 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
Cycle Generative Adversarial Networks Algorithm With Style Transfer For Image Generation
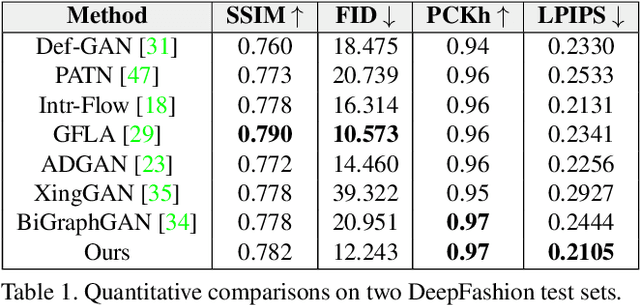
Jan 11, 2021The biggest challenge faced by a Machine Learning Engineer is the lack of data they have, especially for 2-dimensional images. The image is processed to be trained into a Machine Learning model so that it can recognize patterns in the data and provide predictions. This research is intended to create a solution using the Cycle Generative Adversarial Networks (GANs) algorithm in overcoming the problem of lack of data. Then use Style Transfer to be able to generate a new image based on the given style. Based on the results of testing the resulting model has been carried out several improvements, previously the loss value of the photo generator: 3.1267, monet style generator: 3.2026, photo discriminator: 0.6325, and monet style discriminator: 0.6931 to photo generator: 2.3792, monet style generator: 2.7291, photo discriminator: 0.5956, and monet style discriminator: 0.4940. It is hoped that the research will make the application of this solution useful in the fields of Education, Arts, Information Technology, Medicine, Astronomy, Automotive and other important fields.
Style and Pose Control for Image Synthesis of Humans from a Single Monocular View
Feb 22, 2021
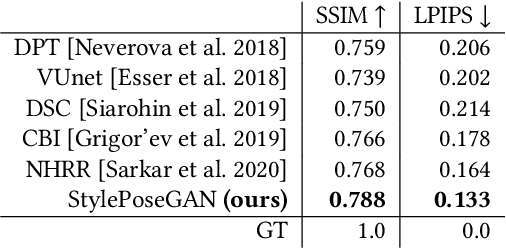


Photo-realistic re-rendering of a human from a single image with explicit control over body pose, shape and appearance enables a wide range of applications, such as human appearance transfer, virtual try-on, motion imitation, and novel view synthesis. While significant progress has been made in this direction using learning-based image generation tools, such as GANs, existing approaches yield noticeable artefacts such as blurring of fine details, unrealistic distortions of the body parts and garments as well as severe changes of the textures. We, therefore, propose a new method for synthesising photo-realistic human images with explicit control over pose and part-based appearance, i.e., StylePoseGAN, where we extend a non-controllable generator to accept conditioning of pose and appearance separately. Our network can be trained in a fully supervised way with human images to disentangle pose, appearance and body parts, and it significantly outperforms existing single image re-rendering methods. Our disentangled representation opens up further applications such as garment transfer, motion transfer, virtual try-on, head (identity) swap and appearance interpolation. StylePoseGAN achieves state-of-the-art image generation fidelity on common perceptual metrics compared to the current best-performing methods and convinces in a comprehensive user study.
Salienteye: Maximizing Engagement While Maintaining Artistic Style on Instagram Using Deep Neural Networks
Jun 13, 2020
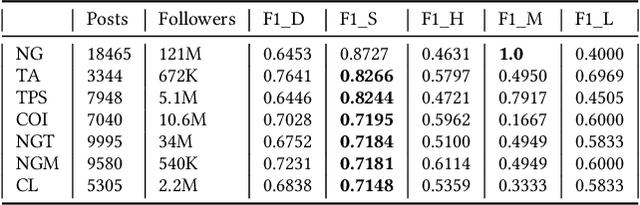
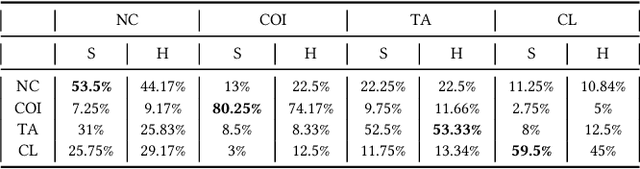
Instagram has become a great venue for amateur and professional photographers alike to showcase their work. It has, in other words, democratized photography. Generally, photographers take thousands of photos in a session, from which they pick a few to showcase their work on Instagram. Photographers trying to build a reputation on Instagram have to strike a balance between maximizing their followers' engagement with their photos, while also maintaining their artistic style. We used transfer learning to adapt Xception, which is a model for object recognition trained on the ImageNet dataset, to the task of engagement prediction and utilized Gram matrices generated from VGG19, another object recognition model trained on ImageNet, for the task of style similarity measurement on photos posted on Instagram. Our models can be trained on individual Instagram accounts to create personalized engagement prediction and style similarity models. Once trained on their accounts, users can have new photos sorted based on predicted engagement and style similarity to their previous work, thus enabling them to upload photos that not only have the potential to maximize engagement from their followers but also maintain their style of photography. We trained and validated our models on several Instagram accounts, showing it to be adept at both tasks, also outperforming several baseline models and human annotators.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021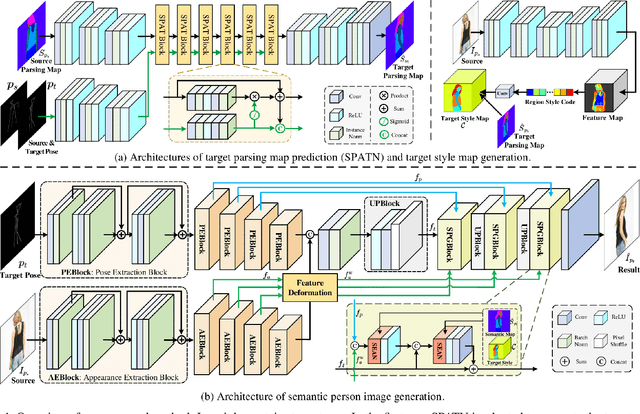
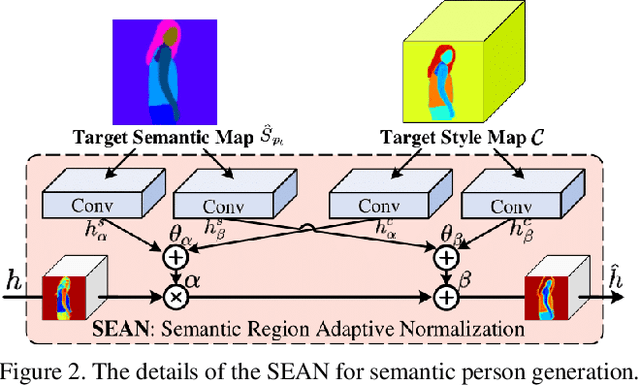

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
Fast and Robust Face-to-Parameter Translation for Game Character Auto-Creation
Aug 17, 2020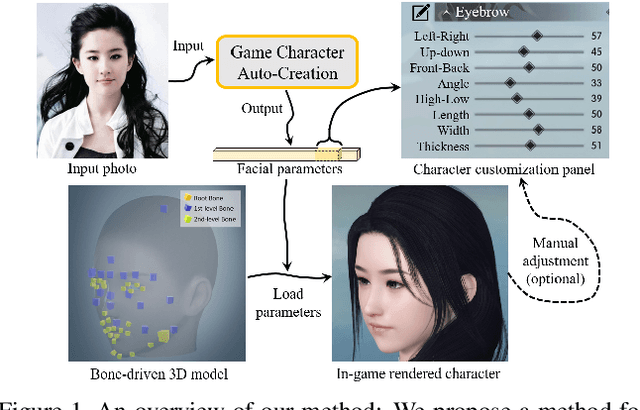

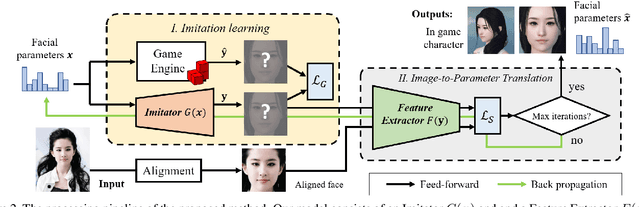

With the rapid development of Role-Playing Games (RPGs), players are now allowed to edit the facial appearance of their in-game characters with their preferences rather than using default templates. This paper proposes a game character auto-creation framework that generates in-game characters according to a player's input face photo. Different from the previous methods that are designed based on neural style transfer or monocular 3D face reconstruction, we re-formulate the character auto-creation process in a different point of view: by predicting a large set of physically meaningful facial parameters under a self-supervised learning paradigm. Instead of updating facial parameters iteratively at the input end of the renderer as suggested by previous methods, which are time-consuming, we introduce a facial parameter translator so that the creation can be done efficiently through a single forward propagation from the face embeddings to parameters, with a considerable 1000x computational speedup. Despite its high efficiency, the interactivity is preserved in our method where users are allowed to optionally fine-tune the facial parameters on our creation according to their needs. Our approach also shows better robustness than previous methods, especially for those photos with head-pose variance. Comparison results and ablation analysis on seven public face verification datasets suggest the effectiveness of our method.
NTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021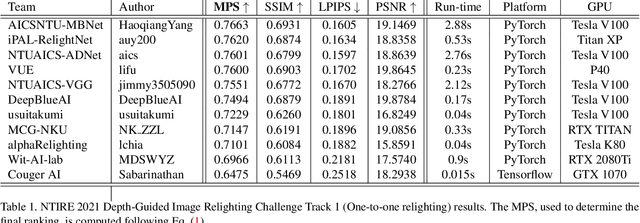

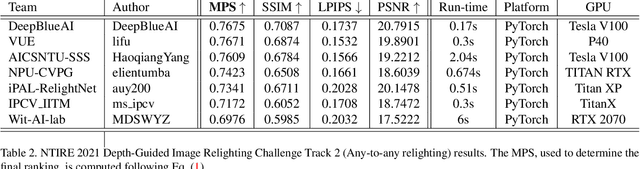

Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
AniGAN: Style-Guided Generative Adversarial Networks for Unsupervised Anime Face Generation
Feb 24, 2021
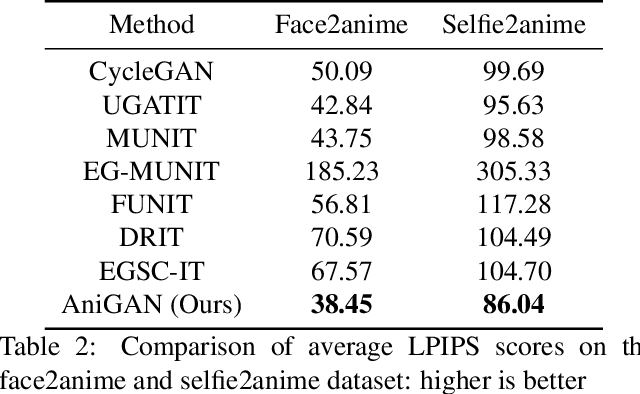
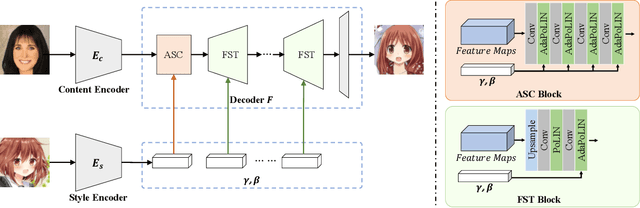
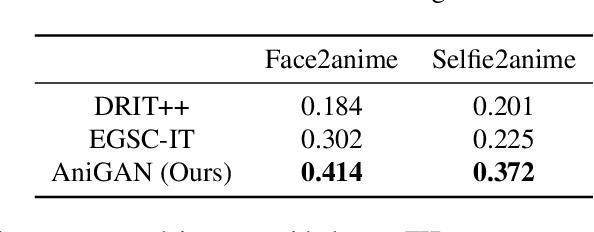
In this paper, we propose a novel framework to translate a portrait photo-face into an anime appearance. Our aim is to synthesize anime-faces which are style-consistent with a given reference anime-face. However, unlike typical translation tasks, such anime-face translation is challenging due to complex variations of appearances among anime-faces. Existing methods often fail to transfer the styles of reference anime-faces, or introduce noticeable artifacts/distortions in the local shapes of their generated faces. We propose Ani- GAN, a novel GAN-based translator that synthesizes highquality anime-faces. Specifically, a new generator architecture is proposed to simultaneously transfer color/texture styles and transform local facial shapes into anime-like counterparts based on the style of a reference anime-face, while preserving the global structure of the source photoface. We propose a double-branch discriminator to learn both domain-specific distributions and domain-shared distributions, helping generate visually pleasing anime-faces and effectively mitigate artifacts. Extensive experiments qualitatively and quantitatively demonstrate the superiority of our method over state-of-the-art methods.
MW-GAN: Multi-Warping GAN for Caricature Generation with Multi-Style Geometric Exaggeration
Jan 07, 2020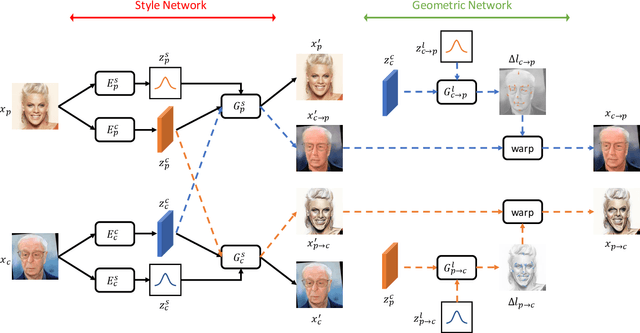
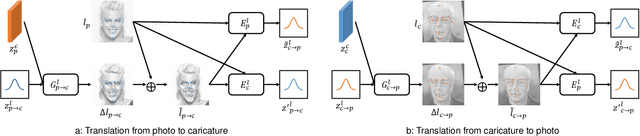
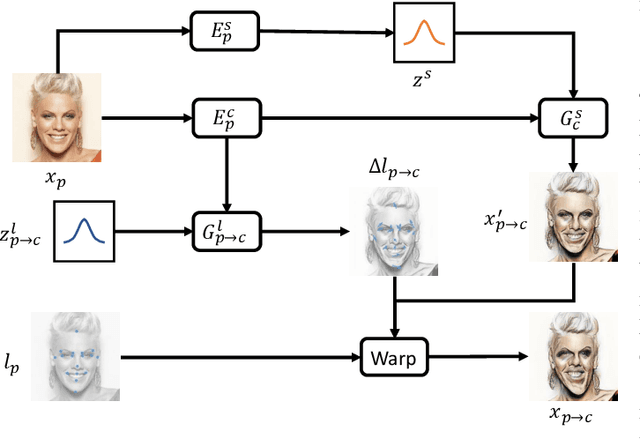

Given an input face photo, the goal of caricature generation is to produce stylized, exaggerated caricatures that share the same identity as the photo. It requires simultaneous style transfer and shape exaggeration with rich diversity, and meanwhile preserving the identity of the input. To address this challenging problem, we propose a novel framework called Multi-Warping GAN (MW-GAN), including a style network and a geometric network that are designed to conduct style transfer and geometric exaggeration respectively. We bridge the gap between the style and landmarks of an image with corresponding latent code spaces by a dual way design, so as to generate caricatures with arbitrary styles and geometric exaggeration, which can be specified either through random sampling of latent code or from a given caricature sample. Besides, we apply identity preserving loss to both image space and landmark space, leading to a great improvement in quality of generated caricatures. Experiments show that caricatures generated by MW-GAN have better quality than existing methods.
TextStyleBrush: Transfer of Text Aesthetics from a Single Example
Jun 15, 2021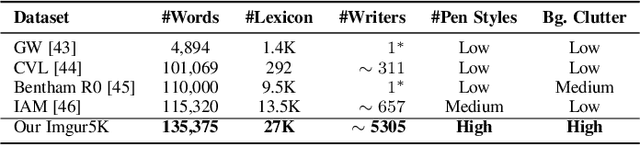

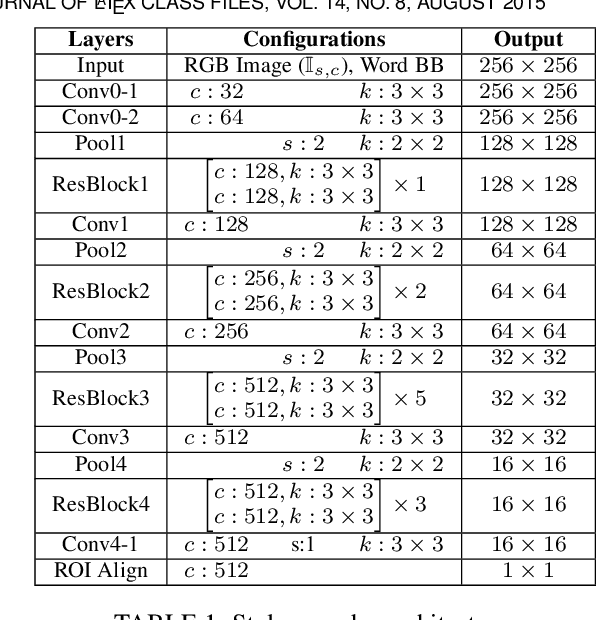
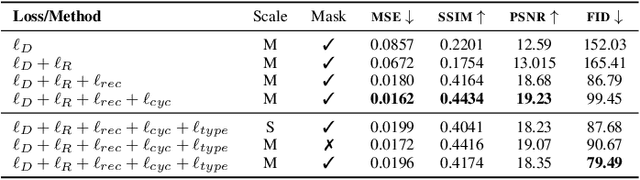
We present a novel approach for disentangling the content of a text image from all aspects of its appearance. The appearance representation we derive can then be applied to new content, for one-shot transfer of the source style to new content. We learn this disentanglement in a self-supervised manner. Our method processes entire word boxes, without requiring segmentation of text from background, per-character processing, or making assumptions on string lengths. We show results in different text domains which were previously handled by specialized methods, e.g., scene text, handwritten text. To these ends, we make a number of technical contributions: (1) We disentangle the style and content of a textual image into a non-parametric, fixed-dimensional vector. (2) We propose a novel approach inspired by StyleGAN but conditioned over the example style at different resolution and content. (3) We present novel self-supervised training criteria which preserve both source style and target content using a pre-trained font classifier and text recognizer. Finally, (4) we also introduce Imgur5K, a new challenging dataset for handwritten word images. We offer numerous qualitative photo-realistic results of our method. We further show that our method surpasses previous work in quantitative tests on scene text and handwriting datasets, as well as in a user study.
Ultrafast Photorealistic Style Transfer via Neural Architecture Search
Dec 05, 2019
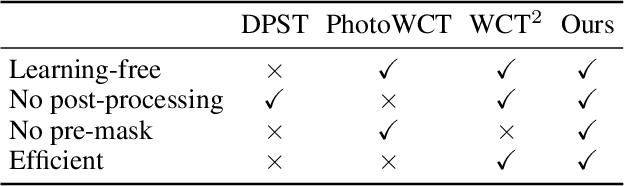
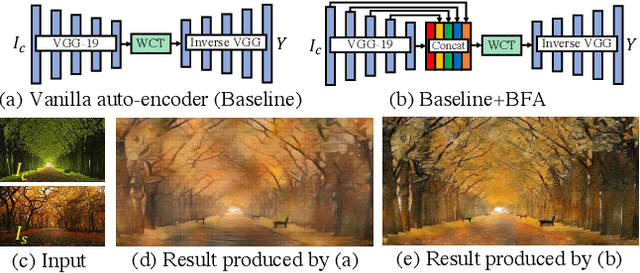

The key challenge in photorealistic style transfer is that an algorithm should faithfully transfer the style of a reference photo to a content photo while the generated image should look like one captured by a camera. Although several photorealistic style transfer algorithms have been proposed, they need to rely on post- and/or pre-processing to make the generated images look photorealistic. If we disable the additional processing, these algorithms would fail to produce plausible photorealistic stylization in terms of detail preservation and photorealism. In this work, we propose an effective solution to these issues. Our method consists of a construction step (C-step) to build a photorealistic stylization network and a pruning step (P-step) for acceleration. In the C-step, we propose a dense auto-encoder named PhotoNet based on a carefully designed pre-analysis. PhotoNet integrates a feature aggregation module (BFA) and instance normalized skip links (INSL). To generate faithful stylization, we introduce multiple style transfer modules in the decoder and INSLs. PhotoNet significantly outperforms existing algorithms in terms of both efficiency and effectiveness. In the P-step, we adopt a neural architecture search method to accelerate PhotoNet. We propose an automatic network pruning framework in the manner of teacher-student learning for photorealistic stylization. The network architecture named PhotoNAS resulted from the search achieves significant acceleration over PhotoNet while keeping the stylization effects almost intact. We conduct extensive experiments on both image and video transfer. The results show that our method can produce favorable results while achieving 20-30 times acceleration in comparison with the existing state-of-the-art approaches. It is worth noting that the proposed algorithm accomplishes better performance without any pre- or post-processing.