 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTX-2: Efficient Joint Audio-Visual Foundation Model
Jan 06, 2026Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.
LTX-Video: Realtime Video Latent Diffusion
Dec 30, 2024



We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer. Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality. At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the patchifying operation from the transformer's input to the VAE's input. Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency. However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space. This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously. It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale. The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation.
V-LASIK: Consistent Glasses-Removal from Videos Using Synthetic Data
Jun 20, 2024Diffusion-based generative models have recently shown remarkable image and video editing capabilities. However, local video editing, particularly removal of small attributes like glasses, remains a challenge. Existing methods either alter the videos excessively, generate unrealistic artifacts, or fail to perform the requested edit consistently throughout the video. In this work, we focus on consistent and identity-preserving removal of glasses in videos, using it as a case study for consistent local attribute removal in videos. Due to the lack of paired data, we adopt a weakly supervised approach and generate synthetic imperfect data, using an adjusted pretrained diffusion model. We show that despite data imperfection, by learning from our generated data and leveraging the prior of pretrained diffusion models, our model is able to perform the desired edit consistently while preserving the original video content. Furthermore, we exemplify the generalization ability of our method to other local video editing tasks by applying it successfully to facial sticker-removal. Our approach demonstrates significant improvement over existing methods, showcasing the potential of leveraging synthetic data and strong video priors for local video editing tasks.
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Jul 24, 2020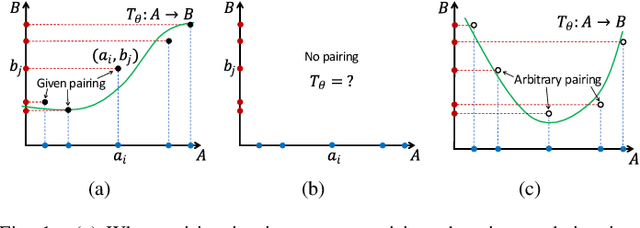



Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but we show that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. In this paper we introduce linear encoder-decoder architectures for unsupervised image to image translation. We show that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, we show a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.
A Bayes-Optimal View on Adversarial Examples
Feb 20, 2020
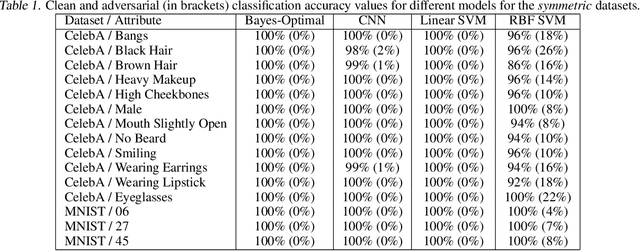

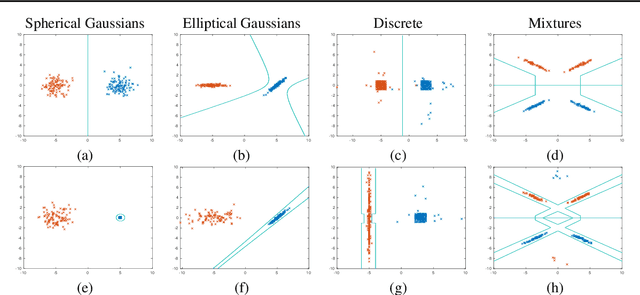
The ability to fool modern CNN classifiers with tiny perturbations of the input has lead to the development of a large number of candidate defenses and often conflicting explanations. In this paper, we argue for examining adversarial examples from the perspective of Bayes-Optimal classification. We construct realistic image datasets for which the Bayes-Optimal classifier can be efficiently computed and derive analytic conditions on the distributions so that the optimal classifier is either robust or vulnerable. By training different classifiers on these datasets (for which the "gold standard" optimal classifiers are known), we can disentangle the possible sources of vulnerability and avoid the accuracy-robustness tradeoff that may occur in commonly used datasets. Our results show that even when the optimal classifier is robust, standard CNN training consistently learns a vulnerable classifier. At the same time, for exactly the same training data, RBF SVMs consistently learn a robust classifier. The same trend is observed in experiments with real images.
On GANs and GMMs
Nov 03, 2018
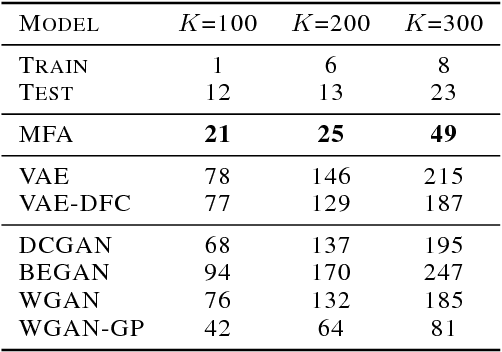
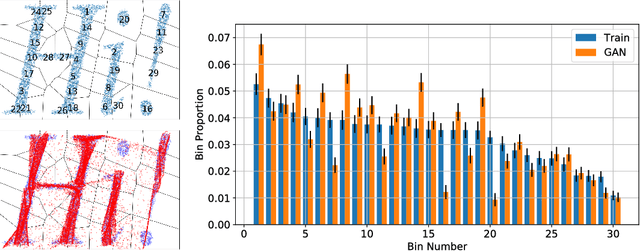

A longstanding problem in machine learning is to find unsupervised methods that can learn the statistical structure of high dimensional signals. In recent years, GANs have gained much attention as a possible solution to the problem, and in particular have shown the ability to generate remarkably realistic high resolution sampled images. At the same time, many authors have pointed out that GANs may fail to model the full distribution ("mode collapse") and that using the learned models for anything other than generating samples may be very difficult. In this paper, we examine the utility of GANs in learning statistical models of images by comparing them to perhaps the simplest statistical model, the Gaussian Mixture Model. First, we present a simple method to evaluate generative models based on relative proportions of samples that fall into predetermined bins. Unlike previous automatic methods for evaluating models, our method does not rely on an additional neural network nor does it require approximating intractable computations. Second, we compare the performance of GANs to GMMs trained on the same datasets. While GMMs have previously been shown to be successful in modeling small patches of images, we show how to train them on full sized images despite the high dimensionality. Our results show that GMMs can generate realistic samples (although less sharp than those of GANs) but also capture the full distribution, which GANs fail to do. Furthermore, GMMs allow efficient inference and explicit representation of the underlying statistical structure. Finally, we discuss how GMMs can be used to generate sharp images.