 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Recommendation via Adaptive Robust Attention with Multi-dimensional Embeddings
Sep 08, 2024



Sequential recommendation models have achieved state-of-the-art performance using self-attention mechanism. It has since been found that moving beyond only using item ID and positional embeddings leads to a significant accuracy boost when predicting the next item. In recent literature, it was reported that a multi-dimensional kernel embedding with temporal contextual kernels to capture users' diverse behavioral patterns results in a substantial performance improvement. In this study, we further improve the sequential recommender model's robustness and generalization by introducing a mix-attention mechanism with a layer-wise noise injection (LNI) regularization. We refer to our proposed model as adaptive robust sequential recommendation framework (ADRRec), and demonstrate through extensive experiments that our model outperforms existing self-attention architectures.
GarmentGAN: Photo-realistic Adversarial Fashion Transfer
Mar 04, 2020
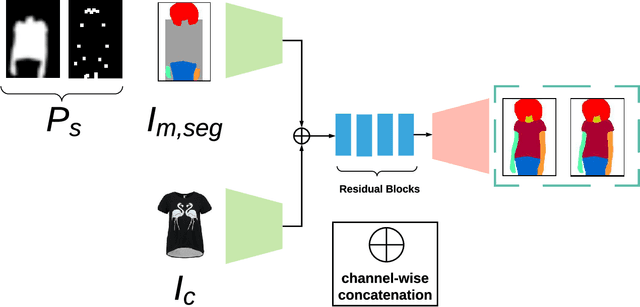
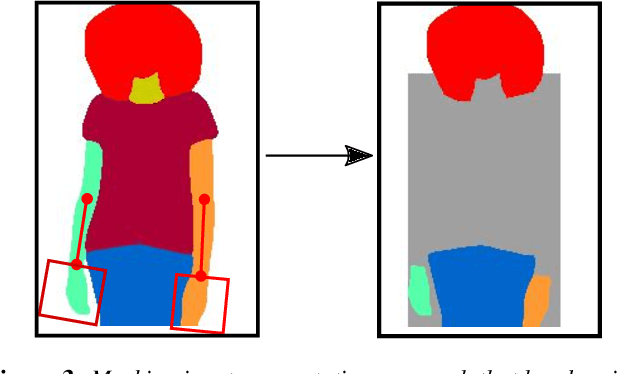
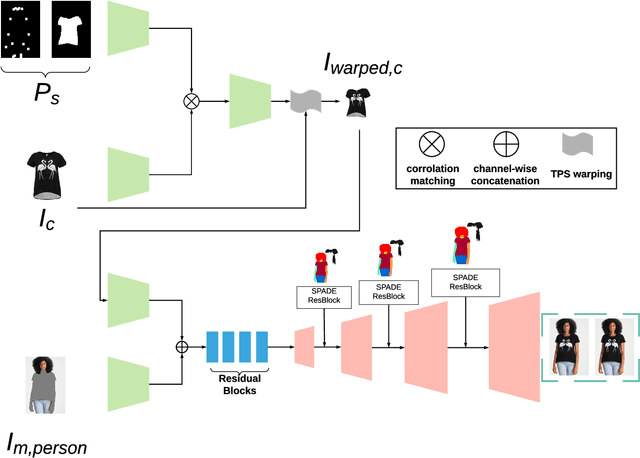
The garment transfer problem comprises two tasks: learning to separate a person's body (pose, shape, color) from their clothing (garment type, shape, style) and then generating new images of the wearer dressed in arbitrary garments. We present GarmentGAN, a new algorithm that performs image-based garment transfer through generative adversarial methods. The GarmentGAN framework allows users to virtually try-on items before purchase and generalizes to various apparel types. GarmentGAN requires as input only two images, namely, a picture of the target fashion item and an image containing the customer. The output is a synthetic image wherein the customer is wearing the target apparel. In order to make the generated image look photo-realistic, we employ the use of novel generative adversarial techniques. GarmentGAN improves on existing methods in the realism of generated imagery and solves various problems related to self-occlusions. Our proposed model incorporates additional information during training, utilizing both segmentation maps and body key-point information. We show qualitative and quantitative comparisons to several other networks to demonstrate the effectiveness of this technique.
Class-specific Anchoring Proposal for 3D Object Recognition in LIDAR and RGB Images
Jul 22, 2019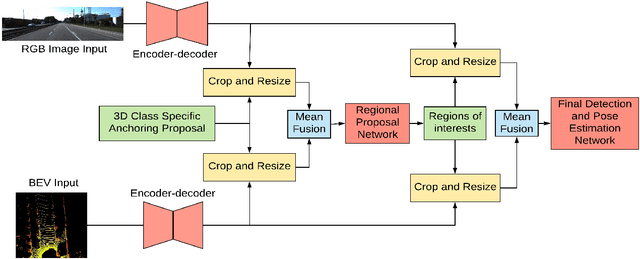
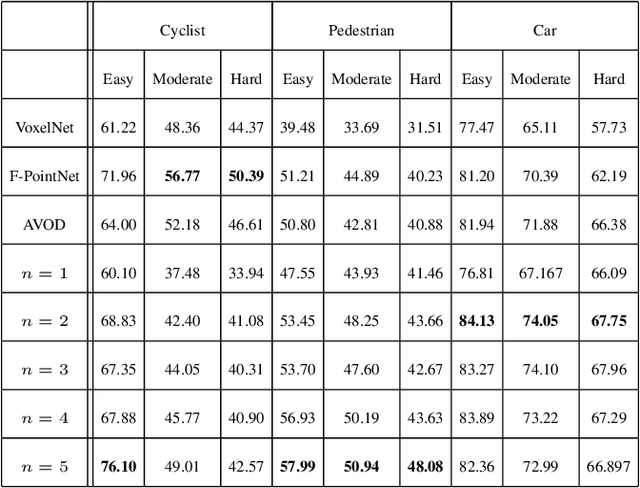
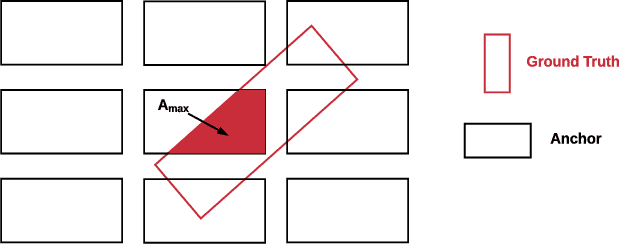
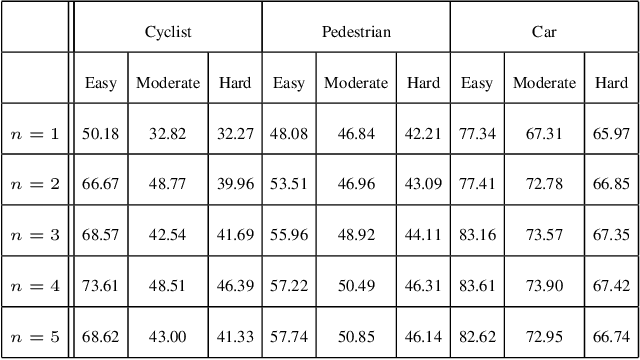
Detecting objects in a two-dimensional setting is often insufficient in the context of real-life applications where the surrounding environment needs to be accurately recognized and oriented in three-dimension (3D), such as in the case of autonomous driving vehicles. Therefore, accurately and efficiently detecting objects in the three-dimensional setting is becoming increasingly relevant to a wide range of industrial applications, and thus is progressively attracting the attention of researchers. Building systems to detect objects in 3D is a challenging task though, because it relies on the multi-modal fusion of data derived from different sources. In this paper, we study the effects of anchoring using the current state-of-the-art 3D object detector and propose Class-specific Anchoring Proposal (CAP) strategy based on object sizes and aspect ratios based clustering of anchors. The proposed anchoring strategy significantly increased detection accuracy's by 7.19%, 8.13% and 8.8% on Easy, Moderate and Hard setting of the pedestrian class, 2.19%, 2.17% and 1.27% on Easy, Moderate and Hard setting of the car class and 12.1% on Easy setting of cyclist class. We also show that the clustering in anchoring process also enhances the performance of the regional proposal network in proposing regions of interests significantly. Finally, we propose the best cluster numbers for each class of objects in KITTI dataset that improves the performance of detection model significantly.