 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Budget Allocation for Adaptive Test-Time Reasoning
May 26, 2026Sampling multiple responses improves language model reasoning, but uniform compute allocation is inefficient: easy questions are over-sampled while hard questions remain under-explored. We propose Uncertainty-Aware Budget Allocation (UAB), a concave integer optimization framework that reallocates a fixed sampling budget based on per-question uncertainty estimated at no additional inference cost. In Phase 1, every question receives one generation; its average negative log-likelihood (ANLL), extracted directly from output log-probabilities, serves as a difficulty signal while the generation contributes to the final vote. In Phase 2, the remaining budget is allocated by a marginal-greedy algorithm that solves a concave coverage-maximization surrogate exactly: uncertain questions receive more sampling budget while confident questions receive fewer additional samples. Evaluated on six open-weight and black-box models spanning 1.5B to 27B parameters and five reasoning benchmarks covering math, logic, and preference tasks, UAB outperforms baselines by up to +3% in average accuracy and up to +5% on individual benchmarks, with the largest gains in low-resource settings, requiring no auxiliary model or additional LLM call. Code is publicly available at https://github.com/manhitv/UAB.
Beyond Majority Voting: Efficient Best-Of-N with Radial Consensus Score
Apr 14, 2026Large language models (LLMs) frequently generate multiple candidate responses for a given prompt, yet selecting the most reliable one remains challenging, especially when correctness diverges from surface-level majority agreement. Existing approaches, such as self-consistency, rely on discrete voting, while probability-based methods often fail to capture relationships among candidate answers or tend to underweight high-quality but less frequent responses, and do not fully leverage the geometric structure of answer representations. To address these limitations, we introduce Radial Consensus Score (RCS), a simple, efficient, and training-free method for best-of-N selection. RCS models semantic consensus by computing a weighted Fréchet mean (semantic center) of answer embeddings and ranking candidates by their radial distance to this center. Importantly, RCS provides a general framework that supports multiple weighting schemes, including uniform, frequency-based, and probability-based variants, enabling flexible integration of agreement signals and model confidence while remaining fully applicable in black-box settings. Extensive experiments across seven benchmarks covering short-form QA and long-form reasoning tasks, and five open-weight models, demonstrate that RCS variants consistently outperform strong baselines, with gains becoming more pronounced as the sampling budget increases. RCS also serves as an effective drop-in replacement for majority voting in multi-agent debate and exhibits strong robustness in black-box scenarios. Overall, these results highlight geometric consensus as a scalable and broadly applicable principle for reliable answer selection, extending beyond majority voting to more expressive and robust aggregation in LLM inference.
Hear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention
Mar 21, 2026Multi-Agent Debate has emerged as a promising framework for improving the reasoning quality of large language models through iterative inter-agent communication. However, broadcasting all agent messages at every round introduces noise and redundancy that can degrade debate quality and waste computational resources. Current approaches rely on uncertainty estimation to filter low-confidence responses before broadcasting, but this approach is unreliable due to miscalibrated confidence scores and sensitivity to threshold selection. To address this, we propose Diversity-Aware Retention (DAR), a lightweight debate framework that, at each debate round, selects the subset of agent responses that maximally disagree with each other and with the majority vote before broadcasting. Through an explicit index-based retention mechanism, DAR preserves the original messages without modification, ensuring that retained disagreements remain authentic. Experiments on diverse reasoning and question answering benchmarks demonstrate that our selective message propagation consistently improves debate performance, particularly as the number of agents scales, where noise accumulation is most severe. Our results highlight that what agents hear is as important as what agents say in multi-agent reasoning systems.
Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of Large Language Models
Nov 13, 2025



Reinforcement learning (RL) finetuning is crucial to aligning large language models (LLMs), but the process is notoriously unstable and exhibits high variance across model checkpoints. In practice, selecting the best checkpoint is challenging: evaluating checkpoints on the validation set during training is computationally expensive and requires a good validation set, while relying on the final checkpoint provides no guarantee of good performance. We introduce an uncertainty-guided approach for checkpoint selection (UGCS) that avoids these pitfalls. Our method identifies hard question-answer pairs using per-sample uncertainty and ranks checkpoints by how well they handle these challenging cases. By averaging the rewards of the top-uncertain samples over a short training window, our method produces a stable and discriminative signal without additional forward passes or significant computation overhead. Experiments across three datasets and three LLMs demonstrate that it consistently identifies checkpoints with stronger generalization, outperforming traditional strategies such as relying on training or validation performance. These results highlight that models solving their hardest tasks with low uncertainty are the most reliable overall.
Probabilities Are All You Need: A Probability-Only Approach to Uncertainty Estimation in Large Language Models
Nov 10, 2025



Large Language Models (LLMs) exhibit strong performance across various natural language processing (NLP) tasks but remain vulnerable to hallucinations, generating factually incorrect or misleading outputs. Uncertainty estimation, often using predictive entropy estimation, is key to addressing this issue. However, existing methods often require multiple samples or extra computation to assess semantic entropy. This paper proposes an efficient, training-free uncertainty estimation method that approximates predictive entropy using the responses' top-$K$ probabilities. Moreover, we employ an adaptive mechanism to determine $K$ to enhance flexibility and filter out low-confidence probabilities. Experimental results on three free-form question-answering datasets across several LLMs demonstrate that our method outperforms expensive state-of-the-art baselines, contributing to the broader goal of enhancing LLM trustworthiness.
GRAD: Graph-Retrieved Adaptive Decoding for Hallucination Mitigation
Nov 05, 2025Hallucination mitigation remains a persistent challenge for large language models (LLMs), even as model scales grow. Existing approaches often rely on external knowledge sources, such as structured databases or knowledge graphs, accessed through prompting or retrieval. However, prompt-based grounding is fragile and domain-sensitive, while symbolic knowledge integration incurs heavy retrieval and formatting costs. Motivated by knowledge graphs, we introduce Graph-Retrieved Adaptive Decoding (GRAD), a decoding-time method that grounds generation in corpus-derived evidence without retraining. GRAD constructs a sparse token transition graph by accumulating next-token logits across a small retrieved corpus in a single forward pass. During decoding, graph-retrieved logits are max-normalized and adaptively fused with model logits to favor high-evidence continuations while preserving fluency. Across three models and a range of question-answering benchmarks spanning intrinsic, extrinsic hallucination, and factuality tasks, GRAD consistently surpasses baselines, achieving up to 9.7$\%$ higher intrinsic accuracy, 8.6$\%$ lower hallucination rates, and 6.9$\%$ greater correctness compared to greedy decoding, while attaining the highest truth--informativeness product score among all methods. GRAD offers a lightweight, plug-and-play alternative to contrastive decoding and knowledge graph augmentation, demonstrating that statistical evidence from corpus-level token transitions can effectively steer generation toward more truthful and verifiable outputs.
SPaRFT: Self-Paced Reinforcement Fine-Tuning for Large Language Models
Aug 07, 2025Large language models (LLMs) have shown strong reasoning capabilities when fine-tuned with reinforcement learning (RL). However, such methods require extensive data and compute, making them impractical for smaller models. Current approaches to curriculum learning or data selection are largely heuristic-driven or demand extensive computational resources, limiting their scalability and generalizability. We propose \textbf{SPaRFT}, a self-paced learning framework that enables efficient learning based on the capability of the model being trained through optimizing which data to use and when. First, we apply \emph{cluster-based data reduction} to partition training data by semantics and difficulty, extracting a compact yet diverse subset that reduces redundancy. Then, a \emph{multi-armed bandit} treats data clusters as arms, optimized to allocate training samples based on model current performance. Experiments across multiple reasoning benchmarks show that SPaRFT achieves comparable or better accuracy than state-of-the-art baselines while using up to \(100\times\) fewer samples. Ablation studies and analyses further highlight the importance of both data clustering and adaptive selection. Our results demonstrate that carefully curated, performance-driven training curricula can unlock strong reasoning abilities in LLMs with minimal resources.
Flow-based Deformation Guidance for Unpaired Multi-Contrast MRI Image-to-Image Translation
Dec 03, 2020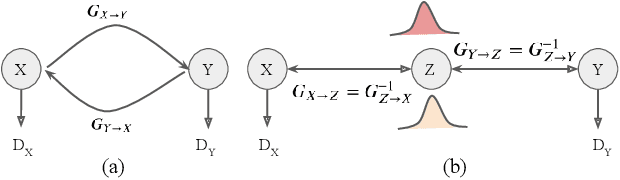
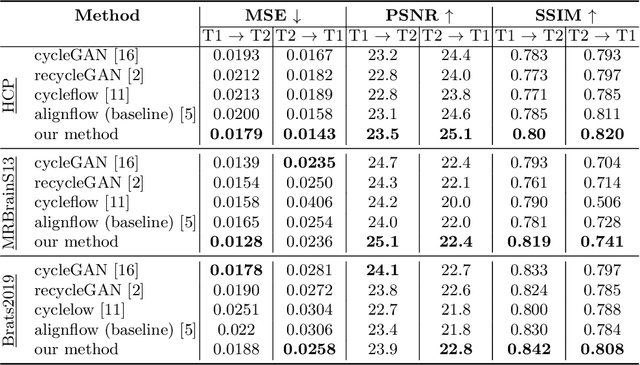
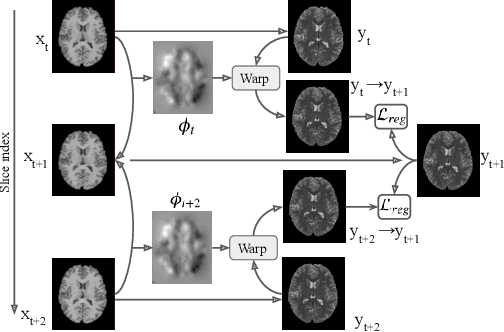
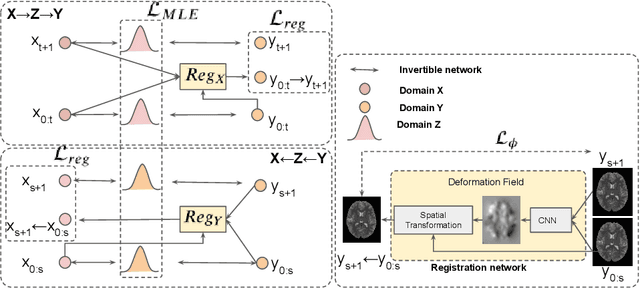
Image synthesis from corrupted contrasts increases the diversity of diagnostic information available for many neurological diseases. Recently the image-to-image translation has experienced significant levels of interest within medical research, beginning with the successful use of the Generative Adversarial Network (GAN) to the introduction of cyclic constraint extended to multiple domains. However, in current approaches, there is no guarantee that the mapping between the two image domains would be unique or one-to-one. In this paper, we introduce a novel approach to unpaired image-to-image translation based on the invertible architecture. The invertible property of the flow-based architecture assures a cycle-consistency of image-to-image translation without additional loss functions. We utilize the temporal information between consecutive slices to provide more constraints to the optimization for transforming one domain to another in unpaired volumetric medical images. To capture temporal structures in the medical images, we explore the displacement between the consecutive slices using a deformation field. In our approach, the deformation field is used as a guidance to keep the translated slides realistic and consistent across the translation. The experimental results have shown that the synthesized images using our proposed approach are able to archive a competitive performance in terms of mean squared error, peak signal-to-noise ratio, and structural similarity index when compared with the existing deep learning-based methods on three standard datasets, i.e. HCP, MRBrainS13, and Brats2019.