 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
pNNCLR: Stochastic Pseudo Neighborhoods for Contrastive Learning based Unsupervised Representation Learning Problems
Aug 14, 2023
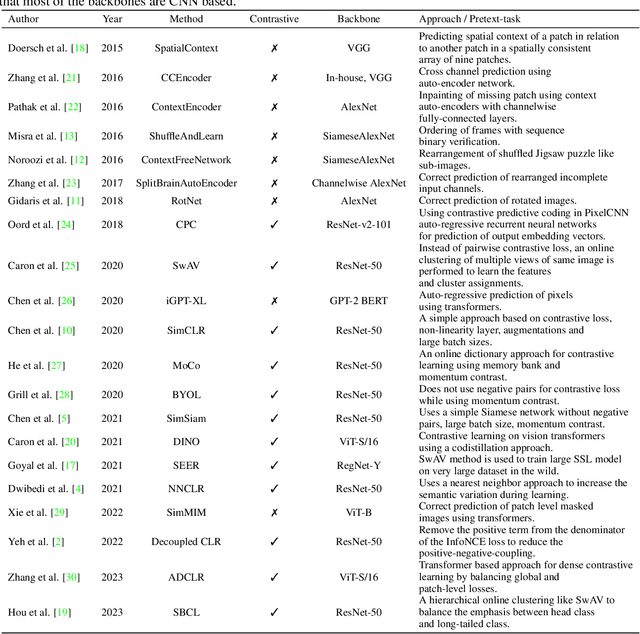
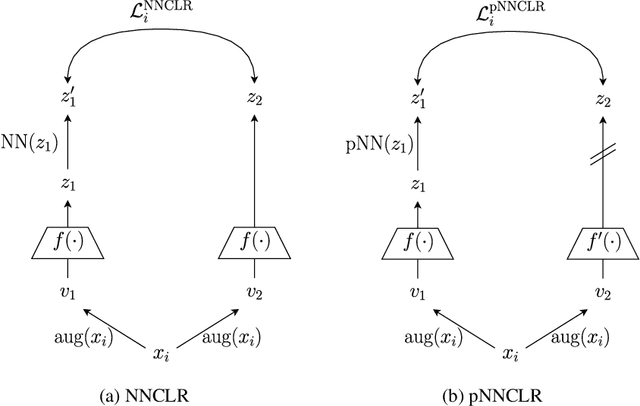
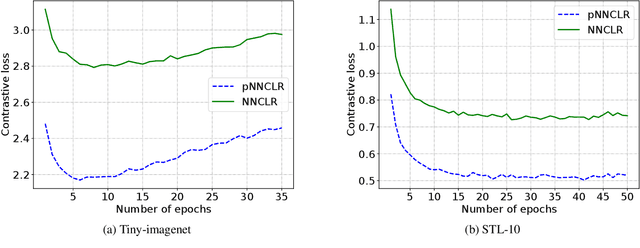
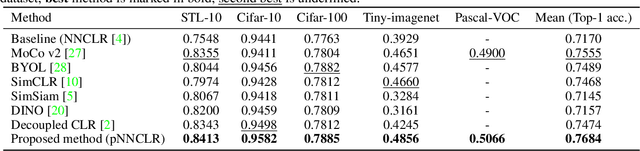
Nearest neighbor (NN) sampling provides more semantic variations than pre-defined transformations for self-supervised learning (SSL) based image recognition problems. However, its performance is restricted by the quality of the support set, which holds positive samples for the contrastive loss. In this work, we show that the quality of the support set plays a crucial role in any nearest neighbor based method for SSL. We then provide a refined baseline (pNNCLR) to the nearest neighbor based SSL approach (NNCLR). To this end, we introduce pseudo nearest neighbors (pNN) to control the quality of the support set, wherein, rather than sampling the nearest neighbors, we sample in the vicinity of hard nearest neighbors by varying the magnitude of the resultant vector and employing a stochastic sampling strategy to improve the performance. Additionally, to stabilize the effects of uncertainty in NN-based learning, we employ a smooth-weight-update approach for training the proposed network. Evaluation of the proposed method on multiple public image recognition and medical image recognition datasets shows that it performs up to 8 percent better than the baseline nearest neighbor method, and is comparable to other previously proposed SSL methods.
2D3D-MATR: 2D-3D Matching Transformer for Detection-free Registration between Images and Point Clouds
Aug 14, 2023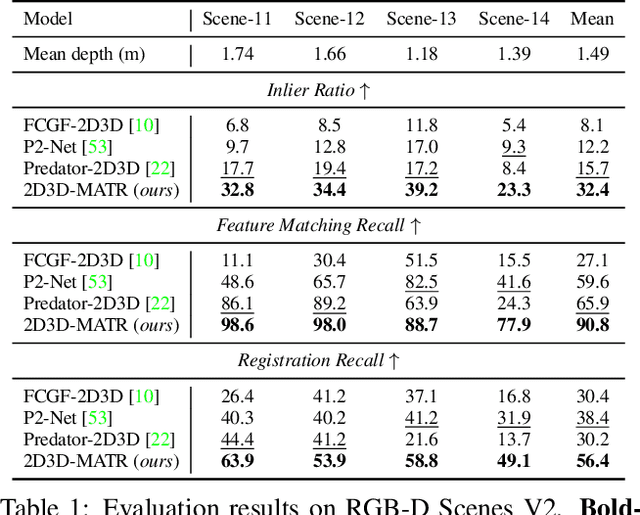
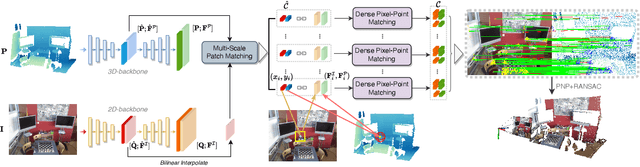
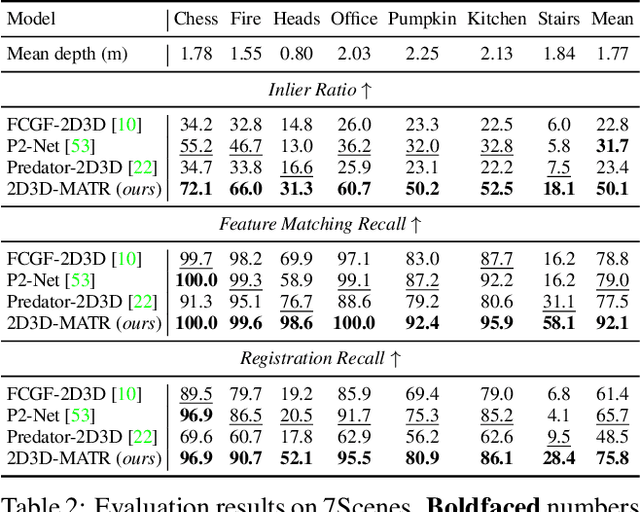
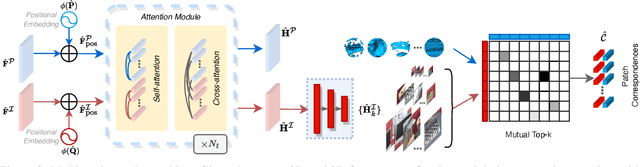
The commonly adopted detect-then-match approach to registration finds difficulties in the cross-modality cases due to the incompatible keypoint detection and inconsistent feature description. We propose, 2D3D-MATR, a detection-free method for accurate and robust registration between images and point clouds. Our method adopts a coarse-to-fine pipeline where it first computes coarse correspondences between downsampled patches of the input image and the point cloud and then extends them to form dense correspondences between pixels and points within the patch region. The coarse-level patch matching is based on transformer which jointly learns global contextual constraints with self-attention and cross-modality correlations with cross-attention. To resolve the scale ambiguity in patch matching, we construct a multi-scale pyramid for each image patch and learn to find for each point patch the best matching image patch at a proper resolution level. Extensive experiments on two public benchmarks demonstrate that 2D3D-MATR outperforms the previous state-of-the-art P2-Net by around $20$ percentage points on inlier ratio and over $10$ points on registration recall. Our code and models are available at https://github.com/minhaolee/2D3DMATR.
VQA Therapy: Exploring Answer Differences by Visually Grounding Answers
Aug 24, 2023



Visual question answering is a task of predicting the answer to a question about an image. Given that different people can provide different answers to a visual question, we aim to better understand why with answer groundings. We introduce the first dataset that visually grounds each unique answer to each visual question, which we call VQAAnswerTherapy. We then propose two novel problems of predicting whether a visual question has a single answer grounding and localizing all answer groundings. We benchmark modern algorithms for these novel problems to show where they succeed and struggle. The dataset and evaluation server can be found publicly at https://vizwiz.org/tasks-and-datasets/vqa-answer-therapy/.
Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities
Aug 24, 2023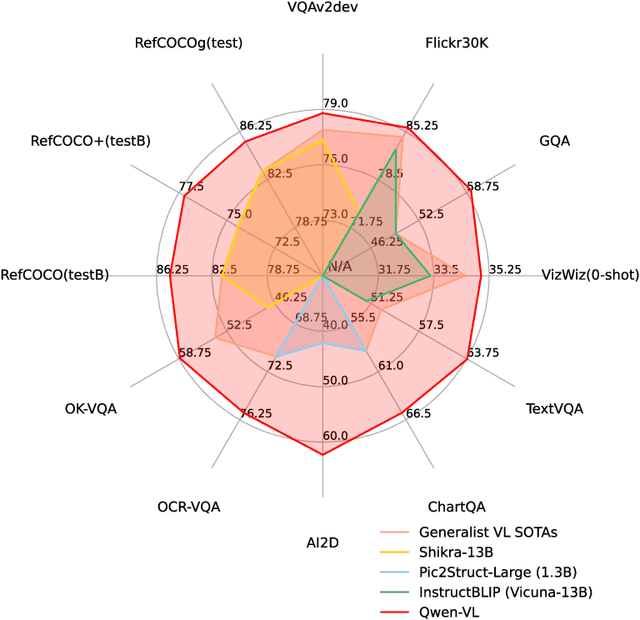

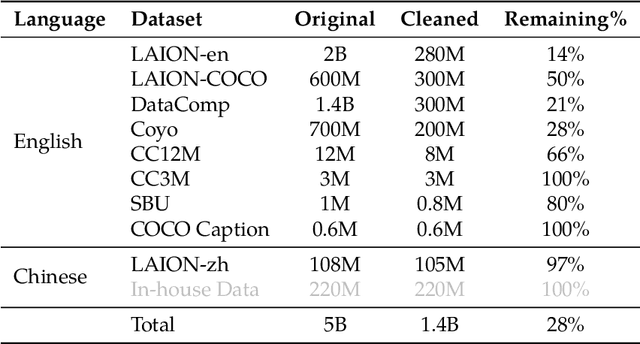
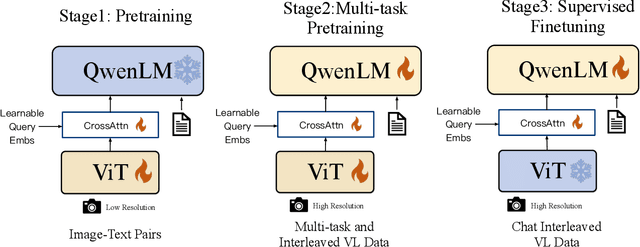
We introduce the Qwen-VL series, a set of large-scale vision-language models designed to perceive and understand both text and images. Comprising Qwen-VL and Qwen-VL-Chat, these models exhibit remarkable performance in tasks like image captioning, question answering, visual localization, and flexible interaction. The evaluation covers a wide range of tasks including zero-shot captioning, visual or document visual question answering, and grounding. We demonstrate the Qwen-VL outperforms existing Large Vision Language Models (LVLMs). We present their architecture, training, capabilities, and performance, highlighting their contributions to advancing multimodal artificial intelligence. Code, demo and models are available at https://github.com/QwenLM/Qwen-VL.
Regular SE(3) Group Convolutions for Volumetric Medical Image Analysis
Jun 24, 2023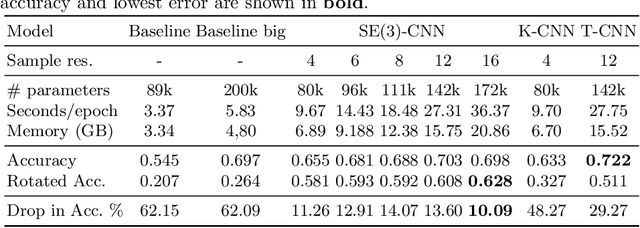
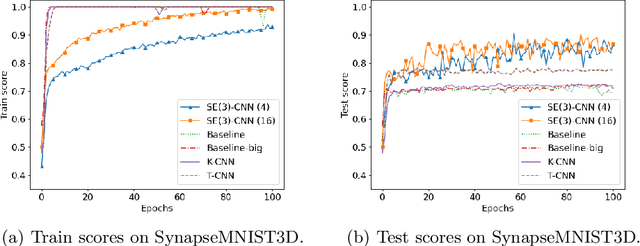
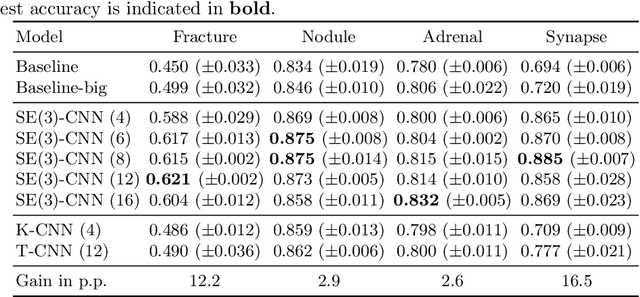
Regular group convolutional neural networks (G-CNNs) have been shown to increase model performance and improve equivariance to different geometrical symmetries. This work addresses the problem of SE(3), i.e., roto-translation equivariance, on volumetric data. Volumetric image data is prevalent in many medical settings. Motivated by the recent work on separable group convolutions, we devise a SE(3) group convolution kernel separated into a continuous SO(3) (rotation) kernel and a spatial kernel. We approximate equivariance to the continuous setting by sampling uniform SO(3) grids. Our continuous SO(3) kernel is parameterized via RBF interpolation on similarly uniform grids. We demonstrate the advantages of our approach in volumetric medical image analysis. Our SE(3) equivariant models consistently outperform CNNs and regular discrete G-CNNs on challenging medical classification tasks and show significantly improved generalization capabilities. Our approach achieves up to a 16.5% gain in accuracy over regular CNNs.
You've Got Two Teachers: Co-evolutionary Image and Report Distillation for Semi-supervised Anatomical Abnormality Detection in Chest X-ray
Jul 18, 2023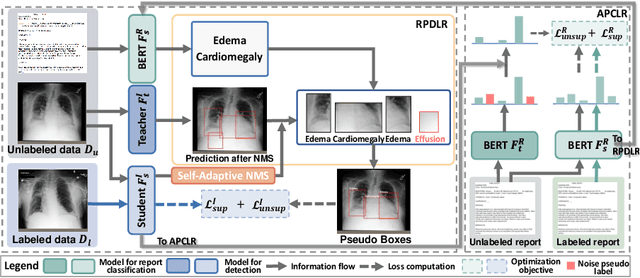


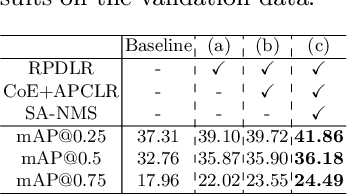
Chest X-ray (CXR) anatomical abnormality detection aims at localizing and characterising cardiopulmonary radiological findings in the radiographs, which can expedite clinical workflow and reduce observational oversights. Most existing methods attempted this task in either fully supervised settings which demanded costly mass per-abnormality annotations, or weakly supervised settings which still lagged badly behind fully supervised methods in performance. In this work, we propose a co-evolutionary image and report distillation (CEIRD) framework, which approaches semi-supervised abnormality detection in CXR by grounding the visual detection results with text-classified abnormalities from paired radiology reports, and vice versa. Concretely, based on the classical teacher-student pseudo label distillation (TSD) paradigm, we additionally introduce an auxiliary report classification model, whose prediction is used for report-guided pseudo detection label refinement (RPDLR) in the primary vision detection task. Inversely, we also use the prediction of the vision detection model for abnormality-guided pseudo classification label refinement (APCLR) in the auxiliary report classification task, and propose a co-evolution strategy where the vision and report models mutually promote each other with RPDLR and APCLR performed alternatively. To this end, we effectively incorporate the weak supervision by reports into the semi-supervised TSD pipeline. Besides the cross-modal pseudo label refinement, we further propose an intra-image-modal self-adaptive non-maximum suppression, where the pseudo detection labels generated by the teacher vision model are dynamically rectified by high-confidence predictions by the student. Experimental results on the public MIMIC-CXR benchmark demonstrate CEIRD's superior performance to several up-to-date weakly and semi-supervised methods.
Multi-Scale U-Shape MLP for Hyperspectral Image Classification
Jul 05, 2023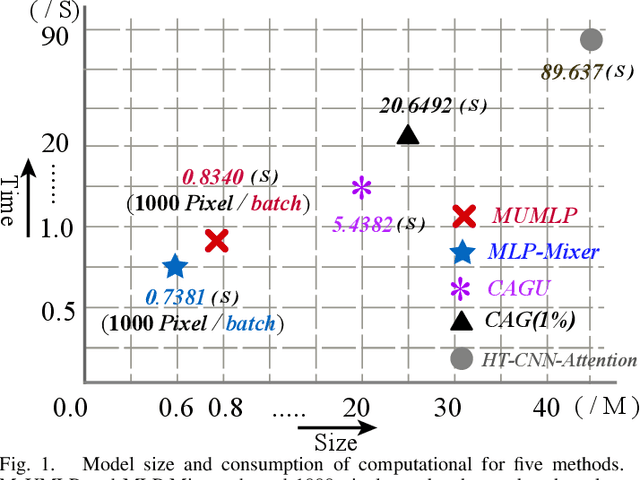
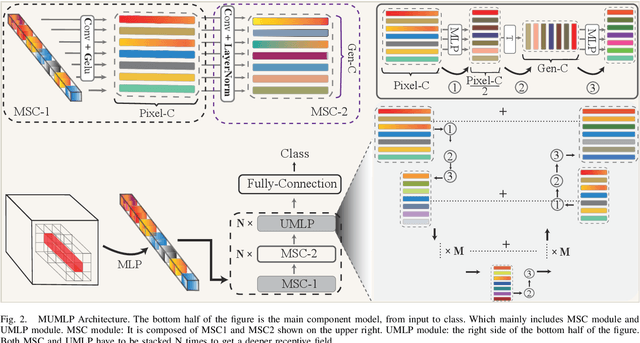

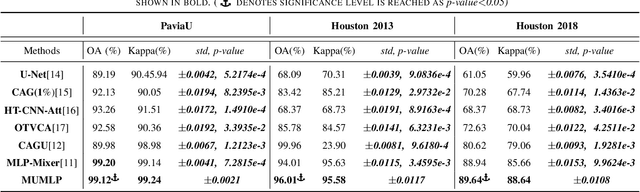
Hyperspectral images have significant applications in various domains, since they register numerous semantic and spatial information in the spectral band with spatial variability of spectral signatures. Two critical challenges in identifying pixels of the hyperspectral image are respectively representing the correlated information among the local and global, as well as the abundant parameters of the model. To tackle this challenge, we propose a Multi-Scale U-shape Multi-Layer Perceptron (MUMLP) a model consisting of the designed MSC (Multi-Scale Channel) block and the UMLP (U-shape Multi-Layer Perceptron) structure. MSC transforms the channel dimension and mixes spectral band feature to embed the deep-level representation adequately. UMLP is designed by the encoder-decoder structure with multi-layer perceptron layers, which is capable of compressing the large-scale parameters. Extensive experiments are conducted to demonstrate our model can outperform state-of-the-art methods across-the-board on three wide-adopted public datasets, namely Pavia University, Houston 2013 and Houston 2018
* 5 pages
Graph Self-Supervised Learning for Endoscopic Image Matching
Jun 19, 2023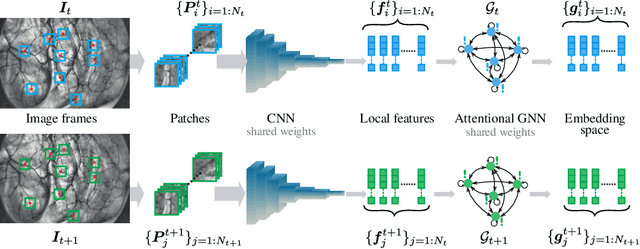
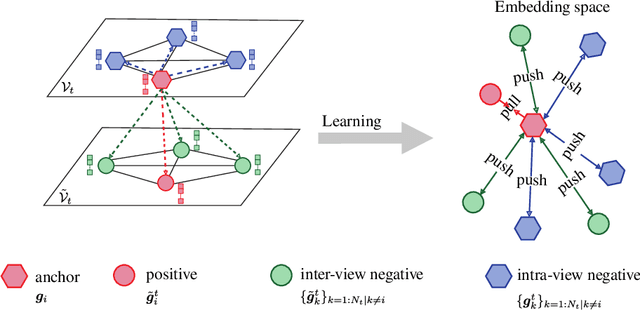
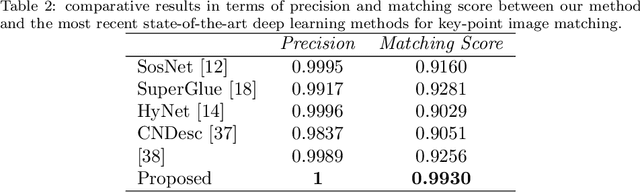
Accurate feature matching and correspondence in endoscopic images play a crucial role in various clinical applications, including patient follow-up and rapid anomaly localization through panoramic image generation. However, developing robust and accurate feature matching techniques faces challenges due to the lack of discriminative texture and significant variability between patients. To address these limitations, we propose a novel self-supervised approach that combines Convolutional Neural Networks for capturing local visual appearance and attention-based Graph Neural Networks for modeling spatial relationships between key-points. Our approach is trained in a fully self-supervised scheme without the need for labeled data. Our approach outperforms state-of-the-art handcrafted and deep learning-based methods, demonstrating exceptional performance in terms of precision rate (1) and matching score (99.3%). We also provide code and materials related to this work, which can be accessed at https://github.com/abenhamadou/graph-self-supervised-learning-for-endoscopic-image-matching.
Context-Aware Pseudo-Label Refinement for Source-Free Domain Adaptive Fundus Image Segmentation
Aug 15, 2023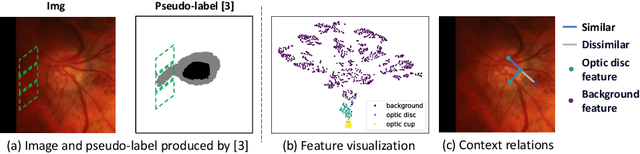
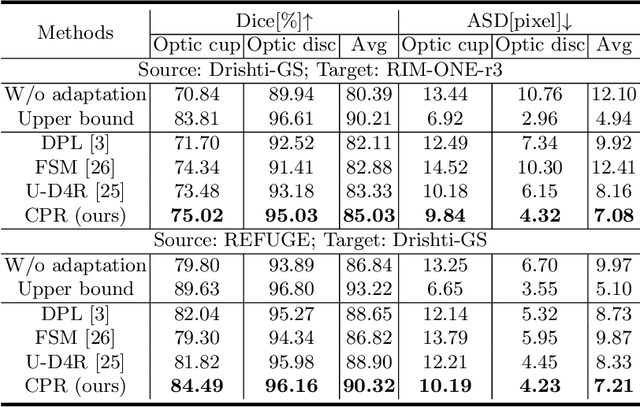
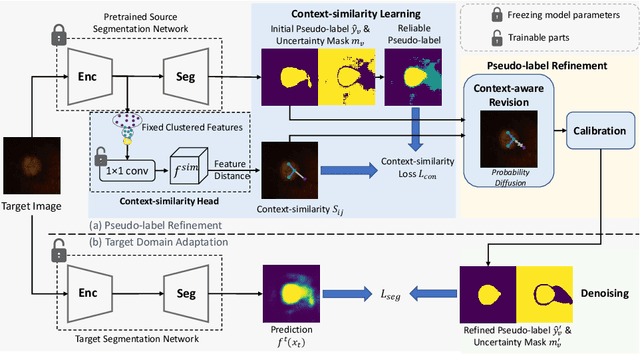
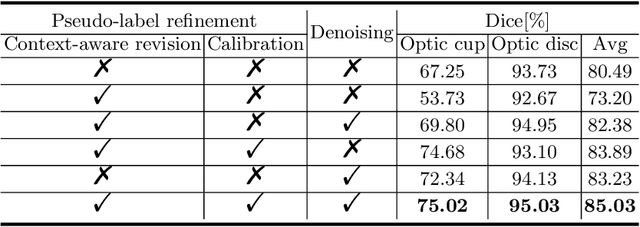
In the domain adaptation problem, source data may be unavailable to the target client side due to privacy or intellectual property issues. Source-free unsupervised domain adaptation (SF-UDA) aims at adapting a model trained on the source side to align the target distribution with only the source model and unlabeled target data. The source model usually produces noisy and context-inconsistent pseudo-labels on the target domain, i.e., neighbouring regions that have a similar visual appearance are annotated with different pseudo-labels. This observation motivates us to refine pseudo-labels with context relations. Another observation is that features of the same class tend to form a cluster despite the domain gap, which implies context relations can be readily calculated from feature distances. To this end, we propose a context-aware pseudo-label refinement method for SF-UDA. Specifically, a context-similarity learning module is developed to learn context relations. Next, pseudo-label revision is designed utilizing the learned context relations. Further, we propose calibrating the revised pseudo-labels to compensate for wrong revision caused by inaccurate context relations. Additionally, we adopt a pixel-level and class-level denoising scheme to select reliable pseudo-labels for domain adaptation. Experiments on cross-domain fundus images indicate that our approach yields the state-of-the-art results. Code is available at https://github.com/xmed-lab/CPR.
Does Image Anonymization Impact Computer Vision Training?
Jun 08, 2023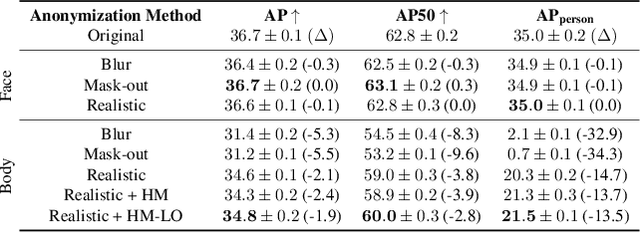

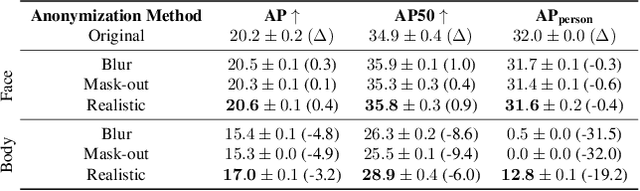

Image anonymization is widely adapted in practice to comply with privacy regulations in many regions. However, anonymization often degrades the quality of the data, reducing its utility for computer vision development. In this paper, we investigate the impact of image anonymization for training computer vision models on key computer vision tasks (detection, instance segmentation, and pose estimation). Specifically, we benchmark the recognition drop on common detection datasets, where we evaluate both traditional and realistic anonymization for faces and full bodies. Our comprehensive experiments reflect that traditional image anonymization substantially impacts final model performance, particularly when anonymizing the full body. Furthermore, we find that realistic anonymization can mitigate this decrease in performance, where our experiments reflect a minimal performance drop for face anonymization. Our study demonstrates that realistic anonymization can enable privacy-preserving computer vision development with minimal performance degradation across a range of important computer vision benchmarks.