 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACULA: Hunting for the Actions Users Want Deep Research Agents to Execute
Apr 26, 2026Scientific Deep Research (DR) agents answer user queries by synthesizing research papers into multi-section reports. User feedback can improve their utility, but existing protocols only score the final report, making it hard to study and learn which intermediate actions DR agents should take to improve reports. We collect DRACULA, the first dataset with user feedback on intermediate actions for DR. Over five weeks, nineteen expert CS researchers ask queries to a DR system that proposes actions (e.g., "Add a section on datasets"). Our users select actions they prefer, then judge whether an output report applied their selections successfully, yielding 8,103 action preferences and 5,230 execution judgments. After confirming a DR agent can execute DRACULA's actions, we study the predictability of user-preferred actions via simulation-how well LLMs predict the actions users select-a step toward learning to generate useful actions. We discover: (1) LLM judges initially struggle to predict action selections, but improve most when using a user's full selection history, rather than self-reported or extrapolated user context signals; (2) Users' selections for the same query differ based on unstated goals, bottlenecking simulation and motivating affordances that let users steer reports; and (3) Our simulation results inform an online intervention that generates new actions based on the user's past interactions, which users pick most often in follow-up studies. Overall, while work extensively studies execution, DRACULA reveals a key challenge is deciding which actions to execute in the first place. We open-source DRACULA's study design, user feedback, and simulation tasks to spur future work on action feedback for long-horizon agents.
Reheat Nachos for Dinner? Evaluating AI Support for Cross-Cultural Communication of Neologisms
Apr 26, 2026Neologisms and emerging slang are central to daily conversation, yet challenging for non-native speakers (NNS) to interpret and use appropriately in cross-cultural communication with native speakers (NS). NNS increasingly make use of Artificial Intelligence (AI) tools to learn these words. We study the utility of such tools in mediating an informal communication scenario through a human-subjects study (N=234): NNS participants learn English neologisms with AI support, write messages using the learned word to an NS friend, and judge contextual appropriateness of the neologism in two provided writing samples. Using both NS evaluator-rated communicative competence of NNS-produced writing and NNS' contextual appropriateness judgments, we compare three AI-based support conditions: AI Definition, AI Rewrite into simpler English, AI Explanation of meaning and usage, and Non-AI Dictionary for comparison. We show that AI Explanation yields the largest gains over no support in NS-rated competence, while contextual appropriateness judgments show indifference across support. NNS participants' self-reported perceptions tend to overestimate NS ratings, revealing a mismatch between perceived and actual competence. We further observe a significant gap between NNS- and NS-produced writing, highlighting the limitations of current AI tools and informing design for future tools.
DiscoTrace: Representing and Comparing Answering Strategies of Humans and LLMs in Information-Seeking Question Answering
Apr 16, 2026We introduce DiscoTrace, a method to identify the rhetorical strategies that answerers use when responding to information-seeking questions. DiscoTrace represents answers as a sequence of question-related discourse acts paired with interpretations of the original question, annotated on top of rhetorical structure theory parses. Applying DiscoTrace to answers from nine different human communities reveals that communities have diverse preferences for answer construction. In contrast, LLMs do not exhibit rhetorical diversity in their answers, even when prompted to mimic specific human community answering guidelines. LLMs also systematically opt for breadth, addressing interpretations of questions that human answerers choose not to address. Our findings can guide the development of pragmatic LLM answerers that consider a range of strategies informed by context in QA.
BenchMarker: An Education-Inspired Toolkit for Highlighting Flaws in Multiple-Choice Benchmarks
Feb 05, 2026Multiple-choice question answering (MCQA) is standard in NLP, but benchmarks lack rigorous quality control. We present BenchMarker, an education-inspired toolkit using LLM judges to flag three common MCQ flaws: 1) contamination - items appearing exactly online; 2) shortcuts - cues in the choices that enable guessing; and 3) writing errors - structural/grammatical issues based on a 19-rule education rubric. We validate BenchMarker with human annotations, then run the tool to audit 12 benchmarks, revealing: 2) contaminated MCQs tend to inflate accuracy, while writing errors tend to lower it and change rankings beyond random; and 3) prior benchmark repairs address their targeted issues (i.e., lowering accuracy with LLM-written distractors), but inadvertently add new flaws (i.e. implausible distractors, many correct answers). Overall, flaws in MCQs degrade NLP evaluation, but education research offers a path forward. We release BenchMarker to bridge the fields and improve MCQA benchmark design.
Take Out Your Calculators: Estimating the Real Difficulty of Question Items with LLM Student Simulations
Jan 15, 2026Standardized math assessments require expensive human pilot studies to establish the difficulty of test items. We investigate the predictive value of open-source large language models (LLMs) for evaluating the difficulty of multiple-choice math questions for real-world students. We show that, while LLMs are poor direct judges of problem difficulty, simulation-based approaches with LLMs yield promising results under the right conditions. Under the proposed approach, we simulate a "classroom" of 4th, 8th, or 12th grade students by prompting the LLM to role-play students of varying proficiency levels. We use the outcomes of these simulations to fit Item Response Theory (IRT) models, comparing learned difficulty parameters for items to their real-world difficulties, as determined by item-level statistics furnished by the National Assessment of Educational Progress (NAEP). We observe correlations as high as 0.75, 0.76, and 0.82 for grades 4, 8, and 12, respectively. In our simulations, we experiment with different "classroom sizes," showing tradeoffs between computation size and accuracy. We find that role-plays with named students improves predictions (compared to student ids), and stratifying names across gender and race further improves predictions. Our results show that LLMs with relatively weaker mathematical abilities (Gemma) actually yield better real-world difficulty predictions than mathematically stronger models (Llama and Qwen), further underscoring the suitability of open-source models for the task.
Test-Time Reasoners Are Strategic Multiple-Choice Test-Takers
Oct 09, 2025



Large language models (LLMs) now give reasoning before answering, excelling in tasks like multiple-choice question answering (MCQA). Yet, a concern is that LLMs do not solve MCQs as intended, as work finds LLMs sans reasoning succeed in MCQA without using the question, i.e., choices-only. Such partial-input success is often deemed problematic, but reasoning traces could reveal if these strategies are truly shallow in choices-only settings. To study these strategies, reasoning LLMs solve MCQs in full and choices-only inputs; test-time reasoning often boosts accuracy on full and in choices-only half the time. While possibly due to shallow shortcuts, choices-only success is barely affected by the length of reasoning traces, and after finding traces pass faithfulness tests, we show they use less problematic strategies like inferring missing questions. In all, we challenge claims that partial-input success is always a flaw, so we discuss how reasoning traces could separate problematic data from less problematic reasoning.
Multiple LLM Agents Debate for Equitable Cultural Alignment
May 30, 2025



Large Language Models (LLMs) need to adapt their predictions to diverse cultural contexts to benefit diverse communities across the world. While previous efforts have focused on single-LLM, single-turn approaches, we propose to exploit the complementary strengths of multiple LLMs to promote cultural adaptability. We introduce a Multi-Agent Debate framework, where two LLM-based agents debate over a cultural scenario and collaboratively reach a final decision. We propose two variants: one where either LLM agents exclusively debate and another where they dynamically choose between self-reflection and debate during their turns. We evaluate these approaches on 7 open-weight LLMs (and 21 LLM combinations) using the NormAd-ETI benchmark for social etiquette norms in 75 countries. Experiments show that debate improves both overall accuracy and cultural group parity over single-LLM baselines. Notably, multi-agent debate enables relatively small LLMs (7-9B) to achieve accuracies comparable to that of a much larger model (27B parameters).
Understanding Common Ground Misalignment in Goal-Oriented Dialog: A Case-Study with Ubuntu Chat Logs
Mar 16, 2025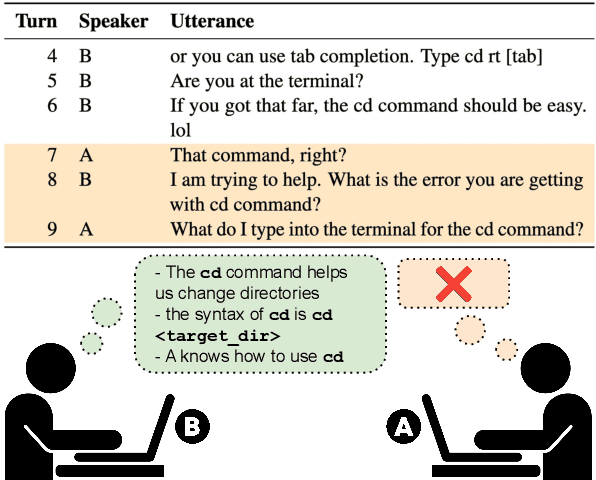
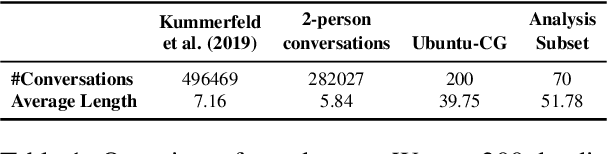
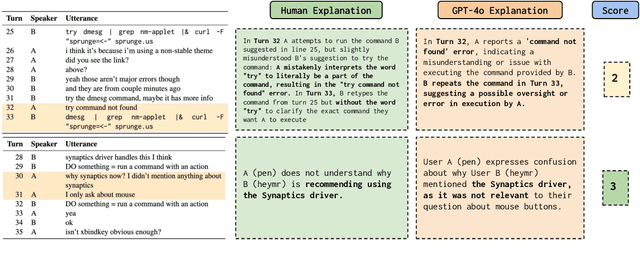
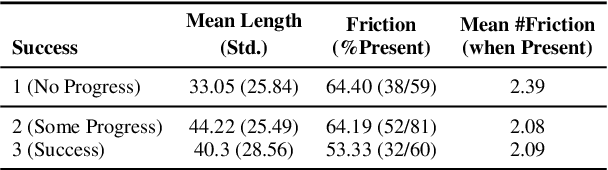
While it is commonly accepted that maintaining common ground plays a role in conversational success, little prior research exists connecting conversational grounding to success in task-oriented conversations. We study failures of grounding in the Ubuntu IRC dataset, where participants use text-only communication to resolve technical issues. We find that disruptions in conversational flow often stem from a misalignment in common ground, driven by a divergence in beliefs and assumptions held by participants. These disruptions, which we call conversational friction, significantly correlate with task success. We find that although LLMs can identify overt cases of conversational friction, they struggle with subtler and more context-dependent instances requiring pragmatic or domain-specific reasoning.
On the Mutual Influence of Gender and Occupation in LLM Representations
Mar 09, 2025We examine LLM representations of gender for first names in various occupational contexts to study how occupations and the gender perception of first names in LLMs influence each other mutually. We find that LLMs' first-name gender representations correlate with real-world gender statistics associated with the name, and are influenced by the co-occurrence of stereotypically feminine or masculine occupations. Additionally, we study the influence of first-name gender representations on LLMs in a downstream occupation prediction task and their potential as an internal metric to identify extrinsic model biases. While feminine first-name embeddings often raise the probabilities for female-dominated jobs (and vice versa for male-dominated jobs), reliably using these internal gender representations for bias detection remains challenging.
Language Models Predict Empathy Gaps Between Social In-groups and Out-groups
Mar 02, 2025Studies of human psychology have demonstrated that people are more motivated to extend empathy to in-group members than out-group members (Cikara et al., 2011). In this study, we investigate how this aspect of intergroup relations in humans is replicated by LLMs in an emotion intensity prediction task. In this task, the LLM is given a short description of an experience a person had that caused them to feel a particular emotion; the LLM is then prompted to predict the intensity of the emotion the person experienced on a numerical scale. By manipulating the group identities assigned to the LLM's persona (the "perceiver") and the person in the narrative (the "experiencer"), we measure how predicted emotion intensities differ between in-group and out-group settings. We observe that LLMs assign higher emotion intensity scores to in-group members than out-group members. This pattern holds across all three types of social groupings we tested: race/ethnicity, nationality, and religion. We perform an in-depth analysis on Llama-3.1-8B, the model which exhibited strongest intergroup bias among those tested.