 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness Metrics Don't Measure Faithfulness: A Meta-Evaluation with Ground Truth
May 24, 2026Chains of thought (CoTs) have become central in interpreting and auditing behaviors of large language models. Yet growing evidence suggests that these traces often fail to faithfully represent the computations behind a model's predictions. Several faithfulness metrics have been proposed, but whether they indeed measure faithfulness remains unknown. Answering this requires ground-truth labels, which are hard to obtain since internal computations are not directly observable. Consequently, most works proposing metrics report only absolute scores or comparisons to prior metrics, and the few existing benchmarks rely on proxies like plausibility or importance, properties orthogonal to faithfulness that can mislead about whether a CoT can be trusted. We address this challenge by constructing tasks whose outputs reveal which intermediate computations must have produced them, and developing an automated labeling pipeline that yields ground-truth faithfulness labels at both the step and CoT level. Building on this methodology, we present BonaFide, a benchmark of 3,066 labeled CoTs across 13 tasks and 10 models, and use it to conduct the first systematic evaluation of prominent faithfulness metrics. Our experiments show that most metrics perform near chance, exhibit strong prediction biases and degrade on longer CoTs. The best metric reaches only 0.70 AUROC at the CoT level while another reaches 0.59 at the step level, with neither transferring across settings, while entailing prohibitively high computational cost. Our results expose fundamental gaps in current faithfulness evaluation and call for the development of more reliable and efficient metrics.
Teaching People LLM's Errors and Getting it Right
Dec 24, 2025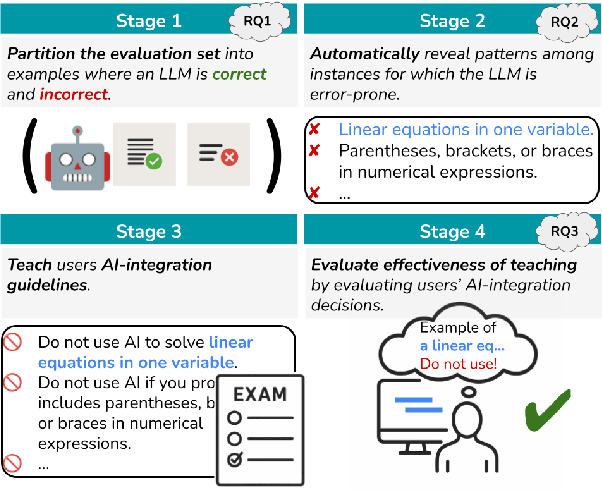
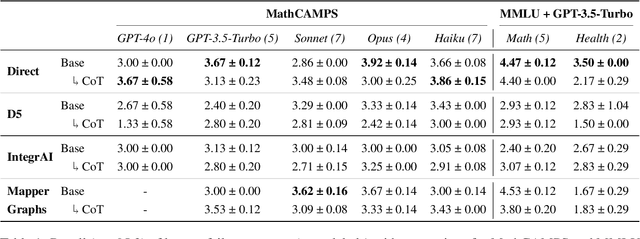
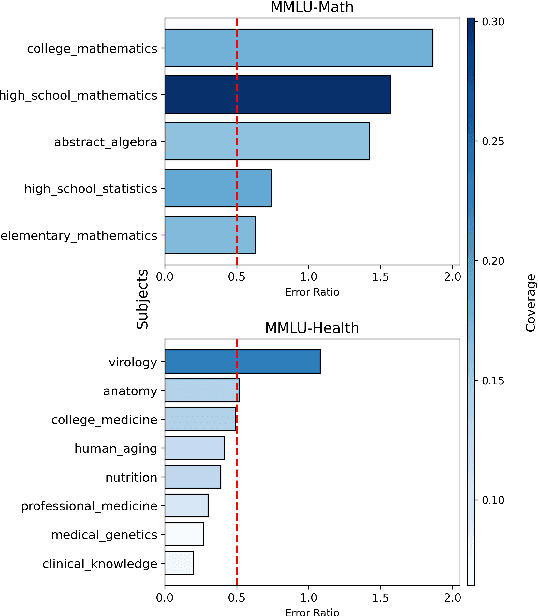
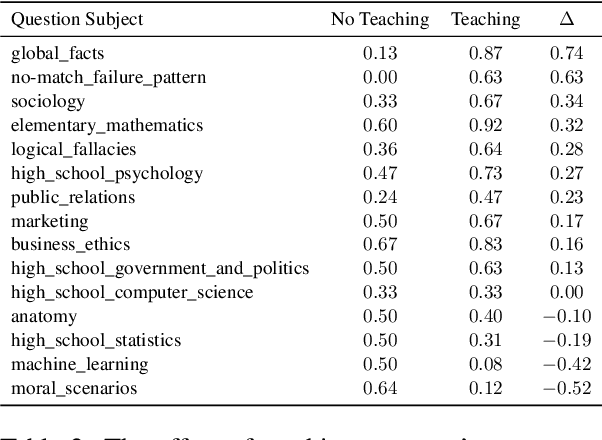
People use large language models (LLMs) when they should not. This is partly because they see LLMs compose poems and answer intricate questions, so they understandably, but incorrectly, assume LLMs won't stumble on basic tasks like simple arithmetic. Prior work has tried to address this by clustering instance embeddings into regions where an LLM is likely to fail and automatically describing patterns in these regions. The found failure patterns are taught to users to mitigate their overreliance. Yet, this approach has not fully succeeded. In this analysis paper, we aim to understand why. We first examine whether the negative result stems from the absence of failure patterns. We group instances in two datasets by their meta-labels and evaluate an LLM's predictions on these groups. We then define criteria to flag groups that are sizable and where the LLM is error-prone, and find meta-label groups that meet these criteria. Their meta-labels are the LLM's failure patterns that could be taught to users, so they do exist. We next test whether prompting and embedding-based approaches can surface these known failures. Without this, users cannot be taught about them to reduce their overreliance. We find mixed results across methods, which could explain the negative result. Finally, we revisit the final metric that measures teaching effectiveness. We propose to assess a user's ability to effectively use the given failure patterns to anticipate when an LLM is error-prone. A user study shows a positive effect from teaching with this metric, unlike the human-AI team accuracy. Our findings show that teaching failure patterns could be a viable approach to mitigating overreliance, but success depends on better automated failure-discovery methods and using metrics like ours.
MixAssist: An Audio-Language Dataset for Co-Creative AI Assistance in Music Mixing
Jul 08, 2025While AI presents significant potential for enhancing music mixing and mastering workflows, current research predominantly emphasizes end-to-end automation or generation, often overlooking the collaborative and instructional dimensions vital for co-creative processes. This gap leaves artists, particularly amateurs seeking to develop expertise, underserved. To bridge this, we introduce MixAssist, a novel audio-language dataset capturing the situated, multi-turn dialogue between expert and amateur music producers during collaborative mixing sessions. Comprising 431 audio-grounded conversational turns derived from 7 in-depth sessions involving 12 producers, MixAssist provides a unique resource for training and evaluating audio-language models that can comprehend and respond to the complexities of real-world music production dialogues. Our evaluations, including automated LLM-as-a-judge assessments and human expert comparisons, demonstrate that fine-tuning models such as Qwen-Audio on MixAssist can yield promising results, with Qwen significantly outperforming other tested models in generating helpful, contextually relevant mixing advice. By focusing on co-creative instruction grounded in audio context, MixAssist enables the development of intelligent AI assistants designed to support and augment the creative process in music mixing.
BriefMe: A Legal NLP Benchmark for Assisting with Legal Briefs
Jun 07, 2025A core part of legal work that has been under-explored in Legal NLP is the writing and editing of legal briefs. This requires not only a thorough understanding of the law of a jurisdiction, from judgments to statutes, but also the ability to make new arguments to try to expand the law in a new direction and make novel and creative arguments that are persuasive to judges. To capture and evaluate these legal skills in language models, we introduce BRIEFME, a new dataset focused on legal briefs. It contains three tasks for language models to assist legal professionals in writing briefs: argument summarization, argument completion, and case retrieval. In this work, we describe the creation of these tasks, analyze them, and show how current models perform. We see that today's large language models (LLMs) are already quite good at the summarization and guided completion tasks, even beating human-generated headings. Yet, they perform poorly on other tasks in our benchmark: realistic argument completion and retrieving relevant legal cases. We hope this dataset encourages more development in Legal NLP in ways that will specifically aid people in performing legal work.
What Has Been Lost with Synthetic Evaluation?
May 28, 2025Large language models (LLMs) are increasingly used for data generation. However, creating evaluation benchmarks raises the bar for this emerging paradigm. Benchmarks must target specific phenomena, penalize exploiting shortcuts, and be challenging. Through two case studies, we investigate whether LLMs can meet these demands by generating reasoning over-text benchmarks and comparing them to those created through careful crowdsourcing. Specifically, we evaluate both the validity and difficulty of LLM-generated versions of two high-quality reading comprehension datasets: CondaQA, which evaluates reasoning about negation, and DROP, which targets reasoning about quantities. We find that prompting LLMs can produce variants of these datasets that are often valid according to the annotation guidelines, at a fraction of the cost of the original crowdsourcing effort. However, we show that they are less challenging for LLMs than their human-authored counterparts. This finding sheds light on what may have been lost by generating evaluation data with LLMs, and calls for critically reassessing the immediate use of this increasingly prevalent approach to benchmark creation.
Measuring Faithfulness of Chains of Thought by Unlearning Reasoning Steps
Feb 20, 2025When prompted to think step-by-step, language models (LMs) produce a chain of thought (CoT), a sequence of reasoning steps that the model supposedly used to produce its prediction. However, despite much work on CoT prompting, it is unclear if CoT reasoning is faithful to the models' parameteric beliefs. We introduce a framework for measuring parametric faithfulness of generated reasoning, and propose Faithfulness by Unlearning Reasoning steps (FUR), an instance of this framework. FUR erases information contained in reasoning steps from model parameters. We perform experiments unlearning CoTs of four LMs prompted on four multi-choice question answering (MCQA) datasets. Our experiments show that FUR is frequently able to change the underlying models' prediction by unlearning key steps, indicating when a CoT is parametrically faithful. Further analysis shows that CoTs generated by models post-unlearning support different answers, hinting at a deeper effect of unlearning. Importantly, CoT steps identified as important by FUR do not align well with human notions of plausbility, emphasizing the need for specialized alignment
On Evaluating Explanation Utility for Human-AI Decision Making in NLP
Jul 03, 2024Is explainability a false promise? This debate has emerged from the insufficient evidence that explanations aid people in situations they are introduced for. More human-centered, application-grounded evaluations of explanations are needed to settle this. Yet, with no established guidelines for such studies in NLP, researchers accustomed to standardized proxy evaluations must discover appropriate measurements, tasks, datasets, and sensible models for human-AI teams in their studies. To help with this, we first review fitting existing metrics. We then establish requirements for datasets to be suitable for application-grounded evaluations. Among over 50 datasets available for explainability research in NLP, we find that 4 meet our criteria. By finetuning Flan-T5-3B, we demonstrate the importance of reassessing the state of the art to form and study human-AI teams. Finally, we present the exemplar studies of human-AI decision-making for one of the identified suitable tasks -- verifying the correctness of a legal claim given a contract.
Chain-of-Thought Unfaithfulness as Disguised Accuracy
Feb 22, 2024



Understanding the extent to which Chain-of-Thought (CoT) generations align with a large language model's (LLM) internal computations is critical for deciding whether to trust an LLM's output. As a proxy for CoT faithfulness, arXiv:2307.13702 propose a metric that measures a model's dependence on its CoT for producing an answer. Within a single family of proprietary models, they find that LLMs exhibit a scaling-then-inverse-scaling relationship between model size and their measure of faithfulness, and that a 13 billion parameter model exhibits increased faithfulness compared to models ranging from 810 million to 175 billion parameters in size. We evaluate whether these results generalize as a property of all LLMs. We replicate their experimental setup with three different families of models and, under specific conditions, successfully reproduce the scaling trends for CoT faithfulness they report. However, we discover that simply changing the order of answer choices in the prompt can reduce the metric by 73 percentage points. The faithfulness metric is also highly correlated ($R^2$ = 0.91) with accuracy, raising doubts about its validity as a construct for evaluating faithfulness.
Whispers of Doubt Amidst Echoes of Triumph in NLP Robustness
Nov 16, 2023Are the longstanding robustness issues in NLP resolved by today's larger and more performant models? To address this question, we conduct a thorough investigation using 19 models of different sizes spanning different architectural choices and pretraining objectives. We conduct evaluations using (a) OOD and challenge test sets, (b) CheckLists, (c) contrast sets, and (d) adversarial inputs. Our analysis reveals that not all OOD tests provide further insight into robustness. Evaluating with CheckLists and contrast sets shows significant gaps in model performance; merely scaling models does not make them sufficiently robust. Finally, we point out that current approaches for adversarial evaluations of models are themselves problematic: they can be easily thwarted, and in their current forms, do not represent a sufficiently deep probe of model robustness. We conclude that not only is the question of robustness in NLP as yet unresolved, but even some of the approaches to measure robustness need to be reassessed.
How Much Consistency Is Your Accuracy Worth?
Oct 20, 2023



Contrast set consistency is a robustness measurement that evaluates the rate at which a model correctly responds to all instances in a bundle of minimally different examples relying on the same knowledge. To draw additional insights, we propose to complement consistency with relative consistency -- the probability that an equally accurate model would surpass the consistency of the proposed model, given a distribution over possible consistencies. Models with 100% relative consistency have reached a consistency peak for their accuracy. We reflect on prior work that reports consistency in contrast sets and observe that relative consistency can alter the assessment of a model's consistency compared to another. We anticipate that our proposed measurement and insights will influence future studies aiming to promote consistent behavior in models.