 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RHINO: Regularizing the Hash-based Implicit Neural Representation
Sep 22, 2023
The use of Implicit Neural Representation (INR) through a hash-table has demonstrated impressive effectiveness and efficiency in characterizing intricate signals. However, current state-of-the-art methods exhibit insufficient regularization, often yielding unreliable and noisy results during interpolations. We find that this issue stems from broken gradient flow between input coordinates and indexed hash-keys, where the chain rule attempts to model discrete hash-keys, rather than the continuous coordinates. To tackle this concern, we introduce RHINO, in which a continuous analytical function is incorporated to facilitate regularization by connecting the input coordinate and the network additionally without modifying the architecture of current hash-based INRs. This connection ensures a seamless backpropagation of gradients from the network's output back to the input coordinates, thereby enhancing regularization. Our experimental results not only showcase the broadened regularization capability across different hash-based INRs like DINER and Instant NGP, but also across a variety of tasks such as image fitting, representation of signed distance functions, and optimization of 5D static / 6D dynamic neural radiance fields. Notably, RHINO outperforms current state-of-the-art techniques in both quality and speed, affirming its superiority.
CINFormer: Transformer network with multi-stage CNN feature injection for surface defect segmentation
Sep 22, 2023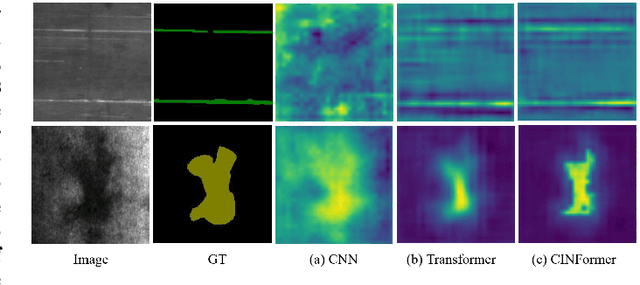
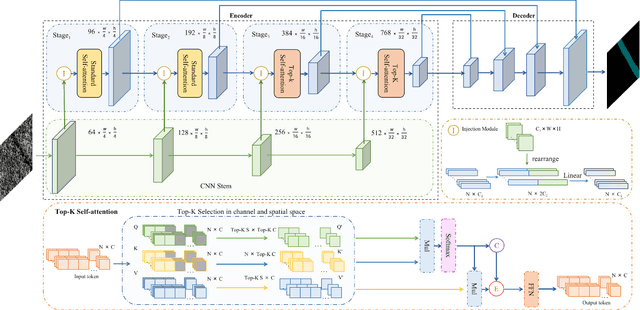

Surface defect inspection is of great importance for industrial manufacture and production. Though defect inspection methods based on deep learning have made significant progress, there are still some challenges for these methods, such as indistinguishable weak defects and defect-like interference in the background. To address these issues, we propose a transformer network with multi-stage CNN (Convolutional Neural Network) feature injection for surface defect segmentation, which is a UNet-like structure named CINFormer. CINFormer presents a simple yet effective feature integration mechanism that injects the multi-level CNN features of the input image into different stages of the transformer network in the encoder. This can maintain the merit of CNN capturing detailed features and that of transformer depressing noises in the background, which facilitates accurate defect detection. In addition, CINFormer presents a Top-K self-attention module to focus on tokens with more important information about the defects, so as to further reduce the impact of the redundant background. Extensive experiments conducted on the surface defect datasets DAGM 2007, Magnetic tile, and NEU show that the proposed CINFormer achieves state-of-the-art performance in defect detection.
GIT-Mol: A Multi-modal Large Language Model for Molecular Science with Graph, Image, and Text
Aug 14, 2023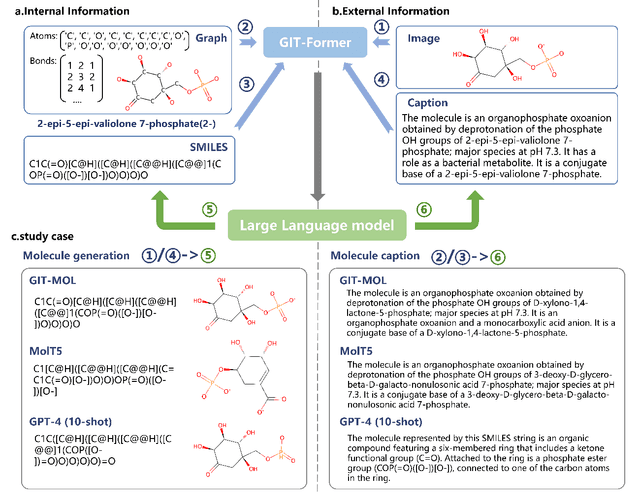

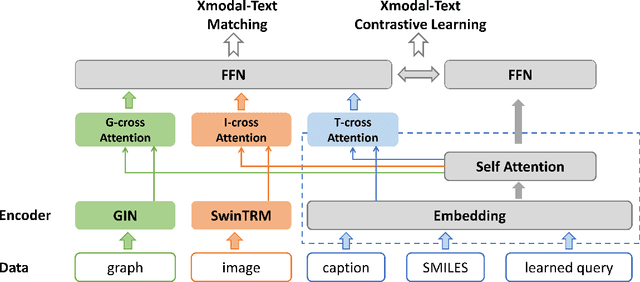
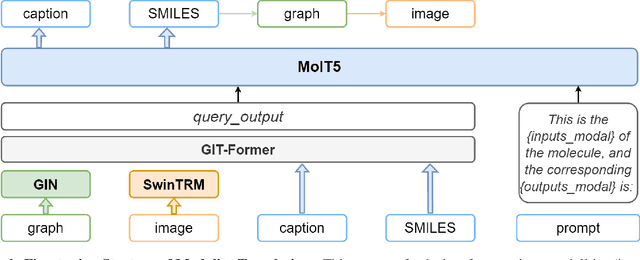
Large language models have made significant strides in natural language processing, paving the way for innovative applications including molecular representation and generation. However, most existing single-modality approaches cannot capture the abundant and complex information in molecular data. Here, we introduce GIT-Mol, a multi-modal large language model that integrates the structure Graph, Image, and Text information, including the Simplified Molecular Input Line Entry System (SMILES) and molecular captions. To facilitate the integration of multi-modal molecular data, we propose GIT-Former, a novel architecture capable of mapping all modalities into a unified latent space. Our study develops an innovative any-to-language molecular translation strategy and achieves a 10%-15% improvement in molecular captioning, a 5%-10% accuracy increase in property prediction, and a 20% boost in molecule generation validity compared to baseline or single-modality models.
Quaternion tensor ring decomposition and application for color image inpainting
Jul 20, 2023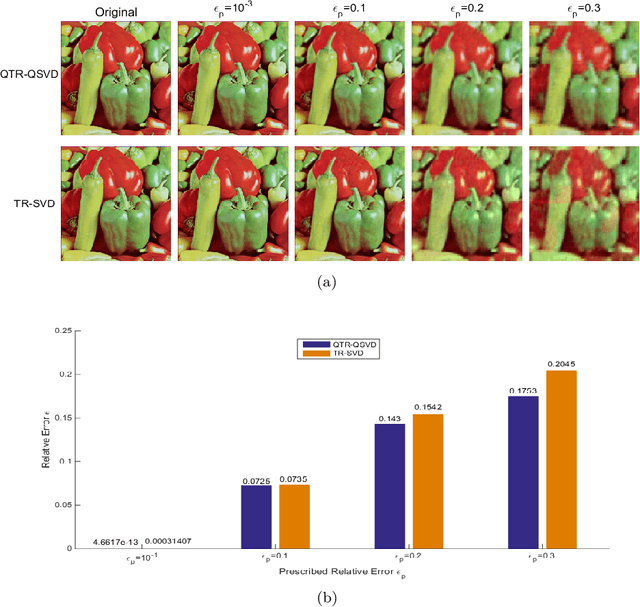
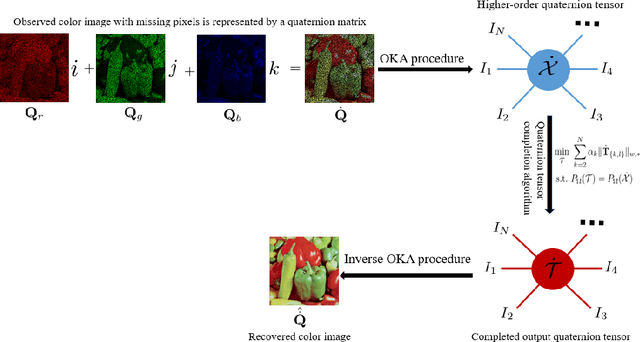
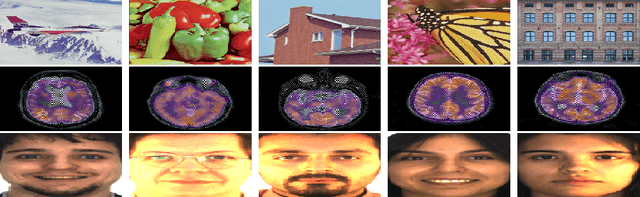
In recent years, tensor networks have emerged as powerful tools for solving large-scale optimization problems. One of the most promising tensor networks is the tensor ring (TR) decomposition, which achieves circular dimensional permutation invariance in the model through the utilization of the trace operation and equitable treatment of the latent cores. On the other hand, more recently, quaternions have gained significant attention and have been widely utilized in color image processing tasks due to their effectiveness in encoding color pixels. Therefore, in this paper, we propose the quaternion tensor ring (QTR) decomposition, which inherits the powerful and generalized representation abilities of the TR decomposition while leveraging the advantages of quaternions for color pixel representation. In addition to providing the definition of QTR decomposition and an algorithm for learning the QTR format, this paper also proposes a low-rank quaternion tensor completion (LRQTC) model and its algorithm for color image inpainting based on the QTR decomposition. Finally, extensive experiments on color image inpainting demonstrate that the proposed QTLRC method is highly competitive.
Cross-modal and Cross-domain Knowledge Transfer for Label-free 3D Segmentation
Sep 19, 2023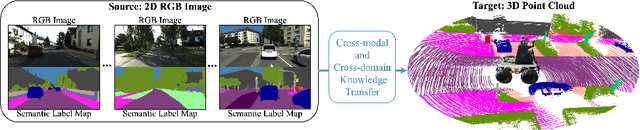
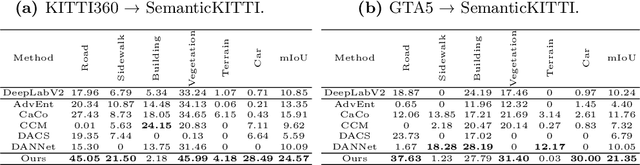
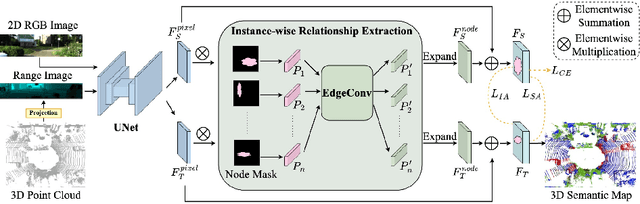

Current state-of-the-art point cloud-based perception methods usually rely on large-scale labeled data, which requires expensive manual annotations. A natural option is to explore the unsupervised methodology for 3D perception tasks. However, such methods often face substantial performance-drop difficulties. Fortunately, we found that there exist amounts of image-based datasets and an alternative can be proposed, i.e., transferring the knowledge in the 2D images to 3D point clouds. Specifically, we propose a novel approach for the challenging cross-modal and cross-domain adaptation task by fully exploring the relationship between images and point clouds and designing effective feature alignment strategies. Without any 3D labels, our method achieves state-of-the-art performance for 3D point cloud semantic segmentation on SemanticKITTI by using the knowledge of KITTI360 and GTA5, compared to existing unsupervised and weakly-supervised baselines.
* 12 pages,4 figures,accepted
Perceptual Quality Assessment of 360$^\circ$ Images Based on Generative Scanpath Representation
Sep 07, 2023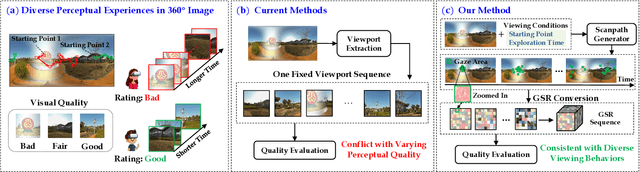
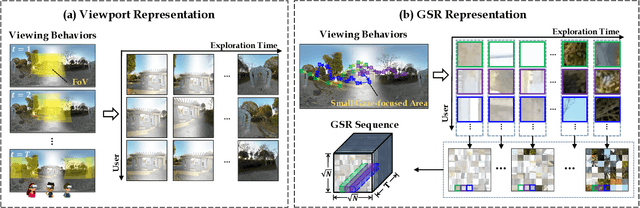
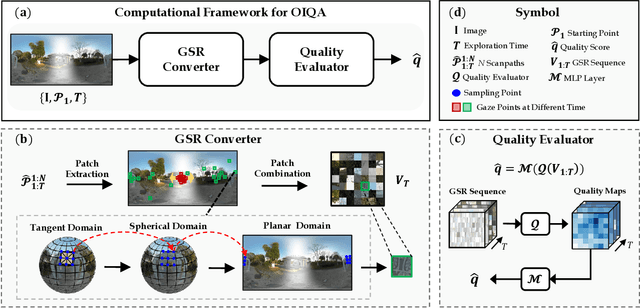
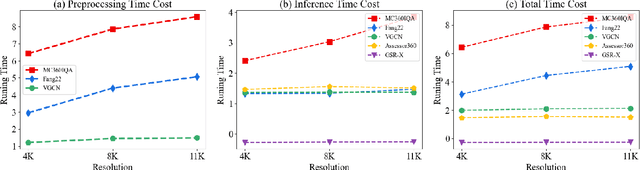
Despite substantial efforts dedicated to the design of heuristic models for omnidirectional (i.e., 360$^\circ$) image quality assessment (OIQA), a conspicuous gap remains due to the lack of consideration for the diversity of viewing behaviors that leads to the varying perceptual quality of 360$^\circ$ images. Two critical aspects underline this oversight: the neglect of viewing conditions that significantly sway user gaze patterns and the overreliance on a single viewport sequence from the 360$^\circ$ image for quality inference. To address these issues, we introduce a unique generative scanpath representation (GSR) for effective quality inference of 360$^\circ$ images, which aggregates varied perceptual experiences of multi-hypothesis users under a predefined viewing condition. More specifically, given a viewing condition characterized by the starting point of viewing and exploration time, a set of scanpaths consisting of dynamic visual fixations can be produced using an apt scanpath generator. Following this vein, we use the scanpaths to convert the 360$^\circ$ image into the unique GSR, which provides a global overview of gazed-focused contents derived from scanpaths. As such, the quality inference of the 360$^\circ$ image is swiftly transformed to that of GSR. We then propose an efficient OIQA computational framework by learning the quality maps of GSR. Comprehensive experimental results validate that the predictions of the proposed framework are highly consistent with human perception in the spatiotemporal domain, especially in the challenging context of locally distorted 360$^\circ$ images under varied viewing conditions. The code will be released at https://github.com/xiangjieSui/GSR
DreamTeacher: Pretraining Image Backbones with Deep Generative Models
Jul 14, 2023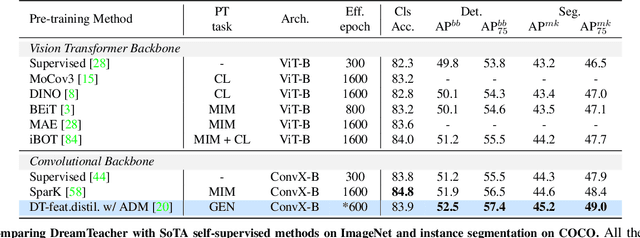
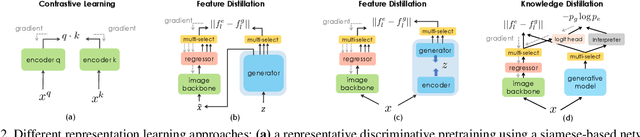

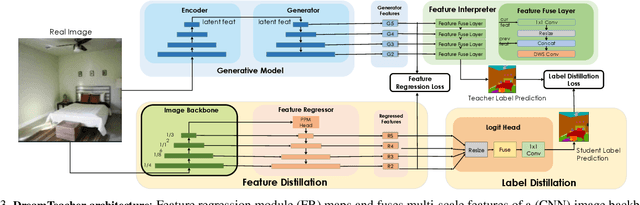
In this work, we introduce a self-supervised feature representation learning framework DreamTeacher that utilizes generative networks for pre-training downstream image backbones. We propose to distill knowledge from a trained generative model into standard image backbones that have been well engineered for specific perception tasks. We investigate two types of knowledge distillation: 1) distilling learned generative features onto target image backbones as an alternative to pretraining these backbones on large labeled datasets such as ImageNet, and 2) distilling labels obtained from generative networks with task heads onto logits of target backbones. We perform extensive analyses on multiple generative models, dense prediction benchmarks, and several pre-training regimes. We empirically find that our DreamTeacher significantly outperforms existing self-supervised representation learning approaches across the board. Unsupervised ImageNet pre-training with DreamTeacher leads to significant improvements over ImageNet classification pre-training on downstream datasets, showcasing generative models, and diffusion generative models specifically, as a promising approach to representation learning on large, diverse datasets without requiring manual annotation.
ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals
Sep 21, 2023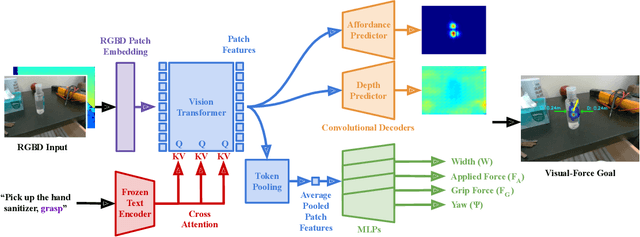



We present ForceSight, a system for text-guided mobile manipulation that predicts visual-force goals using a deep neural network. Given a single RGBD image combined with a text prompt, ForceSight determines a target end-effector pose in the camera frame (kinematic goal) and the associated forces (force goal). Together, these two components form a visual-force goal. Prior work has demonstrated that deep models outputting human-interpretable kinematic goals can enable dexterous manipulation by real robots. Forces are critical to manipulation, yet have typically been relegated to lower-level execution in these systems. When deployed on a mobile manipulator equipped with an eye-in-hand RGBD camera, ForceSight performed tasks such as precision grasps, drawer opening, and object handovers with an 81% success rate in unseen environments with object instances that differed significantly from the training data. In a separate experiment, relying exclusively on visual servoing and ignoring force goals dropped the success rate from 90% to 45%, demonstrating that force goals can significantly enhance performance. The appendix, videos, code, and trained models are available at https://force-sight.github.io/.
Multi-Task Cooperative Learning via Searching for Flat Minima
Sep 21, 2023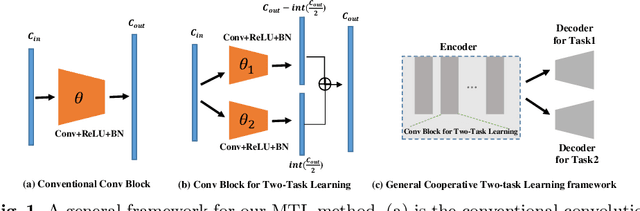
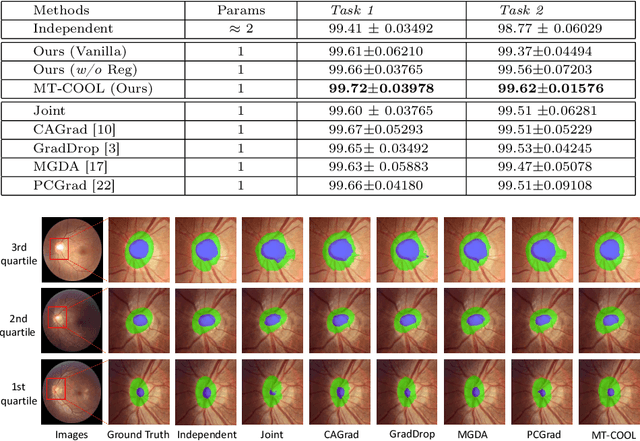

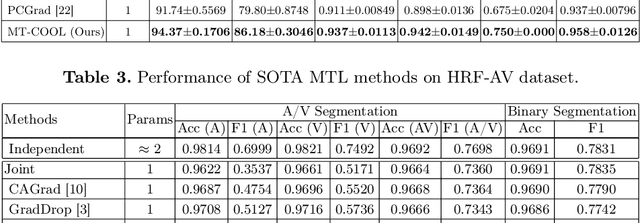
Multi-task learning (MTL) has shown great potential in medical image analysis, improving the generalizability of the learned features and the performance in individual tasks. However, most of the work on MTL focuses on either architecture design or gradient manipulation, while in both scenarios, features are learned in a competitive manner. In this work, we propose to formulate MTL as a multi/bi-level optimization problem, and therefore force features to learn from each task in a cooperative approach. Specifically, we update the sub-model for each task alternatively taking advantage of the learned sub-models of the other tasks. To alleviate the negative transfer problem during the optimization, we search for flat minima for the current objective function with regard to features from other tasks. To demonstrate the effectiveness of the proposed approach, we validate our method on three publicly available datasets. The proposed method shows the advantage of cooperative learning, and yields promising results when compared with the state-of-the-art MTL approaches. The code will be available online.
Online Supervised Training of Spaceborne Vision during Proximity Operations using Adaptive Kalman Filtering
Sep 20, 2023This work presents an Online Supervised Training (OST) method to enable robust vision-based navigation about a non-cooperative spacecraft. Spaceborne Neural Networks (NN) are susceptible to domain gap as they are primarily trained with synthetic images due to the inaccessibility of space. OST aims to close this gap by training a pose estimation NN online using incoming flight images during Rendezvous and Proximity Operations (RPO). The pseudo-labels are provided by adaptive unscented Kalman filter where the NN is used in the loop as a measurement module. Specifically, the filter tracks the target's relative orbital and attitude motion, and its accuracy is ensured by robust on-ground training of the NN using only synthetic data. The experiments on real hardware-in-the-loop trajectory images show that OST can improve the NN performance on the target image domain given that OST is performed on images of the target viewed from a diverse set of directions during RPO.