 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt-Agnostic Evolution
Jan 28, 2026Visual Prompt Tuning (VPT) adapts a frozen Vision Transformer (ViT) to downstream tasks by inserting a small number of learnable prompt tokens into the token sequence at each layer. However, we observe that existing VPT variants often suffer from unstable training dynamics, characterized by gradient oscillations. A layer-wise analysis reveals that shallow-layer prompts tend to stagnate early, while deeper-layer prompts exhibit high-variance oscillations, leading to cross-layer mismatch. These issues slow convergence and degrade final performance. To address these challenges, we propose Prompt-Agnostic Evolution ($\mathtt{PAE}$), which strengthens vision prompt tuning by explicitly modeling prompt dynamics. From a frequency-domain perspective, we initialize prompts in a task-aware direction by uncovering and propagating frequency shortcut patterns that the backbone inherently exploits for recognition. To ensure coherent evolution across layers, we employ a shared Koopman operator that imposes a global linear transformation instead of uncoordinated, layer-specific updates. Finally, inspired by Lyapunov stability theory, we introduce a regularizer that constrains error amplification during evolution. Extensive experiments show that $\mathtt{PAE}$ accelerates convergence with an average $1.41\times$ speedup and improves accuracy by 1--3% on 25 datasets across multiple downstream tasks. Beyond performance, $\mathtt{PAE}$ is prompt-agnostic and lightweight, and it integrates seamlessly with diverse VPT variants without backbone modification or inference-time changes.
Stochastic Weight Sharing for Bayesian Neural Networks
May 23, 2025While offering a principled framework for uncertainty quantification in deep learning, the employment of Bayesian Neural Networks (BNNs) is still constrained by their increased computational requirements and the convergence difficulties when training very deep, state-of-the-art architectures. In this work, we reinterpret weight-sharing quantization techniques from a stochastic perspective in the context of training and inference with Bayesian Neural Networks (BNNs). Specifically, we leverage 2D adaptive Gaussian distributions, Wasserstein distance estimations, and alpha blending to encode the stochastic behaviour of a BNN in a lower dimensional, soft Gaussian representation. Through extensive empirical investigation, we demonstrate that our approach significantly reduces the computational overhead inherent in Bayesian learning by several orders of magnitude, enabling the efficient Bayesian training of large-scale models, such as ResNet-101 and Vision Transformer (VIT). On various computer vision benchmarks including CIFAR10, CIFAR100, and ImageNet1k. Our approach compresses model parameters by approximately 50x and reduces model size by 75, while achieving accuracy and uncertainty estimations comparable to the state-of-the-art.
Hypergraph Tversky-Aware Domain Incremental Learning for Brain Tumor Segmentation with Missing Modalities
May 22, 2025Existing methods for multimodal MRI segmentation with missing modalities typically assume that all MRI modalities are available during training. However, in clinical practice, some modalities may be missing due to the sequential nature of MRI acquisition, leading to performance degradation. Furthermore, retraining models to accommodate newly available modalities can be inefficient and may cause overfitting, potentially compromising previously learned knowledge. To address these challenges, we propose Replay-based Hypergraph Domain Incremental Learning (ReHyDIL) for brain tumor segmentation with missing modalities. ReHyDIL leverages Domain Incremental Learning (DIL) to enable the segmentation model to learn from newly acquired MRI modalities without forgetting previously learned information. To enhance segmentation performance across diverse patient scenarios, we introduce the Cross-Patient Hypergraph Segmentation Network (CHSNet), which utilizes hypergraphs to capture high-order associations between patients. Additionally, we incorporate Tversky-Aware Contrastive (TAC) loss to effectively mitigate information imbalance both across and within different modalities. Extensive experiments on the BraTS2019 dataset demonstrate that ReHyDIL outperforms state-of-the-art methods, achieving an improvement of over 2\% in the Dice Similarity Coefficient across various tumor regions. Our code is available at ReHyDIL.
Multi-Scale U-Shape MLP for Hyperspectral Image Classification
Jul 05, 2023



Hyperspectral images have significant applications in various domains, since they register numerous semantic and spatial information in the spectral band with spatial variability of spectral signatures. Two critical challenges in identifying pixels of the hyperspectral image are respectively representing the correlated information among the local and global, as well as the abundant parameters of the model. To tackle this challenge, we propose a Multi-Scale U-shape Multi-Layer Perceptron (MUMLP) a model consisting of the designed MSC (Multi-Scale Channel) block and the UMLP (U-shape Multi-Layer Perceptron) structure. MSC transforms the channel dimension and mixes spectral band feature to embed the deep-level representation adequately. UMLP is designed by the encoder-decoder structure with multi-layer perceptron layers, which is capable of compressing the large-scale parameters. Extensive experiments are conducted to demonstrate our model can outperform state-of-the-art methods across-the-board on three wide-adopted public datasets, namely Pavia University, Houston 2013 and Houston 2018
* 5 pages
Optimized Vectorizing of Building Structures with Swap: High-Efficiency Convolutional Channel-Swap Hybridization Strategy
Jun 26, 2023



The building planar graph reconstruction, a.k.a. footprint reconstruction, which lies in the domain of computer vision and geoinformatics, has been long afflicted with the challenge of redundant parameters in conventional convolutional models. Therefore, in this paper, we proposed an advanced and adaptive shift architecture, namely the Swap operation, which incorporates non-exponential growth parameters while retaining analogous functionalities to integrate local feature spatial information, resembling a high-dimensional convolution operator. The Swap, cross-channel operation, architecture implements the XOR operation to alternately exchange adjacent or diagonal features, and then blends alternating channels through a 1x1 convolution operation to consolidate information from different channels. The SwapNN architecture, on the other hand, incorporates a group-based parameter-sharing mechanism inspired by the convolutional neural network process and thereby significantly reducing the number of parameters. We validated our proposed approach through experiments on the SpaceNet corpus, a publicly available dataset annotated with 2,001 buildings across the cities of Los Angeles, Las Vegas, and Paris. Our results demonstrate the effectiveness of this innovative architecture in building planar graph reconstruction from 2D building images.
geoGAT: Graph Model Based on Attention Mechanism for Geographic Text Classification
Jan 13, 2021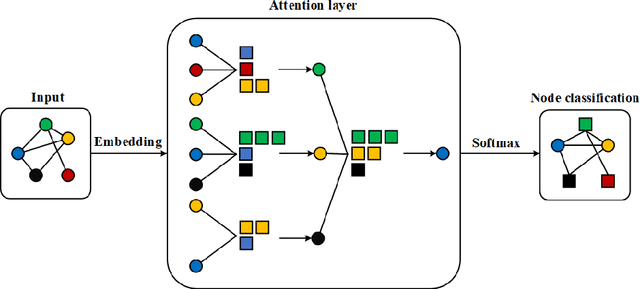

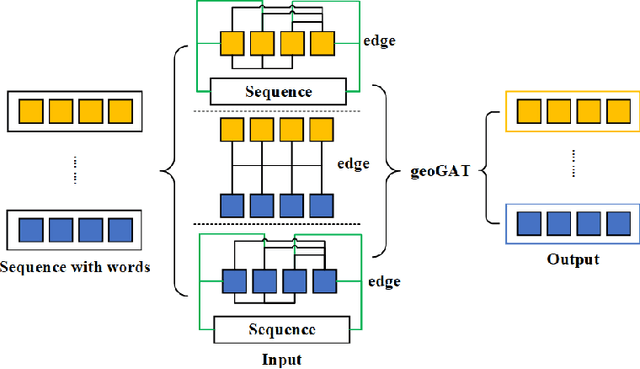
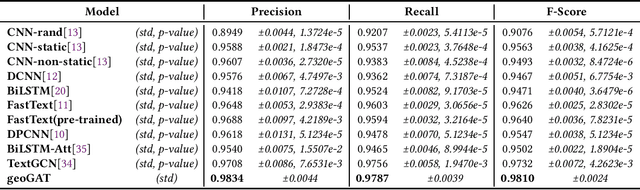
In the area of geographic information processing. There are few researches on geographic text classification. However, the application of this task in Chinese is relatively rare. In our work, we intend to implement a method to extract text containing geographical entities from a large number of network text. The geographic information in these texts is of great practical significance to transportation, urban and rural planning, disaster relief and other fields. We use the method of graph convolutional neural network with attention mechanism to achieve this function. Graph attention networks is an improvement of graph convolutional neural networks. Compared with GCN, the advantage of GAT is that the attention mechanism is proposed to weight the sum of the characteristics of adjacent nodes. In addition, We construct a Chinese dataset containing geographical classification from multiple datasets of Chinese text classification. The Macro-F Score of the geoGAT we used reached 95\% on the new Chinese dataset.
SAN: Scale-Aware Network for Semantic Segmentation of High-Resolution Aerial Images
Jul 06, 2019
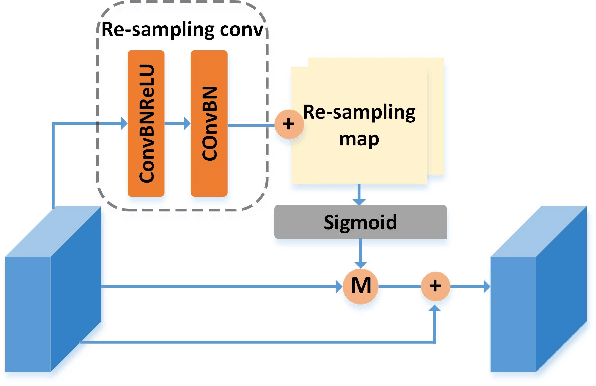
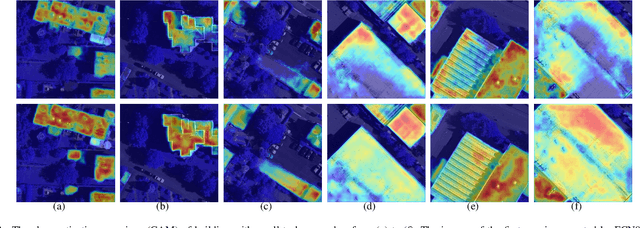

High-resolution aerial images have a wide range of applications, such as military exploration, and urban planning. Semantic segmentation is a fundamental method extensively used in the analysis of high-resolution aerial images. However, the ground objects in high-resolution aerial images have the characteristics of inconsistent scales, and this feature usually leads to unexpected predictions. To tackle this issue, we propose a novel scale-aware module (SAM). In SAM, we employ the re-sampling method aimed to make pixels adjust their positions to fit the ground objects with different scales, and it implicitly introduces spatial attention by employing a re-sampling map as the weighted map. As a result, the network with the proposed module named scale-aware network (SANet) has a stronger ability to distinguish the ground objects with inconsistent scale. Other than this, our proposed modules can easily embed in most of the existing network to improve their performance. We evaluate our modules on the International Society for Photogrammetry and Remote Sensing Vaihingen Dataset, and the experimental results and comprehensive analysis demonstrate the effectiveness of our proposed module.
ESFNet: Efficient Network for Building Extraction from High-Resolution Aerial Images
Apr 19, 2019
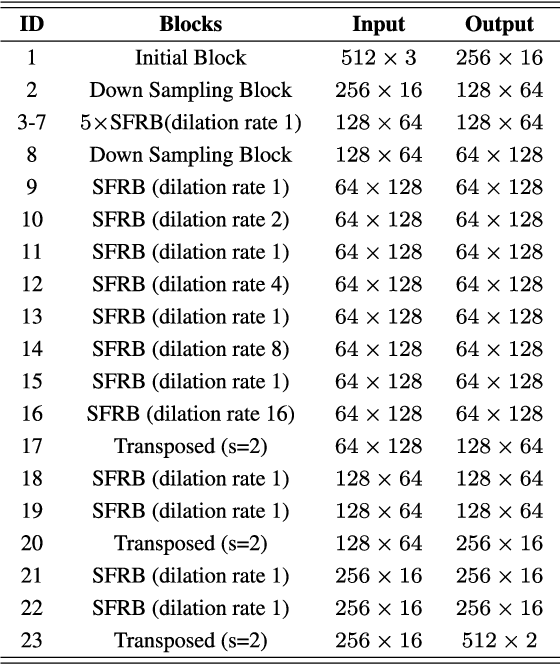
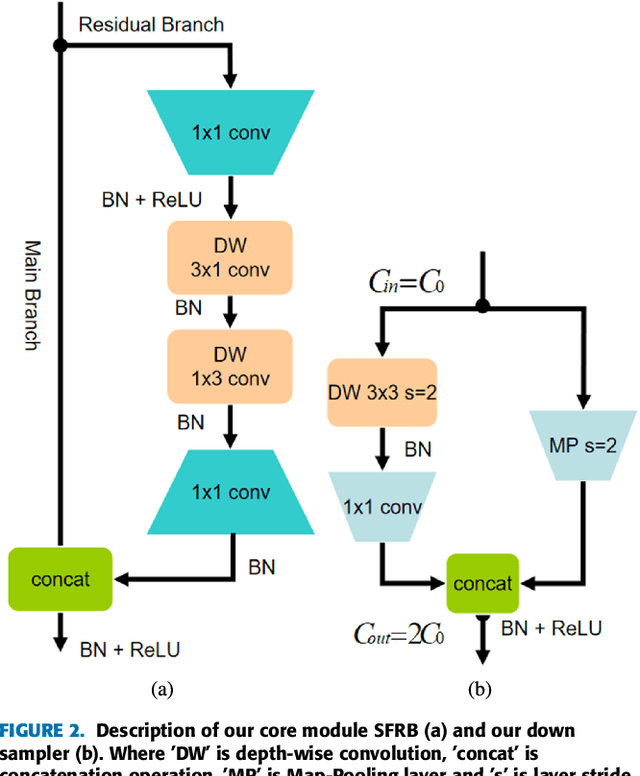
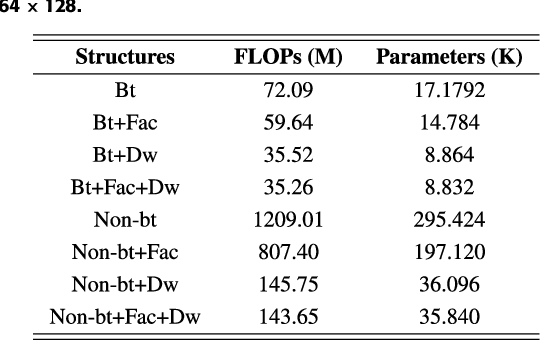
Building footprint extraction from high-resolution aerial images is always an essential part of urban dynamic monitoring, planning and management. It has also been a challenging task in remote sensing research. In recent years, deep neural networks have made great achievement in improving accuracy of building extraction from remote sensing imagery. However, most of existing approaches usually require large amount of parameters and floating point operations for high accuracy, it leads to high memory consumption and low inference speed which are harmful to research. In this paper, we proposed a novel efficient network named ESFNet which employs separable factorized residual block and utilizes the dilated convolutions, aiming to preserve slight accuracy loss with low computational cost and memory consumption. Our ESFNet obtains a better trade-off between accuracy and efficiency, it can run at over 100 FPS on single Tesla V100, requires 6x fewer FLOPs and has 18x fewer parameters than state-of-the-art real-time architecture ERFNet while preserving similar accuracy without any additional context module, post-processing and pre-trained scheme. We evaluated our networks on WHU Building Dataset and compared it with other state-of-the-art architectures. The result and comprehensive analysis show that our networks are benefit for efficient remote sensing researches, and the idea can be further extended to other areas. The code is public available at: https://github.com/mrluin/ESFNet-Pytorch