 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze patterns predict preference and confidence in pairwise AI image evaluation
Mar 25, 2026Preference learning methods, such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), rely on pairwise human judgments, yet little is known about the cognitive processes underlying these judgments. We investigate whether eye-tracking can reveal preference formation during pairwise AI-generated image evaluation. Thirty participants completed 1,800 trials while their gaze was recorded. We replicated the gaze cascade effect, with gaze shifting toward chosen images approximately one second before the decision. Cascade dynamics were consistent across confidence levels. Gaze features predicted binary choice (68% accuracy), with chosen images receiving more dwell time, fixations, and revisits. Gaze transitions distinguished high-confidence from uncertain decisions (66% accuracy), with low-confidence trials showing more image switches per second. These results show that gaze patterns predict both choice and confidence in pairwise image evaluations, suggesting that eye-tracking provides implicit signals relevant to the quality of preference annotations.
Hide and Seek: Investigating Redundancy in Earth Observation Imagery
Mar 13, 2026The growing availability of Earth Observation (EO) data and recent advances in Computer Vision have driven rapid progress in machine learning for EO, producing domain-specific models at ever-increasing scales. Yet this progress risks overlooking fundamental properties of EO data that distinguish it from other domains. We argue that EO data exhibit a multidimensional redundancy (spectral, temporal, spatial, and semantic) which has a more pronounced impact on the domain and its applications than what current literature reflects. To validate this hypothesis, we conduct a systematic domain-specific investigation examining the existence, consistency, and practical implications of this phenomenon across key dimensions of EO variability. Our findings confirm that redundancy in EO data is both substantial and pervasive: exploiting it yields comparable performance ($\approx98.5\%$ of baseline) at a fraction of the computational cost ($\approx4\times$ fewer GFLOPs), at both training and inference. Crucially, these gains are consistent across tasks, geospatial locations, sensors, ground sampling distances, and architectural designs; suggesting that multi-faceted redundancy is a structural property of EO data rather than an artifact of specific experimental choices. These results lay the groundwork for more efficient, scalable, and accessible large-scale EO models.
Hephaestus Minicubes: A Global, Multi-Modal Dataset for Volcanic Unrest Monitoring
May 23, 2025



Ground deformation is regarded in volcanology as a key precursor signal preceding volcanic eruptions. Satellite-based Interferometric Synthetic Aperture Radar (InSAR) enables consistent, global-scale deformation tracking; however, deep learning methods remain largely unexplored in this domain, mainly due to the lack of a curated machine learning dataset. In this work, we build on the existing Hephaestus dataset, and introduce Hephaestus Minicubes, a global collection of 38 spatiotemporal datacubes offering high resolution, multi-source and multi-temporal information, covering 44 of the world's most active volcanoes over a 7-year period. Each spatiotemporal datacube integrates InSAR products, topographic data, as well as atmospheric variables which are known to introduce signal delays that can mimic ground deformation in InSAR imagery. Furthermore, we provide expert annotations detailing the type, intensity and spatial extent of deformation events, along with rich text descriptions of the observed scenes. Finally, we present a comprehensive benchmark, demonstrating Hephaestus Minicubes' ability to support volcanic unrest monitoring as a multi-modal, multi-temporal classification and semantic segmentation task, establishing strong baselines with state-of-the-art architectures. This work aims to advance machine learning research in volcanic monitoring, contributing to the growing integration of data-driven methods within Earth science applications.
Fixating on Attention: Integrating Human Eye Tracking into Vision Transformers
Aug 26, 2023



Modern transformer-based models designed for computer vision have outperformed humans across a spectrum of visual tasks. However, critical tasks, such as medical image interpretation or autonomous driving, still require reliance on human judgments. This work demonstrates how human visual input, specifically fixations collected from an eye-tracking device, can be integrated into transformer models to improve accuracy across multiple driving situations and datasets. First, we establish the significance of fixation regions in left-right driving decisions, as observed in both human subjects and a Vision Transformer (ViT). By comparing the similarity between human fixation maps and ViT attention weights, we reveal the dynamics of overlap across individual heads and layers. This overlap is exploited for model pruning without compromising accuracy. Thereafter, we incorporate information from the driving scene with fixation data, employing a "joint space-fixation" (JSF) attention setup. Lastly, we propose a "fixation-attention intersection" (FAX) loss to train the ViT model to attend to the same regions that humans fixated on. We find that the ViT performance is improved in accuracy and number of training epochs when using JSF and FAX. These results hold significant implications for human-guided artificial intelligence.
Machine Learning Method for Functional Assessment of Retinal Models
Feb 05, 2022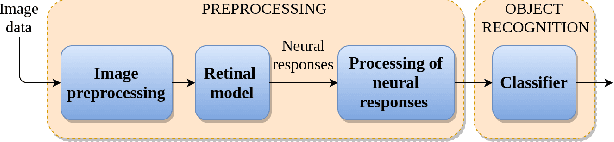

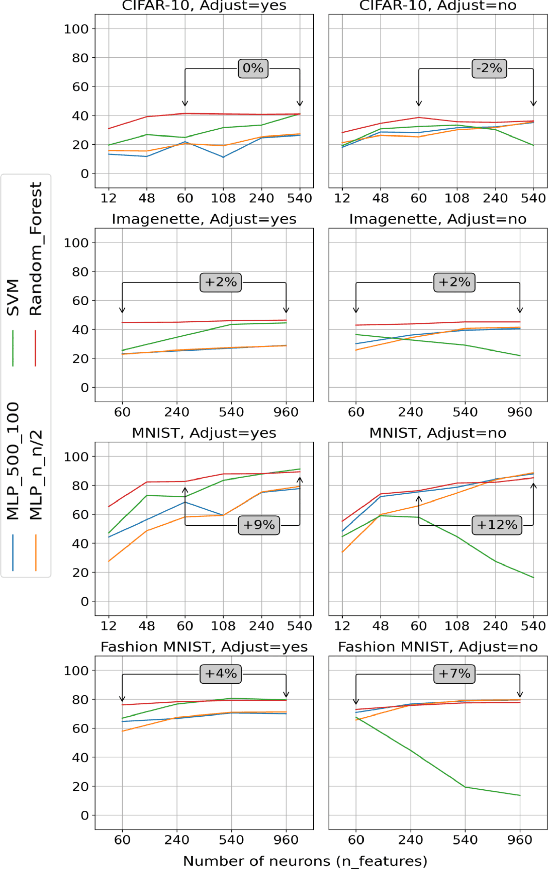
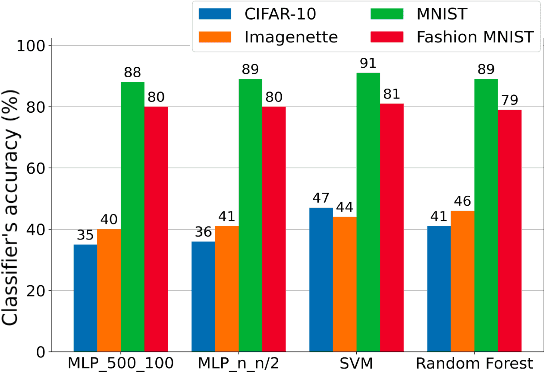
Challenges in the field of retinal prostheses motivate the development of retinal models to accurately simulate Retinal Ganglion Cells (RGCs) responses. The goal of retinal prostheses is to enable blind individuals to solve complex, reallife visual tasks. In this paper, we introduce the functional assessment (FA) of retinal models, which describes the concept of evaluating the performance of retinal models on visual understanding tasks. We present a machine learning method for FA: we feed traditional machine learning classifiers with RGC responses generated by retinal models, to solve object and digit recognition tasks (CIFAR-10, MNIST, Fashion MNIST, Imagenette). We examined critical FA aspects, including how the performance of FA depends on the task, how to optimally feed RGC responses to the classifiers and how the number of output neurons correlates with the model's accuracy. To increase the number of output neurons, we manipulated input images - by splitting and then feeding them to the retinal model and we found that image splitting does not significantly improve the model's accuracy. We also show that differences in the structure of datasets result in largely divergent performance of the retinal model (MNIST and Fashion MNIST exceeded 80% accuracy, while CIFAR-10 and Imagenette achieved ~40%). Furthermore, retinal models which perform better in standard evaluation, i.e. more accurately predict RGC response, perform better in FA as well. However, unlike standard evaluation, FA results can be straightforwardly interpreted in the context of comparing the quality of visual perception.