 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditionally Strongly Log-Concave Generative Models
May 31, 2023
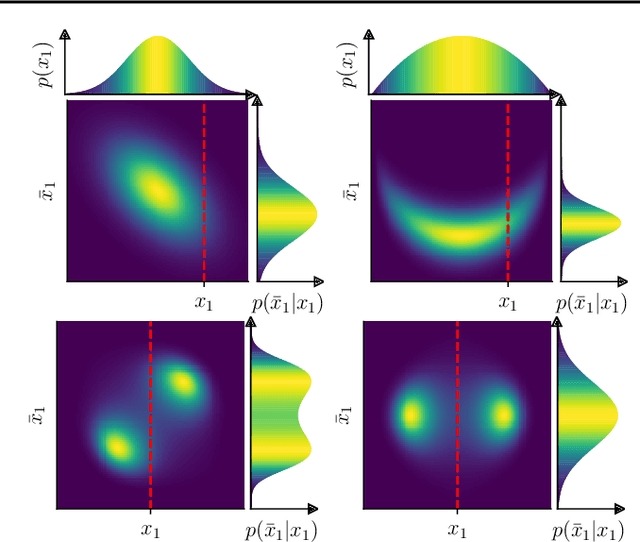
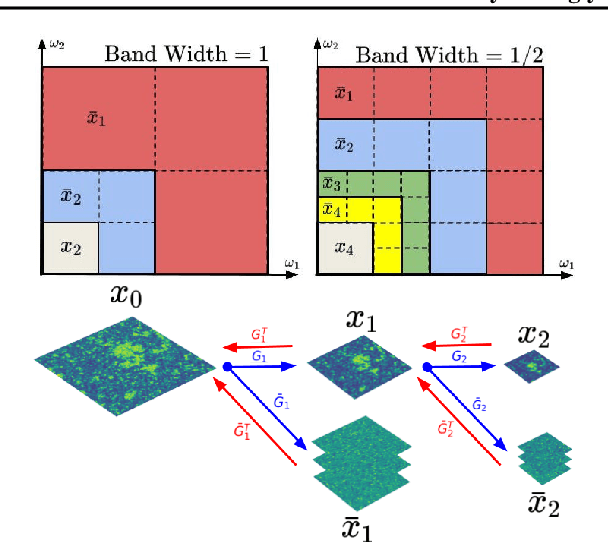
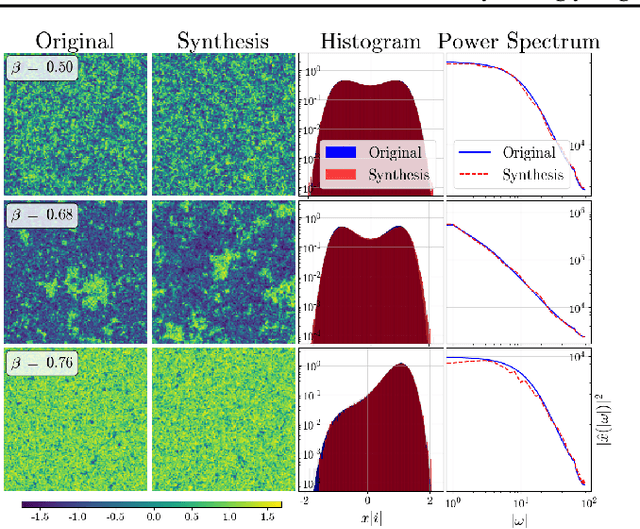
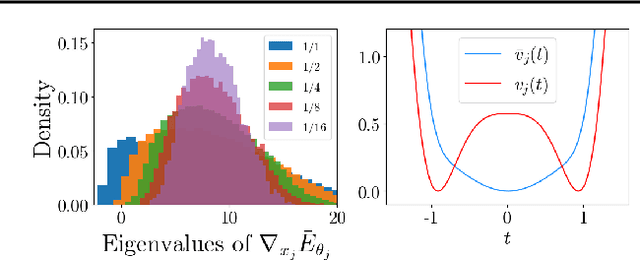
There is a growing gap between the impressive results of deep image generative models and classical algorithms that offer theoretical guarantees. The former suffer from mode collapse or memorization issues, limiting their application to scientific data. The latter require restrictive assumptions such as log-concavity to escape the curse of dimensionality. We partially bridge this gap by introducing conditionally strongly log-concave (CSLC) models, which factorize the data distribution into a product of conditional probability distributions that are strongly log-concave. This factorization is obtained with orthogonal projectors adapted to the data distribution. It leads to efficient parameter estimation and sampling algorithms, with theoretical guarantees, although the data distribution is not globally log-concave. We show that several challenging multiscale processes are conditionally log-concave using wavelet packet orthogonal projectors. Numerical results are shown for physical fields such as the $\varphi^4$ model and weak lensing convergence maps with higher resolution than in previous works.
Integrated multi-operand optical neurons for scalable and hardware-efficient deep learning
May 31, 2023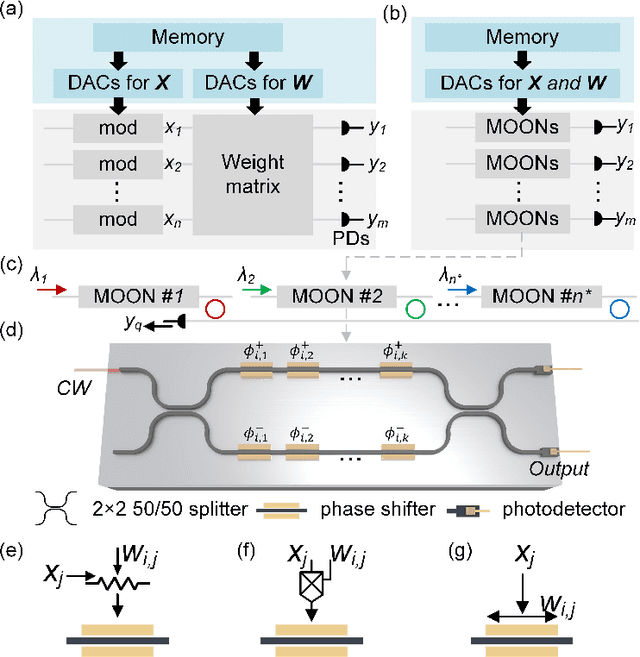
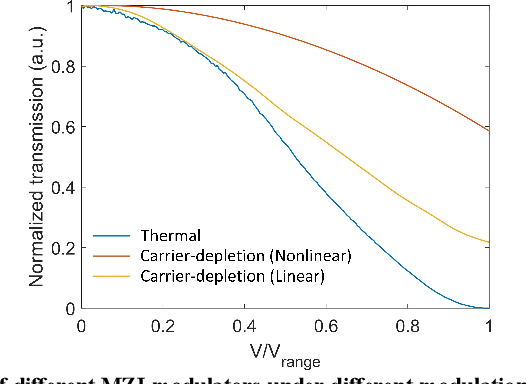
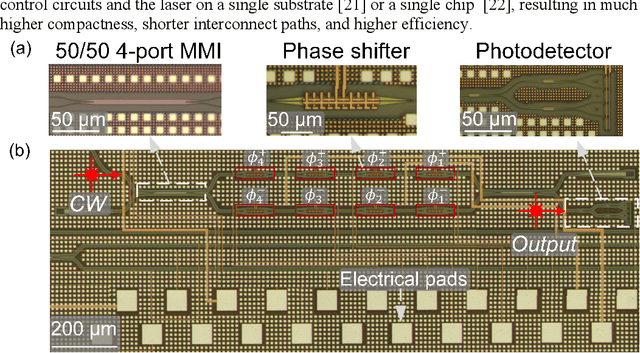
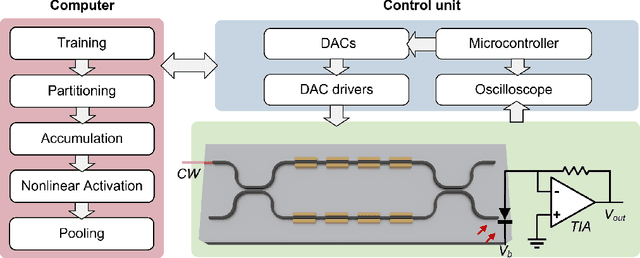
The optical neural network (ONN) is a promising hardware platform for next-generation neuromorphic computing due to its high parallelism, low latency, and low energy consumption. However, previous integrated photonic tensor cores (PTCs) consume numerous single-operand optical modulators for signal and weight encoding, leading to large area costs and high propagation loss to implement large tensor operations. This work proposes a scalable and efficient optical dot-product engine based on customized multi-operand photonic devices, namely multi-operand optical neurons (MOON). We experimentally demonstrate the utility of a MOON using a multi-operand-Mach-Zehnder-interferometer (MOMZI) in image recognition tasks. Specifically, our MOMZI-based ONN achieves a measured accuracy of 85.89% in the street view house number (SVHN) recognition dataset with 4-bit voltage control precision. Furthermore, our performance analysis reveals that a 128x128 MOMZI-based PTCs outperform their counterparts based on single-operand MZIs by one to two order-of-magnitudes in propagation loss, optical delay, and total device footprint, with comparable matrix expressivity.
TransRUPNet for Improved Out-of-Distribution Generalization in Polyp Segmentation
Jun 03, 2023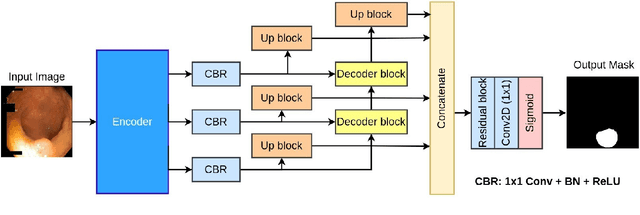
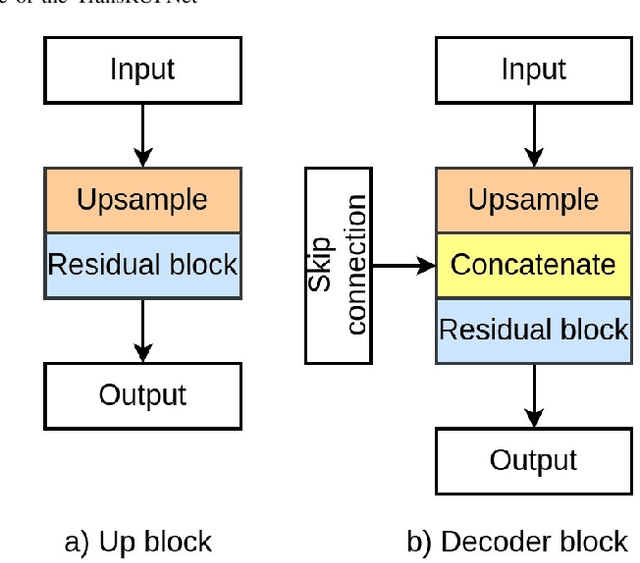
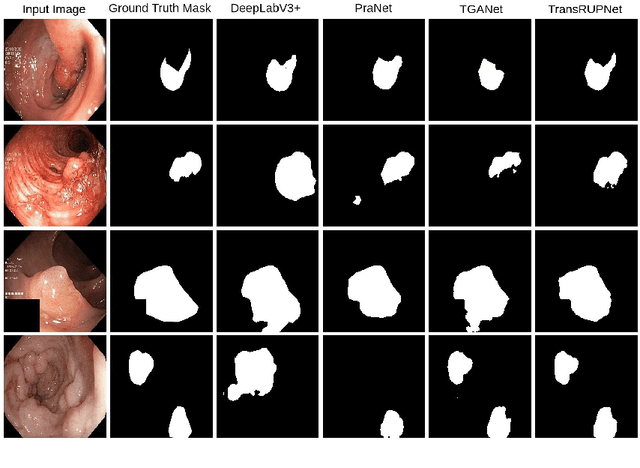
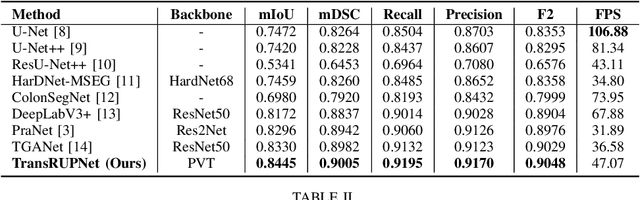
Out-of-distribution (OOD) generalization is a critical challenge in deep learning. It is specifically important when the test samples are drawn from a different distribution than the training data. We develop a novel real-time deep learning based architecture, TransRUPNet that is based on a Transformer and residual upsampling network for colorectal polyp segmentation to improve OOD generalization. The proposed architecture, TransRUPNet, is an encoder-decoder network that consists of three encoder blocks, three decoder blocks, and some additional upsampling blocks at the end of the network. With the image size of $256\times256$, the proposed method achieves an excellent real-time operation speed of \textbf{47.07} frames per second with an average mean dice coefficient score of 0.7786 and mean Intersection over Union of 0.7210 on the out-of-distribution polyp datasets. The results on the publicly available PolypGen dataset (OOD dataset in our case) suggest that TransRUPNet can give real-time feedback while retaining high accuracy for in-distribution dataset. Furthermore, we demonstrate the generalizability of the proposed method by showing that it significantly improves performance on OOD datasets compared to the existing methods.
Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
May 24, 2023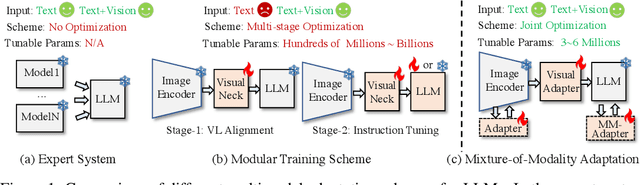
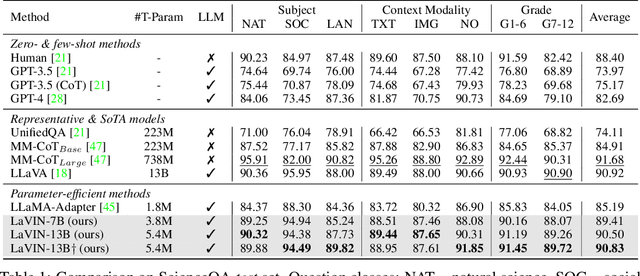
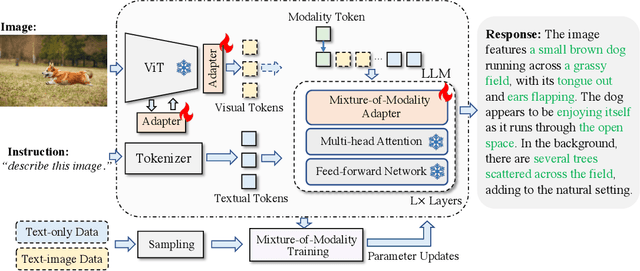
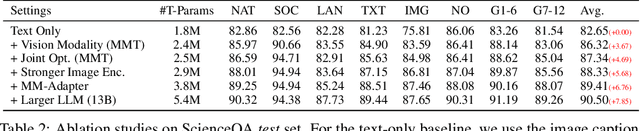
Recently, growing interest has been aroused in extending the multimodal capability of large language models (LLMs), e.g., vision-language (VL) learning, which is regarded as the next milestone of artificial general intelligence. However, existing solutions are prohibitively expensive, which not only need to optimize excessive parameters, but also require another large-scale pre-training before VL instruction tuning. In this paper, we propose a novel and affordable solution for the effective VL adaption of LLMs, called Mixture-of-Modality Adaptation (MMA). Instead of using large neural networks to connect the image encoder and LLM, MMA adopts lightweight modules, i.e., adapters, to bridge the gap between LLMs and VL tasks, which also enables the joint optimization of the image and language models. Meanwhile, MMA is also equipped with a routing algorithm to help LLMs achieve an automatic shift between single- and multi-modal instructions without compromising their ability of natural language understanding. To validate MMA, we apply it to a recent LLM called LLaMA and term this formed large vision-language instructed model as LaVIN. To validate MMA and LaVIN, we conduct extensive experiments under two setups, namely multimodal science question answering and multimodal dialogue. The experimental results not only demonstrate the competitive performance and the superior training efficiency of LaVIN than existing multimodal LLMs, but also confirm its great potential as a general-purpose chatbot. More importantly, the actual expenditure of LaVIN is extremely cheap, e.g., only 1.4 training hours with 3.8M trainable parameters, greatly confirming the effectiveness of MMA. Our project is released at https://luogen1996.github.io/lavin.
Self-Supervised and Supervised Deep Learning for PET Image Reconstruction
Feb 25, 2023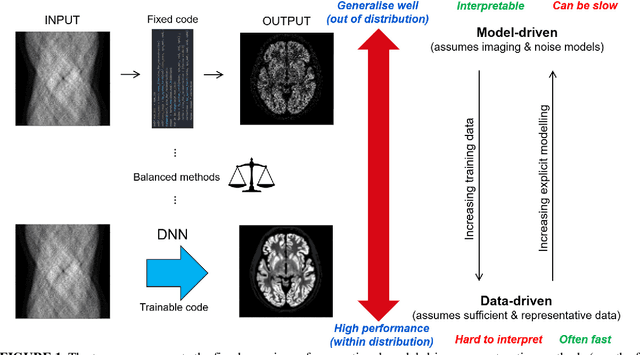
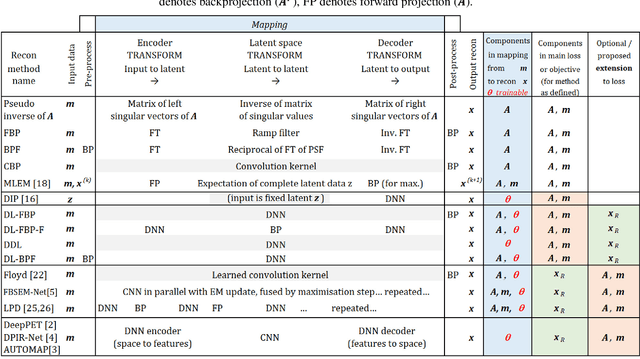
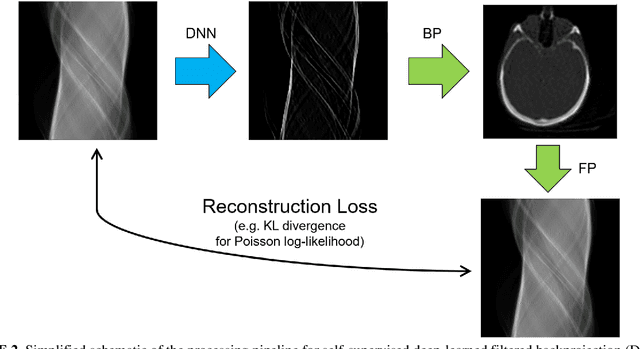
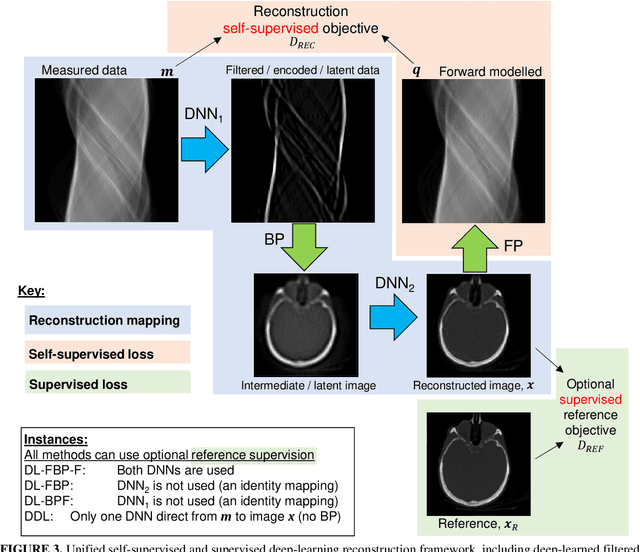
A unified self-supervised and supervised deep learning framework for PET image reconstruction is presented, including deep-learned filtered backprojection (DL-FBP) for sinograms, deep-learned backproject then filter (DL-BPF) for backprojected images, and a more general mapping using a deep network in both the sinogram and image domains (DL-FBP-F). The framework allows varying amounts and types of training data, from the case of having only one single dataset to reconstruct through to the case of having numerous measured datasets, which may or may not be paired with high-quality references. For purely self-supervised mappings, no reference or ground truth data are needed. The self-supervised deep-learned reconstruction operators all use a conventional image reconstruction objective within the loss function (e.g. maximum Poisson likelihood, maximum a posteriori). If it is desired for the reconstruction networks to generalise (i.e. to need either no or minimal retraining for a new measured dataset, but to be fast, ready to reuse), then these self-supervised networks show potential even when previously trained from just one single dataset. For any given new measured dataset, finetuning is however often necessary, and of course the initial training set should ideally go beyond just one dataset if a generalisable network is sought. Example results for the purely self-supervised single-dataset case are shown, but the networks can be i) trained uniquely for any measured dataset to reconstruct from, ii) pretrained on multiple datasets and then used with no retraining for new measured data, iii) pretrained and then finetuned for new measured data, iv) optionally trained with high-quality references. The framework, with its optional inclusion of supervised learning, provides a spectrum of reconstruction approaches by making use of whatever (if any) training data quantities and types are available.
An Evaluation of Non-Contrastive Self-Supervised Learning for Federated Medical Image Analysis
Mar 09, 2023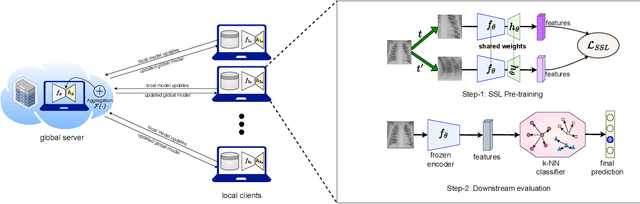
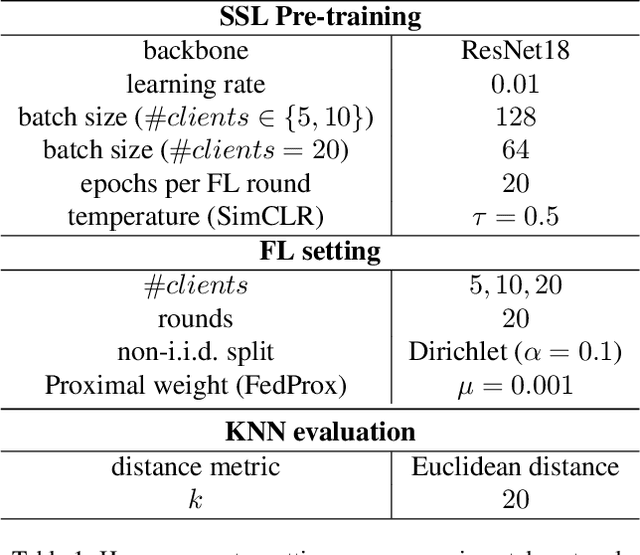
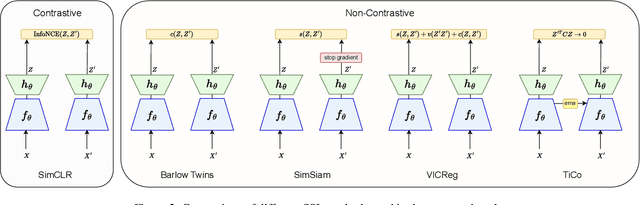

Privacy and annotation bottlenecks are two major issues that profoundly affect the practicality of machine learning-based medical image analysis. Although significant progress has been made in these areas, these issues are not yet fully resolved. In this paper, we seek to tackle these concerns head-on and systematically explore the applicability of non-contrastive self-supervised learning (SSL) algorithms under federated learning (FL) simulations for medical image analysis. We conduct thorough experimentation of recently proposed state-of-the-art non-contrastive frameworks under standard FL setups. With the SoTA Contrastive Learning algorithm, SimCLR as our comparative baseline, we benchmark the performances of our 4 chosen non-contrastive algorithms under non-i.i.d. data conditions and with a varying number of clients. We present a holistic evaluation of these techniques on 6 standardized medical imaging datasets. We further analyse different trends inferred from the findings of our research, with the aim to find directions for further research based on ours. To the best of our knowledge, ours is the first to perform such a thorough analysis of federated self-supervised learning for medical imaging. All of our source code will be made public upon acceptance of the paper.
Predicting Stock Price Movement as an Image Classification Problem
Mar 02, 2023
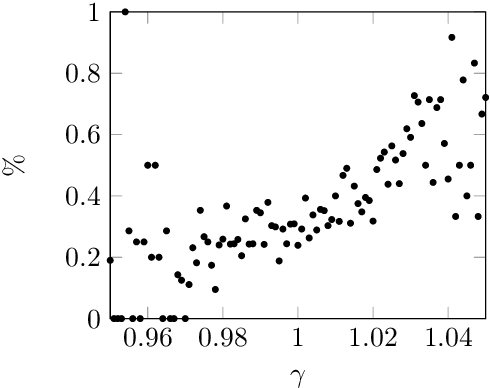
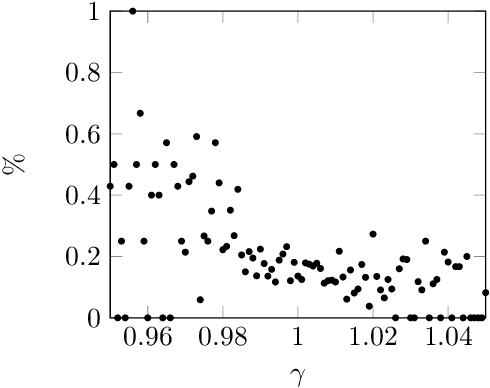
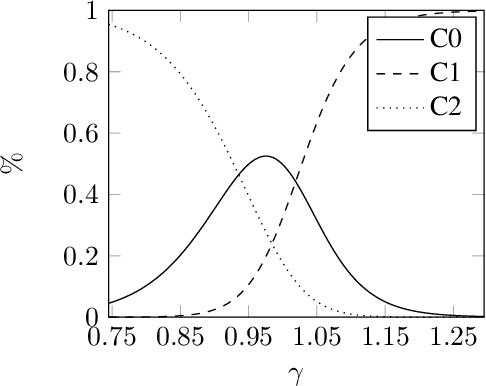
The paper studies intraday price movement of stocks that is considered as an image classification problem. Using a CNN-based model we make a compelling case for the high-level relationship between the first hour of trading and the close. The algorithm managed to adequately separate between the two opposing classes and investing according to the algorithm's predictions outperformed all alternative constructs but the theoretical maximum. To support the thesis, we ran several additional tests. The findings in the paper highlight the suitability of computer vision techniques for studying financial markets and in particular prediction of stock price movements.
ITstyler: Image-optimized Text-based Style Transfer
Jan 26, 2023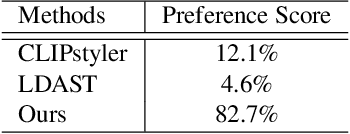
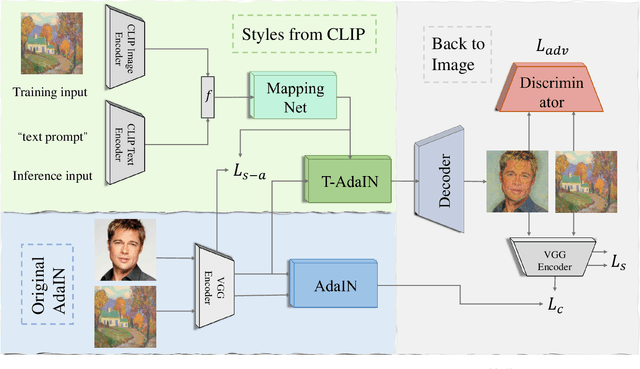
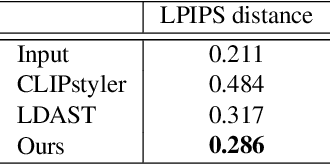

Text-based style transfer is a newly-emerging research topic that uses text information instead of style image to guide the transfer process, significantly extending the application scenario of style transfer. However, previous methods require extra time for optimization or text-image paired data, leading to limited effectiveness. In this work, we achieve a data-efficient text-based style transfer method that does not require optimization at the inference stage. Specifically, we convert text input to the style space of the pre-trained VGG network to realize a more effective style swap. We also leverage CLIP's multi-modal embedding space to learn the text-to-style mapping with the image dataset only. Our method can transfer arbitrary new styles of text input in real-time and synthesize high-quality artistic images.
Spatially-varying Regularization with Conditional Transformer for Unsupervised Image Registration
Mar 10, 2023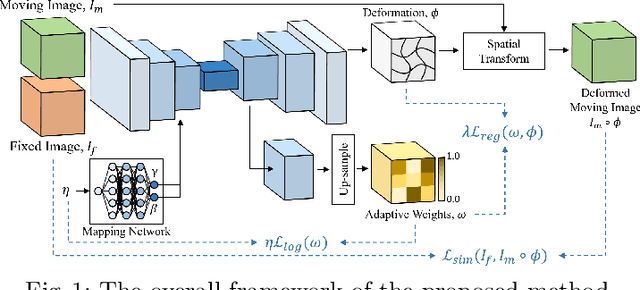
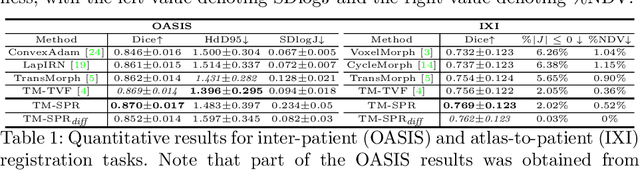
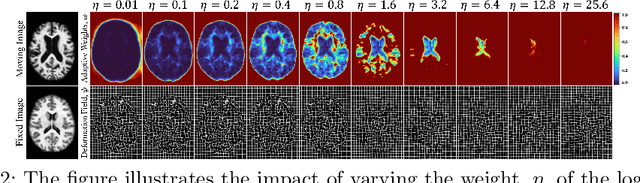
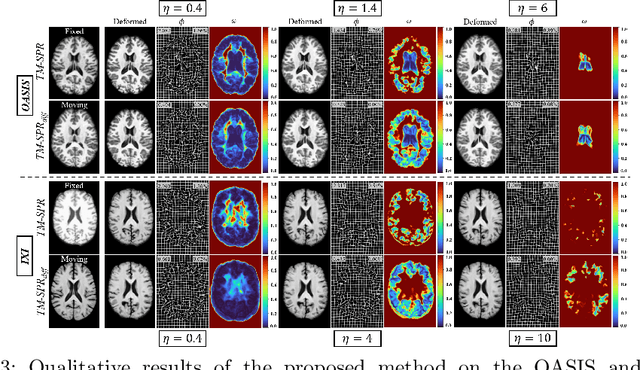
In the past, optimization-based registration models have used spatially-varying regularization to account for deformation variations in different image regions. However, deep learning-based registration models have mostly relied on spatially-invariant regularization. Here, we introduce an end-to-end framework that uses neural networks to learn a spatially-varying deformation regularizer directly from data. The hyperparameter of the proposed regularizer is conditioned into the network, enabling easy tuning of the regularization strength. The proposed method is built upon a Transformer-based model, but it can be readily adapted to any network architecture. We thoroughly evaluated the proposed approach using publicly available datasets and observed a significant performance improvement while maintaining smooth deformation. The source code of this work will be made available after publication.
Using Caterpillar to Nibble Small-Scale Images
May 28, 2023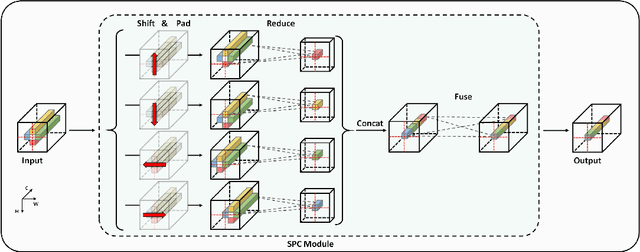
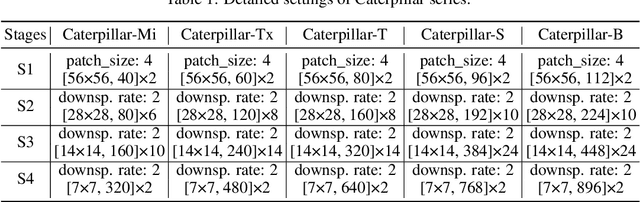
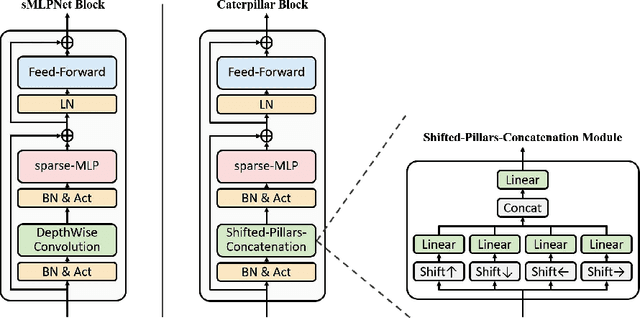
Recently, MLP-based models have become popular and attained significant performance on medium-scale datasets (e.g., ImageNet-1k). However, their direct applications to small-scale images remain limited. To address this issue, we design a new MLP-based network, namely Caterpillar, by proposing a key module of Shifted-Pillars-Concatenation (SPC) for exploiting the inductive bias of locality. SPC consists of two processes: (1) Pillars-Shift, which is to shift all pillars within an image along different directions to generate copies, and (2) Pillars-Concatenation, which is to capture the local information from discrete shift neighborhoods of the shifted copies. Extensive experiments demonstrate its strong scalability and superior performance on popular small-scale datasets, and the competitive performance on ImageNet-1K to recent state-of-the-art methods.