 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixating on Attention: Integrating Human Eye Tracking into Vision Transformers
Aug 26, 2023



Modern transformer-based models designed for computer vision have outperformed humans across a spectrum of visual tasks. However, critical tasks, such as medical image interpretation or autonomous driving, still require reliance on human judgments. This work demonstrates how human visual input, specifically fixations collected from an eye-tracking device, can be integrated into transformer models to improve accuracy across multiple driving situations and datasets. First, we establish the significance of fixation regions in left-right driving decisions, as observed in both human subjects and a Vision Transformer (ViT). By comparing the similarity between human fixation maps and ViT attention weights, we reveal the dynamics of overlap across individual heads and layers. This overlap is exploited for model pruning without compromising accuracy. Thereafter, we incorporate information from the driving scene with fixation data, employing a "joint space-fixation" (JSF) attention setup. Lastly, we propose a "fixation-attention intersection" (FAX) loss to train the ViT model to attend to the same regions that humans fixated on. We find that the ViT performance is improved in accuracy and number of training epochs when using JSF and FAX. These results hold significant implications for human-guided artificial intelligence.
Bayesian Beta-Bernoulli Process Sparse Coding with Deep Neural Networks
Mar 14, 2023

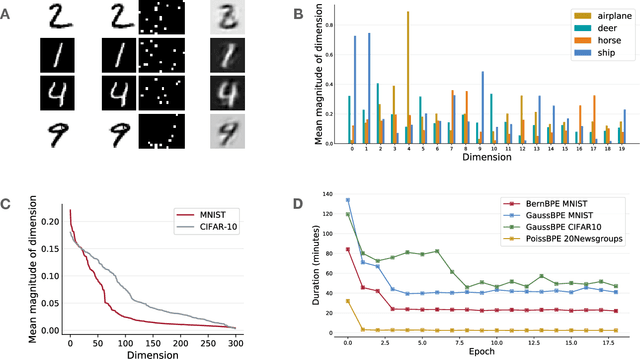

Several approximate inference methods have been proposed for deep discrete latent variable models. However, non-parametric methods which have previously been successfully employed for classical sparse coding models have largely been unexplored in the context of deep models. We propose a non-parametric iterative algorithm for learning discrete latent representations in such deep models. Additionally, to learn scale invariant discrete features, we propose local data scaling variables. Lastly, to encourage sparsity in our representations, we propose a Beta-Bernoulli process prior on the latent factors. We evaluate our spare coding model coupled with different likelihood models. We evaluate our method across datasets with varying characteristics and compare our results to current amortized approximate inference methods.
Improving Prediction of Cognitive Performance using Deep Neural Networks in Sparse Data
Dec 28, 2021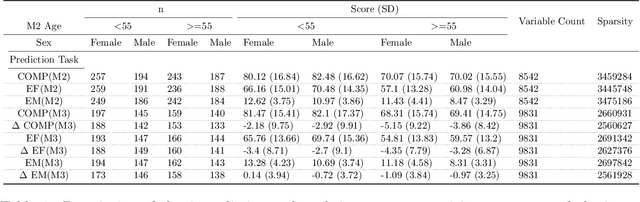
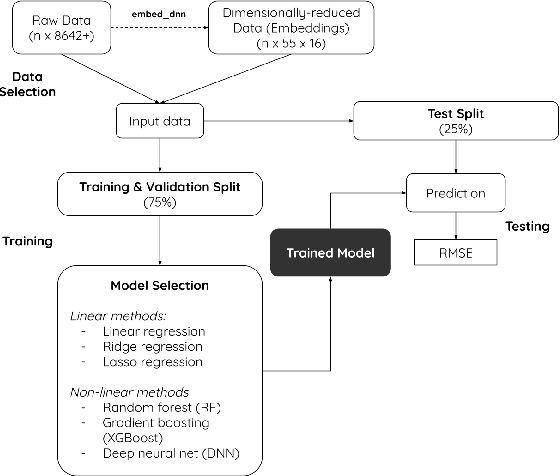
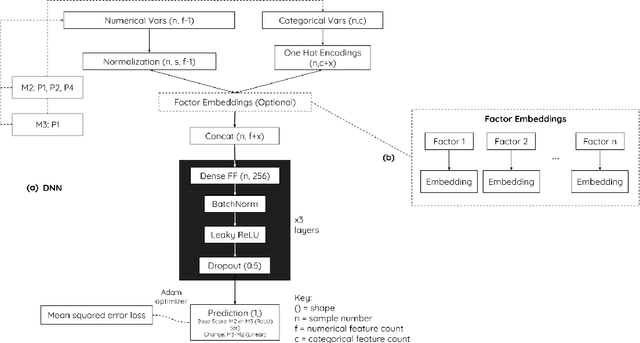
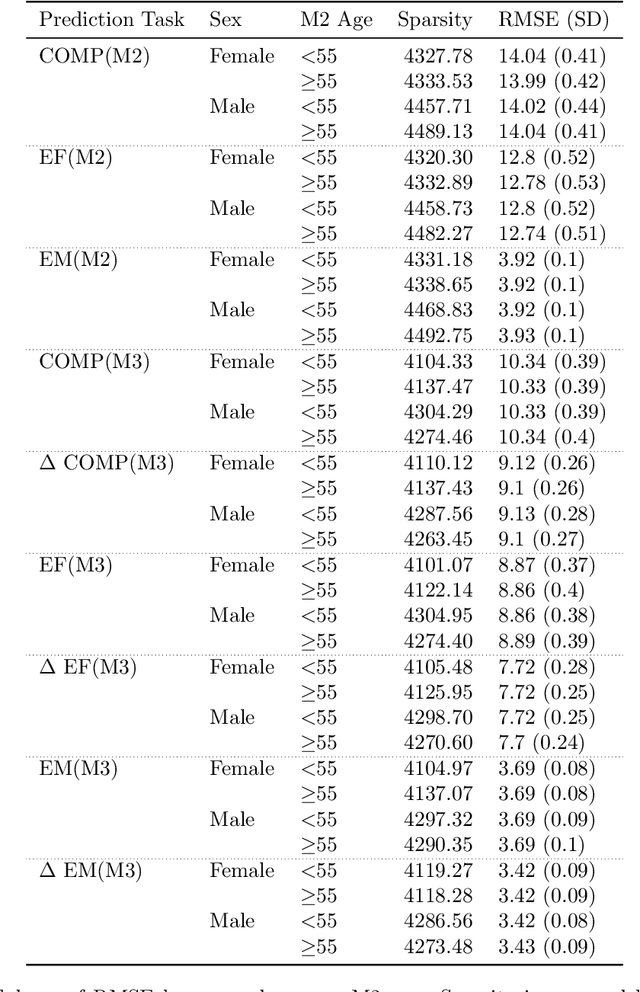
Cognition in midlife is an important predictor of age-related mental decline and statistical models that predict cognitive performance can be useful for predicting decline. However, existing models struggle to capture complex relationships between physical, sociodemographic, psychological and mental health factors that effect cognition. Using data from an observational, cohort study, Midlife in the United States (MIDUS), we modeled a large number of variables to predict executive function and episodic memory measures. We used cross-sectional and longitudinal outcomes with varying sparsity, or amount of missing data. Deep neural network (DNN) models consistently ranked highest in all of the cognitive performance prediction tasks, as assessed with root mean squared error (RMSE) on out-of-sample data. RMSE differences between DNN and other model types were statistically significant (T(8) = -3.70; p < 0.05). The interaction effect between model type and sparsity was significant (F(9)=59.20; p < 0.01), indicating the success of DNNs can partly be attributed to their robustness and ability to model hierarchical relationships between health-related factors. Our findings underscore the potential of neural networks to model clinical datasets and allow better understanding of factors that lead to cognitive decline.
Bayesian recurrent state space model for rs-fMRI
Nov 14, 2020
We propose a hierarchical Bayesian recurrent state space model for modeling switching network connectivity in resting state fMRI data. Our model allows us to uncover shared network patterns across disease conditions. We evaluate our method on the ADNI2 dataset by inferring latent state patterns corresponding to altered neural circuits in individuals with Mild Cognitive Impairment (MCI). In addition to states shared across healthy and individuals with MCI, we discover latent states that are predominantly observed in individuals with MCI. Our model outperforms current state of the art deep learning method on ADNI2 dataset.
Deep Bayesian Nonparametric Factor Analysis
Nov 09, 2020

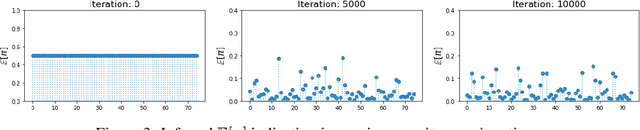
We propose a deep generative factor analysis model with beta process prior that can approximate complex non-factorial distributions over the latent codes. We outline a stochastic EM algorithm for scalable inference in a specific instantiation of this model and present some preliminary results.