 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 23, 2023

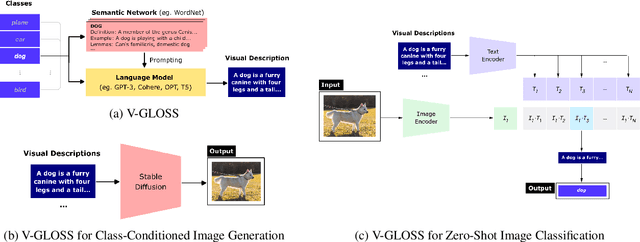

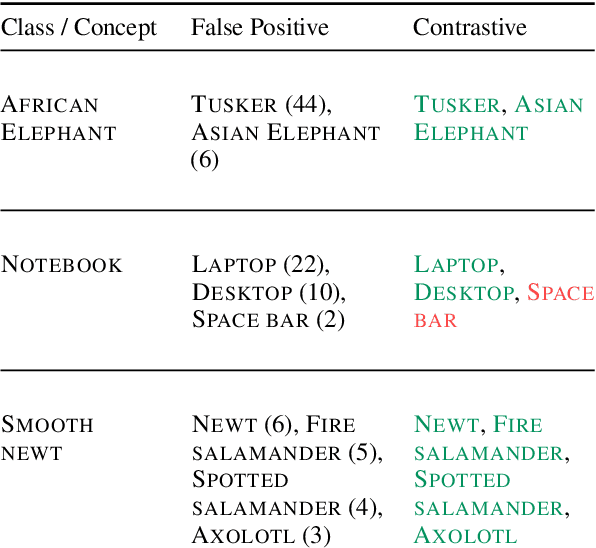
Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.
Guided Image Synthesis via Initial Image Editing in Diffusion Model
May 05, 2023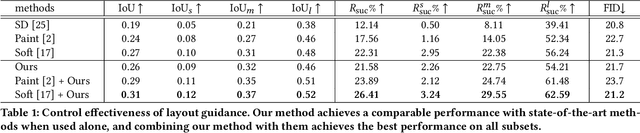

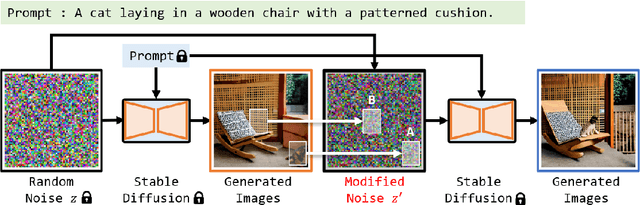

Diffusion models have the ability to generate high quality images by denoising pure Gaussian noise images. While previous research has primarily focused on improving the control of image generation through adjusting the denoising process, we propose a novel direction of manipulating the initial noise to control the generated image. Through experiments on stable diffusion, we show that blocks of pixels in the initial latent images have a preference for generating specific content, and that modifying these blocks can significantly influence the generated image. In particular, we show that modifying a part of the initial image affects the corresponding region of the generated image while leaving other regions unaffected, which is useful for repainting tasks. Furthermore, we find that the generation preferences of pixel blocks are primarily determined by their values, rather than their position. By moving pixel blocks with a tendency to generate user-desired content to user-specified regions, our approach achieves state-of-the-art performance in layout-to-image generation. Our results highlight the flexibility and power of initial image manipulation in controlling the generated image.
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023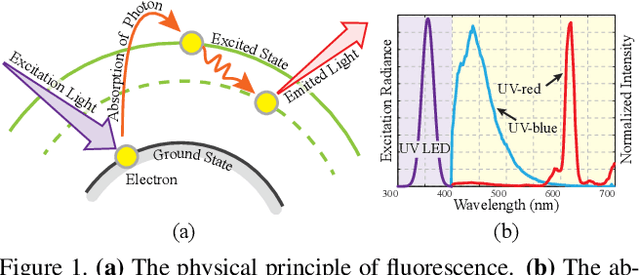

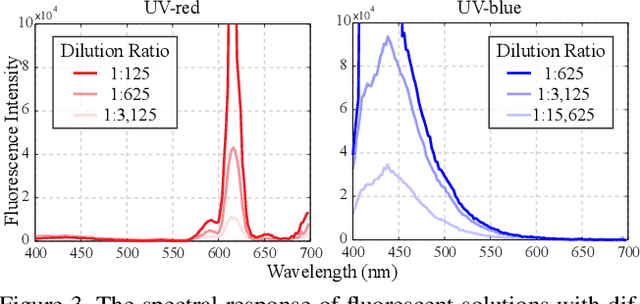
Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
Black-box Unsupervised Domain Adaptation with Bi-directional Atkinson-Shiffrin Memory
Aug 25, 2023Black-box unsupervised domain adaptation (UDA) learns with source predictions of target data without accessing either source data or source models during training, and it has clear superiority in data privacy and flexibility in target network selection. However, the source predictions of target data are often noisy and training with them is prone to learning collapses. We propose BiMem, a bi-directional memorization mechanism that learns to remember useful and representative information to correct noisy pseudo labels on the fly, leading to robust black-box UDA that can generalize across different visual recognition tasks. BiMem constructs three types of memory, including sensory memory, short-term memory, and long-term memory, which interact in a bi-directional manner for comprehensive and robust memorization of learnt features. It includes a forward memorization flow that identifies and stores useful features and a backward calibration flow that rectifies features' pseudo labels progressively. Extensive experiments show that BiMem achieves superior domain adaptation performance consistently across various visual recognition tasks such as image classification, semantic segmentation and object detection.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023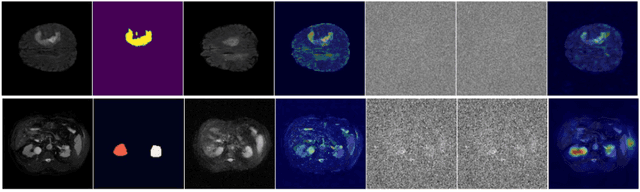
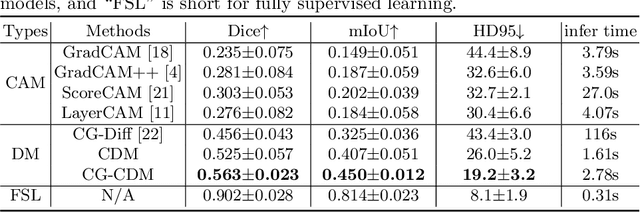
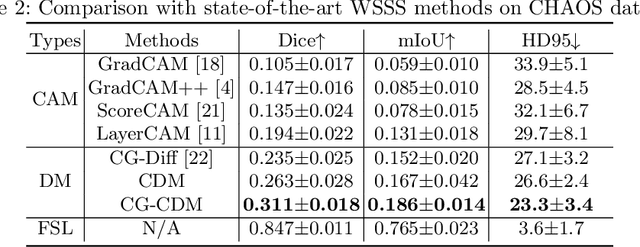

Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.
Green Steganalyzer: A Green Learning Approach to Image Steganalysis
Jun 06, 2023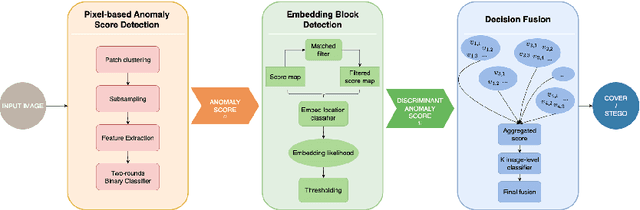
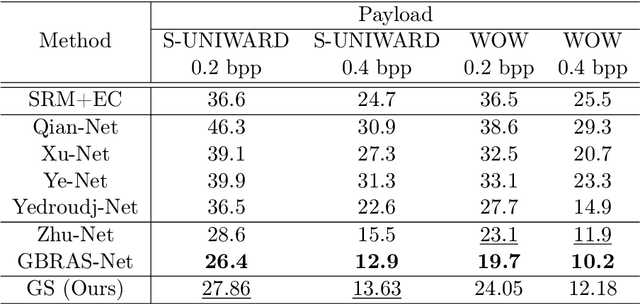
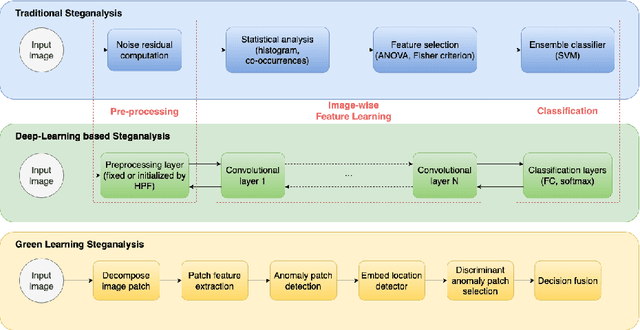
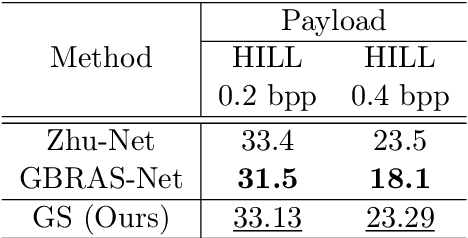
A novel learning solution to image steganalysis based on the green learning paradigm, called Green Steganalyzer (GS), is proposed in this work. GS consists of three modules: 1) pixel-based anomaly prediction, 2) embedding location detection, and 3) decision fusion for image-level detection. In the first module, GS decomposes an image into patches, adopts Saab transforms for feature extraction, and conducts self-supervised learning to predict an anomaly score of their center pixel. In the second module, GS analyzes the anomaly scores of a pixel and its neighborhood to find pixels of higher embedding probabilities. In the third module, GS focuses on pixels of higher embedding probabilities and fuses their anomaly scores to make final image-level classification. Compared with state-of-the-art deep-learning models, GS achieves comparable detection performance against S-UNIWARD, WOW and HILL steganography schemes with significantly lower computational complexity and a smaller model size, making it attractive for mobile/edge applications. Furthermore, GS is mathematically transparent because of its modular design.
Fixating on Attention: Integrating Human Eye Tracking into Vision Transformers
Aug 26, 2023

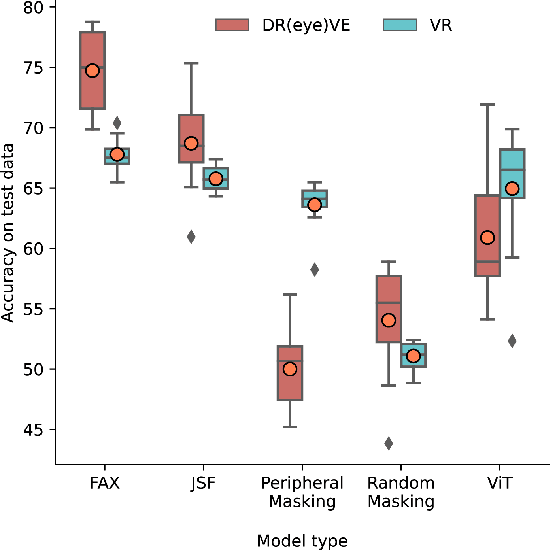
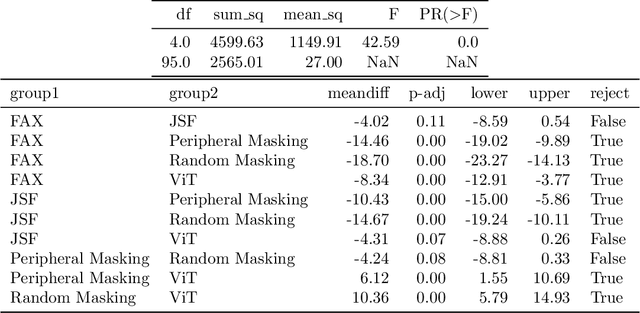
Modern transformer-based models designed for computer vision have outperformed humans across a spectrum of visual tasks. However, critical tasks, such as medical image interpretation or autonomous driving, still require reliance on human judgments. This work demonstrates how human visual input, specifically fixations collected from an eye-tracking device, can be integrated into transformer models to improve accuracy across multiple driving situations and datasets. First, we establish the significance of fixation regions in left-right driving decisions, as observed in both human subjects and a Vision Transformer (ViT). By comparing the similarity between human fixation maps and ViT attention weights, we reveal the dynamics of overlap across individual heads and layers. This overlap is exploited for model pruning without compromising accuracy. Thereafter, we incorporate information from the driving scene with fixation data, employing a "joint space-fixation" (JSF) attention setup. Lastly, we propose a "fixation-attention intersection" (FAX) loss to train the ViT model to attend to the same regions that humans fixated on. We find that the ViT performance is improved in accuracy and number of training epochs when using JSF and FAX. These results hold significant implications for human-guided artificial intelligence.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023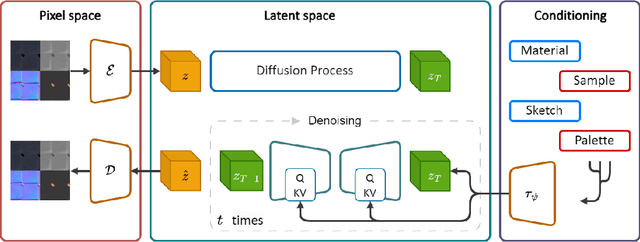
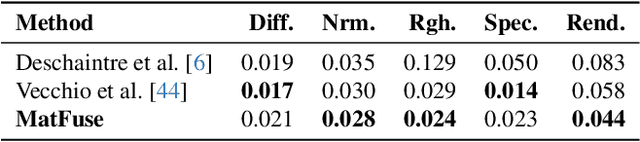
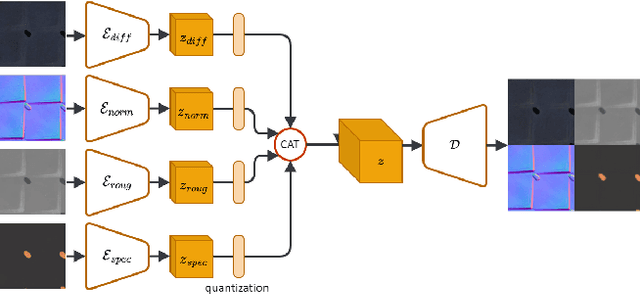
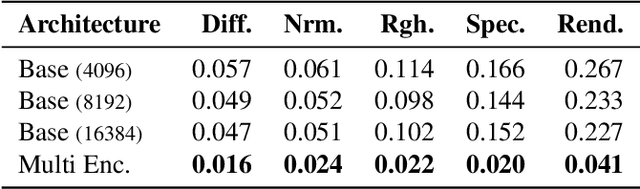
Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
Expert-Agnostic Ultrasound Image Quality Assessment using Deep Variational Clustering
Jul 05, 2023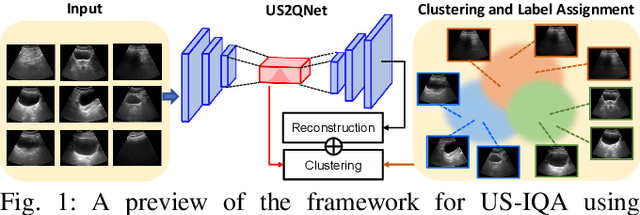
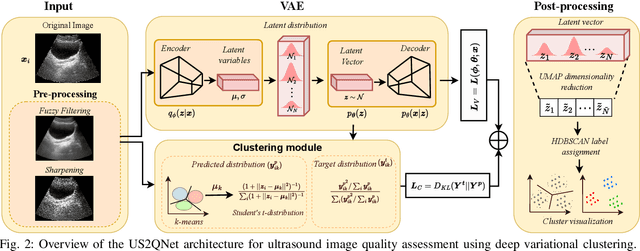
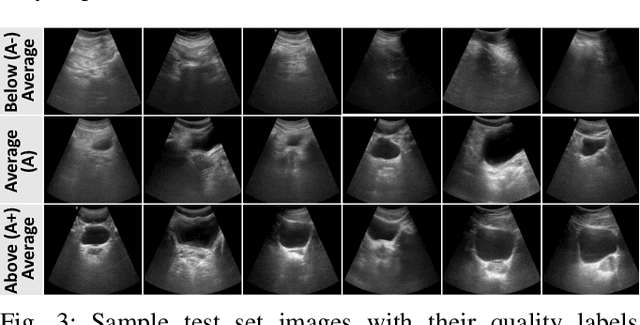
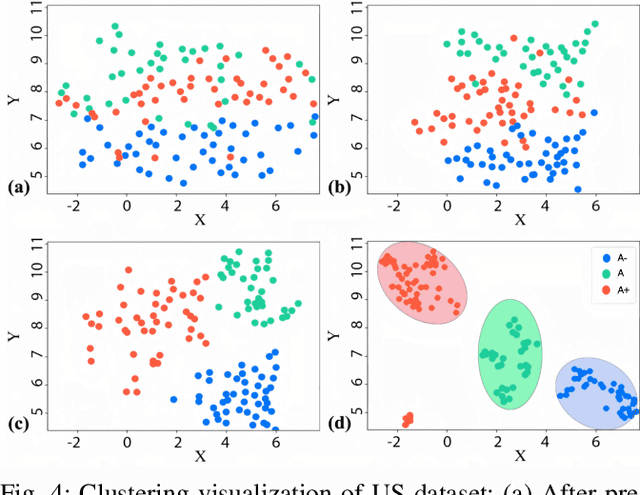
Ultrasound imaging is a commonly used modality for several diagnostic and therapeutic procedures. However, the diagnosis by ultrasound relies heavily on the quality of images assessed manually by sonographers, which diminishes the objectivity of the diagnosis and makes it operator-dependent. The supervised learning-based methods for automated quality assessment require manually annotated datasets, which are highly labour-intensive to acquire. These ultrasound images are low in quality and suffer from noisy annotations caused by inter-observer perceptual variations, which hampers learning efficiency. We propose an UnSupervised UltraSound image Quality assessment Network, US2QNet, that eliminates the burden and uncertainty of manual annotations. US2QNet uses the variational autoencoder embedded with the three modules, pre-processing, clustering and post-processing, to jointly enhance, extract, cluster and visualize the quality feature representation of ultrasound images. The pre-processing module uses filtering of images to point the network's attention towards salient quality features, rather than getting distracted by noise. Post-processing is proposed for visualizing the clusters of feature representations in 2D space. We validated the proposed framework for quality assessment of the urinary bladder ultrasound images. The proposed framework achieved 78% accuracy and superior performance to state-of-the-art clustering methods.
* Accepted in IEEE International Conference on Robotics and Automation (ICRA) 2023
Inter-Rater Uncertainty Quantification in Medical Image Segmentation via Rater-Specific Bayesian Neural Networks
Jun 28, 2023
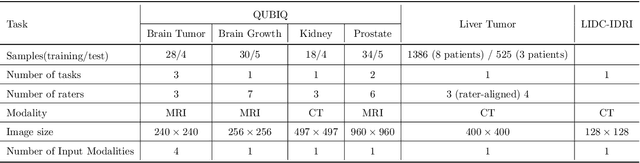
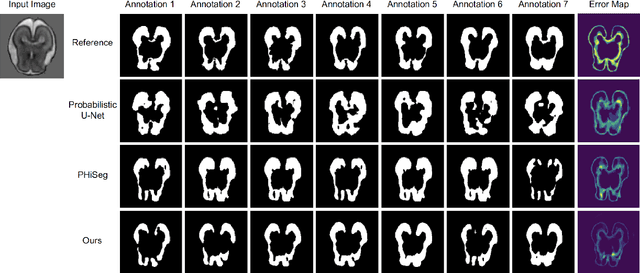

Automated medical image segmentation inherently involves a certain degree of uncertainty. One key factor contributing to this uncertainty is the ambiguity that can arise in determining the boundaries of a target region of interest, primarily due to variations in image appearance. On top of this, even among experts in the field, different opinions can emerge regarding the precise definition of specific anatomical structures. This work specifically addresses the modeling of segmentation uncertainty, known as inter-rater uncertainty. Its primary objective is to explore and analyze the variability in segmentation outcomes that can occur when multiple experts in medical imaging interpret and annotate the same images. We introduce a novel Bayesian neural network-based architecture to estimate inter-rater uncertainty in medical image segmentation. Our approach has three key advancements. Firstly, we introduce a one-encoder-multi-decoder architecture specifically tailored for uncertainty estimation, enabling us to capture the rater-specific representation of each expert involved. Secondly, we propose Bayesian modeling for the new architecture, allowing efficient capture of the inter-rater distribution, particularly in scenarios with limited annotations. Lastly, we enhance the rater-specific representation by integrating an attention module into each decoder. This module facilitates focused and refined segmentation results for each rater. We conduct extensive evaluations using synthetic and real-world datasets to validate our technical innovations rigorously. Our method surpasses existing baseline methods in five out of seven diverse tasks on the publicly available \emph{QUBIQ} dataset, considering two evaluation metrics encompassing different uncertainty aspects. Our codes, models, and the new dataset are available through our GitHub repository: https://github.com/HaoWang420/bOEMD-net .