 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust The Typical
Feb 04, 2026Current approaches to LLM safety fundamentally rely on a brittle cat-and-mouse game of identifying and blocking known threats via guardrails. We argue for a fresh approach: robust safety comes not from enumerating what is harmful, but from deeply understanding what is safe. We introduce Trust The Typical (T3), a framework that operationalizes this principle by treating safety as an out-of-distribution (OOD) detection problem. T3 learns the distribution of acceptable prompts in a semantic space and flags any significant deviation as a potential threat. Unlike prior methods, it requires no training on harmful examples, yet achieves state-of-the-art performance across 18 benchmarks spanning toxicity, hate speech, jailbreaking, multilingual harms, and over-refusal, reducing false positive rates by up to 40x relative to specialized safety models. A single model trained only on safe English text transfers effectively to diverse domains and over 14 languages without retraining. Finally, we demonstrate production readiness by integrating a GPU-optimized version into vLLM, enabling continuous guardrailing during token generation with less than 6% overhead even under dense evaluation intervals on large-scale workloads.
Forte : Finding Outliers with Representation Typicality Estimation
Oct 02, 2024



Generative models can now produce photorealistic synthetic data which is virtually indistinguishable from the real data used to train it. This is a significant evolution over previous models which could produce reasonable facsimiles of the training data, but ones which could be visually distinguished from the training data by human evaluation. Recent work on OOD detection has raised doubts that generative model likelihoods are optimal OOD detectors due to issues involving likelihood misestimation, entropy in the generative process, and typicality. We speculate that generative OOD detectors also failed because their models focused on the pixels rather than the semantic content of the data, leading to failures in near-OOD cases where the pixels may be similar but the information content is significantly different. We hypothesize that estimating typical sets using self-supervised learners leads to better OOD detectors. We introduce a novel approach that leverages representation learning, and informative summary statistics based on manifold estimation, to address all of the aforementioned issues. Our method outperforms other unsupervised approaches and achieves state-of-the art performance on well-established challenging benchmarks, and new synthetic data detection tasks.
Augmentations vs Algorithms: What Works in Self-Supervised Learning
Mar 08, 2024



We study the relative effects of data augmentations, pretraining algorithms, and model architectures in Self-Supervised Learning (SSL). While the recent literature in this space leaves the impression that the pretraining algorithm is of critical importance to performance, understanding its effect is complicated by the difficulty in making objective and direct comparisons between methods. We propose a new framework which unifies many seemingly disparate SSL methods into a single shared template. Using this framework, we identify aspects in which methods differ and observe that in addition to changing the pretraining algorithm, many works also use new data augmentations or more powerful model architectures. We compare several popular SSL methods using our framework and find that many algorithmic additions, such as prediction networks or new losses, have a minor impact on downstream task performance (often less than $1\%$), while enhanced augmentation techniques offer more significant performance improvements ($2-4\%$). Our findings challenge the premise that SSL is being driven primarily by algorithmic improvements, and suggest instead a bitter lesson for SSL: that augmentation diversity and data / model scale are more critical contributors to recent advances in self-supervised learning.
Disentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Dec 02, 2023



Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022



Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
What Do We Mean by Generalization in Federated Learning?
Oct 27, 2021
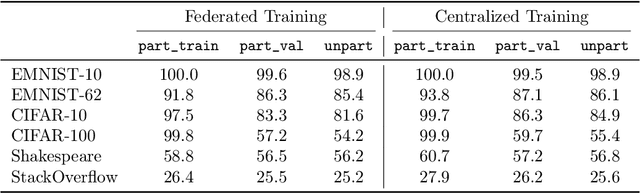
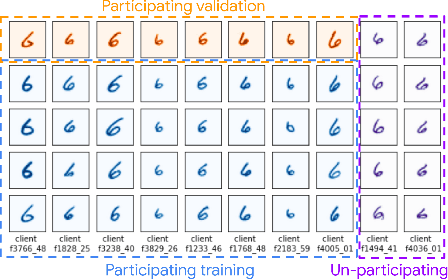
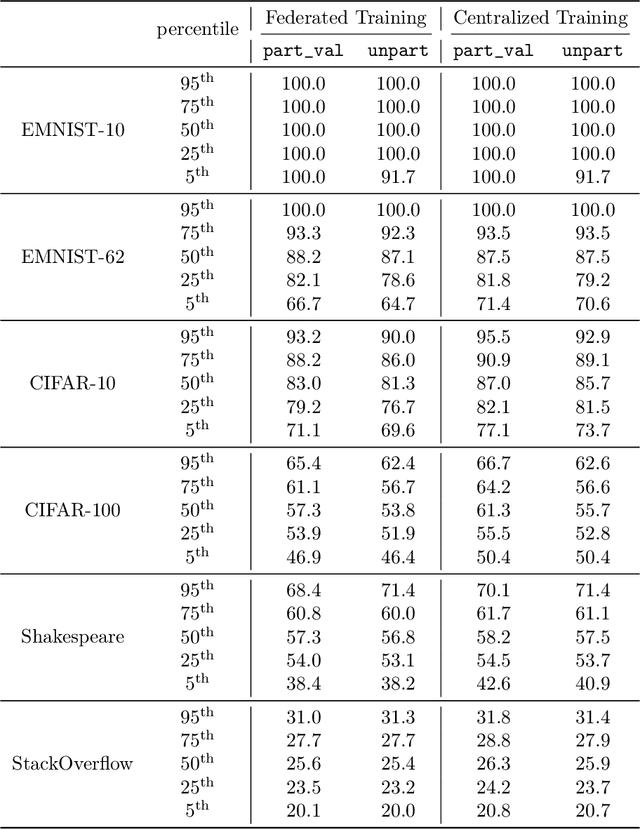
Federated learning data is drawn from a distribution of distributions: clients are drawn from a meta-distribution, and their data are drawn from local data distributions. Thus generalization studies in federated learning should separate performance gaps from unseen client data (out-of-sample gap) from performance gaps from unseen client distributions (participation gap). In this work, we propose a framework for disentangling these performance gaps. Using this framework, we observe and explain differences in behavior across natural and synthetic federated datasets, indicating that dataset synthesis strategy can be important for realistic simulations of generalization in federated learning. We propose a semantic synthesis strategy that enables realistic simulation without naturally-partitioned data. Informed by our findings, we call out community suggestions for future federated learning works.