 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards L-System Captioning for Tree Reconstruction
May 10, 2023

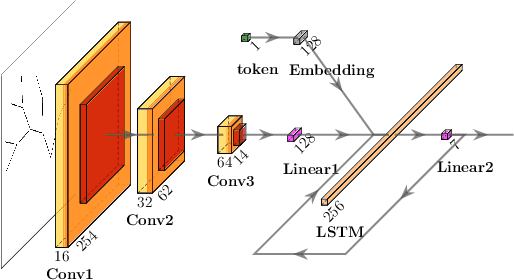
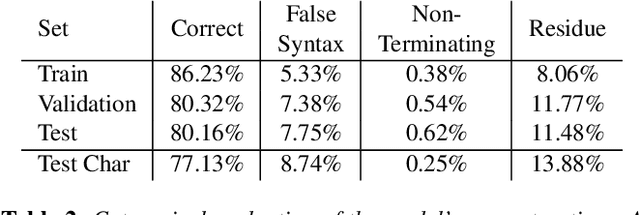
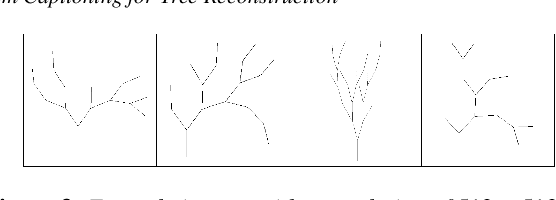
This work proposes a novel concept for tree and plant reconstruction by directly inferring a Lindenmayer-System (L-System) word representation from image data in an image captioning approach. We train a model end-to-end which is able to translate given images into L-System words as a description of the displayed tree. To prove this concept, we demonstrate the applicability on 2D tree topologies. Transferred to real image data, this novel idea could lead to more efficient, accurate and semantically meaningful tree and plant reconstruction without using error-prone point cloud extraction, and other processes usually utilized in tree reconstruction. Furthermore, this approach bypasses the need for a predefined L-System grammar and enables species-specific L-System inference without biological knowledge.
Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
Jun 02, 2023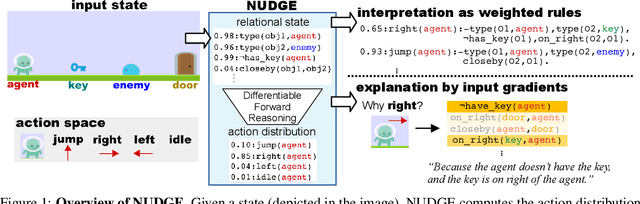
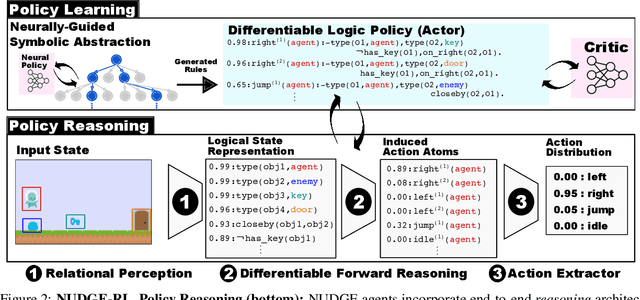
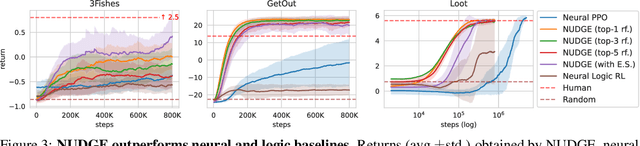

The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.
Generative Autoencoders as Watermark Attackers: Analyses of Vulnerabilities and Threats
Jun 02, 2023
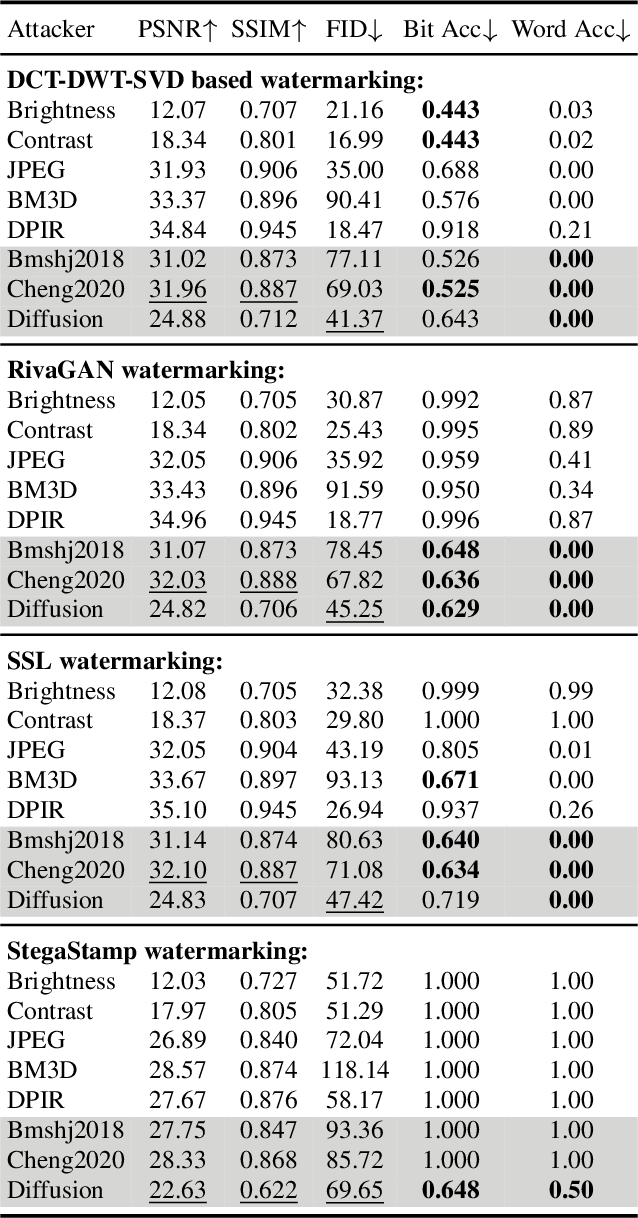
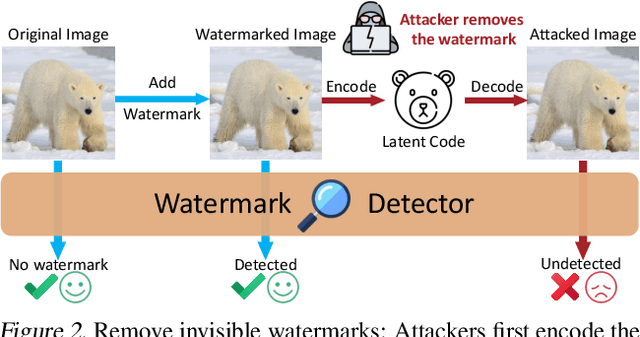
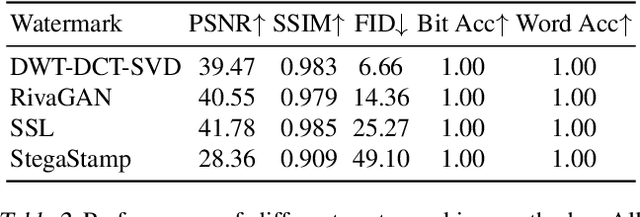
Invisible watermarks safeguard images' copyrights by embedding hidden messages detectable by owners. It also prevents people from misusing images, especially those generated by AI models. Malicious adversaries can violate these rights by removing the watermarks. In order to remove watermarks without damaging the visual quality, the adversary needs to erase them while retaining the essential information in the image. This is analogous to the encoding and decoding process of generative autoencoders, especially variational autoencoders (VAEs) and diffusion models. We propose a framework using generative autoencoders to remove invisible watermarks and test it using VAEs and diffusions. Our results reveal that, even without specific training, off-the-shelf Stable Diffusion effectively removes most watermarks, surpassing all current attackers. The result underscores the vulnerabilities in existing watermarking schemes and calls for more robust methods for copyright protection.
A Data-Driven Measure of Relative Uncertainty for Misclassification Detection
Jun 02, 2023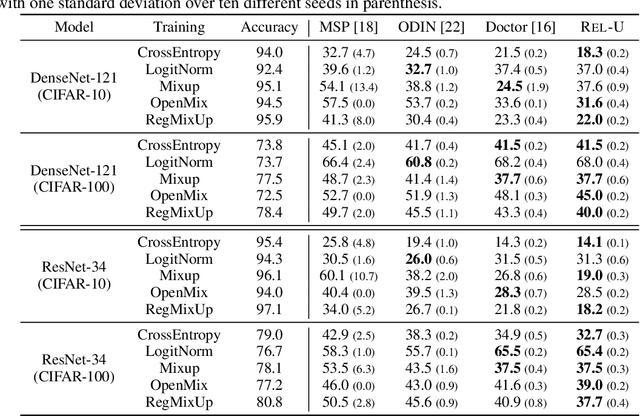
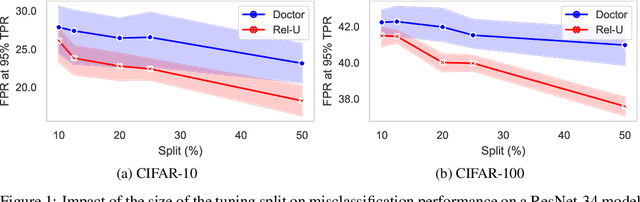
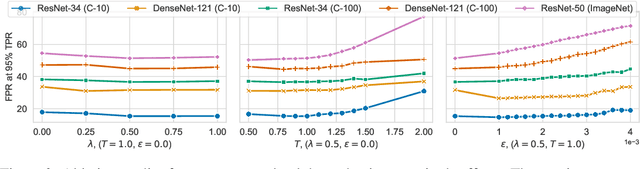
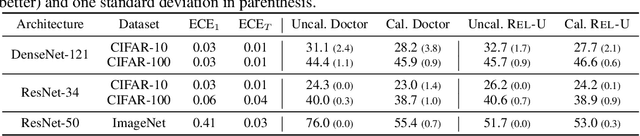
Misclassification detection is an important problem in machine learning, as it allows for the identification of instances where the model's predictions are unreliable. However, conventional uncertainty measures such as Shannon entropy do not provide an effective way to infer the real uncertainty associated with the model's predictions. In this paper, we introduce a novel data-driven measure of relative uncertainty to an observer for misclassification detection. By learning patterns in the distribution of soft-predictions, our uncertainty measure can identify misclassified samples based on the predicted class probabilities. Interestingly, according to the proposed measure, soft-predictions that correspond to misclassified instances can carry a large amount of uncertainty, even though they may have low Shannon entropy. We demonstrate empirical improvements over multiple image classification tasks, outperforming state-of-the-art misclassification detection methods.
Simple U-net Based Synthetic Polyp Image Generation: Polyp to Negative and Negative to Polyp
Feb 20, 2023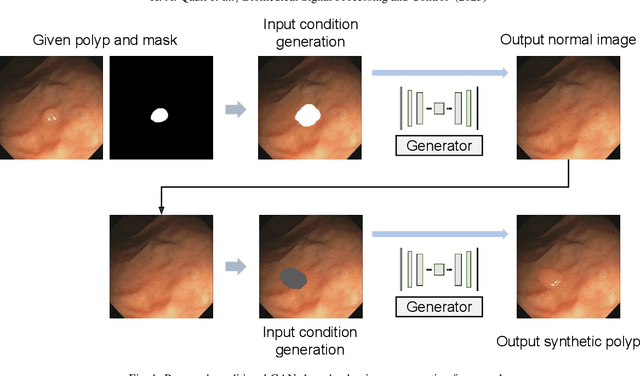
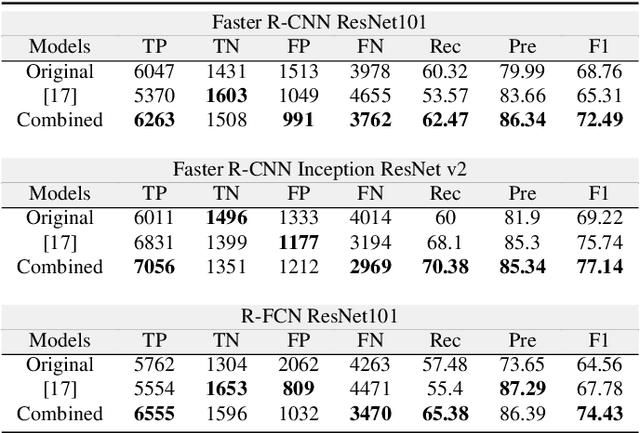
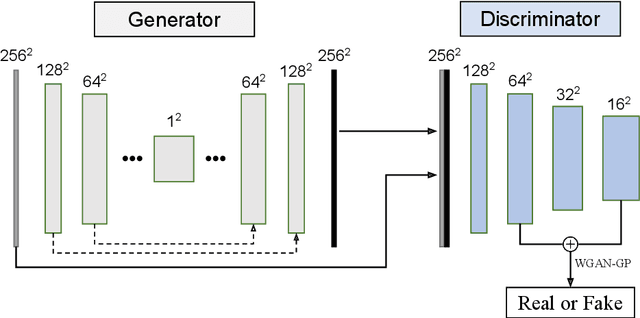

Synthetic polyp generation is a good alternative to overcome the privacy problem of medical data and the lack of various polyp samples. In this study, we propose a deep learning-based polyp image generation framework that generates synthetic polyp images that are similar to real ones. We suggest a framework that converts a given polyp image into a negative image (image without a polyp) using a simple conditional GAN architecture and then converts the negative image into a new-looking polyp image using the same network. In addition, by using the controllable polyp masks, polyps with various characteristics can be generated from one input condition. The generated polyp images can be used directly as training images for polyp detection and segmentation without additional labeling. To quantitatively assess the quality of generated synthetic polyps, we use public polyp image and video datasets combined with the generated synthetic images to examine the performance improvement of several detection and segmentation models. Experimental results show that we obtain performance gains when the generated polyp images are added to the training set.
Comparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving
May 25, 2023
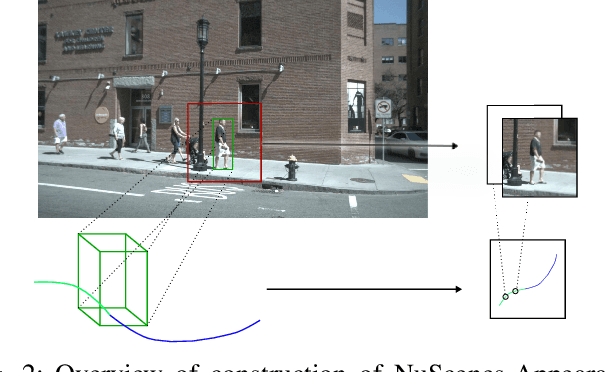
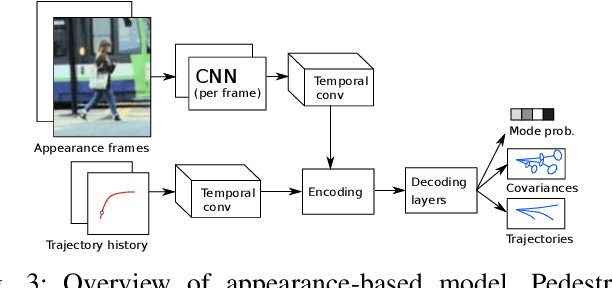
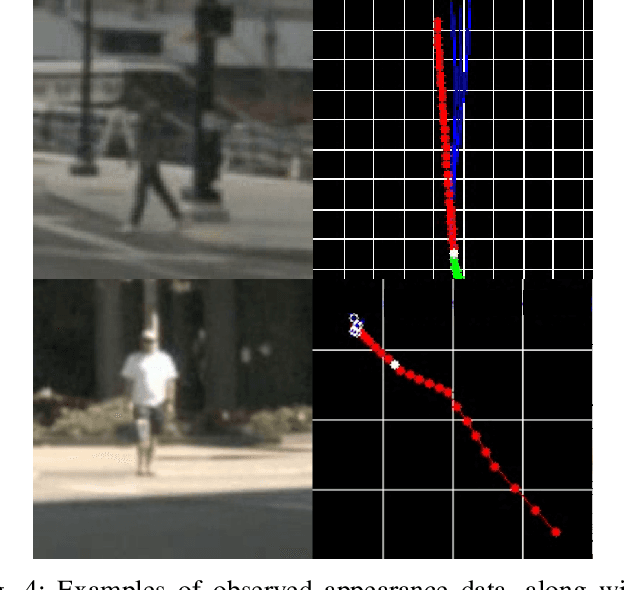
The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.
PiMAE: Point Cloud and Image Interactive Masked Autoencoders for 3D Object Detection
Mar 14, 2023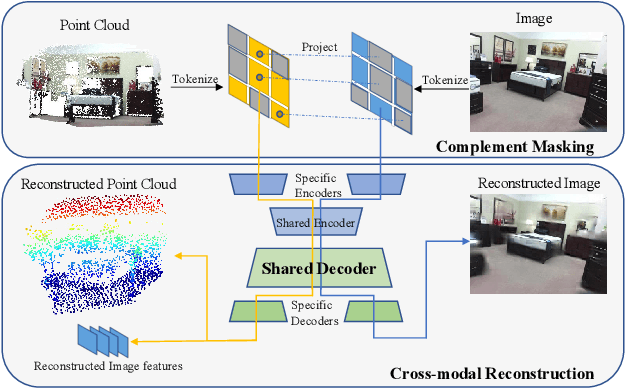
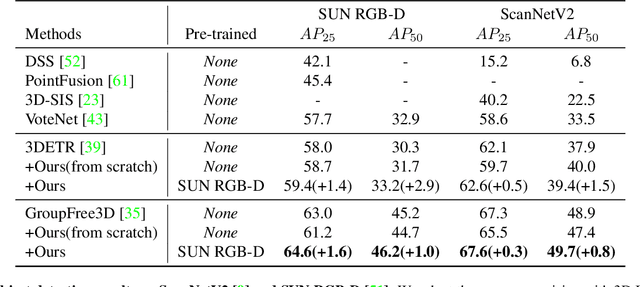
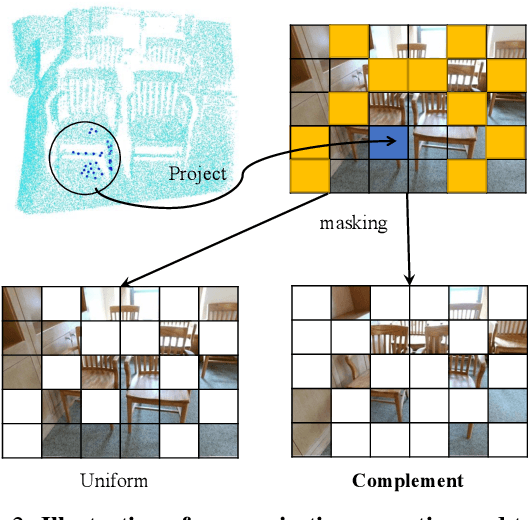

Masked Autoencoders learn strong visual representations and achieve state-of-the-art results in several independent modalities, yet very few works have addressed their capabilities in multi-modality settings. In this work, we focus on point cloud and RGB image data, two modalities that are often presented together in the real world, and explore their meaningful interactions. To improve upon the cross-modal synergy in existing works, we propose PiMAE, a self-supervised pre-training framework that promotes 3D and 2D interaction through three aspects. Specifically, we first notice the importance of masking strategies between the two sources and utilize a projection module to complementarily align the mask and visible tokens of the two modalities. Then, we utilize a well-crafted two-branch MAE pipeline with a novel shared decoder to promote cross-modality interaction in the mask tokens. Finally, we design a unique cross-modal reconstruction module to enhance representation learning for both modalities. Through extensive experiments performed on large-scale RGB-D scene understanding benchmarks (SUN RGB-D and ScannetV2), we discover it is nontrivial to interactively learn point-image features, where we greatly improve multiple 3D detectors, 2D detectors, and few-shot classifiers by 2.9%, 6.7%, and 2.4%, respectively. Code is available at https://github.com/BLVLab/PiMAE.
Fast light-field 3D microscopy with out-of-distribution detection and adaptation through Conditional Normalizing Flows
Jun 10, 2023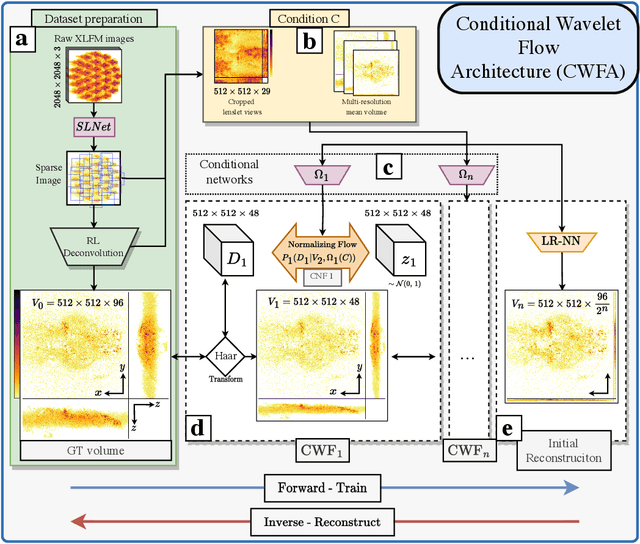
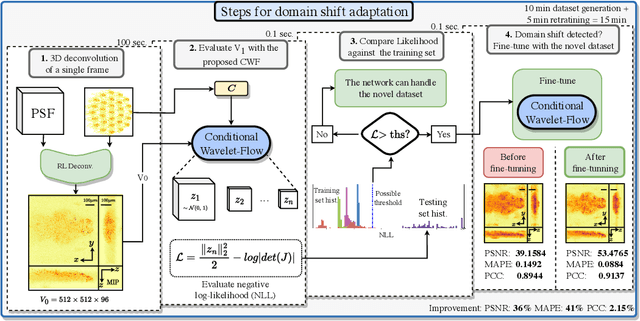
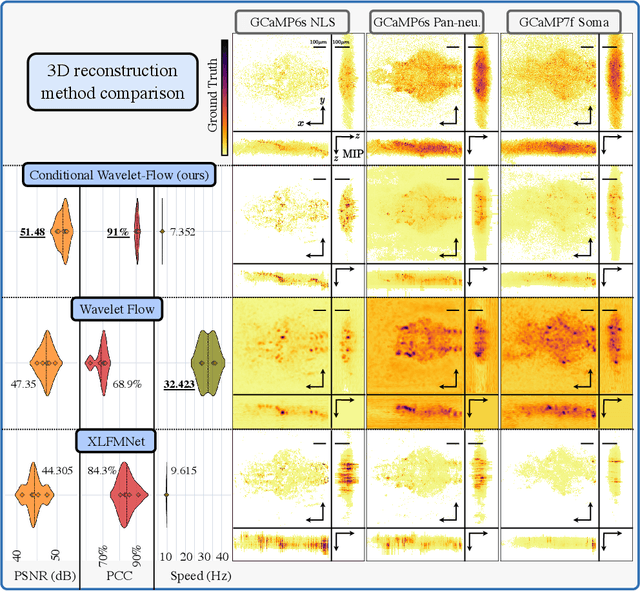
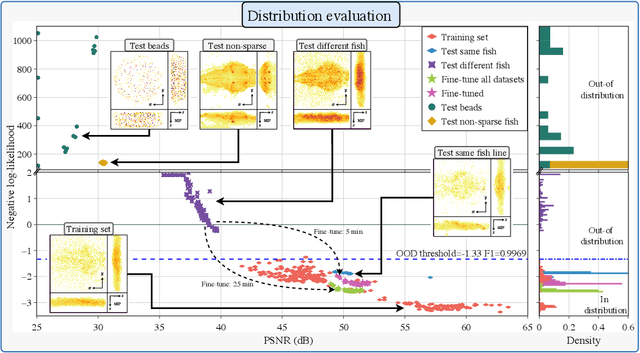
Real-time 3D fluorescence microscopy is crucial for the spatiotemporal analysis of live organisms, such as neural activity monitoring. The eXtended field-of-view light field microscope (XLFM), also known as Fourier light field microscope, is a straightforward, single snapshot solution to achieve this. The XLFM acquires spatial-angular information in a single camera exposure. In a subsequent step, a 3D volume can be algorithmically reconstructed, making it exceptionally well-suited for real-time 3D acquisition and potential analysis. Unfortunately, traditional reconstruction methods (like deconvolution) require lengthy processing times (0.0220 Hz), hampering the speed advantages of the XLFM. Neural network architectures can overcome the speed constraints at the expense of lacking certainty metrics, which renders them untrustworthy for the biomedical realm. This work proposes a novel architecture to perform fast 3D reconstructions of live immobilized zebrafish neural activity based on a conditional normalizing flow. It reconstructs volumes at 8 Hz spanning 512x512x96 voxels, and it can be trained in under two hours due to the small dataset requirements (10 image-volume pairs). Furthermore, normalizing flows allow for exact Likelihood computation, enabling distribution monitoring, followed by out-of-distribution detection and retraining of the system when a novel sample is detected. We evaluate the proposed method on a cross-validation approach involving multiple in-distribution samples (genetically identical zebrafish) and various out-of-distribution ones.
Intelligent sampling for surrogate modeling, hyperparameter optimization, and data analysis
Jun 06, 2023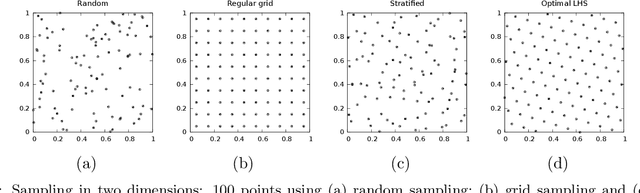
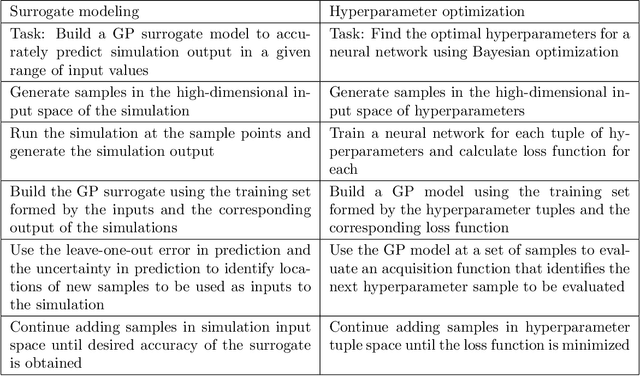
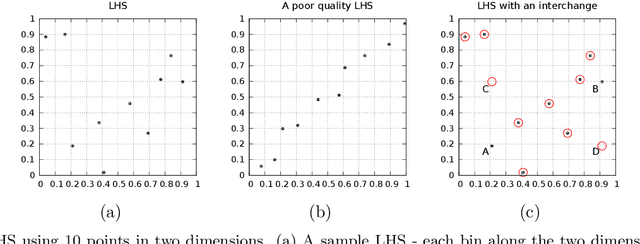
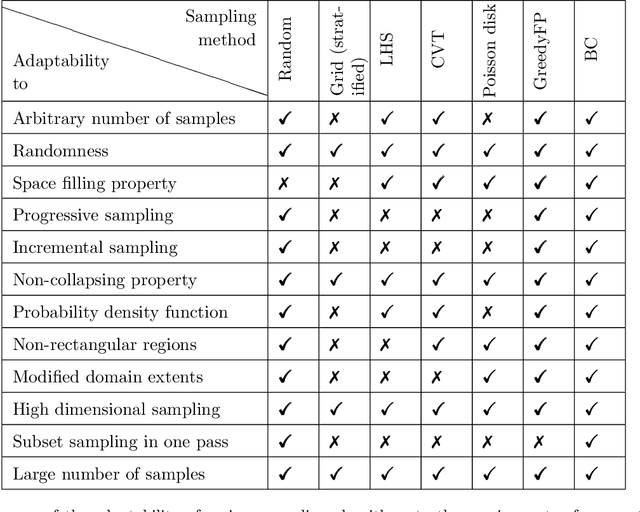
Sampling techniques are used in many fields, including design of experiments, image processing, and graphics. The techniques in each field are designed to meet the constraints specific to that field such as uniform coverage of the range of each dimension or random samples that are at least a certain distance apart from each other. When an application imposes new constraints, for example, by requiring samples in a non-rectangular domain or the addition of new samples to an existing set, a common solution is to modify the algorithm currently in use, often with less than satisfactory results. As an alternative, we propose the concept of intelligent sampling, where we devise algorithms specifically tailored to meet our sampling needs, either by creating new algorithms or by modifying suitable algorithms from other fields. Surprisingly, both qualitative and quantitative comparisons indicate that some relatively simple algorithms can be easily modified to meet the many sampling requirements of surrogate modeling, hyperparameter optimization, and data analysis; these algorithms outperform their more sophisticated counterparts currently in use, resulting in better use of time and computer resources.
* 4 Tables, 18 Figures
Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval
Feb 06, 2023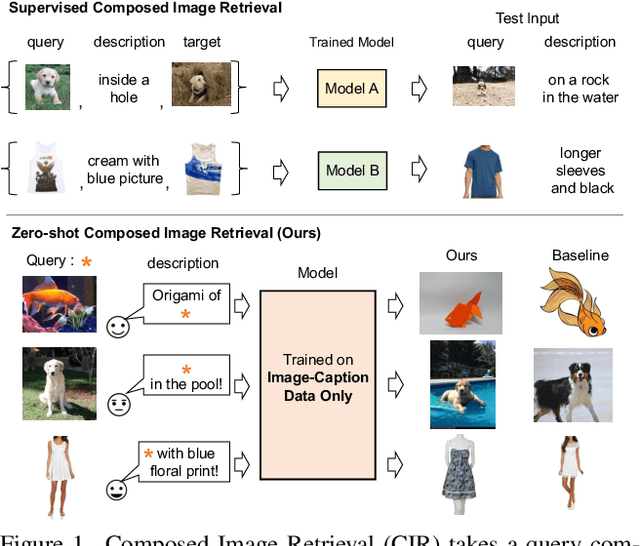
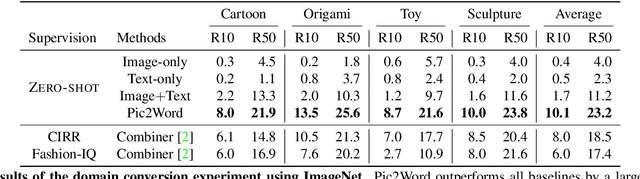
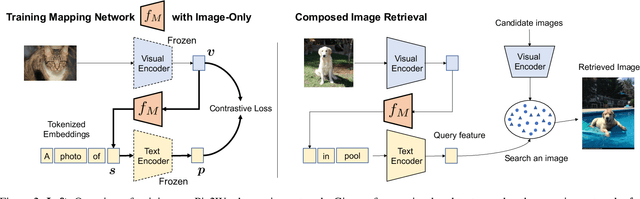
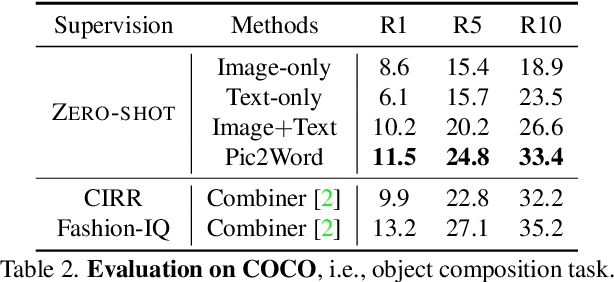
In Composed Image Retrieval (CIR), a user combines a query image with text to describe their intended target. Existing methods rely on supervised learning of CIR models using labeled triplets consisting of the query image, text specification, and the target image. Labeling such triplets is expensive and hinders broad applicability of CIR. In this work, we propose to study an important task, Zero-Shot Composed Image Retrieval (ZS-CIR), whose goal is to build a CIR model without requiring labeled triplets for training. To this end, we propose a novel method, called Pic2Word, that requires only weakly labeled image-caption pairs and unlabeled image datasets to train. Unlike existing supervised CIR models, our model trained on weakly labeled or unlabeled datasets shows strong generalization across diverse ZS-CIR tasks, e.g., attribute editing, object composition, and domain conversion. Our approach outperforms several supervised CIR methods on the common CIR benchmark, CIRR and Fashion-IQ. Code will be made publicly available at https://github.com/google-research/composed_image_retrieval.