 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Through Dialogue: Unpacking the Dynamics of Human-LLM Conversations on Political Issues
Jan 12, 2026Large language models (LLMs) are increasingly used as conversational partners for learning, yet the interactional dynamics supporting users' learning and engagement are understudied. We analyze the linguistic and interactional features from both LLM and participant chats across 397 human-LLM conversations about socio-political issues to identify the mechanisms and conditions under which LLM explanations shape changes in political knowledge and confidence. Mediation analyses reveal that LLM explanatory richness partially supports confidence by fostering users' reflective insight, whereas its effect on knowledge gain operates entirely through users' cognitive engagement. Moderation analyses show that these effects are highly conditional and vary by political efficacy. Confidence gains depend on how high-efficacy users experience and resolve uncertainty. Knowledge gains depend on high-efficacy users' ability to leverage extended interaction, with longer conversations benefiting primarily reflective users. In summary, we find that learning from LLMs is an interactional achievement, not a uniform outcome of better explanations. The findings underscore the importance of aligning LLM explanatory behavior with users' engagement states to support effective learning in designing Human-AI interactive systems.
Towards Inclusive Toxic Content Moderation: Addressing Vulnerabilities to Adversarial Attacks in Toxicity Classifiers Tackling LLM-generated Content
Sep 16, 2025The volume of machine-generated content online has grown dramatically due to the widespread use of Large Language Models (LLMs), leading to new challenges for content moderation systems. Conventional content moderation classifiers, which are usually trained on text produced by humans, suffer from misclassifications due to LLM-generated text deviating from their training data and adversarial attacks that aim to avoid detection. Present-day defence tactics are reactive rather than proactive, since they rely on adversarial training or external detection models to identify attacks. In this work, we aim to identify the vulnerable components of toxicity classifiers that contribute to misclassification, proposing a novel strategy based on mechanistic interpretability techniques. Our study focuses on fine-tuned BERT and RoBERTa classifiers, testing on diverse datasets spanning a variety of minority groups. We use adversarial attacking techniques to identify vulnerable circuits. Finally, we suppress these vulnerable circuits, improving performance against adversarial attacks. We also provide demographic-level insights into these vulnerable circuits, exposing fairness and robustness gaps in model training. We find that models have distinct heads that are either crucial for performance or vulnerable to attack and suppressing the vulnerable heads improves performance on adversarial input. We also find that different heads are responsible for vulnerability across different demographic groups, which can inform more inclusive development of toxicity detection models.
Impact of Decoding Methods on Human Alignment of Conversational LLMs
Jul 28, 2024



To be included into chatbot systems, Large language models (LLMs) must be aligned with human conversational conventions. However, being trained mainly on web-scraped data gives existing LLMs a voice closer to informational text than actual human speech. In this paper, we examine the effect of decoding methods on the alignment between LLM-generated and human conversations, including Beam Search, Top K Sampling, and Nucleus Sampling. We present new measures of alignment in substance, style, and psychometric orientation, and experiment with two conversation datasets. Our results provide subtle insights: better alignment is attributed to fewer beams in Beam Search and lower values of P in Nucleus Sampling. We also find that task-oriented and open-ended datasets perform differently in terms of alignment, indicating the significance of taking into account the context of the interaction.
Beyond Text: Leveraging Multi-Task Learning and Cognitive Appraisal Theory for Post-Purchase Intention Analysis
Jul 11, 2024



Supervised machine-learning models for predicting user behavior offer a challenging classification problem with lower average prediction performance scores than other text classification tasks. This study evaluates multi-task learning frameworks grounded in Cognitive Appraisal Theory to predict user behavior as a function of users' self-expression and psychological attributes. Our experiments show that users' language and traits improve predictions above and beyond models predicting only from text. Our findings highlight the importance of integrating psychological constructs into NLP to enhance the understanding and prediction of user actions. We close with a discussion of the implications for future applications of large language models for computational psychology.
Turn-Level Empathy Prediction Using Psychological Indicators
Jul 11, 2024For the WASSA 2024 Empathy and Personality Prediction Shared Task, we propose a novel turn-level empathy detection method that decomposes empathy into six psychological indicators: Emotional Language, Perspective-Taking, Sympathy and Compassion, Extroversion, Openness, and Agreeableness. A pipeline of text enrichment using a Large Language Model (LLM) followed by DeBERTA fine-tuning demonstrates a significant improvement in the Pearson Correlation Coefficient and F1 scores for empathy detection, highlighting the effectiveness of our approach. Our system officially ranked 7th at the CONV-turn track.
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
May 16, 2024



Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
All Should Be Equal in the Eyes of Language Models: Counterfactually Aware Fair Text Generation
Nov 09, 2023Fairness in Language Models (LMs) remains a longstanding challenge, given the inherent biases in training data that can be perpetuated by models and affect the downstream tasks. Recent methods employ expensive retraining or attempt debiasing during inference by constraining model outputs to contrast from a reference set of biased templates or exemplars. Regardless, they dont address the primary goal of fairness to maintain equitability across different demographic groups. In this work, we posit that inferencing LMs to generate unbiased output for one demographic under a context ensues from being aware of outputs for other demographics under the same context. To this end, we propose Counterfactually Aware Fair InferencE (CAFIE), a framework that dynamically compares the model understanding of diverse demographics to generate more equitable sentences. We conduct an extensive empirical evaluation using base LMs of varying sizes and across three diverse datasets and found that CAFIE outperforms strong baselines. CAFIE produces fairer text and strikes the best balance between fairness and language modeling capability
Rhetorical Role Labeling of Legal Documents using Transformers and Graph Neural Networks
May 06, 2023A legal document is usually long and dense requiring human effort to parse it. It also contains significant amounts of jargon which make deriving insights from it using existing models a poor approach. This paper presents the approaches undertaken to perform the task of rhetorical role labelling on Indian Court Judgements as part of SemEval Task 6: understanding legal texts, shared subtask A. We experiment with graph based approaches like Graph Convolutional Networks and Label Propagation Algorithm, and transformer-based approaches including variants of BERT to improve accuracy scores on text classification of complex legal documents.
BITS Pilani at HinglishEval: Quality Evaluation for Code-Mixed Hinglish Text Using Transformers
Jun 17, 2022
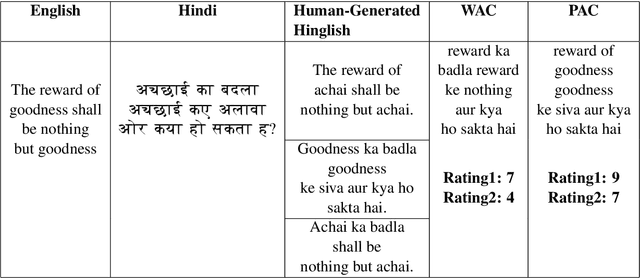
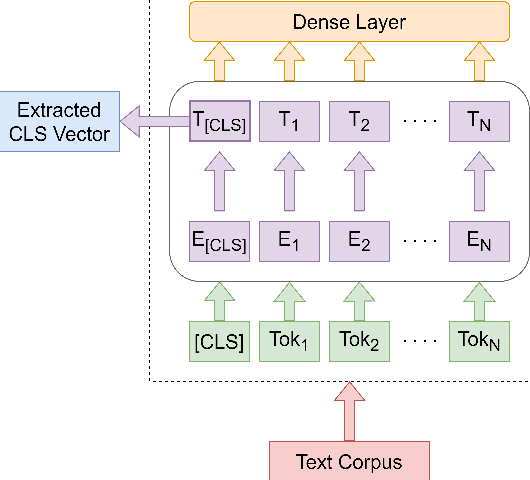
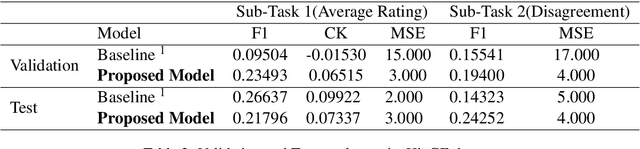
Code-Mixed text data consists of sentences having words or phrases from more than one language. Most multi-lingual communities worldwide communicate using multiple languages, with English usually one of them. Hinglish is a Code-Mixed text composed of Hindi and English but written in Roman script. This paper aims to determine the factors influencing the quality of Code-Mixed text data generated by the system. For the HinglishEval task, the proposed model uses multi-lingual BERT to find the similarity between synthetically generated and human-generated sentences to predict the quality of synthetically generated Hinglish sentences.