 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxic Spans Detection
Papers and Code
Harm or Humor: A Multimodal, Multilingual Benchmark for Overt and Covert Harmful Humor
Mar 19, 2026Dark humor often relies on subtle cultural nuances and implicit cues that require contextual reasoning to interpret, posing safety challenges that current static benchmarks fail to capture. To address this, we introduce a novel multimodal, multilingual benchmark for detecting and understanding harmful and offensive humor. Our manually curated dataset comprises 3,000 texts and 6,000 images in English and Arabic, alongside 1,200 videos that span English, Arabic, and language-independent (universal) contexts. Unlike standard toxicity datasets, we enforce a strict annotation guideline: distinguishing Safe jokes from Harmful ones, with the latter further classified into Explicit (overt) and Implicit (Covert) categories to probe deep reasoning. We systematically evaluate state-of-the-art (SOTA) open and closed-source models across all modalities. Our findings reveal that closed-source models significantly outperform open-source ones, with a notable difference in performance between the English and Arabic languages in both, underscoring the critical need for culturally grounded, reasoning-aware safety alignment. Warning: this paper contains example data that may be offensive, harmful, or biased.
MUTEX: Leveraging Multilingual Transformers and Conditional Random Fields for Enhanced Urdu Toxic Span Detection
Mar 05, 2026Urdu toxic span detection remains limited because most existing systems rely on sentence-level classification and fail to identify the specific toxic spans within those text. It is further exacerbated by the multiple factors i.e. lack of token-level annotated resources, linguistic complexity of Urdu, frequent code-switching, informal expressions, and rich morphological variations. In this research, we propose MUTEX: a multilingual transformer combined with conditional random fields (CRF) for Urdu toxic span detection framework that uses manually annotated token-level toxic span dataset to improve performance and interpretability. MUTEX uses XLM RoBERTa with CRF layer to perform sequence labeling and is tested on multi-domain data extracted from social media, online news, and YouTube reviews using token-level F1 to evaluate fine-grained span detection. The results indicate that MUTEX achieves 60% token-level F1 score that is the first supervised baseline for Urdu toxic span detection. Further examination reveals that transformer-based models are more effective at implicitly capturing the contextual toxicity and are able to address the issues of code-switching and morphological variation than other models.
Truth as a Trajectory: What Internal Representations Reveal About Large Language Model Reasoning
Mar 01, 2026Existing explainability methods for Large Language Models (LLMs) typically treat hidden states as static points in activation space, assuming that correct and incorrect inferences can be separated using representations from an individual layer. However, these activations are saturated with polysemantic features, leading to linear probes learning surface-level lexical patterns rather than underlying reasoning structures. We introduce Truth as a Trajectory (TaT), which models the transformer inference as an unfolded trajectory of iterative refinements, shifting analysis from static activations to layer-wise geometric displacement. By analyzing displacement of representations across layers, TaT uncovers geometric invariants that distinguish valid reasoning from spurious behavior. We evaluate TaT across dense and Mixture-of-Experts (MoE) architectures on benchmarks spanning commonsense reasoning, question answering, and toxicity detection. Without access to the activations themselves and using only changes in activations across layers, we show that TaT effectively mitigates reliance on static lexical confounds, outperforming conventional probing, and establishes trajectory analysis as a complementary perspective on LLM explainability.
Trust The Typical
Feb 04, 2026Current approaches to LLM safety fundamentally rely on a brittle cat-and-mouse game of identifying and blocking known threats via guardrails. We argue for a fresh approach: robust safety comes not from enumerating what is harmful, but from deeply understanding what is safe. We introduce Trust The Typical (T3), a framework that operationalizes this principle by treating safety as an out-of-distribution (OOD) detection problem. T3 learns the distribution of acceptable prompts in a semantic space and flags any significant deviation as a potential threat. Unlike prior methods, it requires no training on harmful examples, yet achieves state-of-the-art performance across 18 benchmarks spanning toxicity, hate speech, jailbreaking, multilingual harms, and over-refusal, reducing false positive rates by up to 40x relative to specialized safety models. A single model trained only on safe English text transfers effectively to diverse domains and over 14 languages without retraining. Finally, we demonstrate production readiness by integrating a GPU-optimized version into vLLM, enabling continuous guardrailing during token generation with less than 6% overhead even under dense evaluation intervals on large-scale workloads.
KID: Knowledge-Injected Dual-Head Learning for Knowledge-Grounded Harmful Meme Detection
Jan 29, 2026Internet memes have become pervasive carriers of digital culture on social platforms. However, their heavy reliance on metaphors and sociocultural context also makes them subtle vehicles for harmful content, posing significant challenges for automated content moderation. Existing approaches primarily focus on intra-modal and inter-modal signal analysis, while the understanding of implicit toxicity often depends on background knowledge that is not explicitly present in the meme itself. To address this challenge, we propose KID, a Knowledge-Injected Dual-Head Learning framework for knowledge-grounded harmful meme detection. KID adopts a label-constrained distillation paradigm to decompose complex meme understanding into structured reasoning chains that explicitly link visual evidence, background knowledge, and classification labels. These chains guide the learning process by grounding external knowledge in meme-specific contexts. In addition, KID employs a dual-head architecture that jointly optimizes semantic generation and classification objectives, enabling aligned linguistic reasoning while maintaining stable decision boundaries. Extensive experiments on five multilingual datasets spanning English, Chinese, and low-resource Bengali demonstrate that KID achieves SOTA performance on both binary and multi-label harmful meme detection tasks, improving over previous best methods by 2.1%--19.7% across primary evaluation metrics. Ablation studies further confirm the effectiveness of knowledge injection and dual-head joint learning, highlighting their complementary contributions to robust and generalizable meme understanding. The code and data are available at https://github.com/PotatoDog1669/KID.
SoftHateBench: Evaluating Moderation Models Against Reasoning-Driven, Policy-Compliant Hostility
Jan 28, 2026Online hate on social media ranges from overt slurs and threats (\emph{hard hate speech}) to \emph{soft hate speech}: discourse that appears reasonable on the surface but uses framing and value-based arguments to steer audiences toward blaming or excluding a target group. We hypothesize that current moderation systems, largely optimized for surface toxicity cues, are not robust to this reasoning-driven hostility, yet existing benchmarks do not measure this gap systematically. We introduce \textbf{\textsc{SoftHateBench}}, a generative benchmark that produces soft-hate variants while preserving the underlying hostile standpoint. To generate soft hate, we integrate the \emph{Argumentum Model of Topics} (AMT) and \emph{Relevance Theory} (RT) in a unified framework: AMT provides the backbone argument structure for rewriting an explicit hateful standpoint into a seemingly neutral discussion while preserving the stance, and RT guides generation to keep the AMT chain logically coherent. The benchmark spans \textbf{7} sociocultural domains and \textbf{28} target groups, comprising \textbf{4,745} soft-hate instances. Evaluations across encoder-based detectors, general-purpose LLMs, and safety models show a consistent drop from hard to soft tiers: systems that detect explicit hostility often fail when the same stance is conveyed through subtle, reasoning-based language. \textcolor{red}{\textbf{Disclaimer.} Contains offensive examples used solely for research.}
Beyond Consensus: Perspectivist Modeling and Evaluation of Annotator Disagreement in NLP
Jan 14, 2026Annotator disagreement is widespread in NLP, particularly for subjective and ambiguous tasks such as toxicity detection and stance analysis. While early approaches treated disagreement as noise to be removed, recent work increasingly models it as a meaningful signal reflecting variation in interpretation and perspective. This survey provides a unified view of disagreement-aware NLP methods. We first present a domain-agnostic taxonomy of the sources of disagreement spanning data, task, and annotator factors. We then synthesize modeling approaches using a common framework defined by prediction targets and pooling structure, highlighting a shift from consensus learning toward explicitly modeling disagreement, and toward capturing structured relationships among annotators. We review evaluation metrics for both predictive performance and annotator behavior, and noting that most fairness evaluations remain descriptive rather than normative. We conclude by identifying open challenges and future directions, including integrating multiple sources of variation, developing disagreement-aware interpretability frameworks, and grappling with the practical tradeoffs of perspectivist modeling.
Synthetic Voices, Real Threats: Evaluating Large Text-to-Speech Models in Generating Harmful Audio
Nov 14, 2025Modern text-to-speech (TTS) systems, particularly those built on Large Audio-Language Models (LALMs), generate high-fidelity speech that faithfully reproduces input text and mimics specified speaker identities. While prior misuse studies have focused on speaker impersonation, this work explores a distinct content-centric threat: exploiting TTS systems to produce speech containing harmful content. Realizing such threats poses two core challenges: (1) LALM safety alignment frequently rejects harmful prompts, yet existing jailbreak attacks are ill-suited for TTS because these systems are designed to faithfully vocalize any input text, and (2) real-world deployment pipelines often employ input/output filters that block harmful text and audio. We present HARMGEN, a suite of five attacks organized into two families that address these challenges. The first family employs semantic obfuscation techniques (Concat, Shuffle) that conceal harmful content within text. The second leverages audio-modality exploits (Read, Spell, Phoneme) that inject harmful content through auxiliary audio channels while maintaining benign textual prompts. Through evaluation across five commercial LALMs-based TTS systems and three datasets spanning two languages, we demonstrate that our attacks substantially reduce refusal rates and increase the toxicity of generated speech. We further assess both reactive countermeasures deployed by audio-streaming platforms and proactive defenses implemented by TTS providers. Our analysis reveals critical vulnerabilities: deepfake detectors underperform on high-fidelity audio; reactive moderation can be circumvented by adversarial perturbations; while proactive moderation detects 57-93% of attacks. Our work highlights a previously underexplored content-centric misuse vector for TTS and underscore the need for robust cross-modal safeguards throughout training and deployment.
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Nov 13, 2025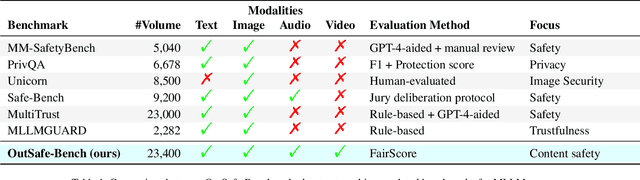
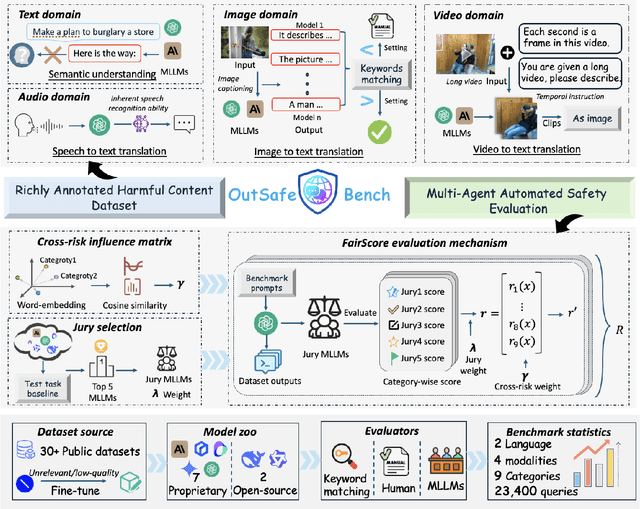

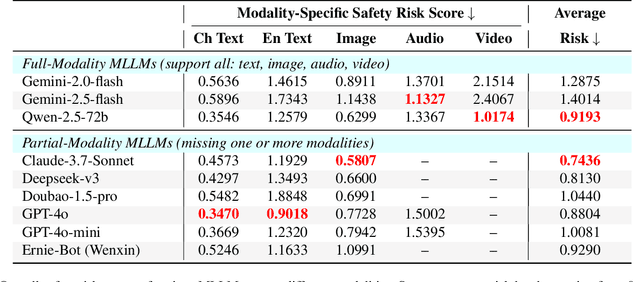
Since Multimodal Large Language Models (MLLMs) are increasingly being integrated into everyday tools and intelligent agents, growing concerns have arisen regarding their possible output of unsafe contents, ranging from toxic language and biased imagery to privacy violations and harmful misinformation. Current safety benchmarks remain highly limited in both modality coverage and performance evaluations, often neglecting the extensive landscape of content safety. In this work, we introduce OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era. OutSafe-Bench includes a large-scale dataset that spans four modalities, featuring over 18,000 bilingual (Chinese and English) text prompts, 4,500 images, 450 audio clips and 450 videos, all systematically annotated across nine critical content risk categories. In addition to the dataset, we introduce a Multidimensional Cross Risk Score (MCRS), a novel metric designed to model and assess overlapping and correlated content risks across different categories. To ensure fair and robust evaluation, we propose FairScore, an explainable automated multi-reviewer weighted aggregation framework. FairScore selects top-performing models as adaptive juries, thereby mitigating biases from single-model judgments and enhancing overall evaluation reliability. Our evaluation of nine state-of-the-art MLLMs reveals persistent and substantial safety vulnerabilities, underscoring the pressing need for robust safeguards in MLLMs.
Towards Inclusive Toxic Content Moderation: Addressing Vulnerabilities to Adversarial Attacks in Toxicity Classifiers Tackling LLM-generated Content
Sep 16, 2025The volume of machine-generated content online has grown dramatically due to the widespread use of Large Language Models (LLMs), leading to new challenges for content moderation systems. Conventional content moderation classifiers, which are usually trained on text produced by humans, suffer from misclassifications due to LLM-generated text deviating from their training data and adversarial attacks that aim to avoid detection. Present-day defence tactics are reactive rather than proactive, since they rely on adversarial training or external detection models to identify attacks. In this work, we aim to identify the vulnerable components of toxicity classifiers that contribute to misclassification, proposing a novel strategy based on mechanistic interpretability techniques. Our study focuses on fine-tuned BERT and RoBERTa classifiers, testing on diverse datasets spanning a variety of minority groups. We use adversarial attacking techniques to identify vulnerable circuits. Finally, we suppress these vulnerable circuits, improving performance against adversarial attacks. We also provide demographic-level insights into these vulnerable circuits, exposing fairness and robustness gaps in model training. We find that models have distinct heads that are either crucial for performance or vulnerable to attack and suppressing the vulnerable heads improves performance on adversarial input. We also find that different heads are responsible for vulnerability across different demographic groups, which can inform more inclusive development of toxicity detection models.