 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
Apr 01, 2024
Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.
PICNIQ: Pairwise Comparisons for Natural Image Quality Assessment
Mar 13, 2024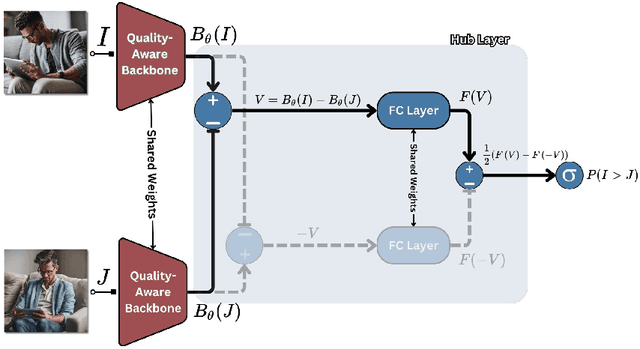
Blind image quality assessment (BIQA) approaches, while promising for automating image quality evaluation, often fall short in real-world scenarios due to their reliance on a generic quality standard applied uniformly across diverse images. This one-size-fits-all approach overlooks the crucial perceptual relationship between image content and quality, leading to a 'domain shift' challenge where a single quality metric inadequately represents various content types. Furthermore, BIQA techniques typically overlook the inherent differences in the human visual system among different observers. In response to these challenges, this paper introduces PICNIQ, an innovative pairwise comparison framework designed to bypass the limitations of conventional BIQA by emphasizing relative, rather than absolute, quality assessment. PICNIQ is specifically designed to assess the quality differences between image pairs. The proposed framework implements a carefully crafted deep learning architecture, a specialized loss function, and a training strategy optimized for sparse comparison settings. By employing psychometric scaling algorithms like TrueSkill, PICNIQ transforms pairwise comparisons into just-objectionable-difference (JOD) quality scores, offering a granular and interpretable measure of image quality. We conduct our research using comparison matrices from the PIQ23 dataset, which are published in this paper. Our extensive experimental analysis showcases PICNIQ's broad applicability and superior performance over existing models, highlighting its potential to set new standards in the field of BIQA.
EfficientMorph: Parameter-Efficient Transformer-Based Architecture for 3D Image Registration
Mar 16, 2024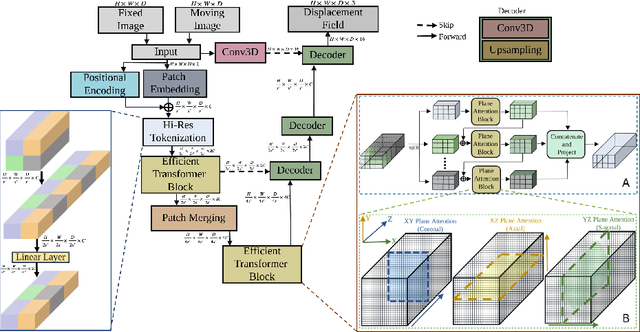
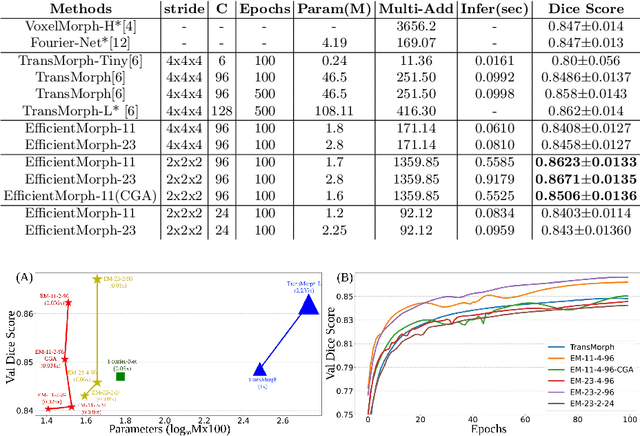
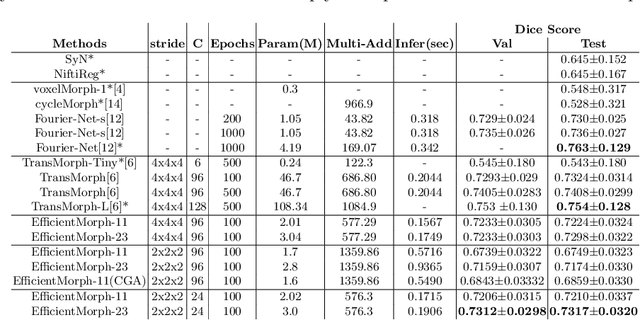
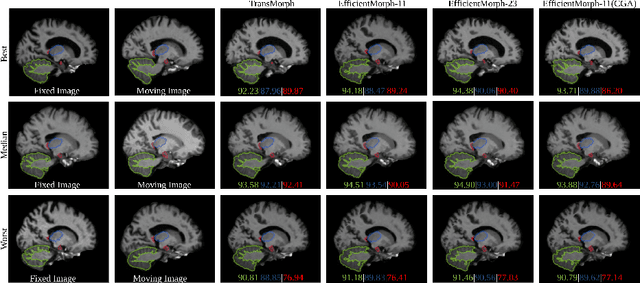
Transformers have emerged as the state-of-the-art architecture in medical image registration, outperforming convolutional neural networks (CNNs) by addressing their limited receptive fields and overcoming gradient instability in deeper models. Despite their success, transformer-based models require substantial resources for training, including data, memory, and computational power, which may restrict their applicability for end users with limited resources. In particular, existing transformer-based 3D image registration architectures face three critical gaps that challenge their efficiency and effectiveness. Firstly, while mitigating the quadratic complexity of full attention by focusing on local regions, window-based attention mechanisms often fail to adequately integrate local and global information. Secondly, feature similarities across attention heads that were recently found in multi-head attention architectures indicate a significant computational redundancy, suggesting that the capacity of the network could be better utilized to enhance performance. Lastly, the granularity of tokenization, a key factor in registration accuracy, presents a trade-off; smaller tokens improve detail capture at the cost of higher computational complexity, increased memory demands, and a risk of overfitting. Here, we propose EfficientMorph, a transformer-based architecture for unsupervised 3D image registration. It optimizes the balance between local and global attention through a plane-based attention mechanism, reduces computational redundancy via cascaded group attention, and captures fine details without compromising computational efficiency, thanks to a Hi-Res tokenization strategy complemented by merging operations. Notably, EfficientMorph sets a new benchmark for performance on the OASIS dataset with 16-27x fewer parameters.
Self-Corrective Sensor Fusion for Drone Positioning in Indoor Facilities
Mar 30, 2024Drones may be more advantageous than fixed cameras for quality control applications in industrial facilities, since they can be redeployed dynamically and adjusted to production planning. The practical scenario that has motivated this paper, image acquisition with drones in a car manufacturing plant, requires drone positioning accuracy in the order of 5 cm. During repetitive manufacturing processes, it is assumed that quality control imaging drones will follow highly deterministic periodic paths, stop at predefined points to take images and send them to image recognition servers. Therefore, by relying on prior knowledge about production chain schedules, it is possible to optimize the positioning technologies for the drones to stay at all times within the boundaries of their flight plans, which will be composed of stopping points and the paths in between. This involves mitigating issues such as temporary blocking of line-of-sight between the drone and any existing radio beacons; sensor data noise; and the loss of visual references. We present a self-corrective solution for this purpose. It corrects visual odometer readings based on filtered and clustered Ultra-Wide Band (UWB) data, as an alternative to direct Kalman fusion. The approach combines the advantages of these technologies when at least one of them works properly at any measurement spot. It has three method components: independent Kalman filtering, data association by means of stream clustering and mutual correction of sensor readings based on the generation of cumulative correction vectors. The approach is inspired by the observation that UWB positioning works reasonably well at static spots whereas visual odometer measurements reflect straight displacements correctly but can underestimate their length. Our experimental results demonstrate the advantages of the approach in the application scenario over Kalman fusion.
Breaking the Limitations with Sparse Inputs by Variational Frameworks (BLIss) in Terahertz Super-Resolution 3D Reconstruction
Mar 27, 2024Data acquisition, image processing, and image quality are the long-lasting issues for terahertz (THz) 3D reconstructed imaging. Existing methods are primarily designed for 2D scenarios, given the challenges associated with obtaining super-resolution (SR) data and the absence of an efficient SR 3D reconstruction framework in conventional computed tomography (CT). Here, we demonstrate BLIss, a new approach for THz SR 3D reconstruction with sparse 2D data input. BLIss seamlessly integrates conventional CT techniques and variational framework with the core of the adapted Euler-Elastica-based model. The quantitative 3D image evaluation metrics, including the standard deviation of Gaussian, mean curvatures, and the multi-scale structural similarity index measure (MS-SSIM), validate the superior smoothness and fidelity achieved with our variational framework approach compared with conventional THz CT modal. Beyond its contributions to advancing THz SR 3D reconstruction, BLIss demonstrates potential applicability in other imaging modalities, such as X-ray and MRI. This suggests extensive impacts on the broader field of imaging applications.
* 15 pages, 7 figures. Supplemental Document: https://doi.org/10.6084/m9.figshare.24455206
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
NYC-Indoor-VPR: A Long-Term Indoor Visual Place Recognition Dataset with Semi-Automatic Annotation
Mar 31, 2024Visual Place Recognition (VPR) in indoor environments is beneficial to humans and robots for better localization and navigation. It is challenging due to appearance changes at various frequencies, and difficulties of obtaining ground truth metric trajectories for training and evaluation. This paper introduces the NYC-Indoor-VPR dataset, a unique and rich collection of over 36,000 images compiled from 13 distinct crowded scenes in New York City taken under varying lighting conditions with appearance changes. Each scene has multiple revisits across a year. To establish the ground truth for VPR, we propose a semiautomatic annotation approach that computes the positional information of each image. Our method specifically takes pairs of videos as input and yields matched pairs of images along with their estimated relative locations. The accuracy of this matching is refined by human annotators, who utilize our annotation software to correlate the selected keyframes. Finally, we present a benchmark evaluation of several state-of-the-art VPR algorithms using our annotated dataset, revealing its challenge and thus value for VPR research.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
Apr 01, 2024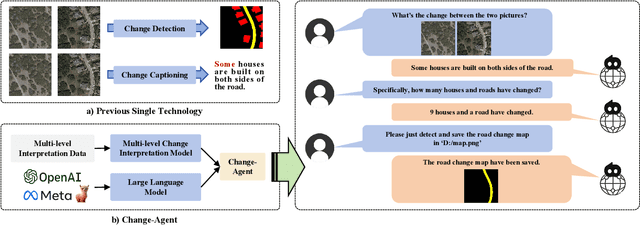
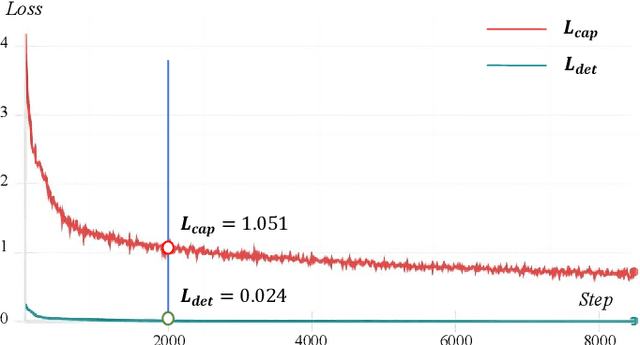
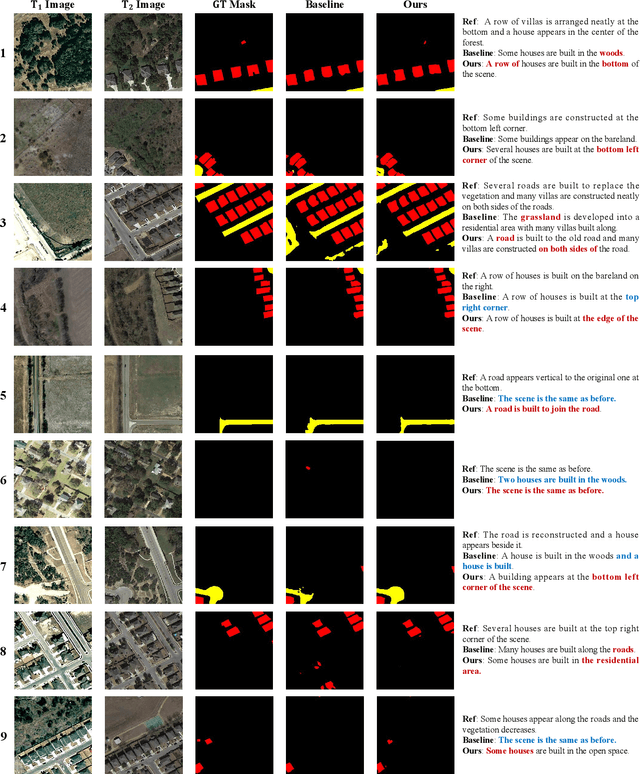
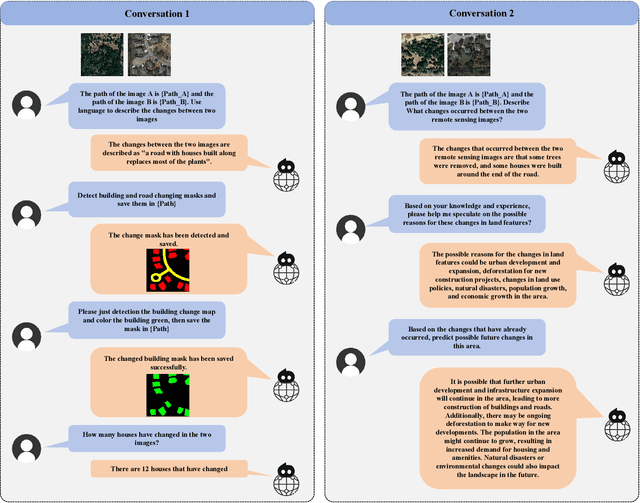
Monitoring changes in the Earth's surface is crucial for understanding natural processes and human impacts, necessitating precise and comprehensive interpretation methodologies. Remote sensing satellite imagery offers a unique perspective for monitoring these changes, leading to the emergence of remote sensing image change interpretation (RSICI) as a significant research focus. Current RSICI technology encompasses change detection and change captioning, each with its limitations in providing comprehensive interpretation. To address this, we propose an interactive Change-Agent, which can follow user instructions to achieve comprehensive change interpretation and insightful analysis according to user instructions, such as change detection and change captioning, change object counting, change cause analysis, etc. The Change-Agent integrates a multi-level change interpretation (MCI) model as the eyes and a large language model (LLM) as the brain. The MCI model contains two branches of pixel-level change detection and semantic-level change captioning, in which multiple BI-temporal Iterative Interaction (BI3) layers utilize Local Perception Enhancement (LPE) and the Global Difference Fusion Attention (GDFA) modules to enhance the model's discriminative feature representation capabilities. To support the training of the MCI model, we build the LEVIR-MCI dataset with a large number of change masks and captions of changes. Extensive experiments demonstrate the effectiveness of the proposed MCI model and highlight the promising potential of our Change-Agent in facilitating comprehensive and intelligent interpretation of surface changes. To facilitate future research, we will make our dataset and codebase of the MCI model and Change-Agent publicly available at https://github.com/Chen-Yang-Liu/Change-Agent
Make Me Happier: Evoking Emotions Through Image Diffusion Models
Mar 13, 2024
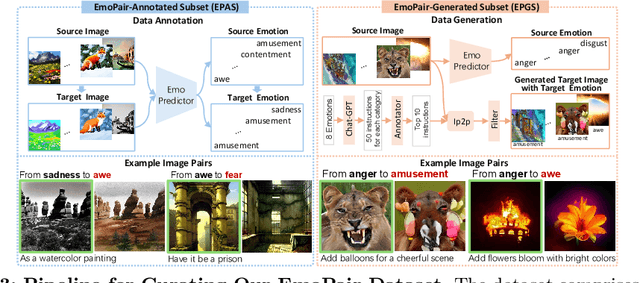
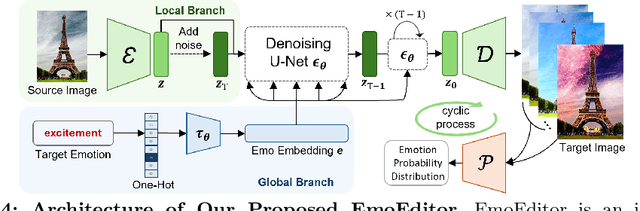
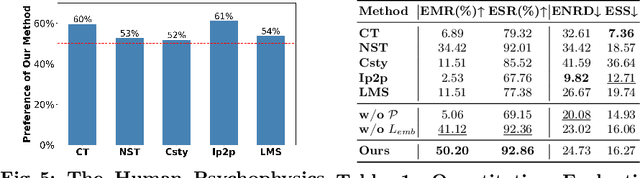
Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and data will be made public.