 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
TalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling
Oct 02, 2025While the recent developments in large language models (LLMs) have successfully enabled generative recommenders with natural language interactions, their recommendation behavior is limited, leaving other simpler yet crucial components such as metadata or attribute filtering underutilized in the system. We propose an LLM-based music recommendation system with tool calling to serve as a unified retrieval-reranking pipeline. Our system positions an LLM as an end-to-end recommendation system that interprets user intent, plans tool invocations, and orchestrates specialized components: boolean filters (SQL), sparse retrieval (BM25), dense retrieval (embedding similarity), and generative retrieval (semantic IDs). Through tool planning, the system predicts which types of tools to use, their execution order, and the arguments needed to find music matching user preferences, supporting diverse modalities while seamlessly integrating multiple database filtering methods. We demonstrate that this unified tool-calling framework achieves competitive performance across diverse recommendation scenarios by selectively employing appropriate retrieval methods based on user queries, envisioning a new paradigm for conversational music recommendation systems.
CompLex: Music Theory Lexicon Constructed by Autonomous Agents for Automatic Music Generation
Aug 27, 2025Generative artificial intelligence in music has made significant strides, yet it still falls short of the substantial achievements seen in natural language processing, primarily due to the limited availability of music data. Knowledge-informed approaches have been shown to enhance the performance of music generation models, even when only a few pieces of musical knowledge are integrated. This paper seeks to leverage comprehensive music theory in AI-driven music generation tasks, such as algorithmic composition and style transfer, which traditionally require significant manual effort with existing techniques. We introduce a novel automatic music lexicon construction model that generates a lexicon, named CompLex, comprising 37,432 items derived from just 9 manually input category keywords and 5 sentence prompt templates. A new multi-agent algorithm is proposed to automatically detect and mitigate hallucinations. CompLex demonstrates impressive performance improvements across three state-of-the-art text-to-music generation models, encompassing both symbolic and audio-based methods. Furthermore, we evaluate CompLex in terms of completeness, accuracy, non-redundancy, and executability, confirming that it possesses the key characteristics of an effective lexicon.
Continuous Audio Language Models
Sep 09, 2025Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart. Experiments on speech and music demonstrate improved efficiency and fidelity over state-of-the-art discrete audio language models, facilitating lightweight, high-quality audio generation. Samples are available at hf.co/spaces/kyutai/calm-samples
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025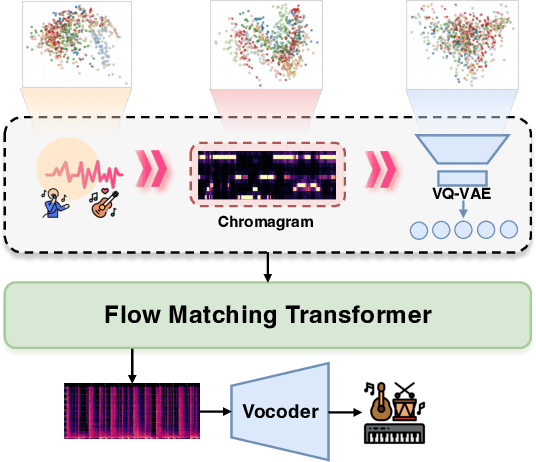
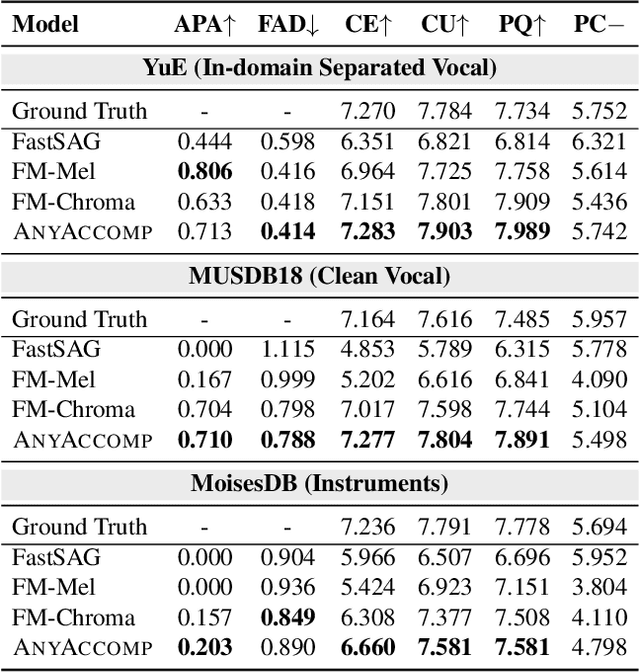
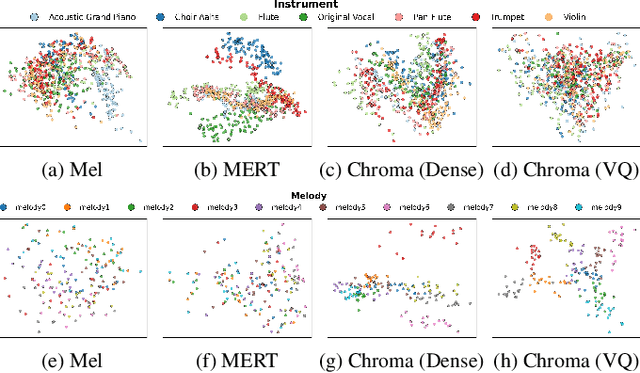
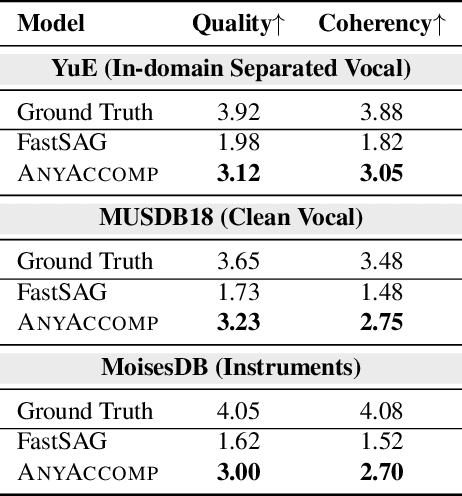
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Oct 16, 2025Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and unreliable. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking accuracy, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a general foundation for vision-language-action humanoid systems.
Jamendo-QA: A Large-Scale Music Question Answering Dataset
Sep 19, 2025We introduce Jamendo-QA, a large-scale dataset for Music Question Answering (Music-QA). The dataset is built on freely licensed tracks from the Jamendo platform and is automatically annotated using the Qwen-Omni model. Jamendo-QA provides question-answer pairs and captions aligned with music audio, enabling both supervised training and zero-shot evaluation. Our resource aims to fill the gap of music-specific QA datasets and foster further research in music understanding, retrieval, and generative applications. In addition to its scale, Jamendo-QA covers a diverse range of genres, instruments, and metadata attributes, allowing robust model benchmarking across varied musical contexts. We also provide detailed dataset statistics and highlight potential biases such as genre and gender imbalance to guide fair evaluation. We position Jamendo-QA as a scalable and publicly available benchmark that can facilitate future research in music understanding, multimodal modeling, and fair evaluation of music-oriented QA systems.
Real-world Music Plagiarism Detection With Music Segment Transcription System
Sep 10, 2025As a result of continuous advances in Music Information Retrieval (MIR) technology, generating and distributing music has become more diverse and accessible. In this context, interest in music intellectual property protection is increasing to safeguard individual music copyrights. In this work, we propose a system for detecting music plagiarism by combining various MIR technologies. We developed a music segment transcription system that extracts musically meaningful segments from audio recordings to detect plagiarism across different musical formats. With this system, we compute similarity scores based on multiple musical features that can be evaluated through comprehensive musical analysis. Our approach demonstrated promising results in music plagiarism detection experiments, and the proposed method can be applied to real-world music scenarios. We also collected a Similar Music Pair (SMP) dataset for musical similarity research using real-world cases. The dataset are publicly available.
Video Object Segmentation-Aware Audio Generation
Sep 30, 2025



Existing multimodal audio generation models often lack precise user control, which limits their applicability in professional Foley workflows. In particular, these models focus on the entire video and do not provide precise methods for prioritizing a specific object within a scene, generating unnecessary background sounds, or focusing on the wrong objects. To address this gap, we introduce the novel task of video object segmentation-aware audio generation, which explicitly conditions sound synthesis on object-level segmentation maps. We present SAGANet, a new multimodal generative model that enables controllable audio generation by leveraging visual segmentation masks along with video and textual cues. Our model provides users with fine-grained and visually localized control over audio generation. To support this task and further research on segmentation-aware Foley, we propose Segmented Music Solos, a benchmark dataset of musical instrument performance videos with segmentation information. Our method demonstrates substantial improvements over current state-of-the-art methods and sets a new standard for controllable, high-fidelity Foley synthesis. Code, samples, and Segmented Music Solos are available at https://saganet.notion.site
Amadeus: Autoregressive Model with Bidirectional Attribute Modelling for Symbolic Music
Aug 28, 2025Existing state-of-the-art symbolic music generation models predominantly adopt autoregressive or hierarchical autoregressive architectures, modelling symbolic music as a sequence of attribute tokens with unidirectional temporal dependencies, under the assumption of a fixed, strict dependency structure among these attributes. However, we observe that using different attributes as the initial token in these models leads to comparable performance. This suggests that the attributes of a musical note are, in essence, a concurrent and unordered set, rather than a temporally dependent sequence. Based on this insight, we introduce Amadeus, a novel symbolic music generation framework. Amadeus adopts a two-level architecture: an autoregressive model for note sequences and a bidirectional discrete diffusion model for attributes. To enhance performance, we propose Music Latent Space Discriminability Enhancement Strategy(MLSDES), incorporating contrastive learning constraints that amplify discriminability of intermediate music representations. The Conditional Information Enhancement Module (CIEM) simultaneously strengthens note latent vector representation via attention mechanisms, enabling more precise note decoding. We conduct extensive experiments on unconditional and text-conditioned generation tasks. Amadeus significantly outperforms SOTA models across multiple metrics while achieving at least 4$\times$ speed-up. Furthermore, we demonstrate training-free, fine-grained note attribute control feasibility using our model. To explore the upper performance bound of the Amadeus architecture, we compile the largest open-source symbolic music dataset to date, AMD (Amadeus MIDI Dataset), supporting both pre-training and fine-tuning.
ACMID: Automatic Curation of Musical Instrument Dataset for 7-Stem Music Source Separation
Oct 09, 2025Most current music source separation (MSS) methods rely on supervised learning, limited by training data quan- tity and quality. Though web-crawling can bring abundant data, platform-level track labeling often causes metadata mismatches, impeding accurate "audio-label" pair acquisi- tion. To address this, we present ACMID: a dataset for MSS generated through web crawling of extensive raw data, fol- lowed by automatic cleaning via an instrument classifier built on a pre-trained audio encoder that filters and aggregates clean segments of target instruments from the crawled tracks, resulting in the refined ACMID-Cleaned dataset. Leverag- ing abundant data, we expand the conventional classifica- tion from 4-stem (Vocal/Bass/Drums/Others) to 7-stem (Pi- ano/Drums/Bass/Acoustic Guitar/Electric Guitar/Strings/Wind- Brass), enabling high granularity MSS systems. Experiments on SOTA MSS model demonstrates two key results: (i) MSS model trained with ACMID-Cleaned achieved a 2.39dB improvement in SDR performance compared to that with ACMID-Uncleaned, demostrating the effectiveness of our data cleaning procedure; (ii) incorporating ACMID-Cleaned to training enhances MSS model's average performance by 1.16dB, confirming the value of our dataset. Our data crawl- ing code, cleaning model code and weights are available at: https://github.com/scottishfold0621/ACMID.