 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat to Test Next: Interpretable Coverage Gap Discovery in Driving VLMs
Jun 01, 2026Driving vision-language models (VLMs) must accurately understand scenes across diverse conditions defined by Operational Design Domains (ODDs), yet verification remains sparse: many slices are missing, making empirical failure rates unreliable. We propose SliceScorer, a deterministic scoring rule for missing-slice recommendation that combines (i) an exposure-based coverage prior to prioritize rare, under-tested regions, and (ii) a neighbor-failure prior that propagates risk from similar tested conditions. SliceScorer is deliberately simple - interpretable, auditable, and conservative - properties essential for safety-critical validation. For stress testing beyond the declared ODD, we embed SliceScorer within SliceNav, an LLM-orchestrated verification pipeline where the model interprets developer queries to select relevant operators (triage, scoring, acquisition, evaluation) and vocabulary extensions, composing verification workflows while keeping all scoring deterministic and auditable. Experiments on three driving VLMs (WiseAD, DriveMM, Cosmos-Reason2-2B) show that SliceNav surfaces high-risk coverage gaps more effectively than prior slice-discovery methods while maintaining diverse recommendations across the condition space. Ablations confirm both scoring components contribute, and qualitative analysis demonstrates end-to-end workflows from developer query to targeted evaluation.
Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Apr 06, 2024



Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
Exploring Question Decomposition for Zero-Shot VQA
Oct 25, 2023



Visual question answering (VQA) has traditionally been treated as a single-step task where each question receives the same amount of effort, unlike natural human question-answering strategies. We explore a question decomposition strategy for VQA to overcome this limitation. We probe the ability of recently developed large vision-language models to use human-written decompositions and produce their own decompositions of visual questions, finding they are capable of learning both tasks from demonstrations alone. However, we show that naive application of model-written decompositions can hurt performance. We introduce a model-driven selective decomposition approach for second-guessing predictions and correcting errors, and validate its effectiveness on eight VQA tasks across three domains, showing consistent improvements in accuracy, including improvements of >20% on medical VQA datasets and boosting the zero-shot performance of BLIP-2 above chance on a VQA reformulation of the challenging Winoground task. Project Site: https://zaidkhan.me/decomposition-0shot-vqa/
Q: How to Specialize Large Vision-Language Models to Data-Scarce VQA Tasks? A: Self-Train on Unlabeled Images!
Jun 06, 2023



Finetuning a large vision language model (VLM) on a target dataset after large scale pretraining is a dominant paradigm in visual question answering (VQA). Datasets for specialized tasks such as knowledge-based VQA or VQA in non natural-image domains are orders of magnitude smaller than those for general-purpose VQA. While collecting additional labels for specialized tasks or domains can be challenging, unlabeled images are often available. We introduce SelTDA (Self-Taught Data Augmentation), a strategy for finetuning large VLMs on small-scale VQA datasets. SelTDA uses the VLM and target dataset to build a teacher model that can generate question-answer pseudolabels directly conditioned on an image alone, allowing us to pseudolabel unlabeled images. SelTDA then finetunes the initial VLM on the original dataset augmented with freshly pseudolabeled images. We describe a series of experiments showing that our self-taught data augmentation increases robustness to adversarially searched questions, counterfactual examples and rephrasings, improves domain generalization, and results in greater retention of numerical reasoning skills. The proposed strategy requires no additional annotations or architectural modifications, and is compatible with any modern encoder-decoder multimodal transformer. Code available at https://github.com/codezakh/SelTDA.
Single-Stream Multi-Level Alignment for Vision-Language Pretraining
Mar 30, 2022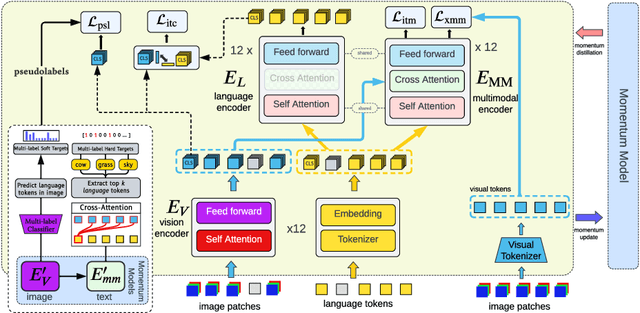
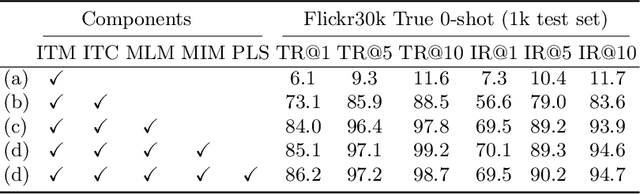
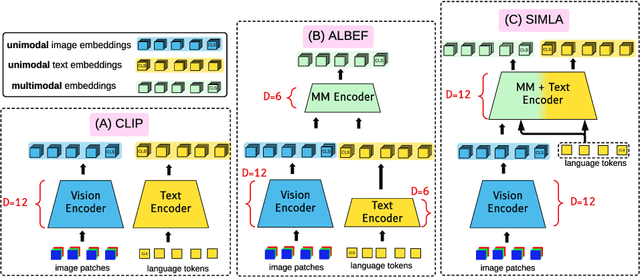
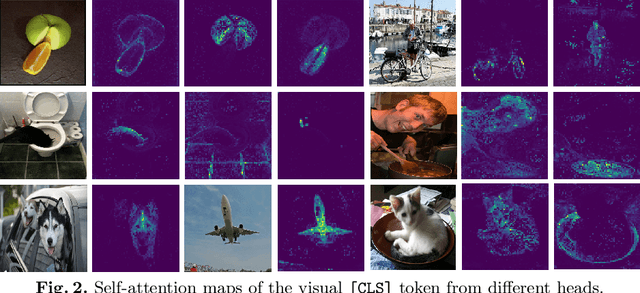
Recent progress in large-scale vision-language pre-training has shown the importance of aligning the visual and text modalities for downstream vision-language tasks. Many methods use a dual-stream architecture that fuses visual tokens and language tokens after representation learning, which aligns only at a global level and cannot extract finer-scale semantics. In contrast, we propose a single stream model that aligns the modalities at multiple levels: i) instance level, ii) fine-grained patch level, iii) conceptual semantic level. We achieve this using two novel tasks: symmetric cross-modality reconstruction and a pseudo-labeled key word prediction. In the former part, we mask the input tokens from one of the modalities and use the cross-modal information to reconstruct the masked token, thus improving fine-grained alignment between the two modalities. In the latter part, we parse the caption to select a few key words and feed it together with the momentum encoder pseudo signal to self-supervise the visual encoder, enforcing it to learn rich semantic concepts that are essential for grounding a textual token to an image region. We demonstrate top performance on a set of Vision-Language downstream tasks such as zero-shot/fine-tuned image/text retrieval, referring expression, and VQA. We also demonstrate how the proposed models can align the modalities at multiple levels.
Large Scale Multimodal Classification Using an Ensemble of Transformer Models and Co-Attention
Nov 23, 2020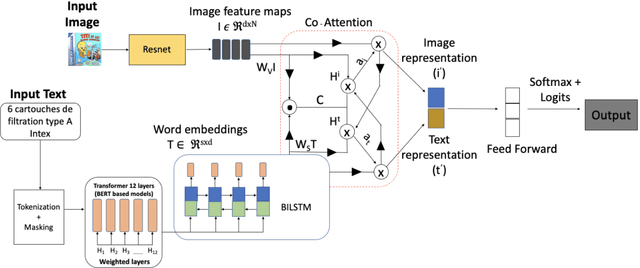


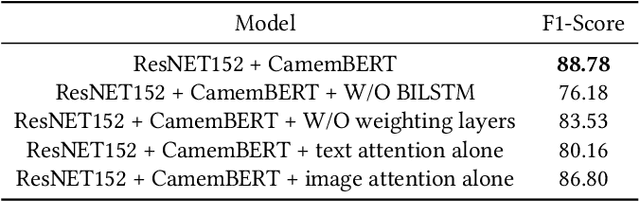
Accurate and efficient product classification is significant for E-commerce applications, as it enables various downstream tasks such as recommendation, retrieval, and pricing. Items often contain textual and visual information, and utilizing both modalities usually outperforms classification utilizing either mode alone. In this paper we describe our methodology and results for the SIGIR eCom Rakuten Data Challenge. We employ a dual attention technique to model image-text relationships using pretrained language and image embeddings. While dual attention has been widely used for Visual Question Answering(VQA) tasks, ours is the first attempt to apply the concept for multimodal classification.
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue
Jul 29, 2016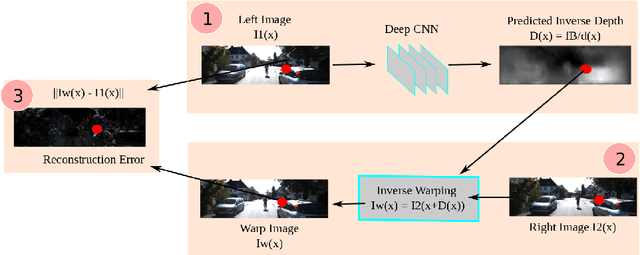
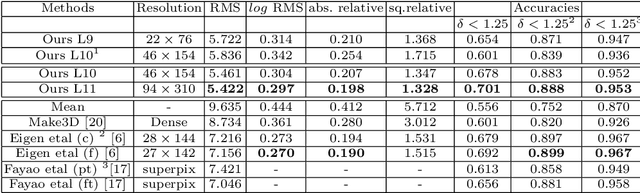
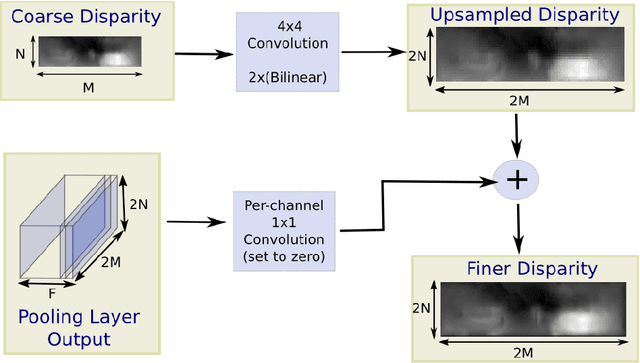
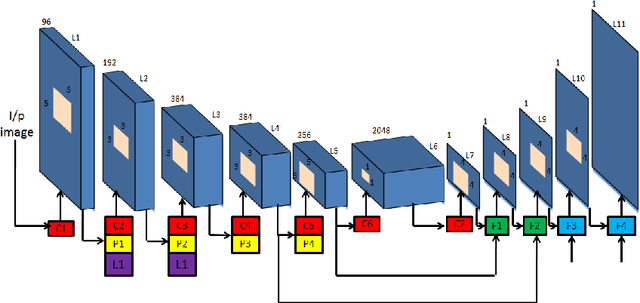
A significant weakness of most current deep Convolutional Neural Networks is the need to train them using vast amounts of manu- ally labelled data. In this work we propose a unsupervised framework to learn a deep convolutional neural network for single view depth predic- tion, without requiring a pre-training stage or annotated ground truth depths. We achieve this by training the network in a manner analogous to an autoencoder. At training time we consider a pair of images, source and target, with small, known camera motion between the two such as a stereo pair. We train the convolutional encoder for the task of predicting the depth map for the source image. To do so, we explicitly generate an inverse warp of the target image using the predicted depth and known inter-view displacement, to reconstruct the source image; the photomet- ric error in the reconstruction is the reconstruction loss for the encoder. The acquisition of this training data is considerably simpler than for equivalent systems, requiring no manual annotation, nor calibration of depth sensor to camera. We show that our network trained on less than half of the KITTI dataset (without any further augmentation) gives com- parable performance to that of the state of art supervised methods for single view depth estimation.