 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Deep Learning Techniques for Accurate Lung Cancer Detection and Classification
Aug 08, 2025Lung cancer (LC) ranks among the most frequently diagnosed cancers and is one of the most common causes of death for men and women worldwide. Computed Tomography (CT) images are the most preferred diagnosis method because of their low cost and their faster processing times. Many researchers have proposed various ways of identifying lung cancer using CT images. However, such techniques suffer from significant false positives, leading to low accuracy. The fundamental reason results from employing a small and imbalanced dataset. This paper introduces an innovative approach for LC detection and classification from CT images based on the DenseNet201 model. Our approach comprises several advanced methods such as Focal Loss, data augmentation, and regularization to overcome the imbalanced data issue and overfitting challenge. The findings show the appropriateness of the proposal, attaining a promising performance of 98.95% accuracy.
Optimal word order for non-causal text generation with Large Language Models: the Spanish case
Feb 20, 2025Natural Language Generation (NLG) popularity has increased owing to the progress in Large Language Models (LLMs), with zero-shot inference capabilities. However, most neural systems utilize decoder-only causal (unidirectional) transformer models, which are effective for English but may reduce the richness of languages with less strict word order, subject omission, or different relative clause attachment preferences. This is the first work that analytically addresses optimal text generation order for non-causal language models. We present a novel Viterbi algorithm-based methodology for maximum likelihood word order estimation. We analyze the non-causal most-likelihood order probability for NLG in Spanish and, then, the probability of generating the same phrases with Spanish causal NLG. This comparative analysis reveals that causal NLG prefers English-like SVO structures. We also analyze the relationship between optimal generation order and causal left-to-right generation order using Spearman's rank correlation. Our results demonstrate that the ideal order predicted by the maximum likelihood estimator is not closely related to the causal order and may be influenced by the syntactic structure of the target sentence.
Detecting anxiety and depression in dialogues: a multi-label and explainable approach
Dec 23, 2024Anxiety and depression are the most common mental health issues worldwide, affecting a non-negligible part of the population. Accordingly, stakeholders, including governments' health systems, are developing new strategies to promote early detection and prevention from a holistic perspective (i.e., addressing several disorders simultaneously). In this work, an entirely novel system for the multi-label classification of anxiety and depression is proposed. The input data consists of dialogues from user interactions with an assistant chatbot. Another relevant contribution lies in using Large Language Models (LLMs) for feature extraction, provided the complexity and variability of language. The combination of LLMs, given their high capability for language understanding, and Machine Learning (ML) models, provided their contextual knowledge about the classification problem thanks to the labeled data, constitute a promising approach towards mental health assessment. To promote the solution's trustworthiness, reliability, and accountability, explainability descriptions of the model's decision are provided in a graphical dashboard. Experimental results on a real dataset attain 90 % accuracy, improving those in the prior literature. The ultimate objective is to contribute in an accessible and scalable way before formal treatment occurs in the healthcare systems.
Explainable cognitive decline detection in free dialogues with a Machine Learning approach based on pre-trained Large Language Models
Nov 04, 2024Cognitive and neurological impairments are very common, but only a small proportion of affected individuals are diagnosed and treated, partly because of the high costs associated with frequent screening. Detecting pre-illness stages and analyzing the progression of neurological disorders through effective and efficient intelligent systems can be beneficial for timely diagnosis and early intervention. We propose using Large Language Models to extract features from free dialogues to detect cognitive decline. These features comprise high-level reasoning content-independent features (such as comprehension, decreased awareness, increased distraction, and memory problems). Our solution comprises (i) preprocessing, (ii) feature engineering via Natural Language Processing techniques and prompt engineering, (iii) feature analysis and selection to optimize performance, and (iv) classification, supported by automatic explainability. We also explore how to improve Chatgpt's direct cognitive impairment prediction capabilities using the best features in our models. Evaluation metrics obtained endorse the effectiveness of a mixed approach combining feature extraction with Chatgpt and a specialized Machine Learning model to detect cognitive decline within free-form conversational dialogues with older adults. Ultimately, our work may facilitate the development of an inexpensive, non-invasive, and rapid means of detecting and explaining cognitive decline.
Leveraging Large Language Models through Natural Language Processing to provide interpretable Machine Learning predictions of mental deterioration in real time
Sep 05, 2024Based on official estimates, 50 million people worldwide are affected by dementia, and this number increases by 10 million new patients every year. Without a cure, clinical prognostication and early intervention represent the most effective ways to delay its progression. To this end, Artificial Intelligence and computational linguistics can be exploited for natural language analysis, personalized assessment, monitoring, and treatment. However, traditional approaches need more semantic knowledge management and explicability capabilities. Moreover, using Large Language Models (LLMs) for cognitive decline diagnosis is still scarce, even though these models represent the most advanced way for clinical-patient communication using intelligent systems. Consequently, we leverage an LLM using the latest Natural Language Processing (NLP) techniques in a chatbot solution to provide interpretable Machine Learning prediction of cognitive decline in real-time. Linguistic-conceptual features are exploited for appropriate natural language analysis. Through explainability, we aim to fight potential biases of the models and improve their potential to help clinical workers in their diagnosis decisions. More in detail, the proposed pipeline is composed of (i) data extraction employing NLP-based prompt engineering; (ii) stream-based data processing including feature engineering, analysis, and selection; (iii) real-time classification; and (iv) the explainability dashboard to provide visual and natural language descriptions of the prediction outcome. Classification results exceed 80 % in all evaluation metrics, with a recall value for the mental deterioration class about 85 %. To sum up, we contribute with an affordable, flexible, non-invasive, personalized diagnostic system to this work.
Predictability and Causality in Spanish and English Natural Language Generation
Aug 26, 2024In recent years, the field of Natural Language Generation (NLG) has been boosted by the recent advances in deep learning technologies. Nonetheless, these new data-intensive methods introduce language-dependent disparities in NLG as the main training data sets are in English. Also, most neural NLG systems use decoder-only (causal) transformer language models, which work well for English, but were not designed with other languages in mind. In this work we depart from the hypothesis that they may introduce generation bias in target languages with less rigid word ordering, subject omission, or different attachment preferences for relative clauses, so that for these target languages other language generation strategies may be more desirable. This paper first compares causal and non-causal language modeling for English and Spanish, two languages with different grammatical structures and over 1.5 billion and 0.5 billion speakers, respectively. For this purpose, we define a novel metric of average causal and non-causal context-conditioned entropy of the grammatical category distribution for both languages as an information-theoretic a priori approach. The evaluation of natural text sources (such as training data) in both languages reveals lower average non-causal conditional entropy in Spanish and lower causal conditional entropy in English. According to this experiment, Spanish is more predictable than English given a non-causal context. Then, by applying a conditional relative entropy metric to text generation experiments, we obtain as insights that the best performance is respectively achieved with causal NLG in English, and with non-causal NLG in Spanish. These insights support further research in NLG in Spanish using bidirectional transformer language models.
Online detection and infographic explanation of spam reviews with data drift adaptation
Jun 21, 2024



Spam reviews are a pervasive problem on online platforms due to its significant impact on reputation. However, research into spam detection in data streams is scarce. Another concern lies in their need for transparency. Consequently, this paper addresses those problems by proposing an online solution for identifying and explaining spam reviews, incorporating data drift adaptation. It integrates (i) incremental profiling, (ii) data drift detection & adaptation, and (iii) identification of spam reviews employing Machine Learning. The explainable mechanism displays a visual and textual prediction explanation in a dashboard. The best results obtained reached up to 87 % spam F-measure.
Toward data-driven research: preliminary study to predict surface roughness in material extrusion using previously published data with Machine Learning
Jun 20, 2024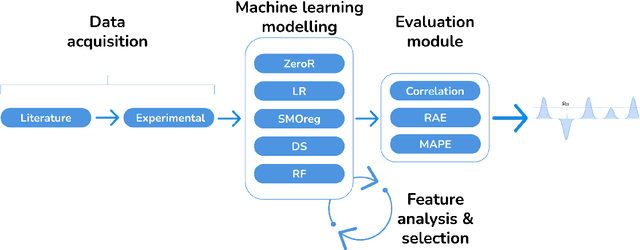

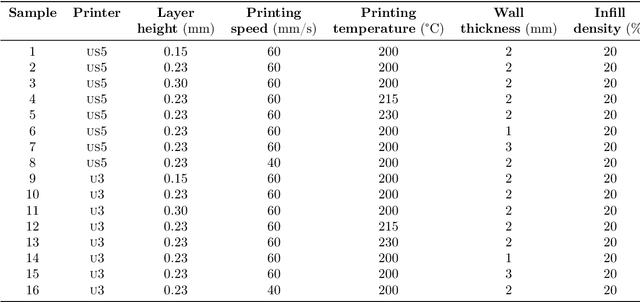
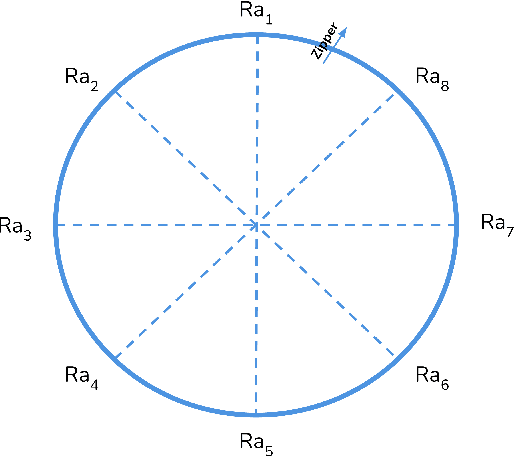
Material extrusion is one of the most commonly used approaches within the additive manufacturing processes available. Despite its popularity and related technical advancements, process reliability and quality assurance remain only partially solved. In particular, the surface roughness caused by this process is a key concern. To solve this constraint, experimental plans have been exploited to optimize surface roughness in recent years. However, the latter empirical trial and error process is extremely time- and resource-consuming. Thus, this study aims to avoid using large experimental programs to optimize surface roughness in material extrusion. Methodology. This research provides an in-depth analysis of the effect of several printing parameters: layer height, printing temperature, printing speed and wall thickness. The proposed data-driven predictive modeling approach takes advantage of Machine Learning models to automatically predict surface roughness based on the data gathered from the literature and the experimental data generated for testing. Findings. Using 10-fold cross-validation of data gathered from the literature, the proposed Machine Learning solution attains a 0.93 correlation with a mean absolute percentage error of 13 %. When testing with our own data, the correlation diminishes to 0.79 and the mean absolute percentage error reduces to 8 %. Thus, the solution for predicting surface roughness in extrusion-based printing offers competitive results regarding the variability of the analyzed factors. Originality. As available manufacturing data continue to increase on a daily basis, the ability to learn from these large volumes of data is critical in future manufacturing and science. Specifically, the power of Machine Learning helps model surface roughness with limited experimental tests.
Informatics & dairy industry coalition: AI trends and present challenges
Jun 19, 2024



Artificial Intelligence (AI) can potentially transform the industry, enhancing the production process and minimizing manual, repetitive tasks. Accordingly, the synergy between high-performance computing and powerful mathematical models enables the application of sophisticated data analysis procedures like Machine Learning. However, challenges exist regarding effective, efficient, and flexible processing to generate valuable knowledge. Consequently, this work comprehensively describes industrial challenges where AI can be exploited, focusing on the dairy industry. The conclusions presented can help researchers apply novel approaches for cattle monitoring and farmers by proposing advanced technological solutions to their needs.
Formatics & dairy industry coalition: AI trends and present challenges
Jun 18, 2024Artificial Intelligence (AI) can potentially transform the industry, enhancing the production process and minimizing manual, repetitive tasks. Accordingly, the synergy between high-performance computing and powerful mathematical models enables the application of sophisticated data analysis procedures like Machine Learning. However, challenges exist regarding effective, efficient, and flexible processing to generate valuable knowledge. Consequently, this work comprehensively describes industrial challenges where AI can be exploited, focusing on the dairy industry. The conclusions presented can help researchers apply novel approaches for cattle monitoring and farmers by proposing advanced technological solutions to their needs.