 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Act Classification
Dialogue act classification is the process of categorizing utterances or dialogues into different dialogue acts or speech acts.
Papers and Code
NatCS: Eliciting Natural Customer Support Dialogues
May 04, 2023



Despite growing interest in applications based on natural customer support conversations, there exist remarkably few publicly available datasets that reflect the expected characteristics of conversations in these settings. Existing task-oriented dialogue datasets, which were collected to benchmark dialogue systems mainly in written human-to-bot settings, are not representative of real customer support conversations and do not provide realistic benchmarks for systems that are applied to natural data. To address this gap, we introduce NatCS, a multi-domain collection of spoken customer service conversations. We describe our process for collecting synthetic conversations between customers and agents based on natural language phenomena observed in real conversations. Compared to previous dialogue datasets, the conversations collected with our approach are more representative of real human-to-human conversations along multiple metrics. Finally, we demonstrate potential uses of NatCS, including dialogue act classification and intent induction from conversations as potential applications, showing that dialogue act annotations in NatCS provide more effective training data for modeling real conversations compared to existing synthetic written datasets. We publicly release NatCS to facilitate research in natural dialog systems
Towards Transparency in Coreference Resolution: A Quantum-Inspired Approach
Dec 01, 2023Guided by grammatical structure, words compose to form sentences, and guided by discourse structure, sentences compose to form dialogues and documents. The compositional aspect of sentence and discourse units is often overlooked by machine learning algorithms. A recent initiative called Quantum Natural Language Processing (QNLP) learns word meanings as points in a Hilbert space and acts on them via a translation of grammatical structure into Parametrised Quantum Circuits (PQCs). Previous work extended the QNLP translation to discourse structure using points in a closure of Hilbert spaces. In this paper, we evaluate this translation on a Winograd-style pronoun resolution task. We train a Variational Quantum Classifier (VQC) for binary classification and implement an end-to-end pronoun resolution system. The simulations executed on IBMQ software converged with an F1 score of 87.20%. The model outperformed two out of three classical coreference resolution systems and neared state-of-the-art SpanBERT. A mixed quantum-classical model yet improved these results with an F1 score increase of around 6%.
A neural prosody encoder for end-ro-end dialogue act classification
May 11, 2022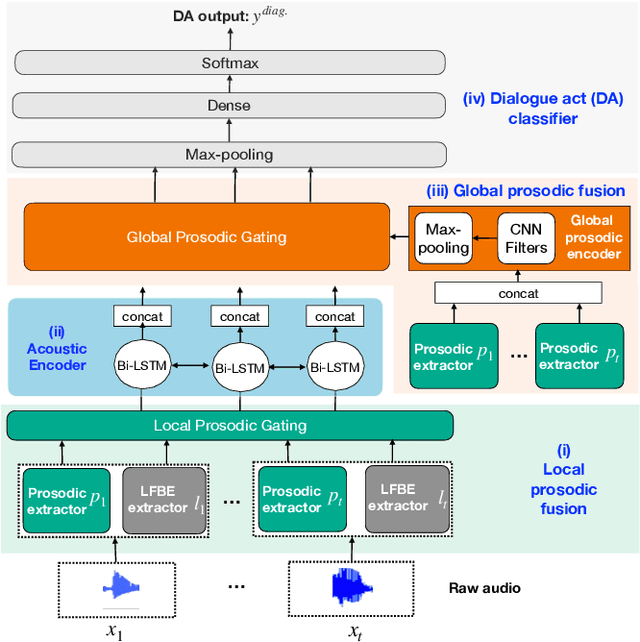
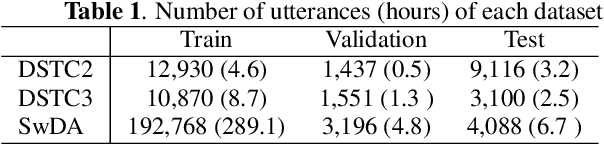
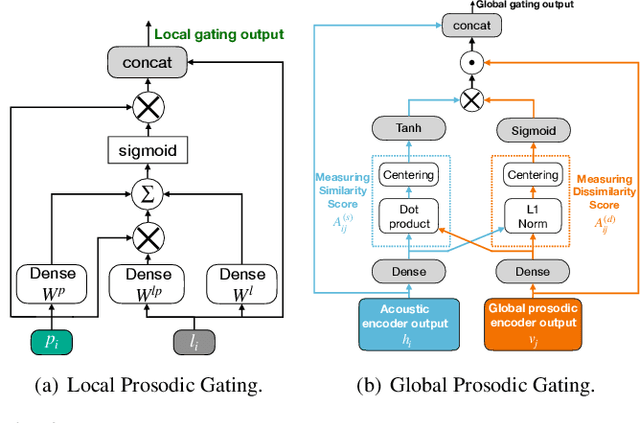

Dialogue act classification (DAC) is a critical task for spoken language understanding in dialogue systems. Prosodic features such as energy and pitch have been shown to be useful for DAC. Despite their importance, little research has explored neural approaches to integrate prosodic features into end-to-end (E2E) DAC models which infer dialogue acts directly from audio signals. In this work, we propose an E2E neural architecture that takes into account the need for characterizing prosodic phenomena co-occurring at different levels inside an utterance. A novel part of this architecture is a learnable gating mechanism that assesses the importance of prosodic features and selectively retains core information necessary for E2E DAC. Our proposed model improves DAC accuracy by 1.07% absolute across three publicly available benchmark datasets.
AUTODIAL: Efficient Asynchronous Task-Oriented Dialogue Model
Mar 10, 2023



As large dialogue models become commonplace in practice, the problems surrounding high compute requirements for training, inference and larger memory footprint still persists. In this work, we present AUTODIAL, a multi-task dialogue model that addresses the challenges of deploying dialogue model. AUTODIAL utilizes parallel decoders to perform tasks such as dialogue act prediction, domain prediction, intent prediction, and dialogue state tracking. Using classification decoders over generative decoders allows AUTODIAL to significantly reduce memory footprint and achieve faster inference times compared to existing generative approach namely SimpleTOD. We demonstrate that AUTODIAL provides 3-6x speedups during inference while having 11x fewer parameters on three dialogue tasks compared to SimpleTOD. Our results show that extending current dialogue models to have parallel decoders can be a viable alternative for deploying them in resource-constrained environments.
MindDial: Belief Dynamics Tracking with Theory-of-Mind Modeling for Situated Neural Dialogue Generation
Jul 03, 2023



Humans talk in free-form while negotiating the expressed meanings or common ground. Despite the impressive conversational abilities of the large generative language models, they do not consider the individual differences in contextual understanding in a shared situated environment. In this work, we propose MindDial, a novel conversational framework that can generate situated free-form responses to negotiate common ground. We design an explicit mind module that can track three-level beliefs -- the speaker's belief, the speaker's prediction of the listener's belief, and the common belief based on the gap between the first two. Then the speaking act classification head will decide to continue to talk, end this turn, or take task-related action. We augment a common ground alignment dataset MutualFriend with belief dynamics annotation, of which the goal is to find a single mutual friend based on the free chat between two agents. Experiments show that our model with mental state modeling can resemble human responses when aligning common ground meanwhile mimic the natural human conversation flow. The ablation study further validates the third-level common belief can aggregate information of the first and second-order beliefs and align common ground more efficiently.
Improving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023



Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
A Benchmark for Automatic Medical Consultation System: Frameworks, Tasks and Datasets
Apr 27, 2022
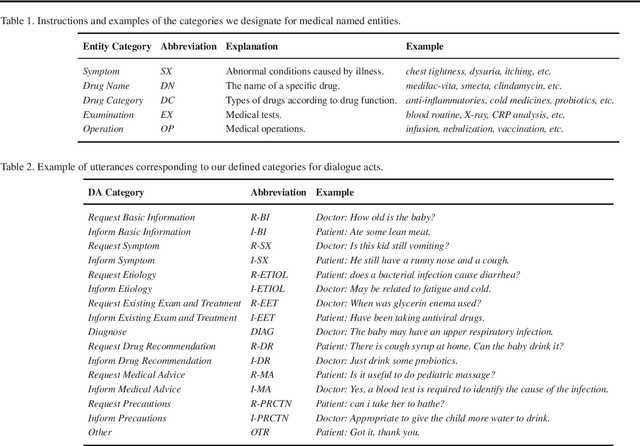
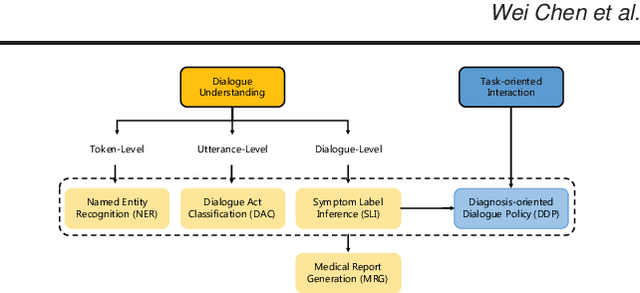
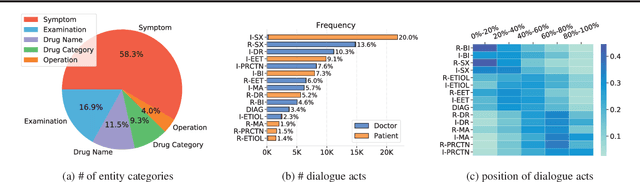
In recent years, interest has arisen in using machine learning to improve the efficiency of automatic medical consultation and enhance patient experience. In this paper, we propose two frameworks to support automatic medical consultation, namely doctor-patient dialogue understanding and task-oriented interaction. A new large medical dialogue dataset with multi-level fine-grained annotations is introduced and five independent tasks are established, including named entity recognition, dialogue act classification, symptom label inference, medical report generation and diagnosis-oriented dialogue policy. We report a set of benchmark results for each task, which shows the usability of the dataset and sets a baseline for future studies.
Robust Educational Dialogue Act Classifiers with Low-Resource and Imbalanced Datasets
Apr 15, 2023



Dialogue acts (DAs) can represent conversational actions of tutors or students that take place during tutoring dialogues. Automating the identification of DAs in tutoring dialogues is significant to the design of dialogue-based intelligent tutoring systems. Many prior studies employ machine learning models to classify DAs in tutoring dialogues and invest much effort to optimize the classification accuracy by using limited amounts of training data (i.e., low-resource data scenario). However, beyond the classification accuracy, the robustness of the classifier is also important, which can reflect the capability of the classifier on learning the patterns from different class distributions. We note that many prior studies on classifying educational DAs employ cross entropy (CE) loss to optimize DA classifiers on low-resource data with imbalanced DA distribution. The DA classifiers in these studies tend to prioritize accuracy on the majority class at the expense of the minority class which might not be robust to the data with imbalanced ratios of different DA classes. To optimize the robustness of classifiers on imbalanced class distributions, we propose to optimize the performance of the DA classifier by maximizing the area under the ROC curve (AUC) score (i.e., AUC maximization). Through extensive experiments, our study provides evidence that (i) by maximizing AUC in the training process, the DA classifier achieves significant performance improvement compared to the CE approach under low-resource data, and (ii) AUC maximization approaches can improve the robustness of the DA classifier under different class imbalance ratios.
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding
Nov 02, 2022



Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.
A Universality-Individuality Integration Model for Dialog Act Classification
Apr 13, 2022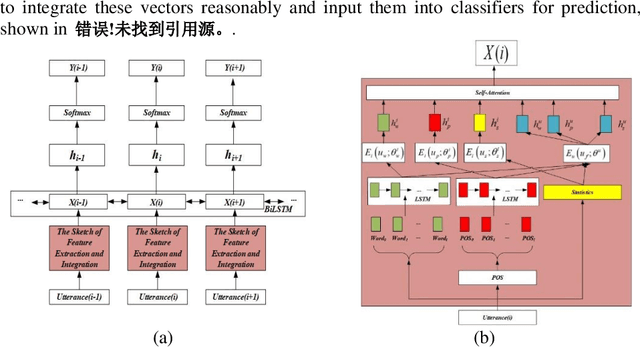

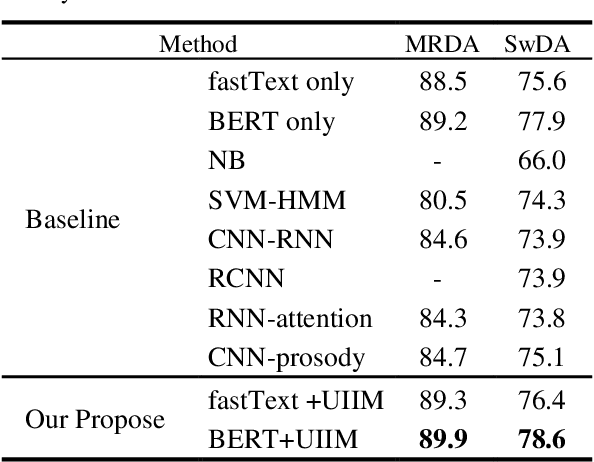
Dialog Act (DA) reveals the general intent of the speaker utterance in a conversation. Accurately predicting DAs can greatly facilitate the development of dialog agents. Although researchers have done extensive research on dialog act classification, the feature information of classification has not been fully considered. This paper suggests that word cues, part-of-speech cues and statistical cues can complement each other to improve the basis for recognition. In addition, the different types of the three lead to the diversity of their distribution forms, which hinders the mining of feature information. To solve this problem, we propose a novel model based on universality and individuality strategies, called Universality-Individuality Integration Model (UIIM). UIIM not only deepens the connection between the clues by learning universality, but also utilizes the learning of individuality to capture the characteristics of the clues themselves. Experiments were made over two most popular benchmark data sets SwDA and MRDA for dialogue act classification, and the results show that extracting the universalities and individualities between cues can more fully excavate the hidden information in the utterance, and improve the accuracy of automatic dialogue act recognition.