 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
May 17, 2023
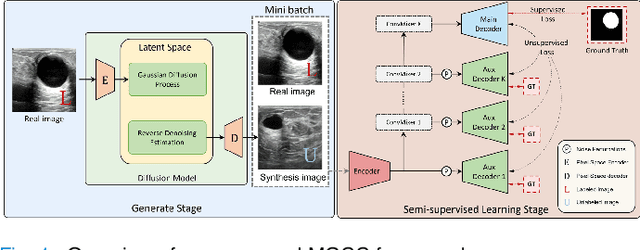
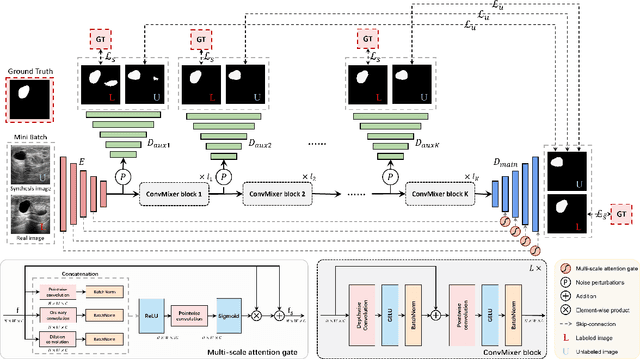
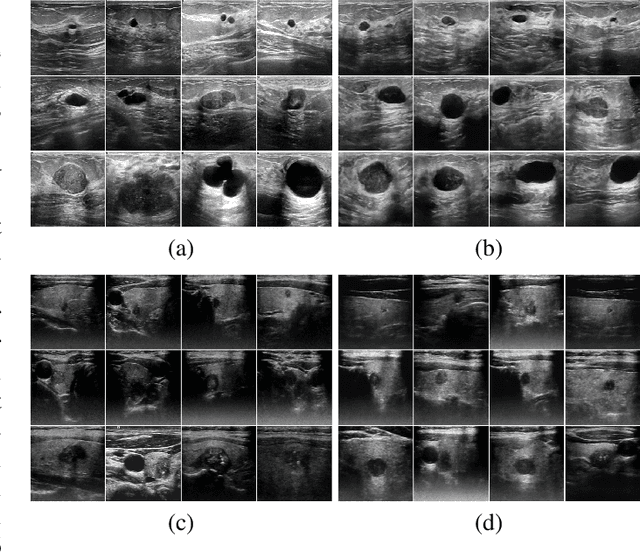
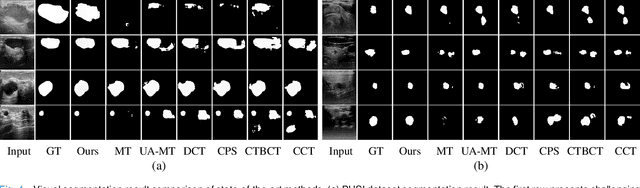
Medical image segmentation is a critical step in computer-aided diagnosis, and convolutional neural networks are popular segmentation networks nowadays. However, the inherent local operation characteristics make it difficult to focus on the global contextual information of lesions with different positions, shapes, and sizes. Semi-supervised learning can be used to learn from both labeled and unlabeled samples, alleviating the burden of manual labeling. However, obtaining a large number of unlabeled images in medical scenarios remains challenging. To address these issues, we propose a Multi-level Global Context Cross-consistency (MGCC) framework that uses images generated by a Latent Diffusion Model (LDM) as unlabeled images for semi-supervised learning. The framework involves of two stages. In the first stage, a LDM is used to generate synthetic medical images, which reduces the workload of data annotation and addresses privacy concerns associated with collecting medical data. In the second stage, varying levels of global context noise perturbation are added to the input of the auxiliary decoder, and output consistency is maintained between decoders to improve the representation ability. Experiments conducted on open-source breast ultrasound and private thyroid ultrasound datasets demonstrate the effectiveness of our framework in bridging the probability distribution and the semantic representation of the medical image. Our approach enables the effective transfer of probability distribution knowledge to the segmentation network, resulting in improved segmentation accuracy. The code is available at https://github.com/FengheTan9/Multi-Level-Global-Context-Cross-Consistency.
AdaptiveClick: Clicks-aware Transformer with Adaptive Focal Loss for Interactive Image Segmentation
May 07, 2023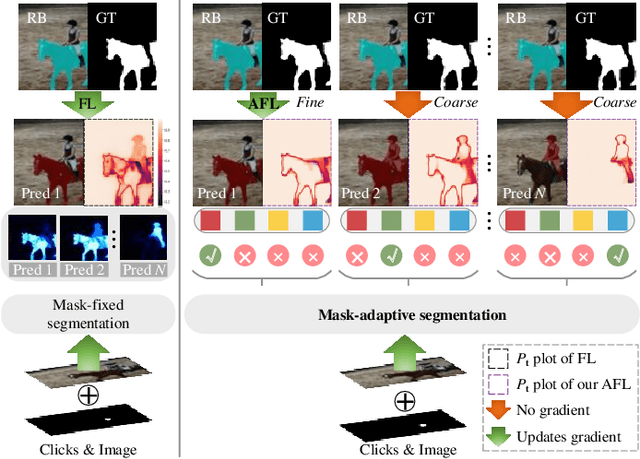
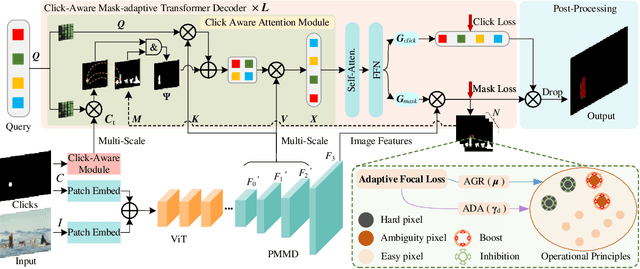

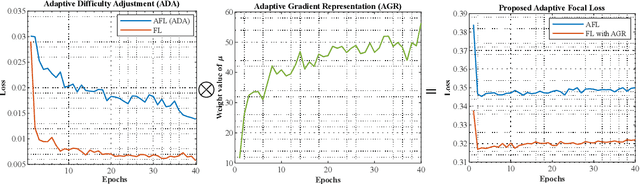
Interactive Image Segmentation (IIS) has emerged as a promising technique for decreasing annotation time. Substantial progress has been made in pre- and post-processing for IIS, but the critical issue of interaction ambiguity notably hindering segmentation quality, has been under-researched. To address this, we introduce AdaptiveClick -- a clicks-aware transformer incorporating an adaptive focal loss, which tackles annotation inconsistencies with tools for mask- and pixel-level ambiguity resolution. To the best of our knowledge, AdaptiveClick is the first transformer-based, mask-adaptive segmentation framework for IIS. The key ingredient of our method is the Clicks-aware Mask-adaptive Transformer Decoder (CAMD), which enhances the interaction between clicks and image features. Additionally, AdaptiveClick enables pixel-adaptive differentiation of hard and easy samples in the decision space, independent of their varying distributions. This is primarily achieved by optimizing a generalized Adaptive Focal Loss (AFL) with a theoretical guarantee, where two adaptive coefficients control the ratio of gradient values for hard and easy pixels. Our analysis reveals that the commonly used Focal and BCE losses can be considered special cases of the proposed AFL loss. With a plain ViT backbone, extensive experimental results on nine datasets demonstrate the superiority of AdaptiveClick compared to state-of-the-art methods. Code will be publicly available at https://github.com/lab206/AdaptiveClick.
Advancing Zero-Shot Digital Human Quality Assessment through Text-Prompted Evaluation
Jul 06, 2023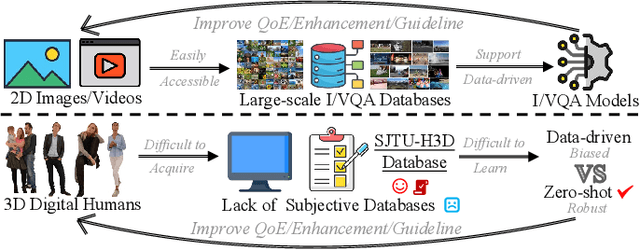
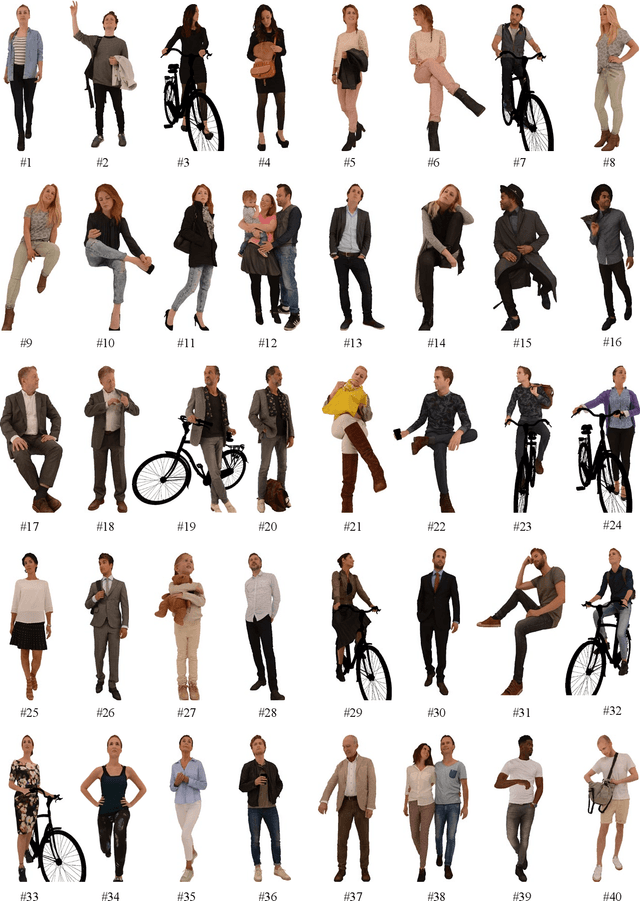
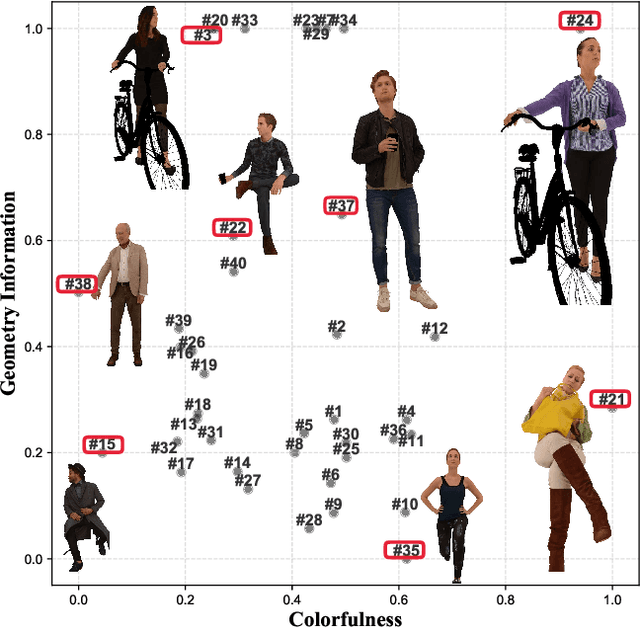
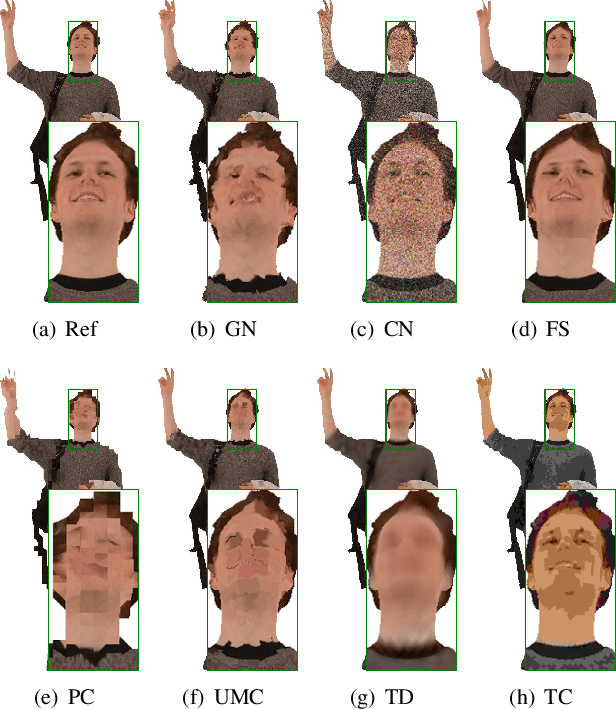
Digital humans have witnessed extensive applications in various domains, necessitating related quality assessment studies. However, there is a lack of comprehensive digital human quality assessment (DHQA) databases. To address this gap, we propose SJTU-H3D, a subjective quality assessment database specifically designed for full-body digital humans. It comprises 40 high-quality reference digital humans and 1,120 labeled distorted counterparts generated with seven types of distortions. The SJTU-H3D database can serve as a benchmark for DHQA research, allowing evaluation and refinement of processing algorithms. Further, we propose a zero-shot DHQA approach that focuses on no-reference (NR) scenarios to ensure generalization capabilities while mitigating database bias. Our method leverages semantic and distortion features extracted from projections, as well as geometry features derived from the mesh structure of digital humans. Specifically, we employ the Contrastive Language-Image Pre-training (CLIP) model to measure semantic affinity and incorporate the Naturalness Image Quality Evaluator (NIQE) model to capture low-level distortion information. Additionally, we utilize dihedral angles as geometry descriptors to extract mesh features. By aggregating these measures, we introduce the Digital Human Quality Index (DHQI), which demonstrates significant improvements in zero-shot performance. The DHQI can also serve as a robust baseline for DHQA tasks, facilitating advancements in the field. The database and the code are available at https://github.com/zzc-1998/SJTU-H3D.
Accuracy of Segment-Anything Model (SAM) in medical image segmentation tasks
Apr 18, 2023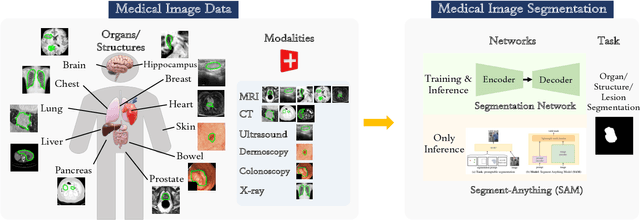
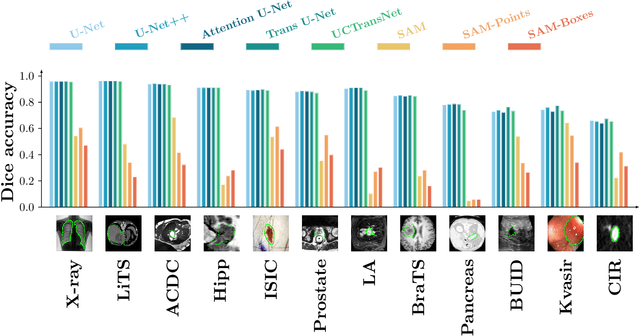
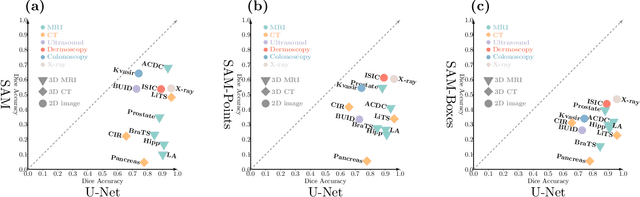
The segment-anything model (SAM), was introduced as a fundamental model for segmenting images. It was trained using over 1 billion masks from 11 million natural images. The model can perform zero-shot segmentation of images by using various prompts such as masks, boxes, and points. In this report, we explored (1) the accuracy of SAM on 12 public medical image segmentation datasets which cover various organs (brain, breast, chest, lung, skin, liver, bowel, pancreas, and prostate), image modalities (2D X-ray, histology, endoscropy, and 3D MRI and CT), and health conditions (normal, lesioned). (2) if the computer vision foundational segmentation model SAM can provide promising research directions for medical image segmentation. We found that SAM without re-training on medical images does not perform as accurately as U-Net or other deep learning models trained on medical images.
HoughLaneNet: Lane Detection with Deep Hough Transform and Dynamic Convolution
Jul 07, 2023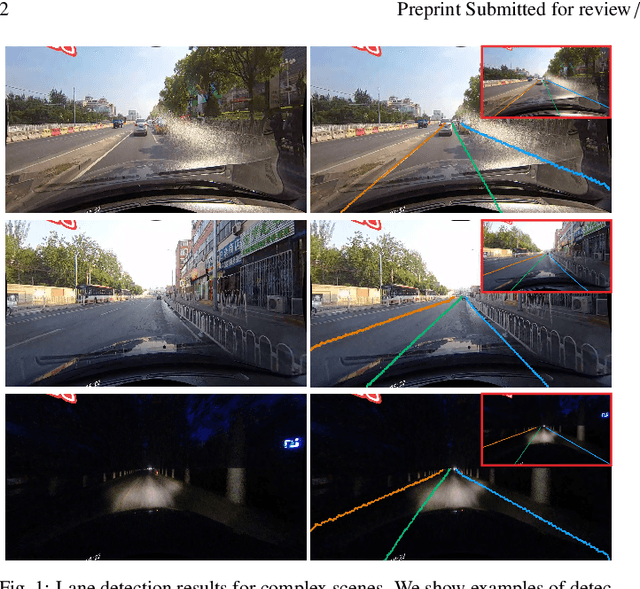
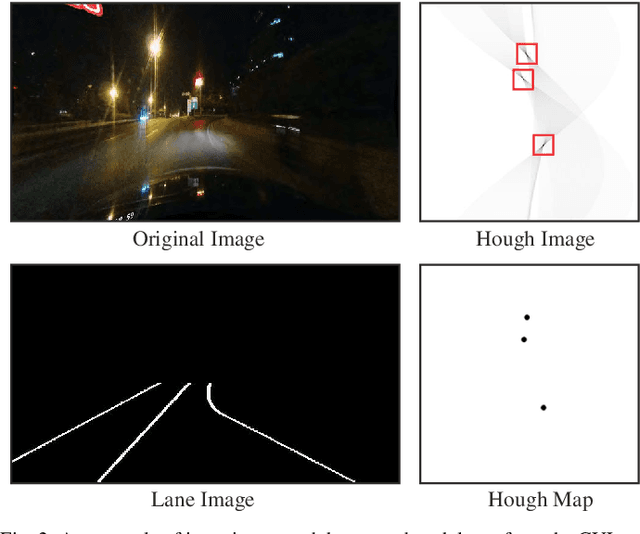
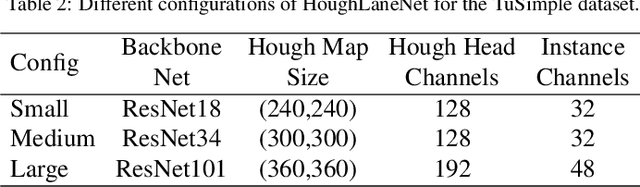
The task of lane detection has garnered considerable attention in the field of autonomous driving due to its complexity. Lanes can present difficulties for detection, as they can be narrow, fragmented, and often obscured by heavy traffic. However, it has been observed that the lanes have a geometrical structure that resembles a straight line, leading to improved lane detection results when utilizing this characteristic. To address this challenge, we propose a hierarchical Deep Hough Transform (DHT) approach that combines all lane features in an image into the Hough parameter space. Additionally, we refine the point selection method and incorporate a Dynamic Convolution Module to effectively differentiate between lanes in the original image. Our network architecture comprises a backbone network, either a ResNet or Pyramid Vision Transformer, a Feature Pyramid Network as the neck to extract multi-scale features, and a hierarchical DHT-based feature aggregation head to accurately segment each lane. By utilizing the lane features in the Hough parameter space, the network learns dynamic convolution kernel parameters corresponding to each lane, allowing the Dynamic Convolution Module to effectively differentiate between lane features. Subsequently, the lane features are fed into the feature decoder, which predicts the final position of the lane. Our proposed network structure demonstrates improved performance in detecting heavily occluded or worn lane images, as evidenced by our extensive experimental results, which show that our method outperforms or is on par with state-of-the-art techniques.
CamDiff: Camouflage Image Augmentation via Diffusion Model
Apr 11, 2023

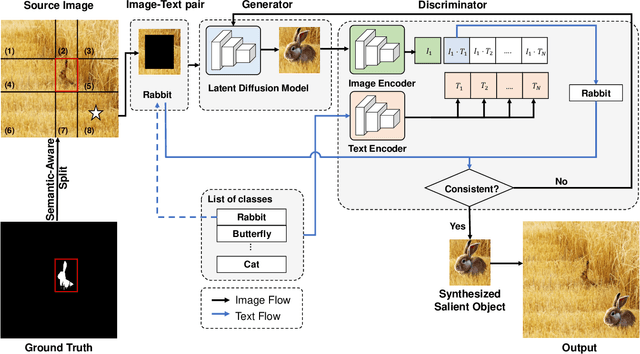
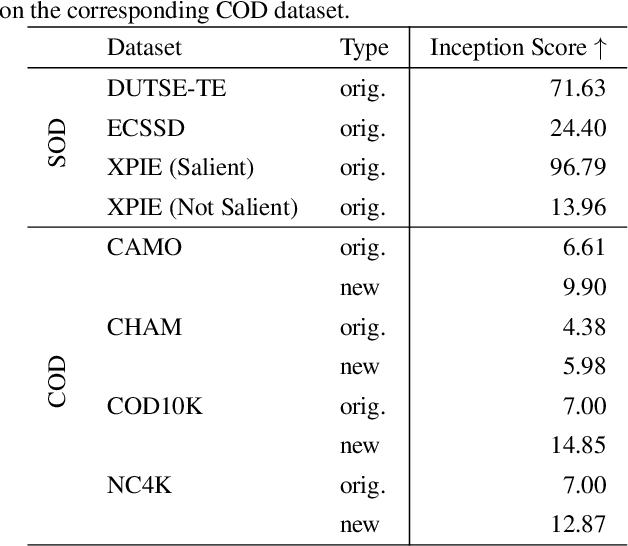
The burgeoning field of camouflaged object detection (COD) seeks to identify objects that blend into their surroundings. Despite the impressive performance of recent models, we have identified a limitation in their robustness, where existing methods may misclassify salient objects as camouflaged ones, despite these two characteristics being contradictory. This limitation may stem from lacking multi-pattern training images, leading to less saliency robustness. To address this issue, we introduce CamDiff, a novel approach inspired by AI-Generated Content (AIGC) that overcomes the scarcity of multi-pattern training images. Specifically, we leverage the latent diffusion model to synthesize salient objects in camouflaged scenes, while using the zero-shot image classification ability of the Contrastive Language-Image Pre-training (CLIP) model to prevent synthesis failures and ensure the synthesized object aligns with the input prompt. Consequently, the synthesized image retains its original camouflage label while incorporating salient objects, yielding camouflage samples with richer characteristics. The results of user studies show that the salient objects in the scenes synthesized by our framework attract the user's attention more; thus, such samples pose a greater challenge to the existing COD models. Our approach enables flexible editing and efficient large-scale dataset generation at a low cost. It significantly enhances COD baselines' training and testing phases, emphasizing robustness across diverse domains. Our newly-generated datasets and source code are available at https://github.com/drlxj/CamDiff.
Are Visual Recognition Models Robust to Image Compression?
Apr 10, 2023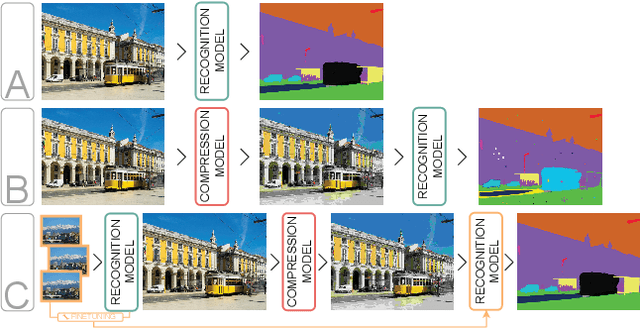

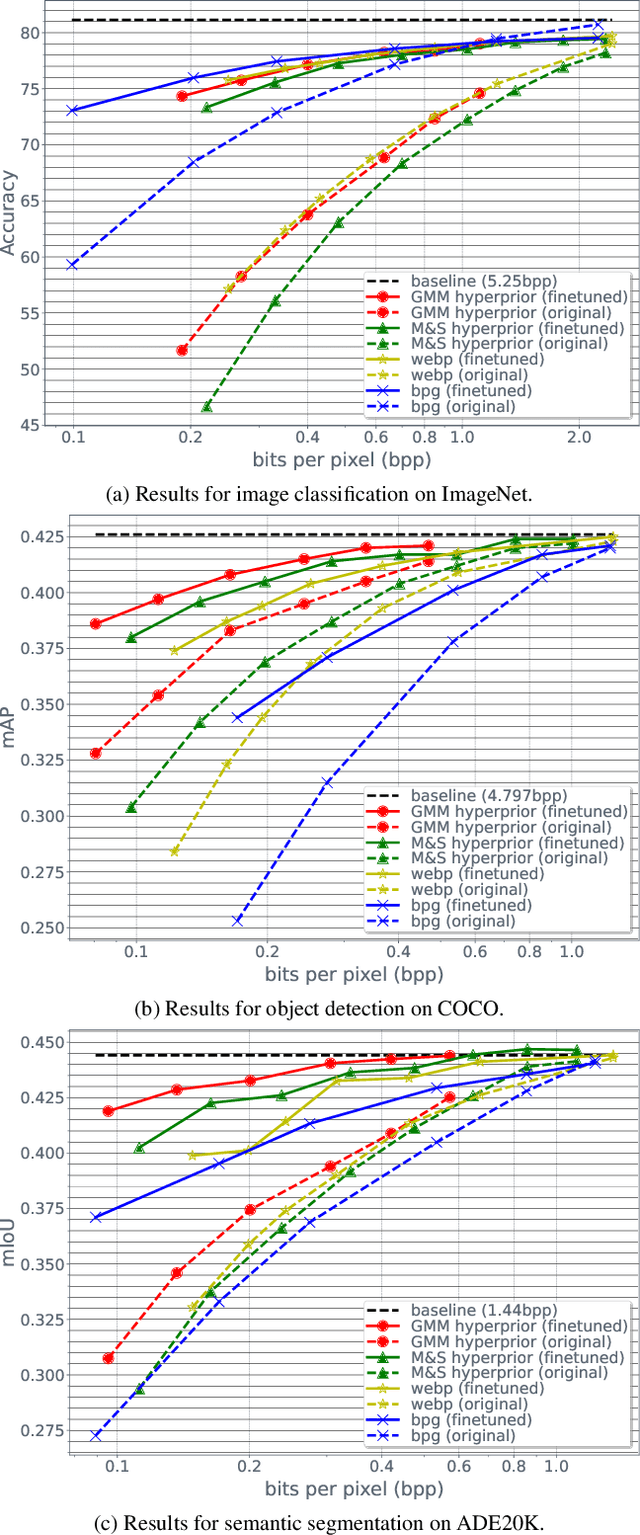
Reducing the data footprint of visual content via image compression is essential to reduce storage requirements, but also to reduce the bandwidth and latency requirements for transmission. In particular, the use of compressed images allows for faster transfer of data, and faster response times for visual recognition in edge devices that rely on cloud-based services. In this paper, we first analyze the impact of image compression using traditional codecs, as well as recent state-of-the-art neural compression approaches, on three visual recognition tasks: image classification, object detection, and semantic segmentation. We consider a wide range of compression levels, ranging from 0.1 to 2 bits-per-pixel (bpp). We find that for all three tasks, the recognition ability is significantly impacted when using strong compression. For example, for segmentation mIoU is reduced from 44.5 to 30.5 mIoU when compressing to 0.1 bpp using the best compression model we evaluated. Second, we test to what extent this performance drop can be ascribed to a loss of relevant information in the compressed image, or to a lack of generalization of visual recognition models to images with compression artefacts. We find that to a large extent the performance loss is due to the latter: by finetuning the recognition models on compressed training images, most of the performance loss is recovered. For example, bringing segmentation accuracy back up to 42 mIoU, i.e. recovering 82% of the original drop in accuracy.
Graph Convolutional Networks based on Manifold Learning for Semi-Supervised Image Classification
Apr 24, 2023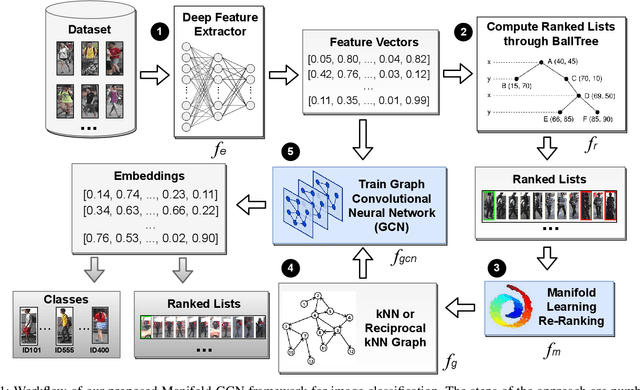
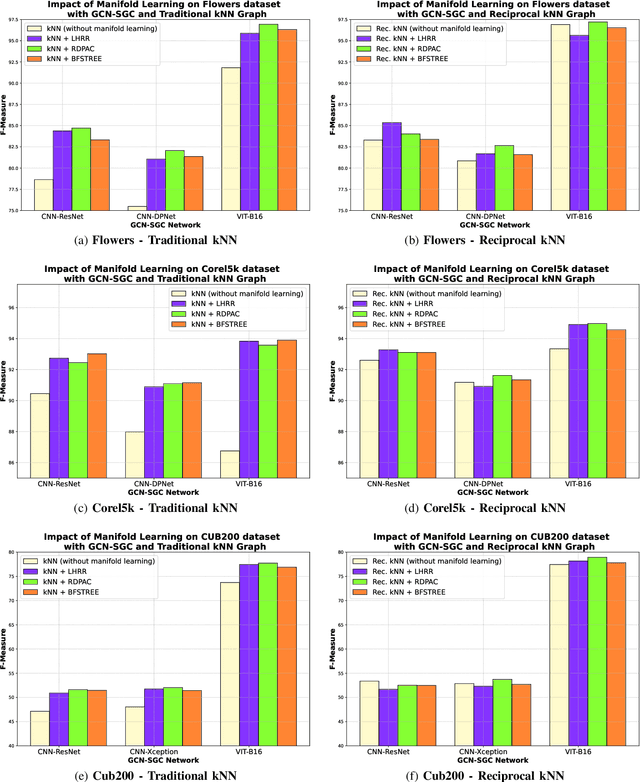
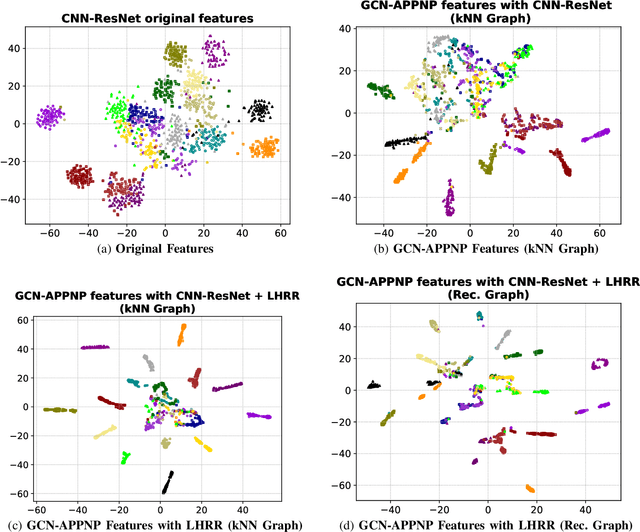
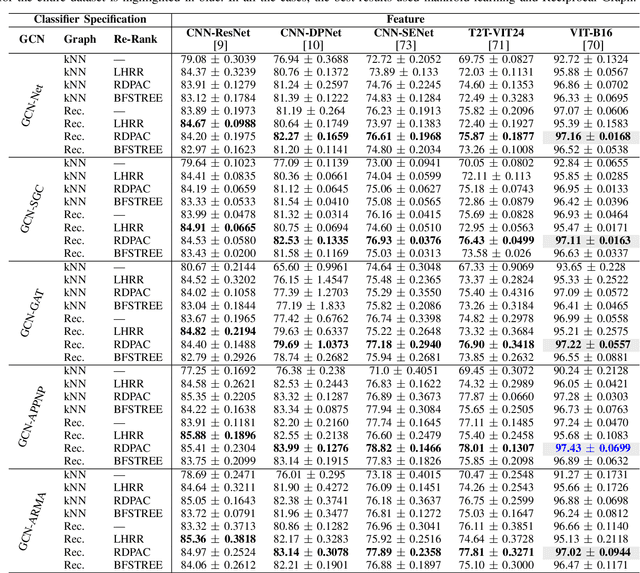
Due to a huge volume of information in many domains, the need for classification methods is imperious. In spite of many advances, most of the approaches require a large amount of labeled data, which is often not available, due to costs and difficulties of manual labeling processes. In this scenario, unsupervised and semi-supervised approaches have been gaining increasing attention. The GCNs (Graph Convolutional Neural Networks) represent a promising solution since they encode the neighborhood information and have achieved state-of-the-art results on scenarios with limited labeled data. However, since GCNs require graph-structured data, their use for semi-supervised image classification is still scarce in the literature. In this work, we propose a novel approach, the Manifold-GCN, based on GCNs for semi-supervised image classification. The main hypothesis of this paper is that the use of manifold learning to model the graph structure can further improve the GCN classification. To the best of our knowledge, this is the first framework that allows the combination of GCNs with different types of manifold learning approaches for image classification. All manifold learning algorithms employed are completely unsupervised, which is especially useful for scenarios where the availability of labeled data is a concern. A broad experimental evaluation was conducted considering 5 GCN models, 3 manifold learning approaches, 3 image datasets, and 5 deep features. The results reveal that our approach presents better accuracy than traditional and recent state-of-the-art methods with very efficient run times for both training and testing.
Weakly supervised marine animal detection from remote sensing images using vector-quantized variational autoencoder
Jul 13, 2023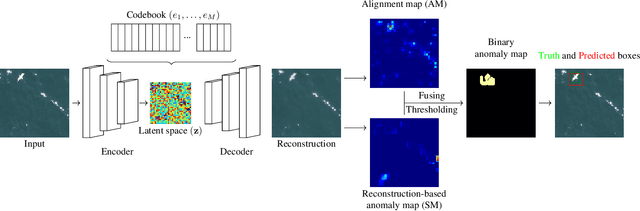
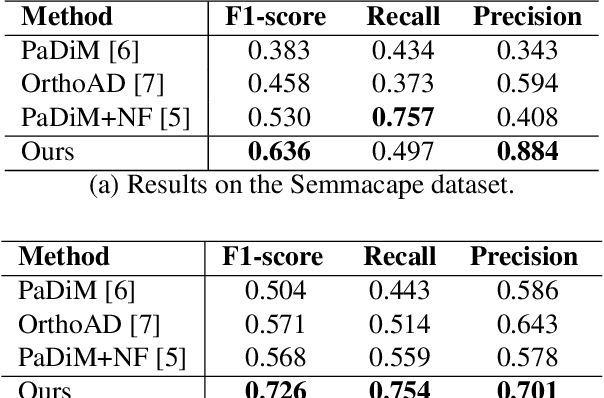
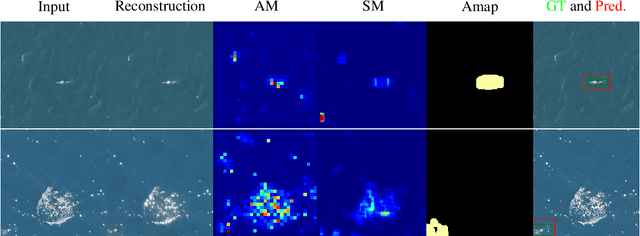

This paper studies a reconstruction-based approach for weakly-supervised animal detection from aerial images in marine environments. Such an approach leverages an anomaly detection framework that computes metrics directly on the input space, enhancing interpretability and anomaly localization compared to feature embedding methods. Building upon the success of Vector-Quantized Variational Autoencoders in anomaly detection on computer vision datasets, we adapt them to the marine animal detection domain and address the challenge of handling noisy data. To evaluate our approach, we compare it with existing methods in the context of marine animal detection from aerial image data. Experiments conducted on two dedicated datasets demonstrate the superior performance of the proposed method over recent studies in the literature. Our framework offers improved interpretability and localization of anomalies, providing valuable insights for monitoring marine ecosystems and mitigating the impact of human activities on marine animals.
UM-CAM: Uncertainty-weighted Multi-resolution Class Activation Maps for Weakly-supervised Fetal Brain Segmentation
Jun 20, 2023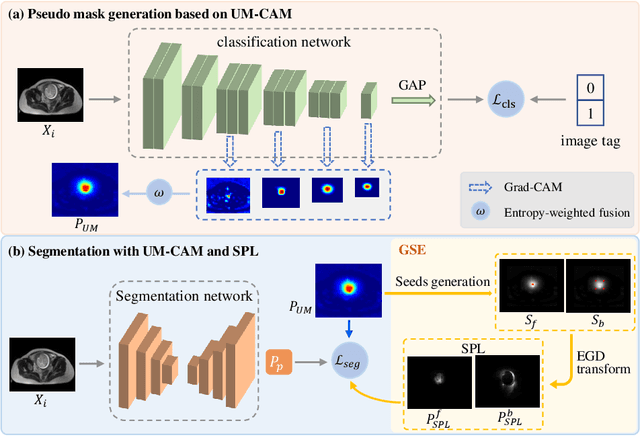
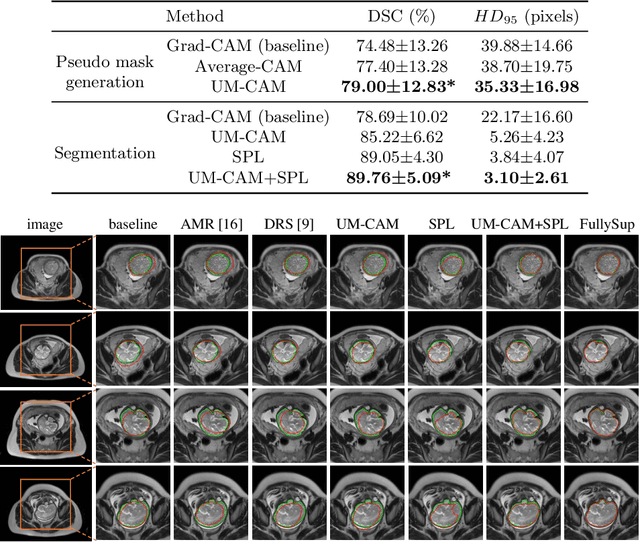
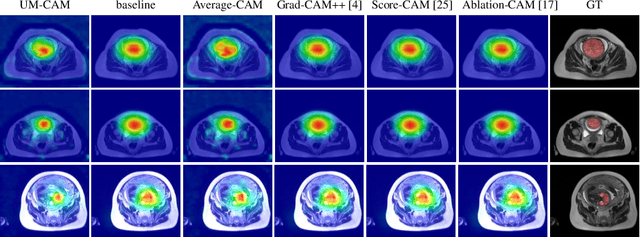
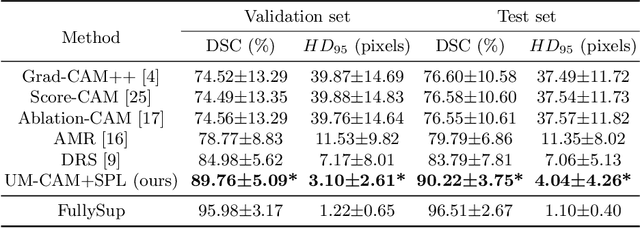
Accurate segmentation of the fetal brain from Magnetic Resonance Image (MRI) is important for prenatal assessment of fetal development. Although deep learning has shown the potential to achieve this task, it requires a large fine annotated dataset that is difficult to collect. To address this issue, weakly-supervised segmentation methods with image-level labels have gained attention, which are commonly based on class activation maps from a classification network trained with image tags. However, most of these methods suffer from incomplete activation regions, due to the low-resolution localization without detailed boundary cues. To this end, we propose a novel weakly-supervised method with image-level labels based on semantic features and context information exploration. We first propose an Uncertainty-weighted Multi-resolution Class Activation Map (UM-CAM) to generate high-quality pixel-level supervision. Then, we design a Geodesic distance-based Seed Expansion (GSE) method to provide context information for rectifying the ambiguous boundaries of UM-CAM. Extensive experiments on a fetal brain dataset show that our UM-CAM can provide more accurate activation regions with fewer false positive regions than existing CAM variants, and our proposed method outperforms state-of-the-art weakly-supervised methods with image-level labels.