 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeΦeat: Physically-Grounded Feature Representation
Nov 14, 2025Foundation models have emerged as effective backbones for many vision tasks. However, current self-supervised features entangle high-level semantics with low-level physical factors, such as geometry and illumination, hindering their use in tasks requiring explicit physical reasoning. In this paper, we introduce $Φ$eat, a novel physically-grounded visual backbone that encourages a representation sensitive to material identity, including reflectance cues and geometric mesostructure. Our key idea is to employ a pretraining strategy that contrasts spatial crops and physical augmentations of the same material under varying shapes and lighting conditions. While similar data have been used in high-end supervised tasks such as intrinsic decomposition or material estimation, we demonstrate that a pure self-supervised training strategy, without explicit labels, already provides a strong prior for tasks requiring robust features invariant to external physical factors. We evaluate the learned representations through feature similarity analysis and material selection, showing that $Φ$eat captures physically-grounded structure beyond semantic grouping. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics.
Structured Pattern Expansion with Diffusion Models
Nov 12, 2024



Recent advances in diffusion models have significantly improved the synthesis of materials, textures, and 3D shapes. By conditioning these models via text or images, users can guide the generation, reducing the time required to create digital assets. In this paper, we address the synthesis of structured, stationary patterns, where diffusion models are generally less reliable and, more importantly, less controllable. Our approach leverages the generative capabilities of diffusion models specifically adapted for the pattern domain. It enables users to exercise direct control over the synthesis by expanding a partially hand-drawn pattern into a larger design while preserving the structure and details of the input. To enhance pattern quality, we fine-tune an image-pretrained diffusion model on structured patterns using Low-Rank Adaptation (LoRA), apply a noise rolling technique to ensure tileability, and utilize a patch-based approach to facilitate the generation of large-scale assets. We demonstrate the effectiveness of our method through a comprehensive set of experiments, showing that it outperforms existing models in generating diverse, consistent patterns that respond directly to user input.
StableMaterials: Enhancing Diversity in Material Generation via Semi-Supervised Learning
Jun 13, 2024



We introduce StableMaterials, a novel approach for generating photorealistic physical-based rendering (PBR) materials that integrate semi-supervised learning with Latent Diffusion Models (LDMs). Our method employs adversarial training to distill knowledge from existing large-scale image generation models, minimizing the reliance on annotated data and enhancing the diversity in generation. This distillation approach aligns the distribution of the generated materials with that of image textures from an SDXL model, enabling the generation of novel materials that are not present in the initial training dataset. Furthermore, we employ a diffusion-based refiner model to improve the visual quality of the samples and achieve high-resolution generation. Finally, we distill a latent consistency model for fast generation in just four steps and propose a new tileability technique that removes visual artifacts typically associated with fewer diffusion steps. We detail the architecture and training process of StableMaterials, the integration of semi-supervised training within existing LDM frameworks and show the advantages of our approach. Comparative evaluations with state-of-the-art methods show the effectiveness of StableMaterials, highlighting its potential applications in computer graphics and beyond. StableMaterials is publicly available at https://gvecchio.com/stablematerials.
MatSynth: A Modern PBR Materials Dataset
Jan 11, 2024We introduce MatSynth, a dataset of $4,000+$ CC0 ultra-high resolution PBR materials. Materials are crucial components of virtual relightable assets, defining the interaction of light at the surface of geometries. Given their importance, significant research effort was dedicated to their representation, creation and acquisition. However, in the past 6 years, most research in material acquisiton or generation relied either on the same unique dataset, or on company-owned huge library of procedural materials. With this dataset we propose a significantly larger, more diverse, and higher resolution set of materials than previously publicly available. We carefully discuss the data collection process and demonstrate the benefits of this dataset on material acquisition and generation applications. The complete data further contains metadata with each material's origin, license, category, tags, creation method and, when available, descriptions and physical size, as well as 3M+ renderings of the augmented materials, in 1K, under various environment lightings. The MatSynth dataset is released through the project page at: https://www.gvecchio.com/matsynth.
ControlMat: A Controlled Generative Approach to Material Capture
Sep 04, 2023



Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits exploration of a variety of materials which could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices. Supplemental materials and additional details are available at: https://gvecchio.com/controlmat/.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
MeT: A Graph Transformer for Semantic Segmentation of 3D Meshes
Jul 03, 2023



Polygonal meshes have become the standard for discretely approximating 3D shapes, thanks to their efficiency and high flexibility in capturing non-uniform shapes. This non-uniformity, however, leads to irregularity in the mesh structure, making tasks like segmentation of 3D meshes particularly challenging. Semantic segmentation of 3D mesh has been typically addressed through CNN-based approaches, leading to good accuracy. Recently, transformers have gained enough momentum both in NLP and computer vision fields, achieving performance at least on par with CNN models, supporting the long-sought architecture universalism. Following this trend, we propose a transformer-based method for semantic segmentation of 3D mesh motivated by a better modeling of the graph structure of meshes, by means of global attention mechanisms. In order to address the limitations of standard transformer architectures in modeling relative positions of non-sequential data, as in the case of 3D meshes, as well as in capturing the local context, we perform positional encoding by means the Laplacian eigenvectors of the adjacency matrix, replacing the traditional sinusoidal positional encodings, and by introducing clustering-based features into the self-attention and cross-attention operators. Experimental results, carried out on three sets of the Shape COSEG Dataset, on the human segmentation dataset proposed in Maron et al., 2017 and on the ShapeNet benchmark, show how the proposed approach yields state-of-the-art performance on semantic segmentation of 3D meshes.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
MIDGARD: A Simulation Platform for Autonomous Navigation in Unstructured Environments
May 17, 2022

We present MIDGARD, an open source simulation platform for autonomous robot navigation in unstructured outdoor environments. We specifically design MIDGARD to enable training of autonomous agents (e.g., unmanned ground vehicles) in photorealistic 3D environments, and to support the generalization skills of learning-based agents by means of diverse and variable training scenarios. MIDGARD differs from other major simulation platforms in that it proposes a highly configurable procedural landscape generation pipeline, which enables autonomous agents to be trained in diverse scenarios while reducing the efforts and costs needed to create digital content from scratch.
SurfaceNet: Adversarial SVBRDF Estimation from a Single Image
Jul 23, 2021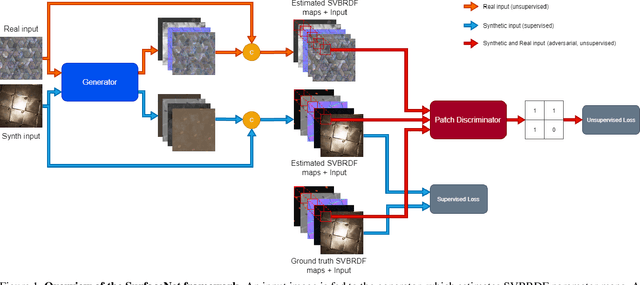
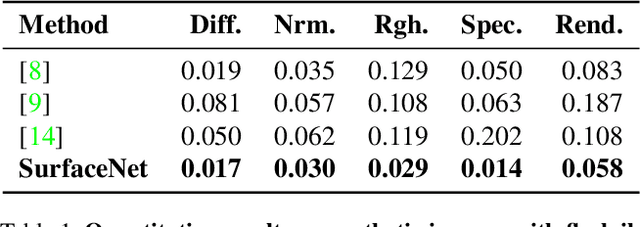
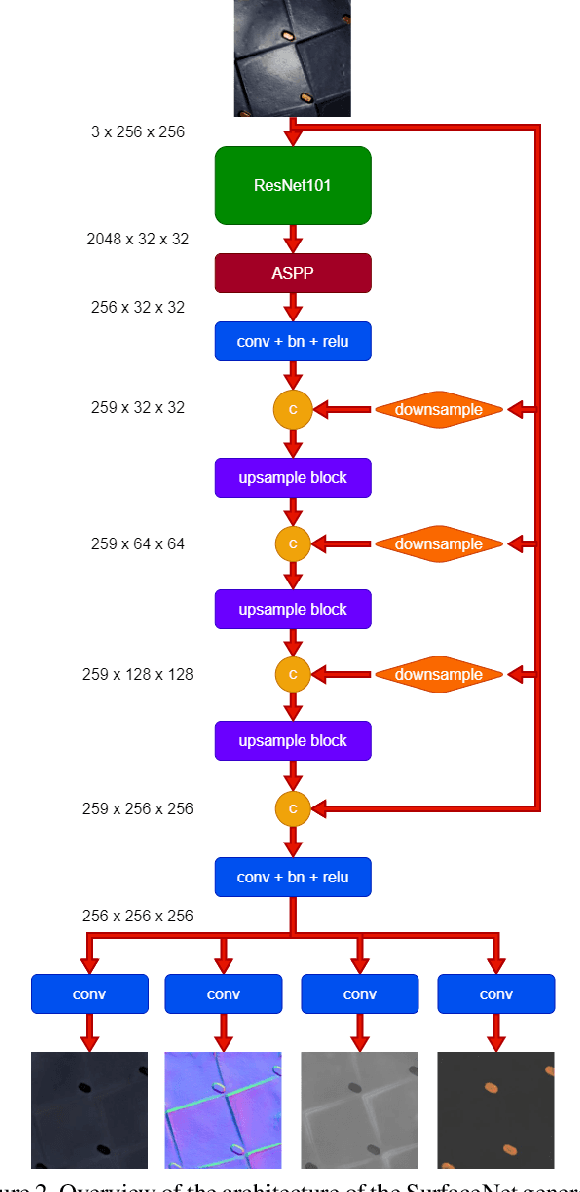
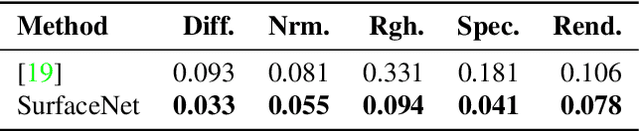
In this paper we present SurfaceNet, an approach for estimating spatially-varying bidirectional reflectance distribution function (SVBRDF) material properties from a single image. We pose the problem as an image translation task and propose a novel patch-based generative adversarial network (GAN) that is able to produce high-quality, high-resolution surface reflectance maps. The employment of the GAN paradigm has a twofold objective: 1) allowing the model to recover finer details than standard translation models; 2) reducing the domain shift between synthetic and real data distributions in an unsupervised way. An extensive evaluation, carried out on a public benchmark of synthetic and real images under different illumination conditions, shows that SurfaceNet largely outperforms existing SVBRDF reconstruction methods, both quantitatively and qualitatively. Furthermore, SurfaceNet exhibits a remarkable ability in generating high-quality maps from real samples without any supervision at training time.