 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal-Conditioned Latent Diffusion Models for Fashion Image Editing
Mar 25, 2024
Fashion illustration is a crucial medium for designers to convey their creative vision and transform design concepts into tangible representations that showcase the interplay between clothing and the human body. In the context of fashion design, computer vision techniques have the potential to enhance and streamline the design process. Departing from prior research primarily focused on virtual try-on, this paper tackles the task of multimodal-conditioned fashion image editing. Our approach aims to generate human-centric fashion images guided by multimodal prompts, including text, human body poses, garment sketches, and fabric textures. To address this problem, we propose extending latent diffusion models to incorporate these multiple modalities and modifying the structure of the denoising network, taking multimodal prompts as input. To condition the proposed architecture on fabric textures, we employ textual inversion techniques and let diverse cross-attention layers of the denoising network attend to textual and texture information, thus incorporating different granularity conditioning details. Given the lack of datasets for the task, we extend two existing fashion datasets, Dress Code and VITON-HD, with multimodal annotations. Experimental evaluations demonstrate the effectiveness of our proposed approach in terms of realism and coherence concerning the provided multimodal inputs.
Translation-based Video-to-Video Synthesis
Apr 03, 2024Translation-based Video Synthesis (TVS) has emerged as a vital research area in computer vision, aiming to facilitate the transformation of videos between distinct domains while preserving both temporal continuity and underlying content features. This technique has found wide-ranging applications, encompassing video super-resolution, colorization, segmentation, and more, by extending the capabilities of traditional image-to-image translation to the temporal domain. One of the principal challenges faced in TVS is the inherent risk of introducing flickering artifacts and inconsistencies between frames during the synthesis process. This is particularly challenging due to the necessity of ensuring smooth and coherent transitions between video frames. Efforts to tackle this challenge have induced the creation of diverse strategies and algorithms aimed at mitigating these unwanted consequences. This comprehensive review extensively examines the latest progress in the realm of TVS. It thoroughly investigates emerging methodologies, shedding light on the fundamental concepts and mechanisms utilized for proficient video synthesis. This survey also illuminates their inherent strengths, limitations, appropriate applications, and potential avenues for future development.
HEMIT: H&E to Multiplex-immunohistochemistry Image Translation with Dual-Branch Pix2pix Generator
Mar 27, 2024Computational analysis of multiplexed immunofluorescence histology data is emerging as an important method for understanding the tumour micro-environment in cancer. This work presents HEMIT, a dataset designed for translating Hematoxylin and Eosin (H&E) sections to multiplex-immunohistochemistry (mIHC) images, featuring DAPI, CD3, and panCK markers. Distinctively, HEMIT's mIHC images are multi-component and cellular-level aligned with H&E, enriching supervised stain translation tasks. To our knowledge, HEMIT is the first publicly available cellular-level aligned dataset that enables H&E to multi-target mIHC image translation. This dataset provides the computer vision community with a valuable resource to develop novel computational methods which have the potential to gain new insights from H&E slide archives. We also propose a new dual-branch generator architecture, using residual Convolutional Neural Networks (CNNs) and Swin Transformers which achieves better translation outcomes than other popular algorithms. When evaluated on HEMIT, it outperforms pix2pixHD, pix2pix, U-Net, and ResNet, achieving the highest overall score on key metrics including the Structural Similarity Index Measure (SSIM), Pearson correlation score (R), and Peak signal-to-noise Ratio (PSNR). Additionally, downstream analysis has been used to further validate the quality of the generated mIHC images. These results set a new benchmark in the field of stain translation tasks.
AdaIR: Adaptive All-in-One Image Restoration via Frequency Mining and Modulation
Mar 21, 2024
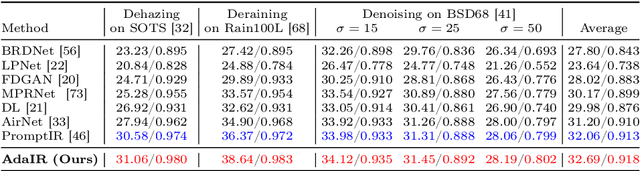
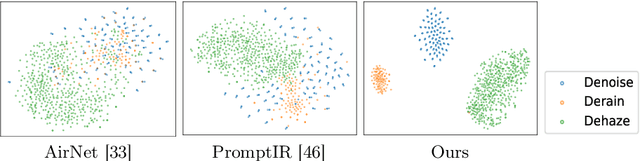

In the image acquisition process, various forms of degradation, including noise, haze, and rain, are frequently introduced. These degradations typically arise from the inherent limitations of cameras or unfavorable ambient conditions. To recover clean images from degraded versions, numerous specialized restoration methods have been developed, each targeting a specific type of degradation. Recently, all-in-one algorithms have garnered significant attention by addressing different types of degradations within a single model without requiring prior information of the input degradation type. However, these methods purely operate in the spatial domain and do not delve into the distinct frequency variations inherent to different degradation types. To address this gap, we propose an adaptive all-in-one image restoration network based on frequency mining and modulation. Our approach is motivated by the observation that different degradation types impact the image content on different frequency subbands, thereby requiring different treatments for each restoration task. Specifically, we first mine low- and high-frequency information from the input features, guided by the adaptively decoupled spectra of the degraded image. The extracted features are then modulated by a bidirectional operator to facilitate interactions between different frequency components. Finally, the modulated features are merged into the original input for a progressively guided restoration. With this approach, the model achieves adaptive reconstruction by accentuating the informative frequency subbands according to different input degradations. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on different image restoration tasks, including denoising, dehazing, deraining, motion deblurring, and low-light image enhancement. Our code is available at https://github.com/c-yn/AdaIR.
PIE: Physics-inspired Low-light Enhancement
Apr 06, 2024In this paper, we propose a physics-inspired contrastive learning paradigm for low-light enhancement, called PIE. PIE primarily addresses three issues: (i) To resolve the problem of existing learning-based methods often training a LLE model with strict pixel-correspondence image pairs, we eliminate the need for pixel-correspondence paired training data and instead train with unpaired images. (ii) To address the disregard for negative samples and the inadequacy of their generation in existing methods, we incorporate physics-inspired contrastive learning for LLE and design the Bag of Curves (BoC) method to generate more reasonable negative samples that closely adhere to the underlying physical imaging principle. (iii) To overcome the reliance on semantic ground truths in existing methods, we propose an unsupervised regional segmentation module, ensuring regional brightness consistency while eliminating the dependency on semantic ground truths. Overall, the proposed PIE can effectively learn from unpaired positive/negative samples and smoothly realize non-semantic regional enhancement, which is clearly different from existing LLE efforts. Besides the novel architecture of PIE, we explore the gain of PIE on downstream tasks such as semantic segmentation and face detection. Training on readily available open data and extensive experiments demonstrate that our method surpasses the state-of-the-art LLE models over six independent cross-scenes datasets. PIE runs fast with reasonable GFLOPs in test time, making it easy to use on mobile devices.
VmambaIR: Visual State Space Model for Image Restoration
Mar 18, 2024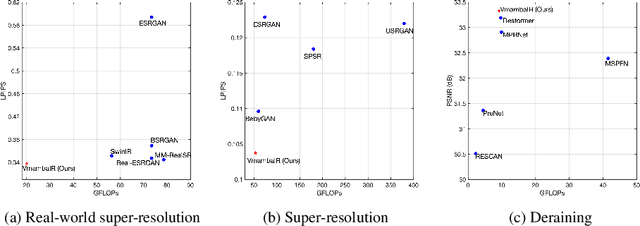
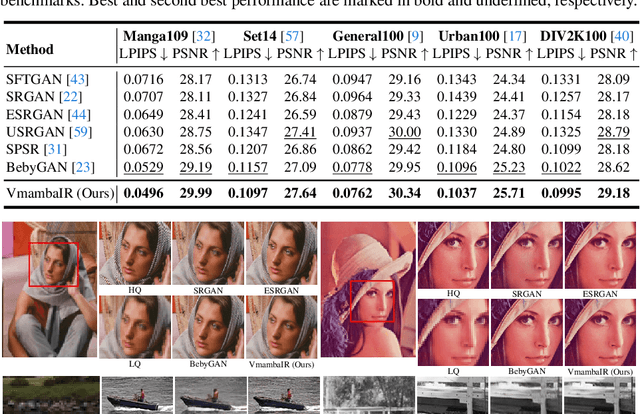
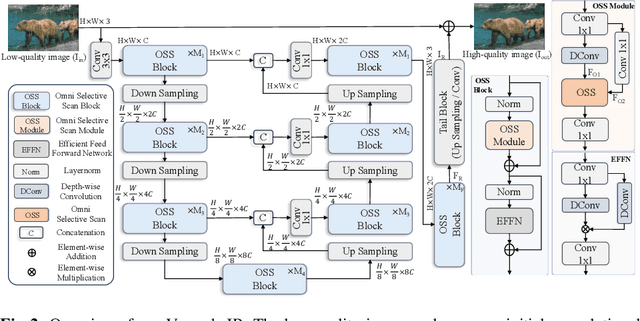
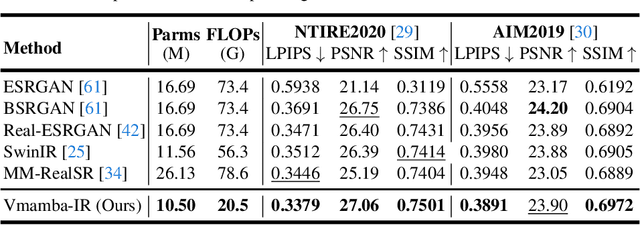
Image restoration is a critical task in low-level computer vision, aiming to restore high-quality images from degraded inputs. Various models, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), transformers, and diffusion models (DMs), have been employed to address this problem with significant impact. However, CNNs have limitations in capturing long-range dependencies. DMs require large prior models and computationally intensive denoising steps. Transformers have powerful modeling capabilities but face challenges due to quadratic complexity with input image size. To address these challenges, we propose VmambaIR, which introduces State Space Models (SSMs) with linear complexity into comprehensive image restoration tasks. We utilize a Unet architecture to stack our proposed Omni Selective Scan (OSS) blocks, consisting of an OSS module and an Efficient Feed-Forward Network (EFFN). Our proposed omni selective scan mechanism overcomes the unidirectional modeling limitation of SSMs by efficiently modeling image information flows in all six directions. Furthermore, we conducted a comprehensive evaluation of our VmambaIR across multiple image restoration tasks, including image deraining, single image super-resolution, and real-world image super-resolution. Extensive experimental results demonstrate that our proposed VmambaIR achieves state-of-the-art (SOTA) performance with much fewer computational resources and parameters. Our research highlights the potential of state space models as promising alternatives to the transformer and CNN architectures in serving as foundational frameworks for next-generation low-level visual tasks.
Integrative Graph-Transformer Framework for Histopathology Whole Slide Image Representation and Classification
Mar 26, 2024In digital pathology, the multiple instance learning (MIL) strategy is widely used in the weakly supervised histopathology whole slide image (WSI) classification task where giga-pixel WSIs are only labeled at the slide level. However, existing attention-based MIL approaches often overlook contextual information and intrinsic spatial relationships between neighboring tissue tiles, while graph-based MIL frameworks have limited power to recognize the long-range dependencies. In this paper, we introduce the integrative graph-transformer framework that simultaneously captures the context-aware relational features and global WSI representations through a novel Graph Transformer Integration (GTI) block. Specifically, each GTI block consists of a Graph Convolutional Network (GCN) layer modeling neighboring relations at the local instance level and an efficient global attention model capturing comprehensive global information from extensive feature embeddings. Extensive experiments on three publicly available WSI datasets: TCGA-NSCLC, TCGA-RCC and BRIGHT, demonstrate the superiority of our approach over current state-of-the-art MIL methods, achieving an improvement of 1.0% to 2.6% in accuracy and 0.7%-1.6% in AUROC.
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
Improving Detection in Aerial Images by Capturing Inter-Object Relationships
Apr 05, 2024In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
Generalizing deep learning models for medical image classification
Mar 21, 2024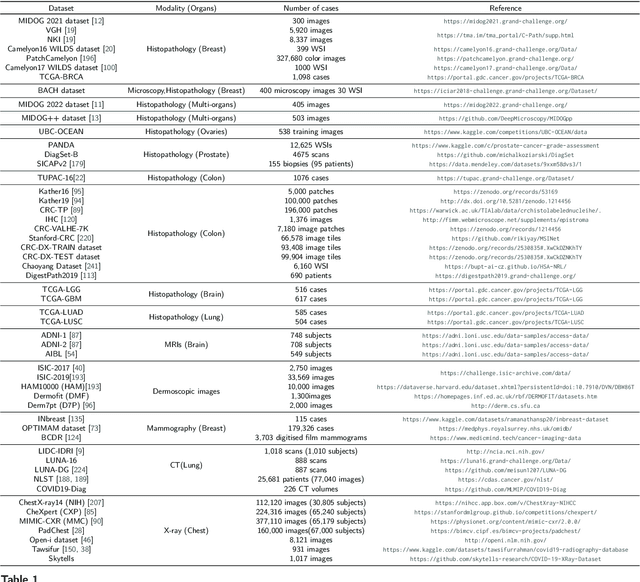
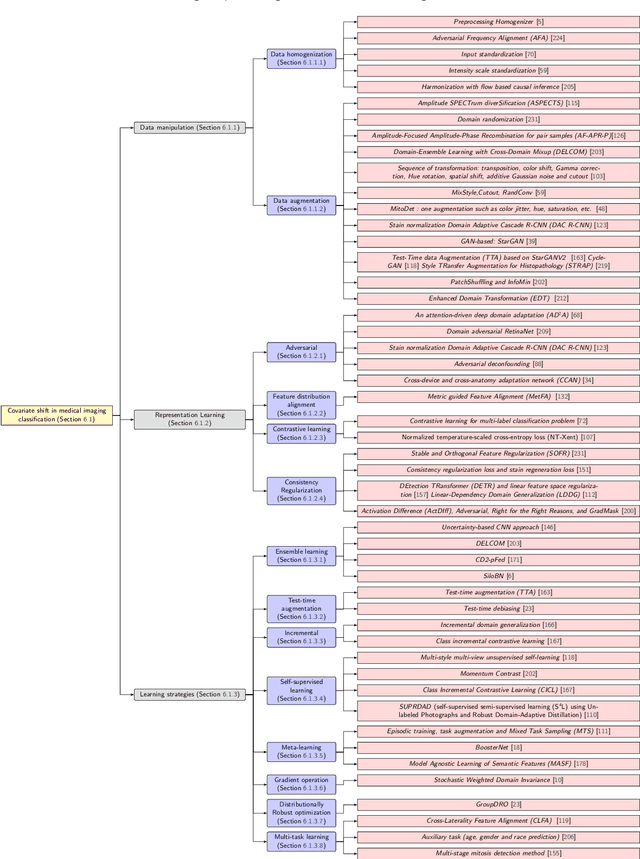
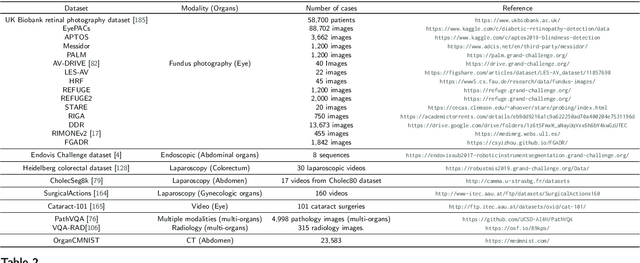
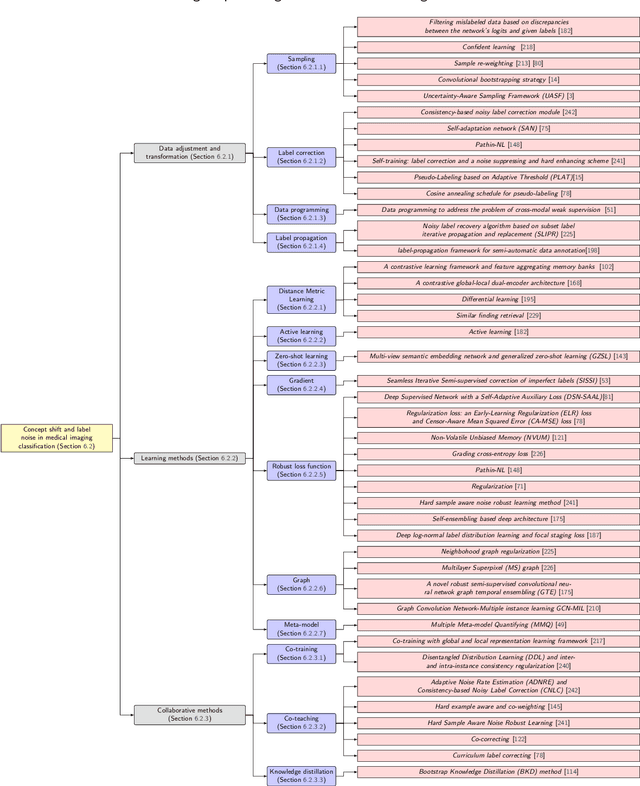
Numerous Deep Learning (DL) models have been developed for a large spectrum of medical image analysis applications, which promises to reshape various facets of medical practice. Despite early advances in DL model validation and implementation, which encourage healthcare institutions to adopt them, some fundamental questions remain: are the DL models capable of generalizing? What causes a drop in DL model performances? How to overcome the DL model performance drop? Medical data are dynamic and prone to domain shift, due to multiple factors such as updates to medical equipment, new imaging workflow, and shifts in patient demographics or populations can induce this drift over time. In this paper, we review recent developments in generalization methods for DL-based classification models. We also discuss future challenges, including the need for improved evaluation protocols and benchmarks, and envisioned future developments to achieve robust, generalized models for medical image classification.