 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do Diffusion Models Suffer Error Propagation? Theoretical Analysis and Consistency Regularization
Aug 09, 2023
While diffusion models have achieved promising performances in data synthesis, they might suffer error propagation because of their cascade structure, where the distributional mismatch spreads and magnifies through the chain of denoising modules. However, a strict analysis is expected since many sequential models such as Conditional Random Field (CRF) are free from error propagation. In this paper, we empirically and theoretically verify that diffusion models are indeed affected by error propagation and we then propose a regularization to address this problem. Our theoretical analysis reveals that the question can be reduced to whether every denoising module of the diffusion model is fault-tolerant. We derive insightful transition equations, indicating that the module can't recover from input errors and even propagates additional errors to the next module. Our analysis directly leads to a consistency regularization scheme for diffusion models, which explicitly reduces the distribution gap between forward and backward processes. We further introduce a bootstrapping algorithm to reduce the computation cost of the regularizer. Our experimental results on multiple image datasets show that our regularization effectively handles error propagation and significantly improves the performance of vanilla diffusion models.
DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
Aug 09, 2023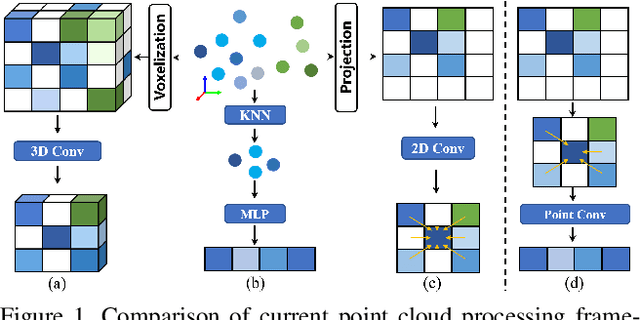
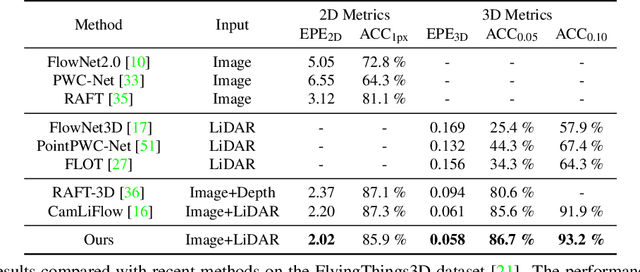
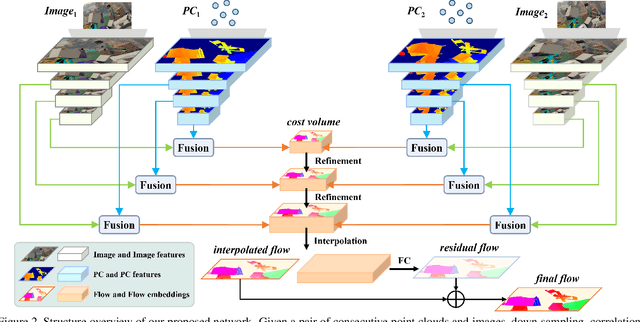
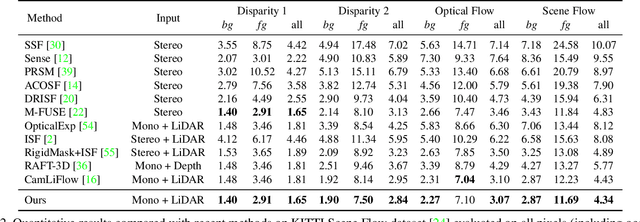
Point clouds are naturally sparse, while image pixels are dense. The inconsistency limits feature fusion from both modalities for point-wise scene flow estimation. Previous methods rarely predict scene flow from the entire point clouds of the scene with one-time inference due to the memory inefficiency and heavy overhead from distance calculation and sorting involved in commonly used farthest point sampling, KNN, and ball query algorithms for local feature aggregation. To mitigate these issues in scene flow learning, we regularize raw points to a dense format by storing 3D coordinates in 2D grids. Unlike the sampling operation commonly used in existing works, the dense 2D representation 1) preserves most points in the given scene, 2) brings in a significant boost of efficiency, and 3) eliminates the density gap between points and pixels, allowing us to perform effective feature fusion. We also present a novel warping projection technique to alleviate the information loss problem resulting from the fact that multiple points could be mapped into one grid during projection when computing cost volume. Sufficient experiments demonstrate the efficiency and effectiveness of our method, outperforming the prior-arts on the FlyingThings3D and KITTI dataset.
SelectNAdapt: Support Set Selection for Few-Shot Domain Adaptation
Aug 09, 2023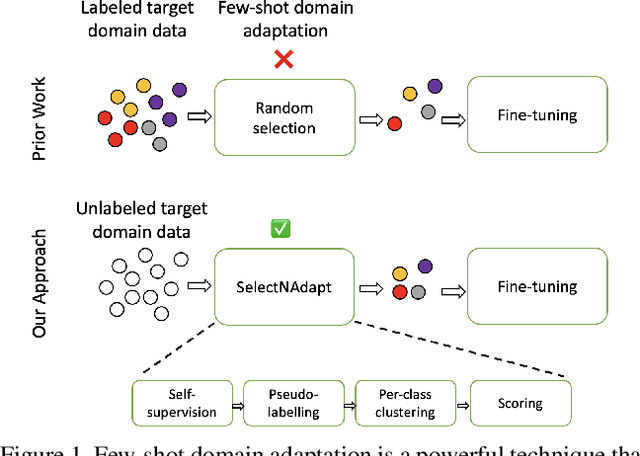

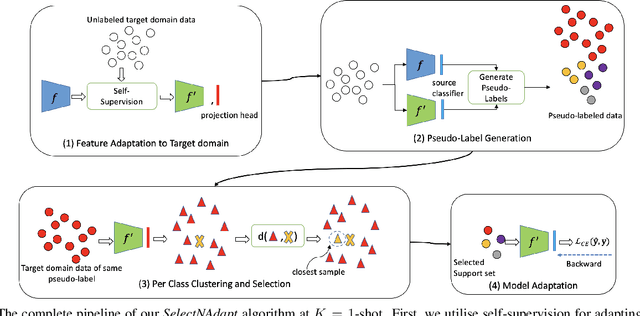
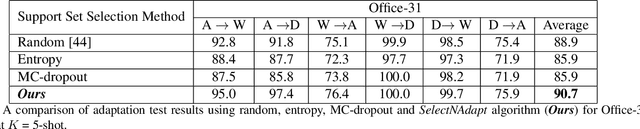
Generalisation of deep neural networks becomes vulnerable when distribution shifts are encountered between train (source) and test (target) domain data. Few-shot domain adaptation mitigates this issue by adapting deep neural networks pre-trained on the source domain to the target domain using a randomly selected and annotated support set from the target domain. This paper argues that randomly selecting the support set can be further improved for effectively adapting the pre-trained source models to the target domain. Alternatively, we propose SelectNAdapt, an algorithm to curate the selection of the target domain samples, which are then annotated and included in the support set. In particular, for the K-shot adaptation problem, we first leverage self-supervision to learn features of the target domain data. Then, we propose a per-class clustering scheme of the learned target domain features and select K representative target samples using a distance-based scoring function. Finally, we bring our selection setup towards a practical ground by relying on pseudo-labels for clustering semantically similar target domain samples. Our experiments show promising results on three few-shot domain adaptation benchmarks for image recognition compared to related approaches and the standard random selection.
LoLep: Single-View View Synthesis with Locally-Learned Planes and Self-Attention Occlusion Inference
Aug 09, 2023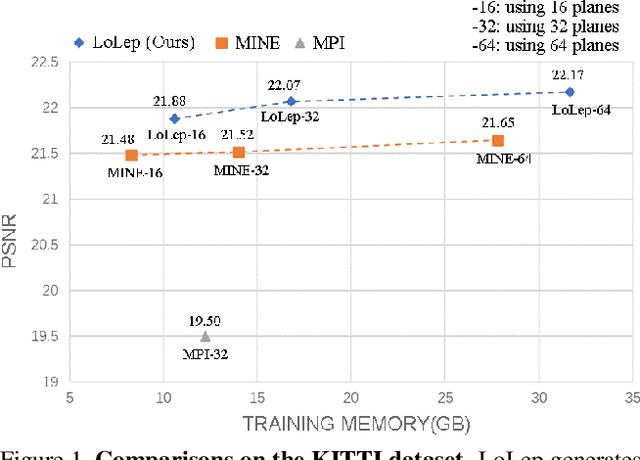

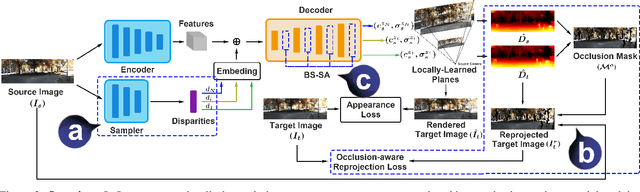
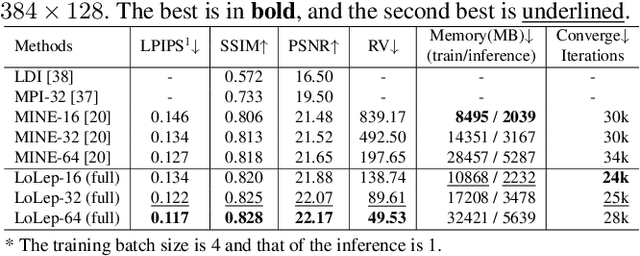
We propose a novel method, LoLep, which regresses Locally-Learned planes from a single RGB image to represent scenes accurately, thus generating better novel views. Without the depth information, regressing appropriate plane locations is a challenging problem. To solve this issue, we pre-partition the disparity space into bins and design a disparity sampler to regress local offsets for multiple planes in each bin. However, only using such a sampler makes the network not convergent; we further propose two optimizing strategies that combine with different disparity distributions of datasets and propose an occlusion-aware reprojection loss as a simple yet effective geometric supervision technique. We also introduce a self-attention mechanism to improve occlusion inference and present a Block-Sampling Self-Attention (BS-SA) module to address the problem of applying self-attention to large feature maps. We demonstrate the effectiveness of our approach and generate state-of-the-art results on different datasets. Compared to MINE, our approach has an LPIPS reduction of 4.8%-9.0% and an RV reduction of 73.9%-83.5%. We also evaluate the performance on real-world images and demonstrate the benefits.
Absorption-Based, Passive Range Imaging from Hyperspectral Thermal Measurements
Aug 10, 2023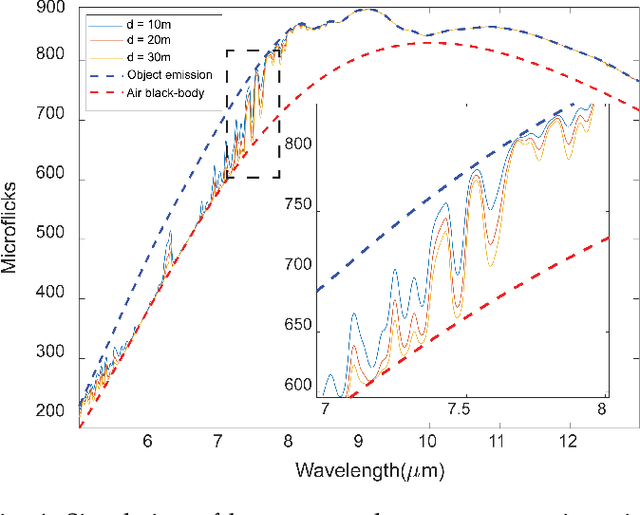
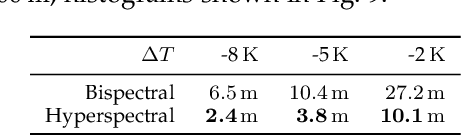
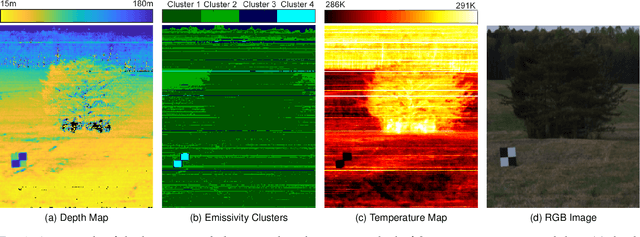

Passive hyperspectral long-wave infrared measurements are remarkably informative about the surroundings, such as remote object material composition, temperature, and range; and air temperature and gas concentrations. Remote object material and temperature determine the spectrum of thermal radiance, and range, air temperature, and gas concentrations determine how this spectrum is modified by propagation to the sensor. We computationally separate these phenomena, introducing a novel passive range imaging method based on atmospheric absorption of ambient thermal radiance. Previously demonstrated passive absorption-based ranging methods assume hot and highly emitting objects. However, the temperature variation in natural scenes is usually low, making range imaging challenging. Our method benefits from explicit consideration of air emission and parametric modeling of atmospheric absorption. To mitigate noise in low-contrast scenarios, we jointly estimate range and intrinsic object properties by exploiting a variety of absorption lines spread over the infrared spectrum. Along with Monte Carlo simulations that demonstrate the importance of regularization, temperature differentials, and availability of many spectral bands, we apply this method to long-wave infrared (8--13 $\mu$m) hyperspectral image data acquired from natural scenes with no active illumination. Range features from 15m to 150m are recovered, with good qualitative match to unaligned lidar data.
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
May 14, 2023
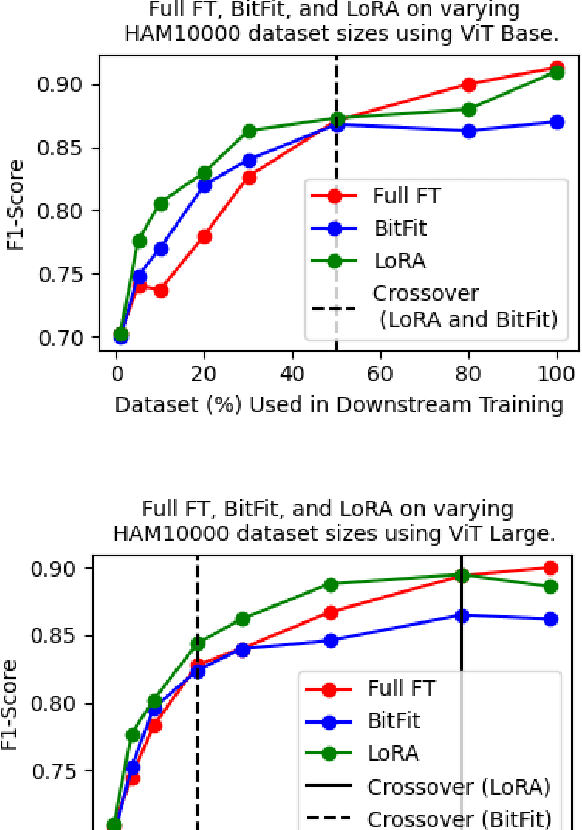
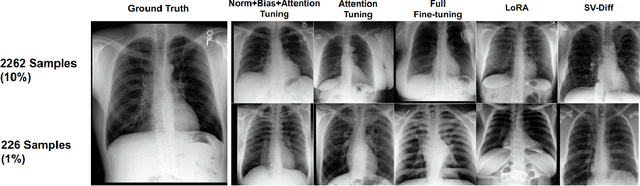
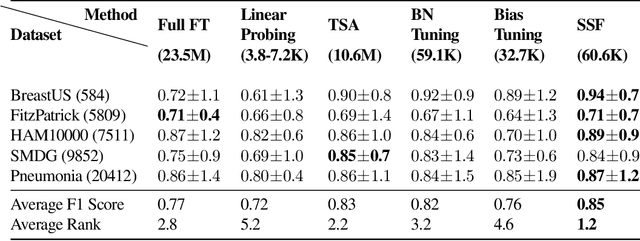
We present a comprehensive evaluation of Parameter-Efficient Fine-Tuning (PEFT) techniques for diverse medical image analysis tasks. PEFT is increasingly exploited as a valuable approach for knowledge transfer from pre-trained models in natural language processing, vision, speech, and cross-modal tasks, such as vision-language and text-to-image generation. However, its application in medical image analysis remains relatively unexplored. As foundation models are increasingly exploited in the medical domain, it is crucial to investigate and comparatively assess various strategies for knowledge transfer that can bolster a range of downstream tasks. Our study, the first of its kind (to the best of our knowledge), evaluates 16 distinct PEFT methodologies proposed for convolutional and transformer-based networks, focusing on image classification and text-to-image generation tasks across six medical datasets ranging in size, modality, and complexity. Through a battery of more than 600 controlled experiments, we demonstrate performance gains of up to 22% under certain scenarios and demonstrate the efficacy of PEFT for medical text-to-image generation. Further, we reveal the instances where PEFT methods particularly dominate over conventional fine-tuning approaches by studying their relationship with downstream data volume.
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023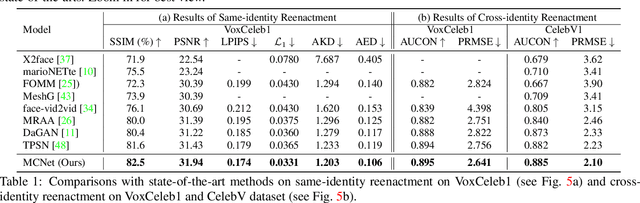
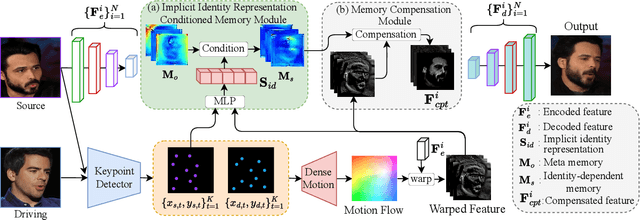
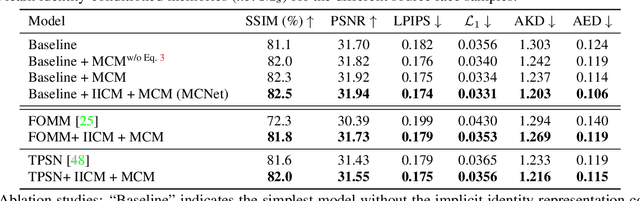
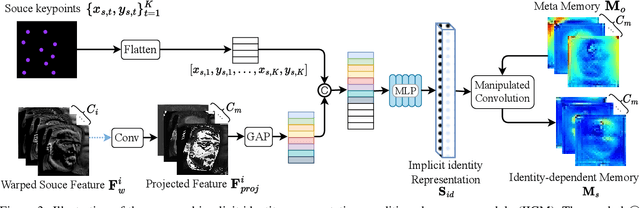
Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.
A Mountain-Shaped Single-Stage Network for Accurate Image Restoration
May 09, 2023
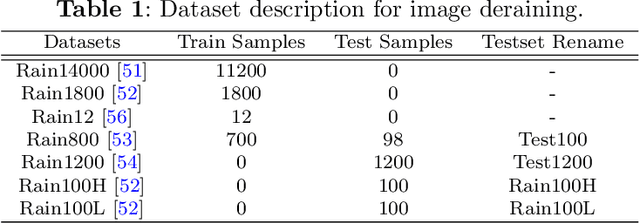
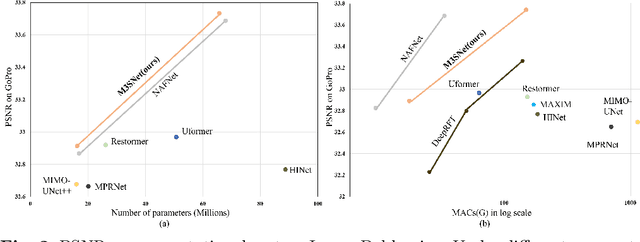

Image restoration is the task of aiming to obtain a high-quality image from a corrupt input image, such as deblurring and deraining. In image restoration, it is typically necessary to maintain a complex balance between spatial details and contextual information. Although a multi-stage network can optimally balance these competing goals and achieve significant performance, this also increases the system's complexity. In this paper, we propose a mountain-shaped single-stage design base on a simple U-Net architecture, which removes or replaces unnecessary nonlinear activation functions to achieve the above balance with low system complexity. Specifically, we propose a feature fusion middleware (FFM) mechanism as an information exchange component between the encoder-decoder architectural levels. It seamlessly integrates upper-layer information into the adjacent lower layer, sequentially down to the lowest layer. Finally, all information is fused into the original image resolution manipulation level. This preserves spatial details and integrates contextual information, ensuring high-quality image restoration. In addition, we propose a multi-head attention middle block (MHAMB) as a bridge between the encoder and decoder to capture more global information and surpass the limitations of the receptive field of CNNs. Extensive experiments demonstrate that our approach, named as M3SNet, outperforms previous state-of-the-art models while using less than half the computational costs, for several image restoration tasks, such as image deraining and deblurring.
Synthesizing Artistic Cinemagraphs from Text
Jul 12, 2023
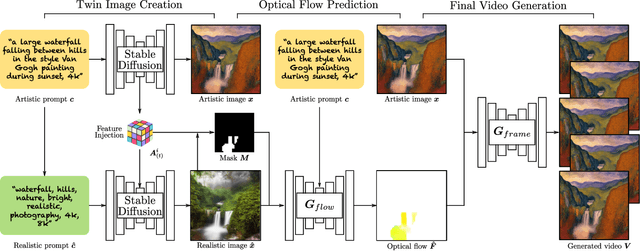


We introduce Text2Cinemagraph, a fully automated method for creating cinemagraphs from text descriptions - an especially challenging task when prompts feature imaginary elements and artistic styles, given the complexity of interpreting the semantics and motions of these images. Existing single-image animation methods fall short on artistic inputs, and recent text-based video methods frequently introduce temporal inconsistencies, struggling to keep certain regions static. To address these challenges, we propose an idea of synthesizing image twins from a single text prompt - a pair of an artistic image and its pixel-aligned corresponding natural-looking twin. While the artistic image depicts the style and appearance detailed in our text prompt, the realistic counterpart greatly simplifies layout and motion analysis. Leveraging existing natural image and video datasets, we can accurately segment the realistic image and predict plausible motion given the semantic information. The predicted motion can then be transferred to the artistic image to create the final cinemagraph. Our method outperforms existing approaches in creating cinemagraphs for natural landscapes as well as artistic and other-worldly scenes, as validated by automated metrics and user studies. Finally, we demonstrate two extensions: animating existing paintings and controlling motion directions using text.
Interferometric single-pixel imaging with a multicore fiber
Jul 17, 2023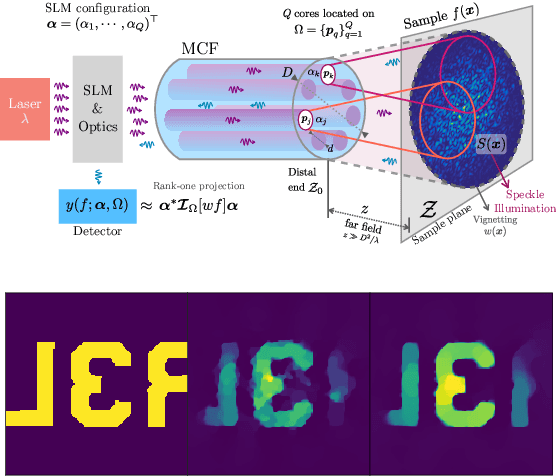
Lensless illumination single-pixel imaging with a multicore fiber (MCF) is a computational imaging technique that enables potential endoscopic observations of biological samples at cellular scale. In this work, we show that this technique is tantamount to collecting multiple symmetric rank-one projections (SROP) of a Hermitian \emph{interferometric} matrix -- a matrix encoding the spectral content of the sample image. In this model, each SROP is induced by the complex \emph{sketching} vector shaping the incident light wavefront with a spatial light modulator (SLM), while the projected interferometric matrix collects up to $O(Q^2)$ image frequencies for a $Q$-core MCF. While this scheme subsumes previous sensing modalities, such as raster scanning (RS) imaging with beamformed illumination, we demonstrate that collecting the measurements of $M$ random SLM configurations -- and thus acquiring $M$ SROPs -- allows us to estimate an image of interest if $M$ and $Q$ scale linearly (up to log factors) with the image sparsity level, hence requiring much fewer observations than RS imaging or a complete Nyquist sampling of the $Q \times Q$ interferometric matrix. This demonstration is achieved both theoretically, with a specific restricted isometry analysis of the sensing scheme, and with extensive Monte Carlo experiments. Experimental results made on an actual MCF system finally demonstrate the effectiveness of this imaging procedure on a benchmark image.