 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RSIR Transformer: Hierarchical Vision Transformer using Random Sampling Windows and Important Region Windows
Apr 13, 2023
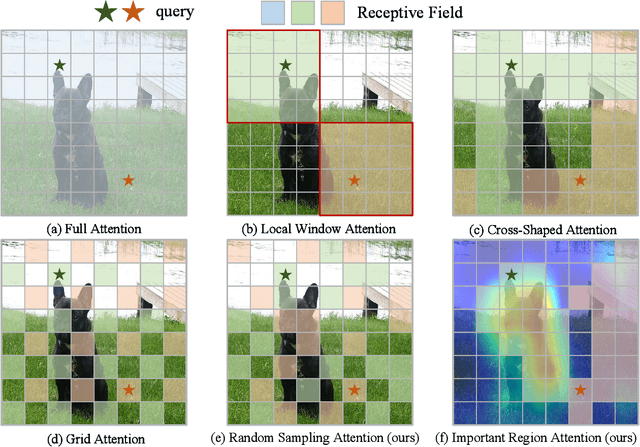
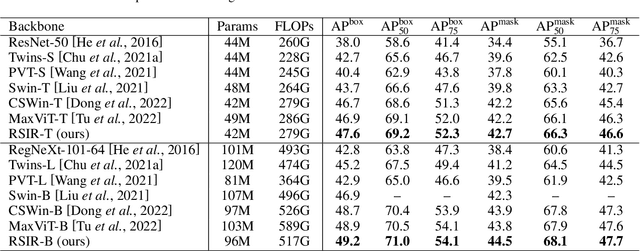
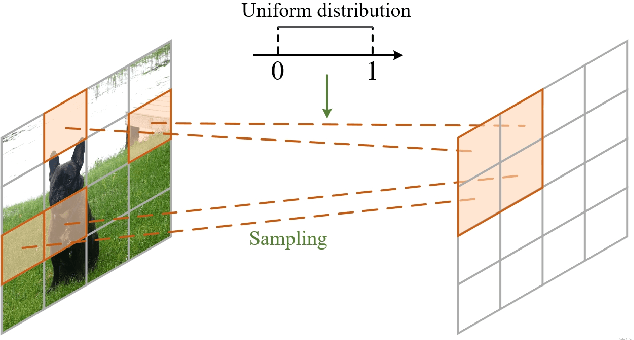
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Local self-attention runs attention computation within a limited region for the sake of efficiency, resulting in insufficient context modeling as their receptive fields are small. In this work, we introduce two new attention modules to enhance the global modeling capability of the hierarchical vision transformer, namely, random sampling windows (RS-Win) and important region windows (IR-Win). Specifically, RS-Win sample random image patches to compose the window, following a uniform distribution, i.e., the patches in RS-Win can come from any position in the image. IR-Win composes the window according to the weights of the image patches in the attention map. Notably, RS-Win is able to capture global information throughout the entire model, even in earlier, high-resolution stages. IR-Win enables the self-attention module to focus on important regions of the image and capture more informative features. Incorporated with these designs, RSIR-Win Transformer demonstrates competitive performance on common vision tasks.
Learning Controllable 3D Diffusion Models from Single-view Images
Apr 13, 2023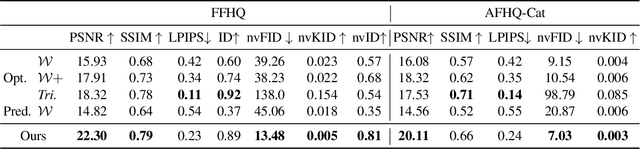

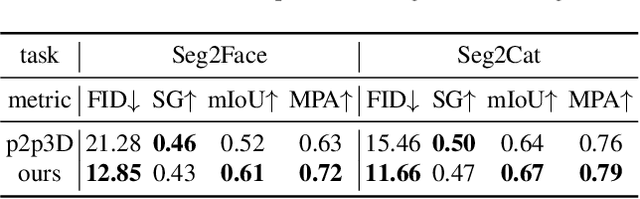
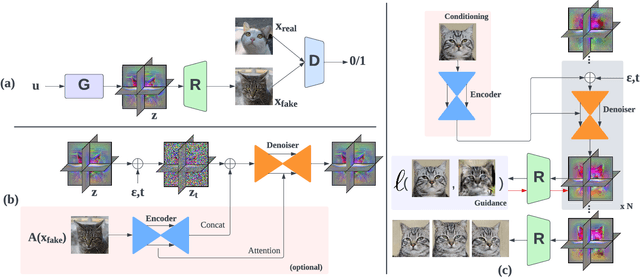
Diffusion models have recently become the de-facto approach for generative modeling in the 2D domain. However, extending diffusion models to 3D is challenging due to the difficulties in acquiring 3D ground truth data for training. On the other hand, 3D GANs that integrate implicit 3D representations into GANs have shown remarkable 3D-aware generation when trained only on single-view image datasets. However, 3D GANs do not provide straightforward ways to precisely control image synthesis. To address these challenges, We present Control3Diff, a 3D diffusion model that combines the strengths of diffusion models and 3D GANs for versatile, controllable 3D-aware image synthesis for single-view datasets. Control3Diff explicitly models the underlying latent distribution (optionally conditioned on external inputs), thus enabling direct control during the diffusion process. Moreover, our approach is general and applicable to any type of controlling input, allowing us to train it with the same diffusion objective without any auxiliary supervision. We validate the efficacy of Control3Diff on standard image generation benchmarks, including FFHQ, AFHQ, and ShapeNet, using various conditioning inputs such as images, sketches, and text prompts. Please see the project website (\url{https://jiataogu.me/control3diff}) for video comparisons.
Segment Anything Model (SAM) for Digital Pathology: Assess Zero-shot Segmentation on Whole Slide Imaging
Apr 09, 2023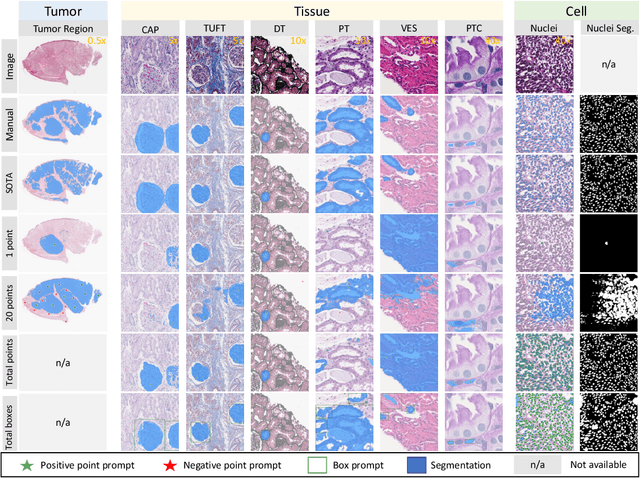
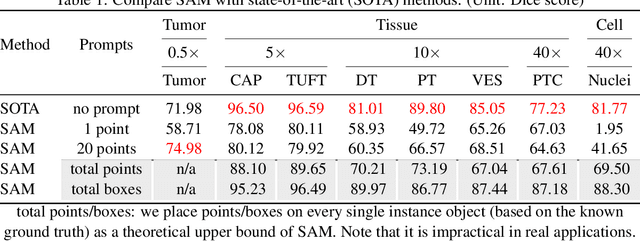
The segment anything model (SAM) was released as a foundation model for image segmentation. The promptable segmentation model was trained by over 1 billion masks on 11M licensed and privacy-respecting images. The model supports zero-shot image segmentation with various segmentation prompts (e.g., points, boxes, masks). It makes the SAM attractive for medical image analysis, especially for digital pathology where the training data are rare. In this study, we evaluate the zero-shot segmentation performance of SAM model on representative segmentation tasks on whole slide imaging (WSI), including (1) tumor segmentation, (2) non-tumor tissue segmentation, (3) cell nuclei segmentation. Core Results: The results suggest that the zero-shot SAM model achieves remarkable segmentation performance for large connected objects. However, it does not consistently achieve satisfying performance for dense instance object segmentation, even with 20 prompts (clicks/boxes) on each image. We also summarized the identified limitations for digital pathology: (1) image resolution, (2) multiple scales, (3) prompt selection, and (4) model fine-tuning. In the future, the few-shot fine-tuning with images from downstream pathological segmentation tasks might help the model to achieve better performance in dense object segmentation.
Vision Langauge Pre-training by Contrastive Learning with Cross-Modal Similarity Regulation
May 09, 2023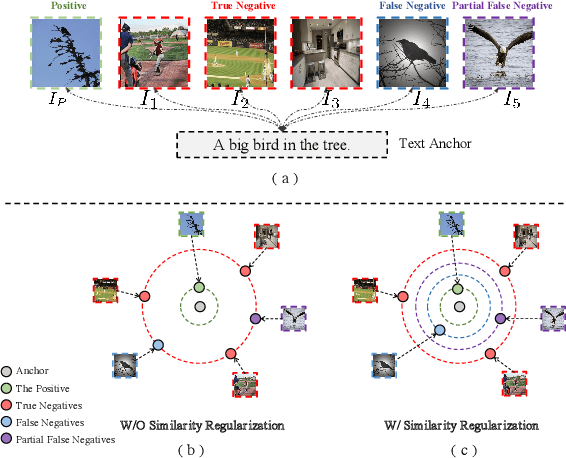
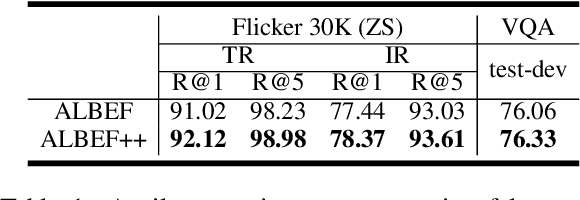
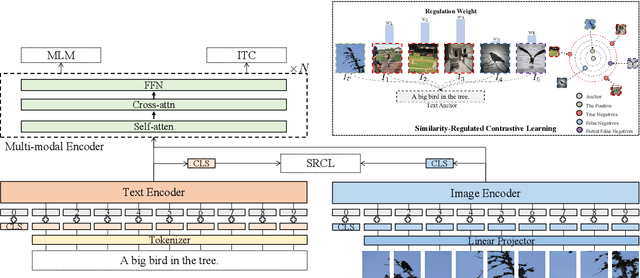
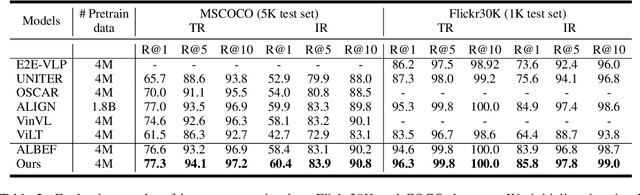
Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
Fully 3D Implementation of the End-to-end Deep Image Prior-based PET Image Reconstruction Using Block Iterative Algorithm
Dec 22, 2022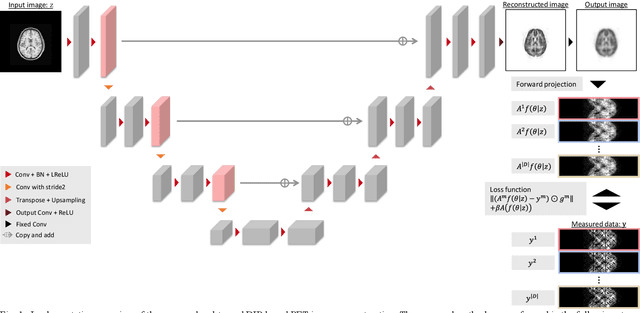
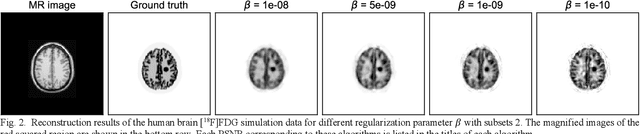
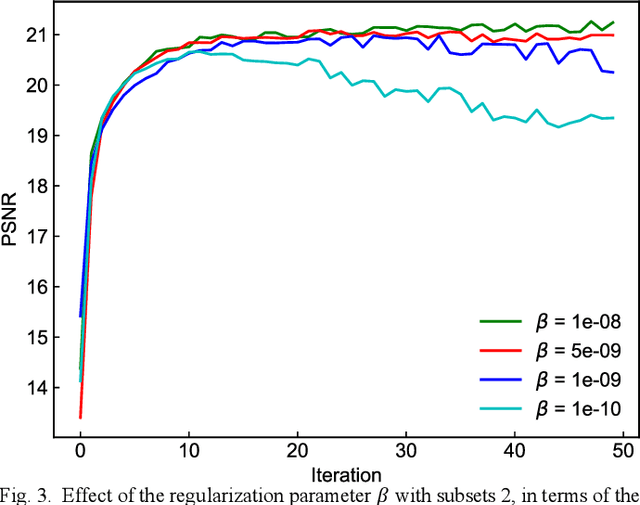
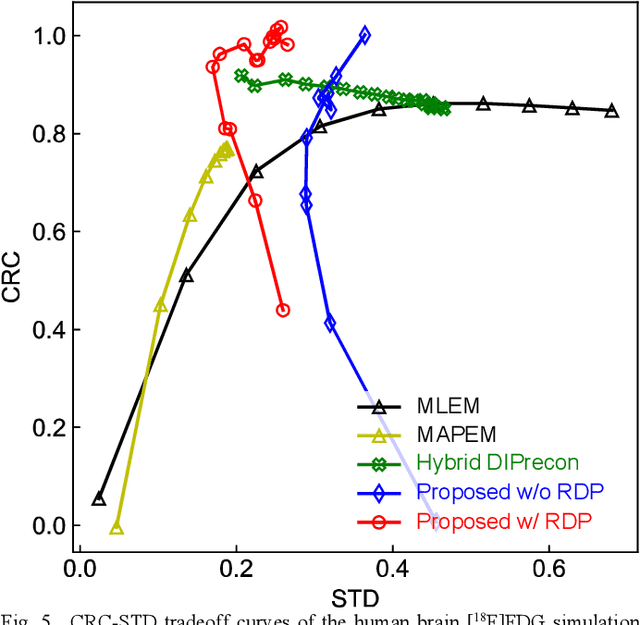
Deep image prior (DIP) has recently attracted attention owing to its unsupervised positron emission tomography (PET) image reconstruction, which does not require any prior training dataset. In this paper, we present the first attempt to implement an end-to-end DIP-based fully 3D PET image reconstruction method that incorporates a forward-projection model into a loss function. To implement a practical fully 3D PET image reconstruction, which could not be performed due to a graphics processing unit memory limitation, we modify the DIP optimization to block-iteration and sequentially learn an ordered sequence of block sinograms. Furthermore, the relative difference penalty (RDP) term was added to the loss function to enhance the quantitative PET image accuracy. We evaluated our proposed method using Monte Carlo simulation with [$^{18}$F]FDG PET data of a human brain and a preclinical study on monkey brain [$^{18}$F]FDG PET data. The proposed method was compared with the maximum-likelihood expectation maximization (EM), maximum-a-posterior EM with RDP, and hybrid DIP-based PET reconstruction methods. The simulation results showed that the proposed method improved the PET image quality by reducing statistical noise and preserved a contrast of brain structures and inserted tumor compared with other algorithms. In the preclinical experiment, finer structures and better contrast recovery were obtained by the proposed method. This indicated that the proposed method can produce high-quality images without a prior training dataset. Thus, the proposed method is a key enabling technology for the straightforward and practical implementation of end-to-end DIP-based fully 3D PET image reconstruction.
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023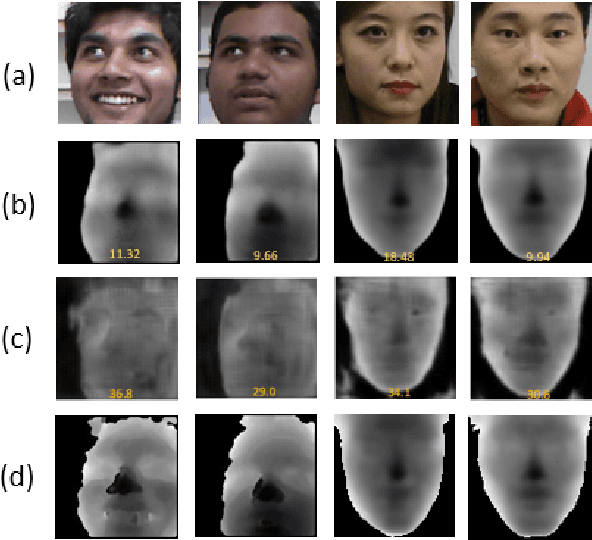

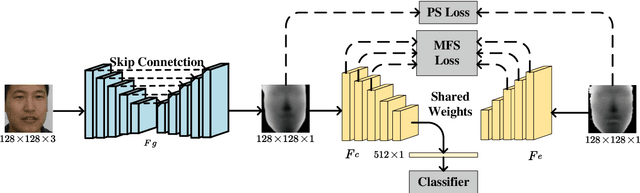

Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
Linking Representations with Multimodal Contrastive Learning
Apr 11, 2023
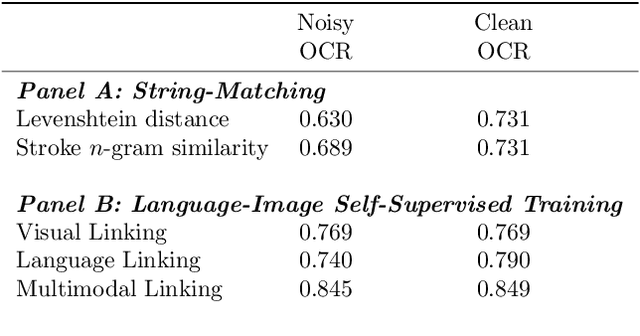
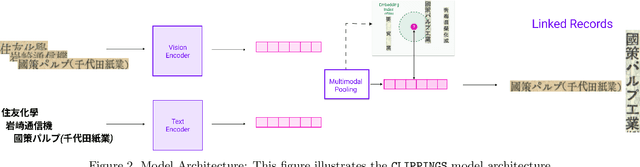
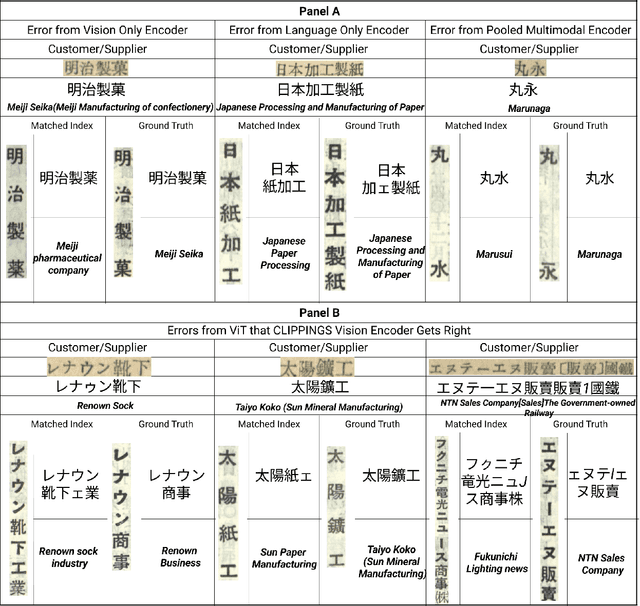
Many applications require grouping instances contained in diverse document datasets into classes. Most widely used methods do not employ deep learning and do not exploit the inherently multimodal nature of documents. Notably, record linkage is typically conceptualized as a string-matching problem. This study develops CLIPPINGS, (Contrastively Linking Pooled Pre-trained Embeddings), a multimodal framework for record linkage. CLIPPINGS employs end-to-end training of symmetric vision and language bi-encoders, aligned through contrastive language-image pre-training, to learn a metric space where the pooled image-text representation for a given instance is close to representations in the same class and distant from representations in different classes. At inference time, instances can be linked by retrieving their nearest neighbor from an offline exemplar embedding index or by clustering their representations. The study examines two challenging applications: constructing comprehensive supply chains for mid-20th century Japan through linking firm level financial records - with each firm name represented by its crop in the document image and the corresponding OCR - and detecting which image-caption pairs in a massive corpus of historical U.S. newspapers came from the same underlying photo wire source. CLIPPINGS outperforms widely used string matching methods by a wide margin and also outperforms unimodal methods. Moreover, a purely self-supervised model trained on only image-OCR pairs also outperforms popular string-matching methods without requiring any labels.
PixCUE: Joint Uncertainty Estimation and Image Reconstruction in MRI using Deep Pixel Classification
Mar 08, 2023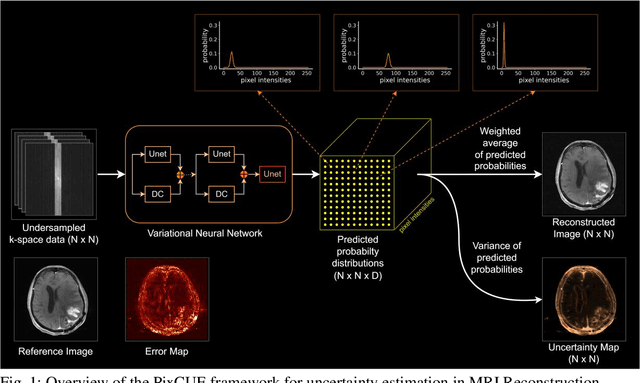
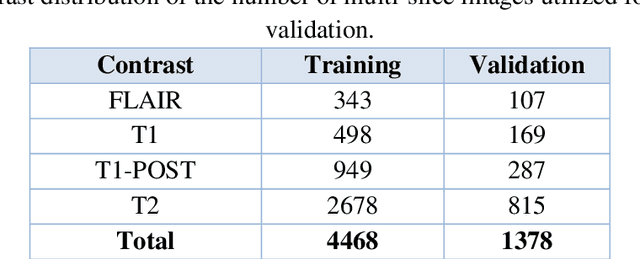
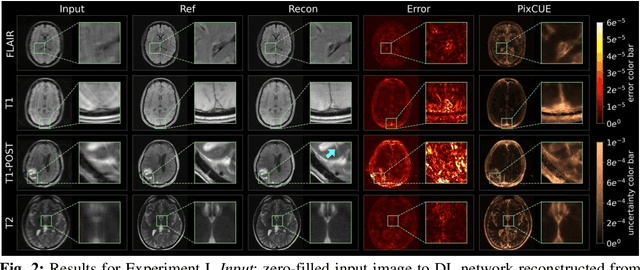
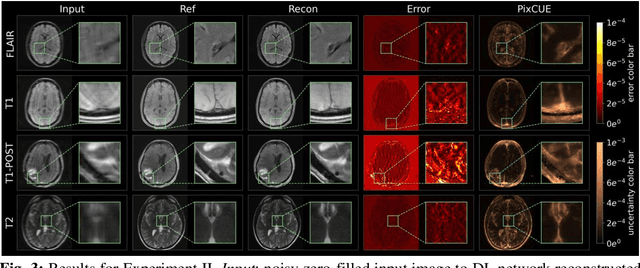
Deep learning (DL) models are capable of successfully exploiting latent representations in MR data and have become state-of-the-art for accelerated MRI reconstruction. However, undersampling the measurements in k-space as well as the over- or under-parameterized and non-transparent nature of DL make these models exposed to uncertainty. Consequently, uncertainty estimation has become a major issue in DL MRI reconstruction. To estimate uncertainty, Monte Carlo (MC) inference techniques have become a common practice where multiple reconstructions are utilized to compute the variance in reconstruction as a measurement of uncertainty. However, these methods demand high computational costs as they require multiple inferences through the DL model. To this end, we introduce a method to estimate uncertainty during MRI reconstruction using a pixel classification framework. The proposed method, PixCUE (stands for Pixel Classification Uncertainty Estimation) produces the reconstructed image along with an uncertainty map during a single forward pass through the DL model. We demonstrate that this approach generates uncertainty maps that highly correlate with the reconstruction errors with respect to various MR imaging sequences and under numerous adversarial conditions. We also show that the estimated uncertainties are correlated to that of the conventional MC method. We further provide an empirical relationship between the uncertainty estimations using PixCUE and well-established reconstruction metrics such as NMSE, PSNR, and SSIM. We conclude that PixCUE is capable of reliably estimating the uncertainty in MRI reconstruction with a minimum additional computational cost.
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 18, 2022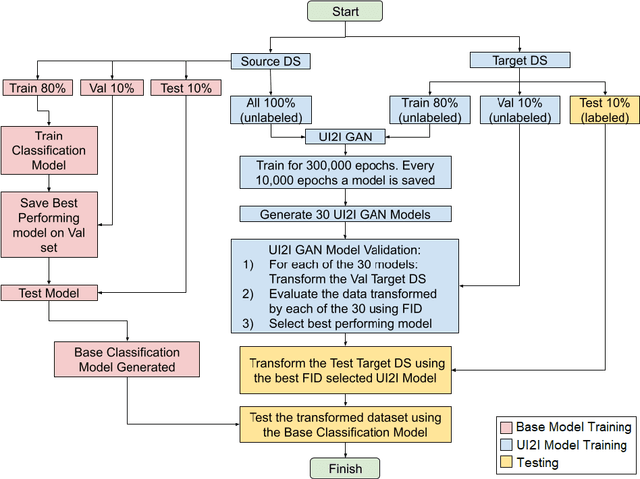
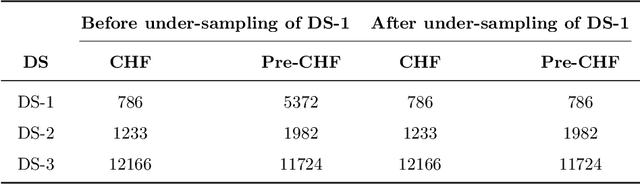

This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.
FM-Loc: Using Foundation Models for Improved Vision-based Localization
Apr 14, 2023
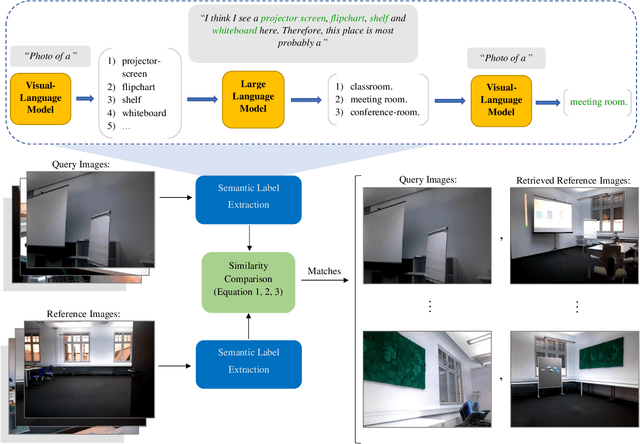
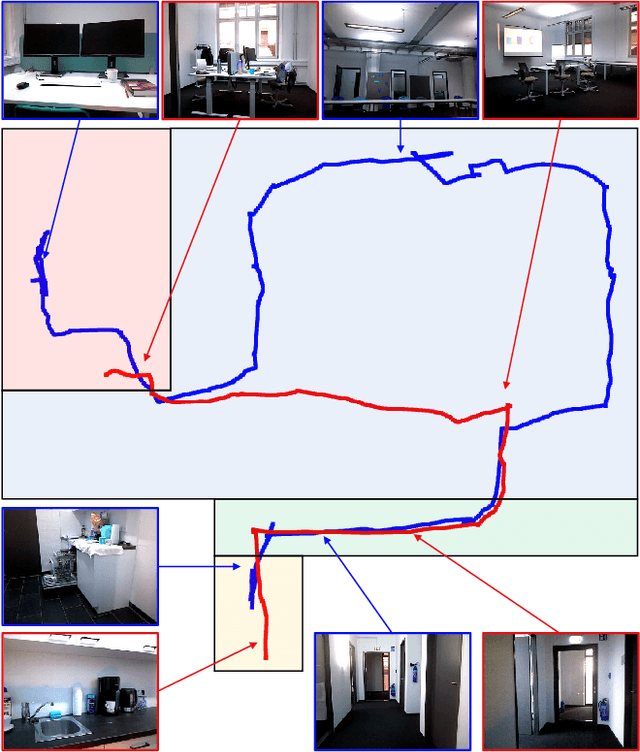

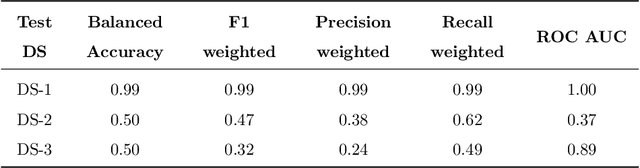
Visual place recognition is essential for vision-based robot localization and SLAM. Despite the tremendous progress made in recent years, place recognition in changing environments remains challenging. A promising approach to cope with appearance variations is to leverage high-level semantic features like objects or place categories. In this paper, we propose FM-Loc which is a novel image-based localization approach based on Foundation Models that uses the Large Language Model GPT-3 in combination with the Visual-Language Model CLIP to construct a semantic image descriptor that is robust to severe changes in scene geometry and camera viewpoint. We deploy CLIP to detect objects in an image, GPT-3 to suggest potential room labels based on the detected objects, and CLIP again to propose the most likely location label. The object labels and the scene label constitute an image descriptor that we use to calculate a similarity score between the query and database images. We validate our approach on real-world data that exhibit significant changes in camera viewpoints and object placement between the database and query trajectories. The experimental results demonstrate that our method is applicable to a wide range of indoor scenarios without the need for training or fine-tuning.