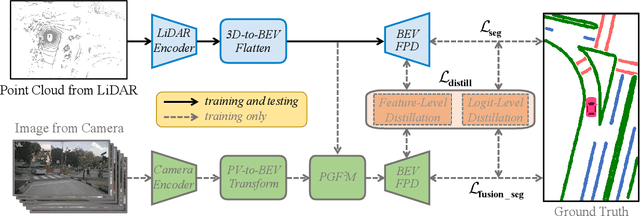
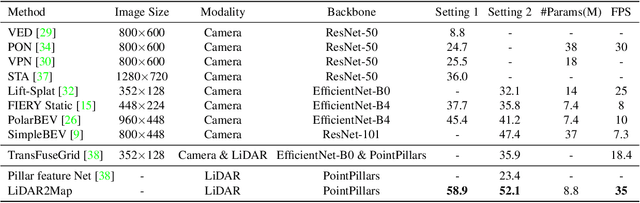
Semantic map construction under bird's-eye view (BEV) plays an essential role in autonomous driving. In contrast to camera image, LiDAR provides the accurate 3D observations to project the captured 3D features onto BEV space inherently. However, the vanilla LiDAR-based BEV feature often contains many indefinite noises, where the spatial features have little texture and semantic cues. In this paper, we propose an effective LiDAR-based method to build semantic map. Specifically, we introduce a BEV pyramid feature decoder that learns the robust multi-scale BEV features for semantic map construction, which greatly boosts the accuracy of the LiDAR-based method. To mitigate the defects caused by lacking semantic cues in LiDAR data, we present an online Camera-to-LiDAR distillation scheme to facilitate the semantic learning from image to point cloud. Our distillation scheme consists of feature-level and logit-level distillation to absorb the semantic information from camera in BEV. The experimental results on challenging nuScenes dataset demonstrate the efficacy of our proposed LiDAR2Map on semantic map construction, which significantly outperforms the previous LiDAR-based methods over 27.9% mIoU and even performs better than the state-of-the-art camera-based approaches. Source code is available at: https://github.com/songw-zju/LiDAR2Map.
RSFDM-Net: Real-time Spatial and Frequency Domains Modulation Network for Underwater Image Enhancement
Feb 23, 2023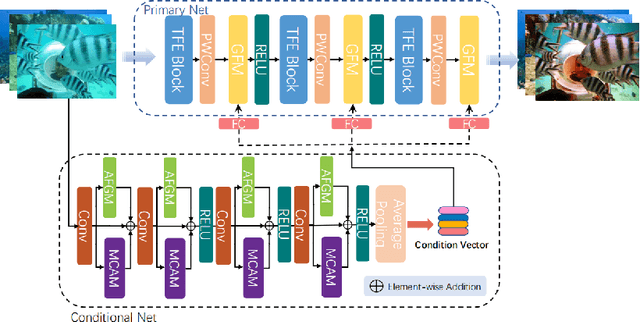

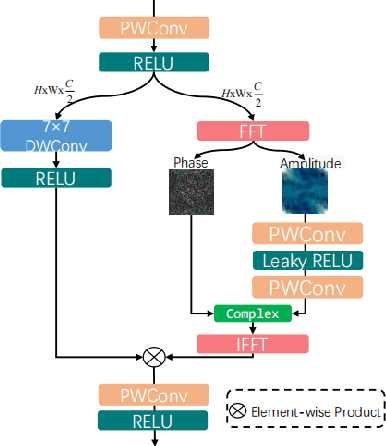
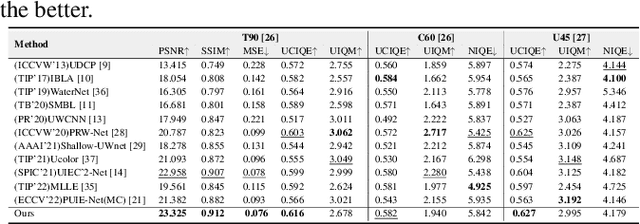
Underwater images typically experience mixed degradations of brightness and structure caused by the absorption and scattering of light by suspended particles. To address this issue, we propose a Real-time Spatial and Frequency Domains Modulation Network (RSFDM-Net) for the efficient enhancement of colors and details in underwater images. Specifically, our proposed conditional network is designed with Adaptive Fourier Gating Mechanism (AFGM) and Multiscale Convolutional Attention Module (MCAM) to generate vectors carrying low-frequency background information and high-frequency detail features, which effectively promote the network to model global background information and local texture details. To more precisely correct the color cast and low saturation of the image, we introduce a Three-branch Feature Extraction (TFE) block in the primary net that processes images pixel by pixel to integrate the color information extended by the same channel (R, G, or B). This block consists of three small branches, each of which has its own weights. Extensive experiments demonstrate that our network significantly outperforms over state-of-the-art methods in both visual quality and quantitative metrics.
Do humans and machines have the same eyes? Human-machine perceptual differences on image classification
Apr 18, 2023
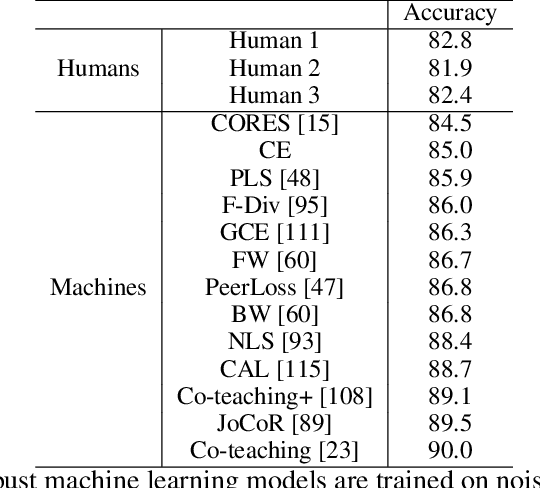
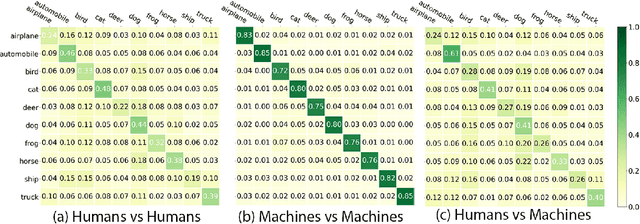
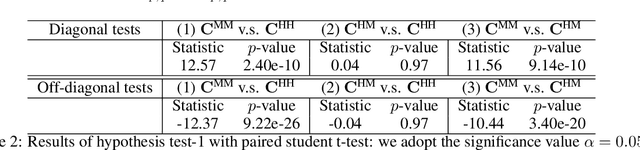
Trained computer vision models are assumed to solve vision tasks by imitating human behavior learned from training labels. Most efforts in recent vision research focus on measuring the model task performance using standardized benchmarks. Limited work has been done to understand the perceptual difference between humans and machines. To fill this gap, our study first quantifies and analyzes the statistical distributions of mistakes from the two sources. We then explore human vs. machine expertise after ranking tasks by difficulty levels. Even when humans and machines have similar overall accuracies, the distribution of answers may vary. Leveraging the perceptual difference between humans and machines, we empirically demonstrate a post-hoc human-machine collaboration that outperforms humans or machines alone.
Multi-Reference Image Super-Resolution: A Posterior Fusion Approach
Dec 20, 2022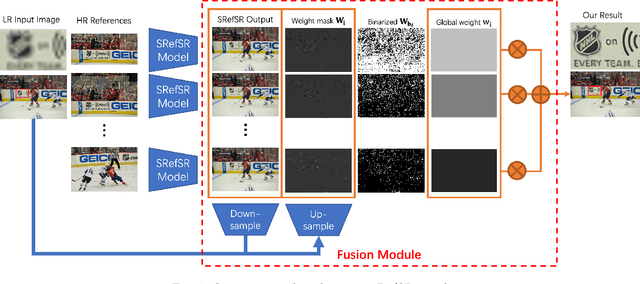

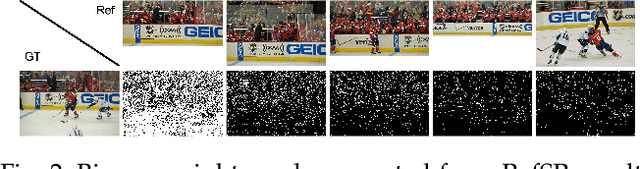
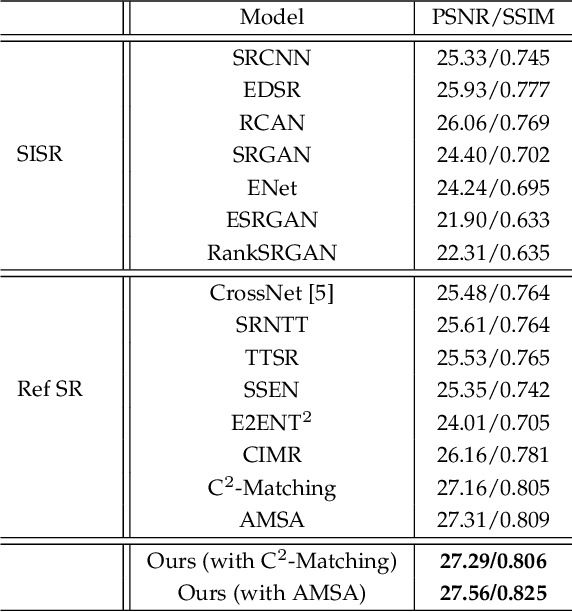
Reference-based Super-resolution (RefSR) approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution image. Multi-reference super-resolution extends this approach by allowing more information to be incorporated. This paper proposes a 2-step-weighting posterior fusion approach to combine the outputs of RefSR models with multiple references. Extensive experiments on the CUFED5 dataset demonstrate that the proposed methods can be applied to various state-of-the-art RefSR models to get a consistent improvement in image quality.
Uncertainty-Aware Semi-Supervised Learning for Prostate MRI Zonal Segmentation
May 10, 2023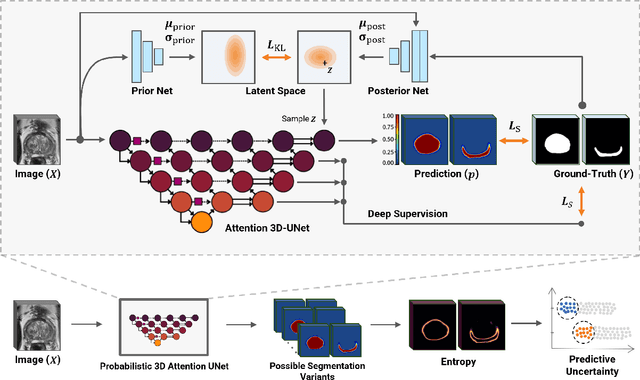
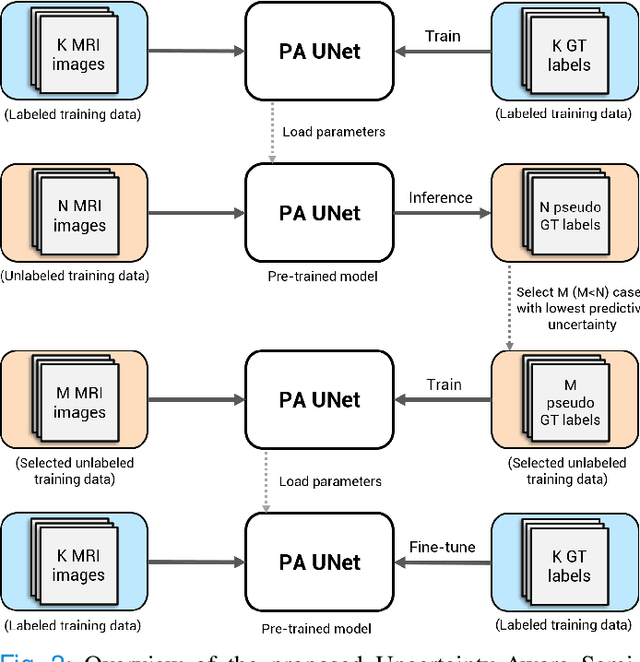
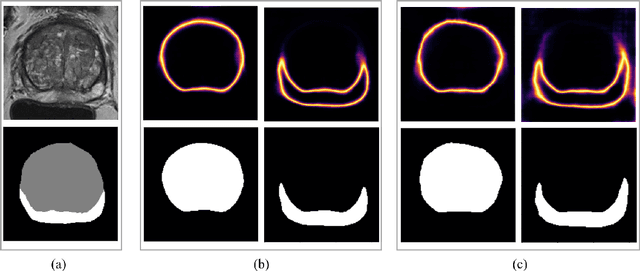
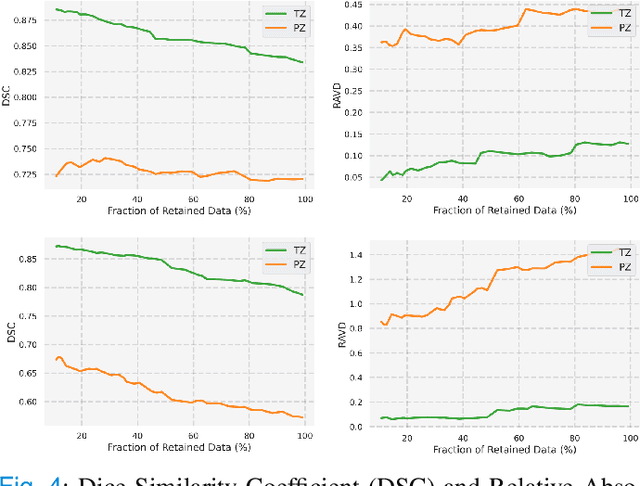
Quality of deep convolutional neural network predictions strongly depends on the size of the training dataset and the quality of the annotations. Creating annotations, especially for 3D medical image segmentation, is time-consuming and requires expert knowledge. We propose a novel semi-supervised learning (SSL) approach that requires only a relatively small number of annotations while being able to use the remaining unlabeled data to improve model performance. Our method uses a pseudo-labeling technique that employs recent deep learning uncertainty estimation models. By using the estimated uncertainty, we were able to rank pseudo-labels and automatically select the best pseudo-annotations generated by the supervised model. We applied this to prostate zonal segmentation in T2-weighted MRI scans. Our proposed model outperformed the semi-supervised model in experiments with the ProstateX dataset and an external test set, by leveraging only a subset of unlabeled data rather than the full collection of 4953 cases, our proposed model demonstrated improved performance. The segmentation dice similarity coefficient in the transition zone and peripheral zone increased from 0.835 and 0.727 to 0.852 and 0.751, respectively, for fully supervised model and the uncertainty-aware semi-supervised learning model (USSL). Our USSL model demonstrates the potential to allow deep learning models to be trained on large datasets without requiring full annotation. Our code is available at https://github.com/DIAGNijmegen/prostateMR-USSL.