 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021

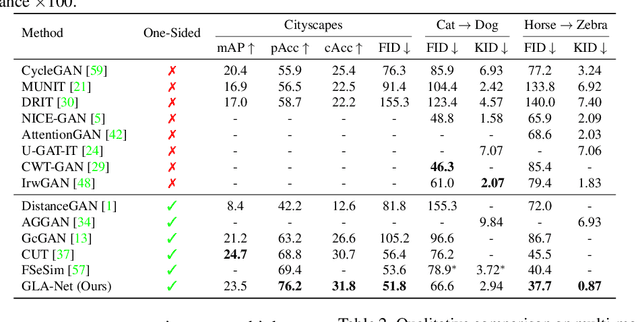
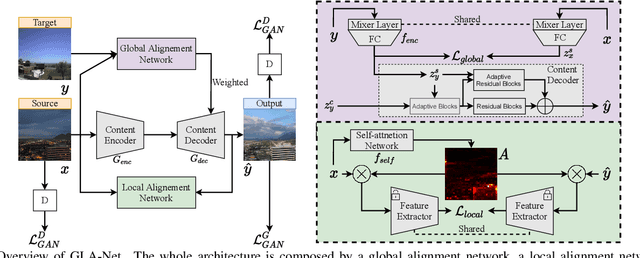
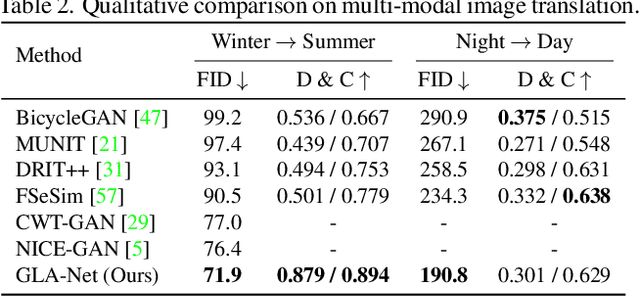
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
Semantically-aware Mask CycleGAN for Translating Artistic Portraits to Photo-realistic Visualizations
Jun 11, 2023


Image-to-image translation (I2I) is defined as a computer vision task where the aim is to transfer images in a source domain to a target domain with minimal loss or alteration of the content representations. Major progress has been made since I2I was proposed with the invention of a variety of revolutionary generative models. Among them, GAN-based models perform exceptionally well as they are mostly tailor-made for specific domains or tasks. However, few works proposed a tailor-made method for the artistic domain. In this project, I propose the Semantic-aware Mask CycleGAN (SMCycleGAN) architecture which can translate artistic portraits to photo-realistic visualizations. This model can generate realistic human portraits by feeding the discriminators semantically masked fake samples, thus enforcing them to make discriminative decisions with partial information so that the generators can be optimized to synthesize more realistic human portraits instead of increasing the similarity of other irrelevant components, such as the background. Experiments have shown that the SMCycleGAN generate images with significantly increased realism and minimal loss of content representations.
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Jul 24, 2020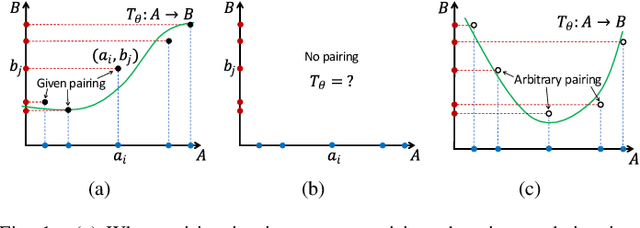



Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but we show that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. In this paper we introduce linear encoder-decoder architectures for unsupervised image to image translation. We show that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, we show a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.
DeepI2I: Enabling Deep Hierarchical Image-to-Image Translation by Transferring from GANs
Nov 11, 2020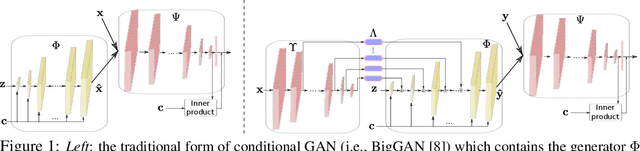
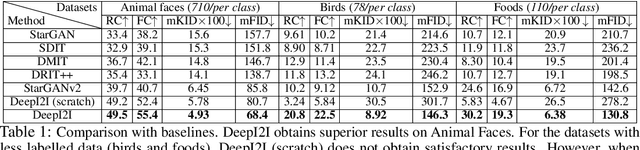
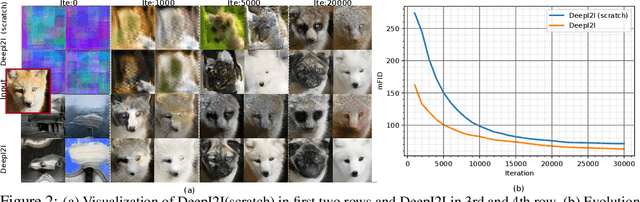

Image-to-image translation has recently achieved remarkable results. But despite current success, it suffers from inferior performance when translations between classes require large shape changes. We attribute this to the high-resolution bottlenecks which are used by current state-of-the-art image-to-image methods. Therefore, in this work, we propose a novel deep hierarchical Image-to-Image Translation method, called DeepI2I. We learn a model by leveraging hierarchical features: (a) structural information contained in the shallow layers and (b) semantic information extracted from the deep layers. To enable the training of deep I2I models on small datasets, we propose a novel transfer learning method, that transfers knowledge from pre-trained GANs. Specifically, we leverage the discriminator of a pre-trained GANs (i.e. BigGAN or StyleGAN) to initialize both the encoder and the discriminator and the pre-trained generator to initialize the generator of our model. Applying knowledge transfer leads to an alignment problem between the encoder and generator. We introduce an adaptor network to address this. On many-class image-to-image translation on three datasets (Animal faces, Birds, and Foods) we decrease mFID by at least 35% when compared to the state-of-the-art. Furthermore, we qualitatively and quantitatively demonstrate that transfer learning significantly improves the performance of I2I systems, especially for small datasets. Finally, we are the first to perform I2I translations for domains with over 100 classes.
Multimodal Unsupervised Image-to-Image Translation
Aug 14, 2018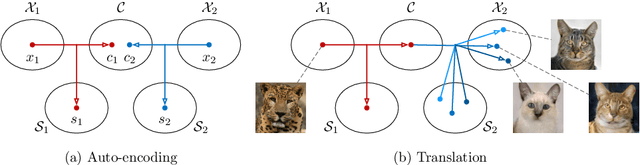
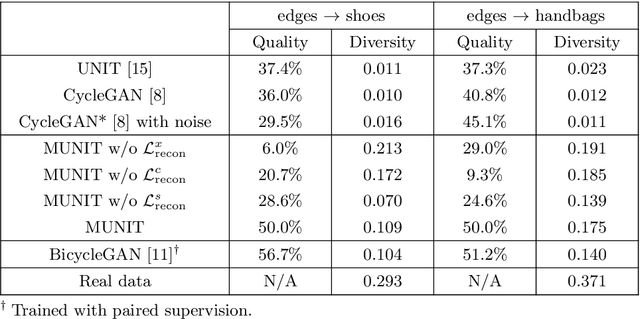
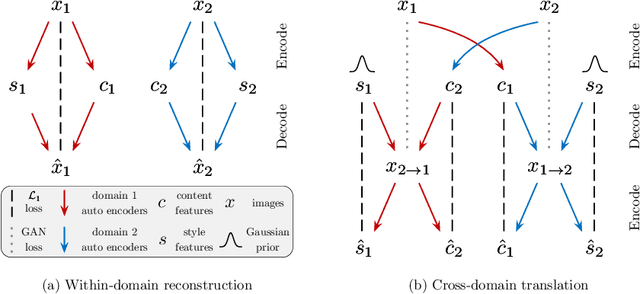
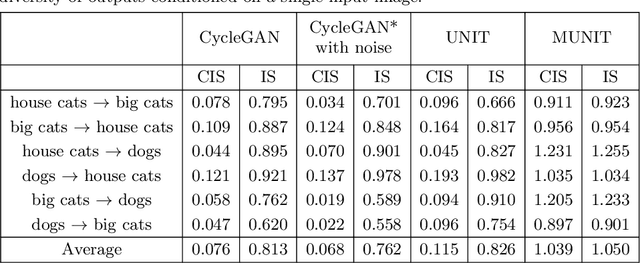
Unsupervised image-to-image translation is an important and challenging problem in computer vision. Given an image in the source domain, the goal is to learn the conditional distribution of corresponding images in the target domain, without seeing any pairs of corresponding images. While this conditional distribution is inherently multimodal, existing approaches make an overly simplified assumption, modeling it as a deterministic one-to-one mapping. As a result, they fail to generate diverse outputs from a given source domain image. To address this limitation, we propose a Multimodal Unsupervised Image-to-image Translation (MUNIT) framework. We assume that the image representation can be decomposed into a content code that is domain-invariant, and a style code that captures domain-specific properties. To translate an image to another domain, we recombine its content code with a random style code sampled from the style space of the target domain. We analyze the proposed framework and establish several theoretical results. Extensive experiments with comparisons to the state-of-the-art approaches further demonstrates the advantage of the proposed framework. Moreover, our framework allows users to control the style of translation outputs by providing an example style image. Code and pretrained models are available at https://github.com/nvlabs/MUNIT
Conditional Image-to-Image Translation
May 01, 2018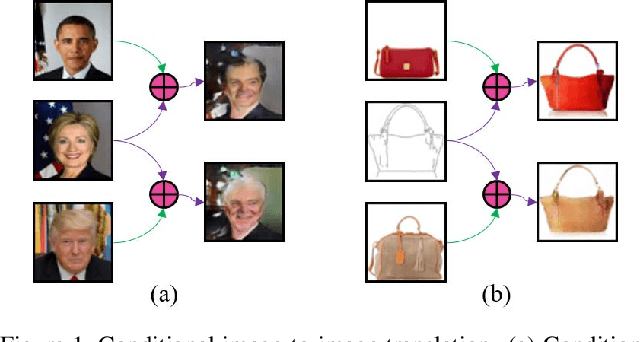
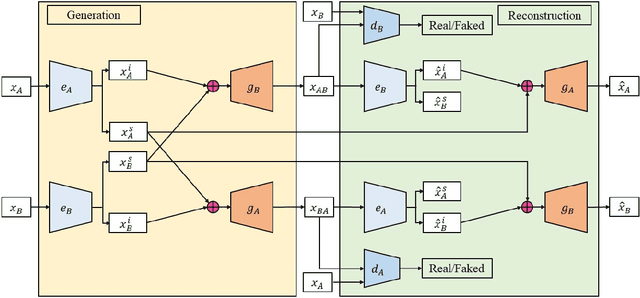


Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs) and dual learning. However, existing models lack the ability to control the translated results in the target domain and their results usually lack of diversity in the sense that a fixed image usually leads to (almost) deterministic translation result. In this paper, we study a new problem, conditional image-to-image translation, which is to translate an image from the source domain to the target domain conditioned on a given image in the target domain. It requires that the generated image should inherit some domain-specific features of the conditional image from the target domain. Therefore, changing the conditional image in the target domain will lead to diverse translation results for a fixed input image from the source domain, and therefore the conditional input image helps to control the translation results. We tackle this problem with unpaired data based on GANs and dual learning. We twist two conditional translation models (one translation from A domain to B domain, and the other one from B domain to A domain) together for inputs combination and reconstruction while preserving domain independent features. We carry out experiments on men's faces from-to women's faces translation and edges to shoes&bags translations. The results demonstrate the effectiveness of our proposed method.
Generating Embroidery Patterns Using Image-to-Image Translation
Mar 05, 2020

In many scenarios in computer vision, machine learning, and computer graphics, there is a requirement to learn the mapping from an image of one domain to an image of another domain, called Image-to-image translation. For example, style transfer, object transfiguration, visually altering the appearance of weather conditions in an image, changing the appearance of a day image into a night image or vice versa, photo enhancement, to name a few. In this paper, we propose two machine learning techniques to solve the embroidery image-to-image translation. Our goal is to generate a preview image which looks similar to an embroidered image, from a user-uploaded image. Our techniques are modifications of two existing techniques, neural style transfer, and cycle-consistent generative-adversarial network. Neural style transfer renders the semantic content of an image from one domain in the style of a different image in another domain, whereas a cycle-consistent generative adversarial network learns the mapping from an input image to output image without any paired training data, and also learn a loss function to train this mapping. Furthermore, the techniques we propose are independent of any embroidery attributes, such as elevation of the image, light-source, start, and endpoints of a stitch, type of stitch used, fabric type, etc. Given the user image, our techniques can generate a preview image which looks similar to an embroidered image. We train and test our propose techniques on an embroidery dataset which consist of simple 2D images. To do so, we prepare an unpaired embroidery dataset with more than 8000 user-uploaded images along with embroidered images. Empirical results show that these techniques successfully generate an approximate preview of an embroidered version of a user image, which can help users in decision making.
Flow-based Deformation Guidance for Unpaired Multi-Contrast MRI Image-to-Image Translation
Dec 03, 2020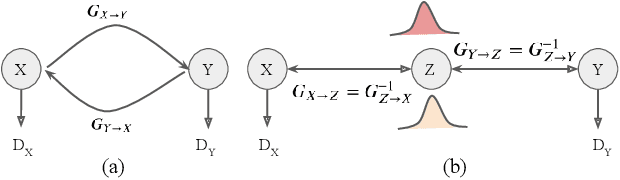
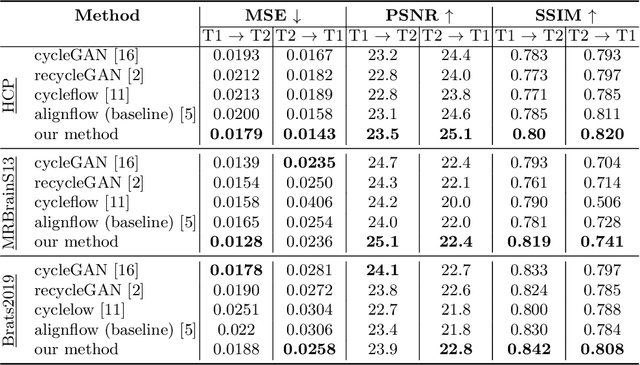
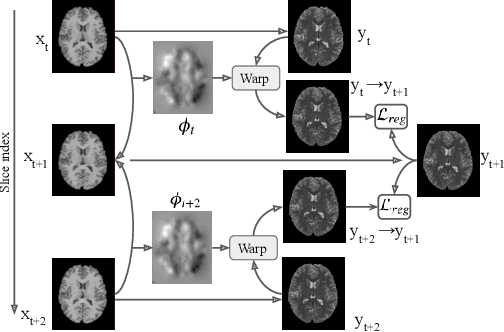
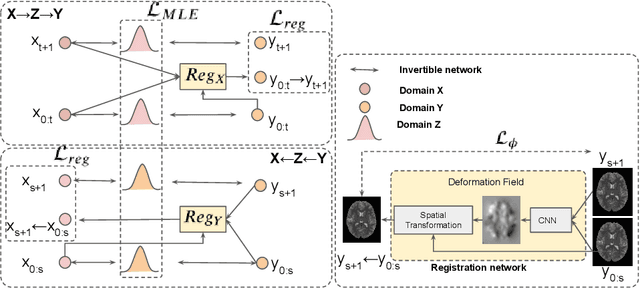
Image synthesis from corrupted contrasts increases the diversity of diagnostic information available for many neurological diseases. Recently the image-to-image translation has experienced significant levels of interest within medical research, beginning with the successful use of the Generative Adversarial Network (GAN) to the introduction of cyclic constraint extended to multiple domains. However, in current approaches, there is no guarantee that the mapping between the two image domains would be unique or one-to-one. In this paper, we introduce a novel approach to unpaired image-to-image translation based on the invertible architecture. The invertible property of the flow-based architecture assures a cycle-consistency of image-to-image translation without additional loss functions. We utilize the temporal information between consecutive slices to provide more constraints to the optimization for transforming one domain to another in unpaired volumetric medical images. To capture temporal structures in the medical images, we explore the displacement between the consecutive slices using a deformation field. In our approach, the deformation field is used as a guidance to keep the translated slides realistic and consistent across the translation. The experimental results have shown that the synthesized images using our proposed approach are able to archive a competitive performance in terms of mean squared error, peak signal-to-noise ratio, and structural similarity index when compared with the existing deep learning-based methods on three standard datasets, i.e. HCP, MRBrainS13, and Brats2019.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
Image-to-Image Translation of Synthetic Samples for Rare Classes
Jun 23, 2021
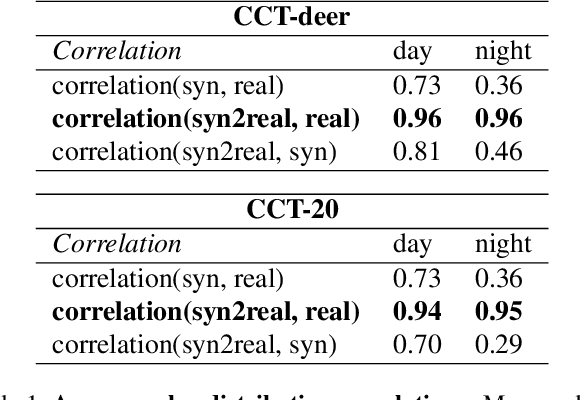
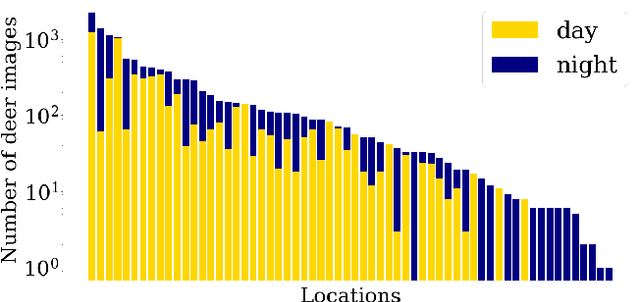
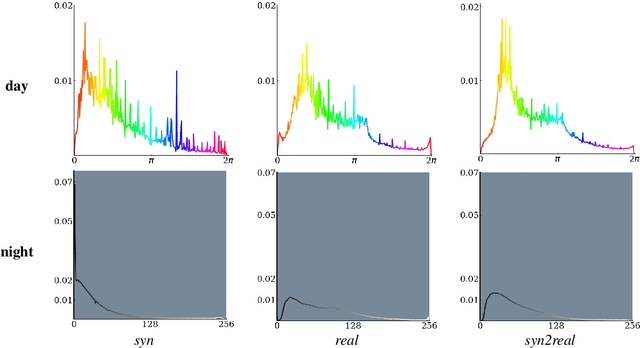
The natural world is long-tailed: rare classes are observed orders of magnitudes less frequently than common ones, leading to highly-imbalanced data where rare classes can have only handfuls of examples. Learning from few examples is a known challenge for deep learning based classification algorithms, and is the focus of the field of low-shot learning. One potential approach to increase the training data for these rare classes is to augment the limited real data with synthetic samples. This has been shown to help, but the domain shift between real and synthetic hinders the approaches' efficacy when tested on real data. We explore the use of image-to-image translation methods to close the domain gap between synthetic and real imagery for animal species classification in data collected from camera traps: motion-activated static cameras used to monitor wildlife. We use low-level feature alignment between source and target domains to make synthetic data for a rare species generated using a graphics engine more "realistic". Compared against a system augmented with unaligned synthetic data, our experiments show a considerable decrease in classification error rates on a rare species.