 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to make Medical AI Systems safer? Simulating Vulnerabilities, and Threats in Multimodal Medical RAG System
Aug 24, 2025



Large Vision-Language Models (LVLMs) augmented with Retrieval-Augmented Generation (RAG) are increasingly employed in medical AI to enhance factual grounding through external clinical image-text retrieval. However, this reliance creates a significant attack surface. We propose MedThreatRAG, a novel multimodal poisoning framework that systematically probes vulnerabilities in medical RAG systems by injecting adversarial image-text pairs. A key innovation of our approach is the construction of a simulated semi-open attack environment, mimicking real-world medical systems that permit periodic knowledge base updates via user or pipeline contributions. Within this setting, we introduce and emphasize Cross-Modal Conflict Injection (CMCI), which embeds subtle semantic contradictions between medical images and their paired reports. These mismatches degrade retrieval and generation by disrupting cross-modal alignment while remaining sufficiently plausible to evade conventional filters. While basic textual and visual attacks are included for completeness, CMCI demonstrates the most severe degradation. Evaluations on IU-Xray and MIMIC-CXR QA tasks show that MedThreatRAG reduces answer F1 scores by up to 27.66% and lowers LLaVA-Med-1.5 F1 rates to as low as 51.36%. Our findings expose fundamental security gaps in clinical RAG systems and highlight the urgent need for threat-aware design and robust multimodal consistency checks. Finally, we conclude with a concise set of guidelines to inform the safe development of future multimodal medical RAG systems.
CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
May 15, 2025We introduce CheXGenBench, a rigorous and multifaceted evaluation framework for synthetic chest radiograph generation that simultaneously assesses fidelity, privacy risks, and clinical utility across state-of-the-art text-to-image generative models. Despite rapid advancements in generative AI for real-world imagery, medical domain evaluations have been hindered by methodological inconsistencies, outdated architectural comparisons, and disconnected assessment criteria that rarely address the practical clinical value of synthetic samples. CheXGenBench overcomes these limitations through standardised data partitioning and a unified evaluation protocol comprising over 20 quantitative metrics that systematically analyse generation quality, potential privacy vulnerabilities, and downstream clinical applicability across 11 leading text-to-image architectures. Our results reveal critical inefficiencies in the existing evaluation protocols, particularly in assessing generative fidelity, leading to inconsistent and uninformative comparisons. Our framework establishes a standardised benchmark for the medical AI community, enabling objective and reproducible comparisons while facilitating seamless integration of both existing and future generative models. Additionally, we release a high-quality, synthetic dataset, SynthCheX-75K, comprising 75K radiographs generated by the top-performing model (Sana 0.6B) in our benchmark to support further research in this critical domain. Through CheXGenBench, we establish a new state-of-the-art and release our framework, models, and SynthCheX-75K dataset at https://raman1121.github.io/CheXGenBench/
Exploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
Apr 01, 2025In this work, we undertake the challenge of augmenting the existing generative capabilities of pre-trained text-only large language models (LLMs) with multi-modal generation capability while satisfying two core constraints: C1 preserving the preservation of original language generative capabilities with negligible performance degradation, and C2 adhering to a small parameter budget to learn the new modality, ensuring scalability and efficiency. In contrast to current approaches that add dedicated modules, thereby significantly increasing the parameter count, we propose a method that leverages the underutilized capacity inherent in deep models. Specifically, we exploit the parameter redundancy within Mixture-of-Experts (MoEs) as a source of additional capacity for learning a new modality, enabling better parameter efficiency (C1). Moreover, we preserve the original language generation capabilities by applying low-rank adaptation exclusively to the tokens of the new modality (C2). Furthermore, we introduce a novel parameter initialization scheme based on the Gromov-Wasserstein distance to improve convergence and training stability. Through an extensive analysis of the routing mechanism, we uncover the emergence of modality-specific pathways and decreased redundancy within the experts that can efficiently unlock multi-modal generative capabilities. Overall, our method can be seamlessly applied to a wide range of contemporary LLMs, providing a new pathway for transitioning from uni-modal to multi-modal architectures.
The Devil is in the Prompts: De-Identification Traces Enhance Memorization Risks in Synthetic Chest X-Ray Generation
Feb 11, 2025


Generative models, particularly text-to-image (T2I) diffusion models, play a crucial role in medical image analysis. However, these models are prone to training data memorization, posing significant risks to patient privacy. Synthetic chest X-ray generation is one of the most common applications in medical image analysis with the MIMIC-CXR dataset serving as the primary data repository for this task. This study adopts a data-driven approach and presents the first systematic attempt to identify prompts and text tokens in MIMIC-CXR that contribute the most to training data memorization. Our analysis reveals an unexpected finding: prompts containing traces of de-identification procedures are among the most memorized, with de-identification markers contributing the most. Furthermore, we also find existing inference-time memorization mitigation strategies are ineffective and fail to sufficiently reduce the model's reliance on memorized text tokens highlighting a broader issue in T2I synthesis with MIMIC-CXR. On this front, we propose actionable strategies to enhance privacy and improve the reliability of generative models in medical imaging. Finally, our results provide a foundation for future work on developing and benchmarking memorization mitigation techniques for synthetic chest X-ray generation using the MIMIC-CXR dataset.
Capacity Control is an Effective Memorization Mitigation Mechanism in Text-Conditional Diffusion Models
Oct 29, 2024

In this work, we present compelling evidence that controlling model capacity during fine-tuning can effectively mitigate memorization in diffusion models. Specifically, we demonstrate that adopting Parameter-Efficient Fine-Tuning (PEFT) within the pre-train fine-tune paradigm significantly reduces memorization compared to traditional full fine-tuning approaches. Our experiments utilize the MIMIC dataset, which comprises image-text pairs of chest X-rays and their corresponding reports. The results, evaluated through a range of memorization and generation quality metrics, indicate that PEFT not only diminishes memorization but also enhances downstream generation quality. Additionally, PEFT methods can be seamlessly combined with existing memorization mitigation techniques for further improvement. The code for our experiments is available at: https://github.com/Raman1121/Diffusion_Memorization_HPO
BMFT: Achieving Fairness via Bias-based Weight Masking Fine-tuning
Aug 13, 2024Developing models with robust group fairness properties is paramount, particularly in ethically sensitive domains such as medical diagnosis. Recent approaches to achieving fairness in machine learning require a substantial amount of training data and depend on model retraining, which may not be practical in real-world scenarios. To mitigate these challenges, we propose Bias-based Weight Masking Fine-Tuning (BMFT), a novel post-processing method that enhances the fairness of a trained model in significantly fewer epochs without requiring access to the original training data. BMFT produces a mask over model parameters, which efficiently identifies the weights contributing the most towards biased predictions. Furthermore, we propose a two-step debiasing strategy, wherein the feature extractor undergoes initial fine-tuning on the identified bias-influenced weights, succeeded by a fine-tuning phase on a reinitialised classification layer to uphold discriminative performance. Extensive experiments across four dermatological datasets and two sensitive attributes demonstrate that BMFT outperforms existing state-of-the-art (SOTA) techniques in both diagnostic accuracy and fairness metrics. Our findings underscore the efficacy and robustness of BMFT in advancing fairness across various out-of-distribution (OOD) settings. Our code is available at: https://github.com/vios-s/BMFT
MemControl: Mitigating Memorization in Medical Diffusion Models via Automated Parameter Selection
May 29, 2024



Diffusion models show a remarkable ability in generating images that closely mirror the training distribution. However, these models are prone to training data memorization, leading to significant privacy, ethical, and legal concerns, particularly in sensitive fields such as medical imaging. We hypothesize that memorization is driven by the overparameterization of deep models, suggesting that regularizing model capacity during fine-tuning could be an effective mitigation strategy. Parameter-efficient fine-tuning (PEFT) methods offer a promising approach to capacity control by selectively updating specific parameters. However, finding the optimal subset of learnable parameters that balances generation quality and memorization remains elusive. To address this challenge, we propose a bi-level optimization framework that guides automated parameter selection by utilizing memorization and generation quality metrics as rewards. Our framework successfully identifies the optimal parameter set to be updated to satisfy the generation-memorization tradeoff. We perform our experiments for the specific task of medical image generation and outperform existing state-of-the-art training-time mitigation strategies by fine-tuning as few as 0.019% of model parameters. Furthermore, we show that the strategies learned through our framework are transferable across different datasets and domains. Our proposed framework is scalable to large datasets and agnostic to the choice of reward functions. Finally, we show that our framework can be combined with existing approaches for further memorization mitigation.
FairTune: Optimizing Parameter Efficient Fine Tuning for Fairness in Medical Image Analysis
Oct 08, 2023Training models with robust group fairness properties is crucial in ethically sensitive application areas such as medical diagnosis. Despite the growing body of work aiming to minimise demographic bias in AI, this problem remains challenging. A key reason for this challenge is the fairness generalisation gap: High-capacity deep learning models can fit all training data nearly perfectly, and thus also exhibit perfect fairness during training. In this case, bias emerges only during testing when generalisation performance differs across subgroups. This motivates us to take a bi-level optimisation perspective on fair learning: Optimising the learning strategy based on validation fairness. Specifically, we consider the highly effective workflow of adapting pre-trained models to downstream medical imaging tasks using parameter-efficient fine-tuning (PEFT) techniques. There is a trade-off between updating more parameters, enabling a better fit to the task of interest vs. fewer parameters, potentially reducing the generalisation gap. To manage this tradeoff, we propose FairTune, a framework to optimise the choice of PEFT parameters with respect to fairness. We demonstrate empirically that FairTune leads to improved fairness on a range of medical imaging datasets.
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
May 24, 2023



We present a comprehensive evaluation of Parameter-Efficient Fine-Tuning (PEFT) techniques for diverse medical image analysis tasks. PEFT is increasingly exploited as a valuable approach for knowledge transfer from pre-trained models in natural language processing, vision, speech, and cross-modal tasks, such as vision-language and text-to-image generation. However, its application in medical image analysis remains relatively unexplored. As foundation models are increasingly exploited in the medical domain, it is crucial to investigate and comparatively assess various strategies for knowledge transfer that can bolster a range of downstream tasks. Our study, the first of its kind (to the best of our knowledge), evaluates 16 distinct PEFT methodologies proposed for convolutional and transformer-based networks, focusing on image classification and text-to-image generation tasks across six medical datasets ranging in size, modality, and complexity. Through a battery of more than 600 controlled experiments, we demonstrate performance gains of up to 22% under certain scenarios and demonstrate the efficacy of PEFT for medical text-to-image generation. Further, we reveal the instances where PEFT methods particularly dominate over conventional fine-tuning approaches by studying their relationship with downstream data volume.
The EMory BrEast imaging Dataset : A Racially Diverse, Granular Dataset of 3.5M Screening and Diagnostic Mammograms
Feb 08, 2022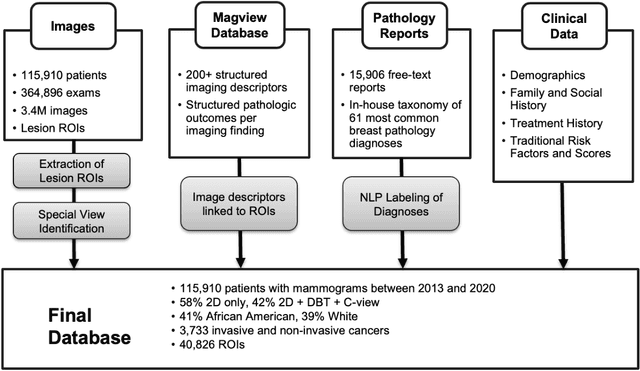
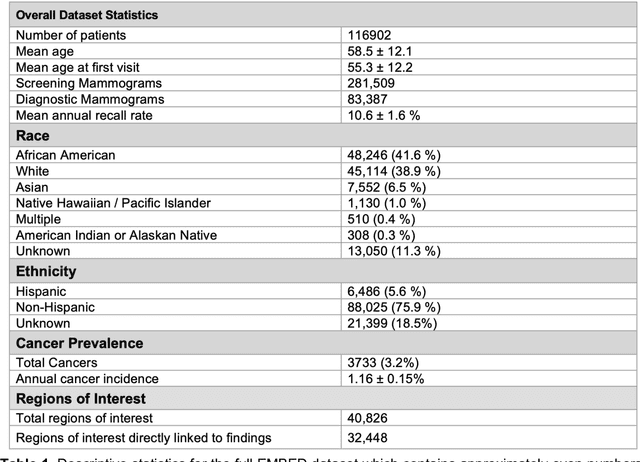
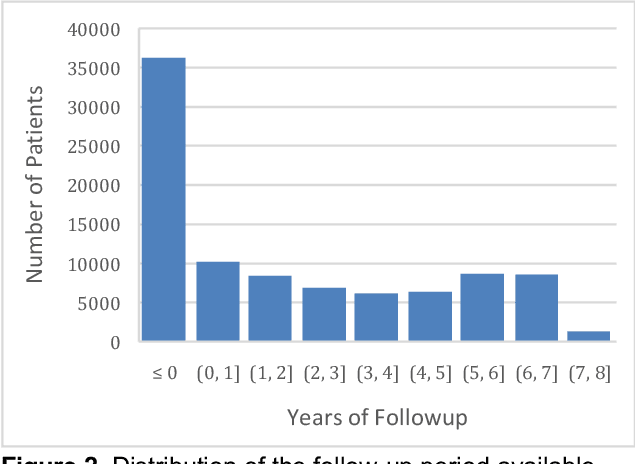

Developing and validating artificial intelligence models in medical imaging requires datasets that are large, granular, and diverse. To date, the majority of publicly available breast imaging datasets lack in one or more of these areas. Models trained on these data may therefore underperform on patient populations or pathologies that have not previously been encountered. The EMory BrEast imaging Dataset (EMBED) addresses these gaps by providing 3650,000 2D and DBT screening and diagnostic mammograms for 116,000 women divided equally between White and African American patients. The dataset also contains 40,000 annotated lesions linked to structured imaging descriptors and 61 ground truth pathologic outcomes grouped into six severity classes. Our goal is to share this dataset with research partners to aid in development and validation of breast AI models that will serve all patients fairly and help decrease bias in medical AI.