 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinoground
Papers and Code
Inference-Time Structural Reasoning for Compositional Vision-Language Understanding
Mar 28, 2026Vision-language models (VLMs) excel at image-text retrieval yet persistently fail at compositional reasoning, distinguishing captions that share the same words but differ in relational structure. We present, a unified evaluation and augmentation framework benchmarking four architecturally diverse VLMs,CLIP, BLIP, LLaVA, and Qwen3-VL-8B-Thinking,on the Winoground benchmark under plain and scene-graph-augmented regimes. We introduce a dependency-based TextSceneGraphParser (spaCy) extracting subject-relation-object triples, and a Graph Asymmetry Scorer using optimal bipartite matching to inject structural relational priors. Caption ablation experiments (subject-object masking and swapping) reveal that Qwen3-VL-8B-Thinking achieves a group score of 62.75, far above all encoder-based models, while a proposed multi-turn SG filtering strategy further lifts it to 66.0, surpassing prior open-source state-of-the-art. We analyze the capability augmentation tradeoff and find that SG augmentation benefits already capable models while providing negligible or negative gains for weaker baselines. Code: https://github.com/amartyacodes/Inference-Time-Structural-Reasoning-for-Compositional-Vision-Language-Understanding
LINA: Learning INterventions Adaptively for Physical Alignment and Generalization in Diffusion Models
Dec 15, 2025



Diffusion models (DMs) have achieved remarkable success in image and video generation. However, they still struggle with (1) physical alignment and (2) out-of-distribution (OOD) instruction following. We argue that these issues stem from the models' failure to learn causal directions and to disentangle causal factors for novel recombination. We introduce the Causal Scene Graph (CSG) and the Physical Alignment Probe (PAP) dataset to enable diagnostic interventions. This analysis yields three key insights. First, DMs struggle with multi-hop reasoning for elements not explicitly determined in the prompt. Second, the prompt embedding contains disentangled representations for texture and physics. Third, visual causal structure is disproportionately established during the initial, computationally limited denoising steps. Based on these findings, we introduce LINA (Learning INterventions Adaptively), a novel framework that learns to predict prompt-specific interventions, which employs (1) targeted guidance in the prompt and visual latent spaces, and (2) a reallocated, causality-aware denoising schedule. Our approach enforces both physical alignment and OOD instruction following in image and video DMs, achieving state-of-the-art performance on challenging causal generation tasks and the Winoground dataset. Our project page is at https://opencausalab.github.io/LINA.
Enhancing Compositional Reasoning in Vision-Language Models with Synthetic Preference Data
Apr 07, 2025



Compositionality, or correctly recognizing scenes as compositions of atomic visual concepts, remains difficult for multimodal large language models (MLLMs). Even state of the art MLLMs such as GPT-4o can make mistakes in distinguishing compositions like "dog chasing cat" vs "cat chasing dog". While on Winoground, a benchmark for measuring such reasoning, MLLMs have made significant progress, they are still far from a human's performance. We show that compositional reasoning in these models can be improved by elucidating such concepts via data, where a model is trained to prefer the correct caption for an image over a close but incorrect one. We introduce SCRAMBLe: Synthetic Compositional Reasoning Augmentation of MLLMs with Binary preference Learning, an approach for preference tuning open-weight MLLMs on synthetic preference data generated in a fully automated manner from existing image-caption data. SCRAMBLe holistically improves these MLLMs' compositional reasoning capabilities which we can see through significant improvements across multiple vision language compositionality benchmarks, as well as smaller but significant improvements on general question answering tasks. As a sneak peek, SCRAMBLe tuned Molmo-7B model improves on Winoground from 49.5% to 54.8% (best reported to date), while improving by ~1% on more general visual question answering tasks. Code for SCRAMBLe along with tuned models and our synthetic training dataset is available at https://github.com/samarth4149/SCRAMBLe.
Natural Language Inference Improves Compositionality in Vision-Language Models
Oct 29, 2024



Compositional reasoning in Vision-Language Models (VLMs) remains challenging as these models often struggle to relate objects, attributes, and spatial relationships. Recent methods aim to address these limitations by relying on the semantics of the textual description, using Large Language Models (LLMs) to break them down into subsets of questions and answers. However, these methods primarily operate on the surface level, failing to incorporate deeper lexical understanding while introducing incorrect assumptions generated by the LLM. In response to these issues, we present Caption Expansion with Contradictions and Entailments (CECE), a principled approach that leverages Natural Language Inference (NLI) to generate entailments and contradictions from a given premise. CECE produces lexically diverse sentences while maintaining their core meaning. Through extensive experiments, we show that CECE enhances interpretability and reduces overreliance on biased or superficial features. By balancing CECE along the original premise, we achieve significant improvements over previous methods without requiring additional fine-tuning, producing state-of-the-art results on benchmarks that score agreement with human judgments for image-text alignment, and achieving an increase in performance on Winoground of +19.2% (group score) and +12.9% on EqBen (group score) over the best prior work (finetuned with targeted data).
Understanding the Effect of using Semantically Meaningful Tokens for Visual Representation Learning
May 26, 2024



Vision transformers have established a precedent of patchifying images into uniformly-sized chunks before processing. We hypothesize that this design choice may limit models in learning comprehensive and compositional representations from visual data. This paper explores the notion of providing semantically-meaningful visual tokens to transformer encoders within a vision-language pre-training framework. Leveraging off-the-shelf segmentation and scene-graph models, we extract representations of instance segmentation masks (referred to as tangible tokens) and relationships and actions (referred to as intangible tokens). Subsequently, we pre-train a vision-side transformer by incorporating these newly extracted tokens and aligning the resultant embeddings with caption embeddings from a text-side encoder. To capture the structural and semantic relationships among visual tokens, we introduce additive attention weights, which are used to compute self-attention scores. Our experiments on COCO demonstrate notable improvements over ViTs in learned representation quality across text-to-image (+47%) and image-to-text retrieval (+44%) tasks. Furthermore, we showcase the advantages on compositionality benchmarks such as ARO (+18%) and Winoground (+10%).
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
May 05, 2024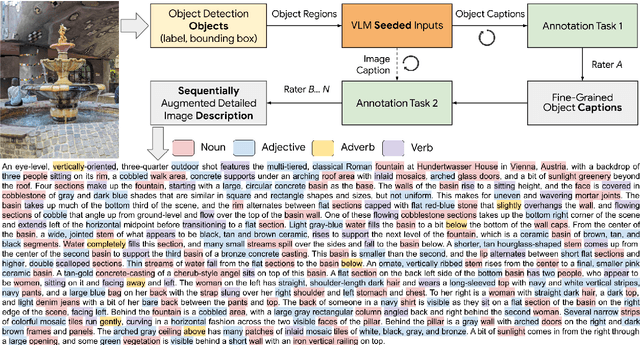
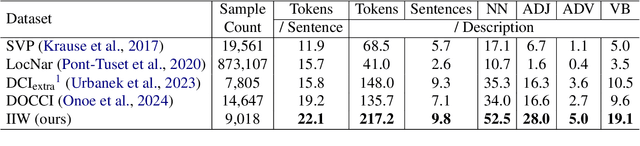

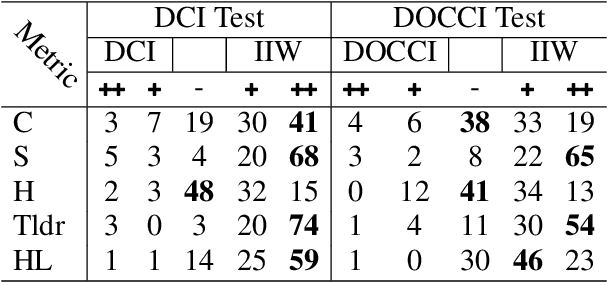
Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
ColorSwap: A Color and Word Order Dataset for Multimodal Evaluation
Feb 07, 2024



This paper introduces the ColorSwap dataset, designed to assess and improve the proficiency of multimodal models in matching objects with their colors. The dataset is comprised of 2,000 unique image-caption pairs, grouped into 1,000 examples. Each example includes a caption-image pair, along with a ``color-swapped'' pair. We follow the Winoground schema: the two captions in an example have the same words, but the color words have been rearranged to modify different objects. The dataset was created through a novel blend of automated caption and image generation with humans in the loop. We evaluate image-text matching (ITM) and visual language models (VLMs) and find that even the latest ones are still not robust at this task. GPT-4V and LLaVA score 72% and 42% on our main VLM metric, although they may improve with more advanced prompting techniques. On the main ITM metric, contrastive models such as CLIP and SigLIP perform close to chance (at 12% and 30%, respectively), although the non-contrastive BLIP ITM model is stronger (87%). We also find that finetuning on fewer than 2,000 examples yields significant performance gains on this out-of-distribution word-order understanding task. The dataset is here: https://github.com/Top34051/colorswap.
Prompting Large Vision-Language Models for Compositional Reasoning
Jan 20, 2024Vision-language models such as CLIP have shown impressive capabilities in encoding texts and images into aligned embeddings, enabling the retrieval of multimodal data in a shared embedding space. However, these embedding-based models still face challenges in effectively matching images and texts with similar visio-linguistic compositionality, as evidenced by their performance on the recent Winoground dataset. In this paper, we argue that this limitation stems from two factors: the use of single vector representations for complex multimodal data, and the absence of step-by-step reasoning in these embedding-based methods. To address this issue, we make an exploratory step using a novel generative method that prompts large vision-language models (e.g., GPT-4) to depict images and perform compositional reasoning. Our method outperforms other embedding-based methods on the Winoground dataset, and obtains further improvement of up to 10% accuracy when enhanced with the optimal description.
A Contrastive Compositional Benchmark for Text-to-Image Synthesis: A Study with Unified Text-to-Image Fidelity Metrics
Dec 04, 2023Text-to-image (T2I) synthesis has recently achieved significant advancements. However, challenges remain in the model's compositionality, which is the ability to create new combinations from known components. We introduce Winoground-T2I, a benchmark designed to evaluate the compositionality of T2I models. This benchmark includes 11K complex, high-quality contrastive sentence pairs spanning 20 categories. These contrastive sentence pairs with subtle differences enable fine-grained evaluations of T2I synthesis models. Additionally, to address the inconsistency across different metrics, we propose a strategy that evaluates the reliability of various metrics by using comparative sentence pairs. We use Winoground-T2I with a dual objective: to evaluate the performance of T2I models and the metrics used for their evaluation. Finally, we provide insights into the strengths and weaknesses of these metrics and the capabilities of current T2I models in tackling challenges across a range of complex compositional categories. Our benchmark is publicly available at https://github.com/zhuxiangru/Winoground-T2I .
SelfEval: Leveraging the discriminative nature of generative models for evaluation
Nov 17, 2023



In this work, we show that text-to-image generative models can be 'inverted' to assess their own text-image understanding capabilities in a completely automated manner. Our method, called SelfEval, uses the generative model to compute the likelihood of real images given text prompts, making the generative model directly applicable to discriminative tasks. Using SelfEval, we repurpose standard datasets created for evaluating multimodal text-image discriminative models to evaluate generative models in a fine-grained manner: assessing their performance on attribute binding, color recognition, counting, shape recognition, spatial understanding. To the best of our knowledge SelfEval is the first automated metric to show a high degree of agreement for measuring text-faithfulness with the gold-standard human evaluations across multiple models and benchmarks. Moreover, SelfEval enables us to evaluate generative models on challenging tasks such as Winoground image-score where they demonstrate competitive performance to discriminative models. We also show severe drawbacks of standard automated metrics such as CLIP-score to measure text faithfulness on benchmarks such as DrawBench, and how SelfEval sidesteps these issues. We hope SelfEval enables easy and reliable automated evaluation for diffusion models.