 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Voices, Real Threats: Evaluating Large Text-to-Speech Models in Generating Harmful Audio
Nov 14, 2025Modern text-to-speech (TTS) systems, particularly those built on Large Audio-Language Models (LALMs), generate high-fidelity speech that faithfully reproduces input text and mimics specified speaker identities. While prior misuse studies have focused on speaker impersonation, this work explores a distinct content-centric threat: exploiting TTS systems to produce speech containing harmful content. Realizing such threats poses two core challenges: (1) LALM safety alignment frequently rejects harmful prompts, yet existing jailbreak attacks are ill-suited for TTS because these systems are designed to faithfully vocalize any input text, and (2) real-world deployment pipelines often employ input/output filters that block harmful text and audio. We present HARMGEN, a suite of five attacks organized into two families that address these challenges. The first family employs semantic obfuscation techniques (Concat, Shuffle) that conceal harmful content within text. The second leverages audio-modality exploits (Read, Spell, Phoneme) that inject harmful content through auxiliary audio channels while maintaining benign textual prompts. Through evaluation across five commercial LALMs-based TTS systems and three datasets spanning two languages, we demonstrate that our attacks substantially reduce refusal rates and increase the toxicity of generated speech. We further assess both reactive countermeasures deployed by audio-streaming platforms and proactive defenses implemented by TTS providers. Our analysis reveals critical vulnerabilities: deepfake detectors underperform on high-fidelity audio; reactive moderation can be circumvented by adversarial perturbations; while proactive moderation detects 57-93% of attacks. Our work highlights a previously underexplored content-centric misuse vector for TTS and underscore the need for robust cross-modal safeguards throughout training and deployment.
AudioJailbreak: Jailbreak Attacks against End-to-End Large Audio-Language Models
May 21, 2025



Jailbreak attacks to Large audio-language models (LALMs) are studied recently, but they achieve suboptimal effectiveness, applicability, and practicability, particularly, assuming that the adversary can fully manipulate user prompts. In this work, we first conduct an extensive experiment showing that advanced text jailbreak attacks cannot be easily ported to end-to-end LALMs via text-to speech (TTS) techniques. We then propose AudioJailbreak, a novel audio jailbreak attack, featuring (1) asynchrony: the jailbreak audio does not need to align with user prompts in the time axis by crafting suffixal jailbreak audios; (2) universality: a single jailbreak perturbation is effective for different prompts by incorporating multiple prompts into perturbation generation; (3) stealthiness: the malicious intent of jailbreak audios will not raise the awareness of victims by proposing various intent concealment strategies; and (4) over-the-air robustness: the jailbreak audios remain effective when being played over the air by incorporating the reverberation distortion effect with room impulse response into the generation of the perturbations. In contrast, all prior audio jailbreak attacks cannot offer asynchrony, universality, stealthiness, or over-the-air robustness. Moreover, AudioJailbreak is also applicable to the adversary who cannot fully manipulate user prompts, thus has a much broader attack scenario. Extensive experiments with thus far the most LALMs demonstrate the high effectiveness of AudioJailbreak. We highlight that our work peeks into the security implications of audio jailbreak attacks against LALMs, and realistically fosters improving their security robustness. The implementation and audio samples are available at our website https://audiojailbreak.github.io/AudioJailbreak.
LaserGuider: A Laser Based Physical Backdoor Attack against Deep Neural Networks
Dec 05, 2024



Backdoor attacks embed hidden associations between triggers and targets in deep neural networks (DNNs), causing them to predict the target when a trigger is present while maintaining normal behavior otherwise. Physical backdoor attacks, which use physical objects as triggers, are feasible but lack remote control, temporal stealthiness, flexibility, and mobility. To overcome these limitations, in this work, we propose a new type of backdoor triggers utilizing lasers that feature long-distance transmission and instant-imaging properties. Based on the laser-based backdoor triggers, we present a physical backdoor attack, called LaserGuider, which possesses remote control ability and achieves high temporal stealthiness, flexibility, and mobility. We also introduce a systematic approach to optimize laser parameters for improving attack effectiveness. Our evaluation on traffic sign recognition DNNs, critical in autonomous vehicles, demonstrates that LaserGuider with three different laser-based triggers achieves over 90% attack success rate with negligible impact on normal inputs. Additionally, we release LaserMark, the first dataset of real world traffic signs stamped with physical laser spots, to support further research in backdoor attacks and defenses.
A Proactive and Dual Prevention Mechanism against Illegal Song Covers empowered by Singing Voice Conversion
Jan 30, 2024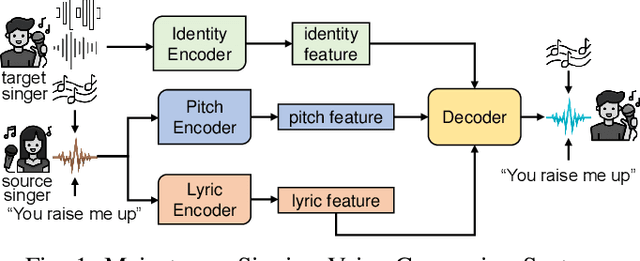
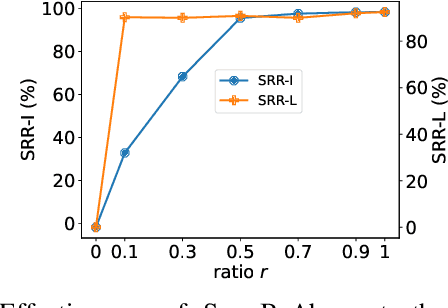
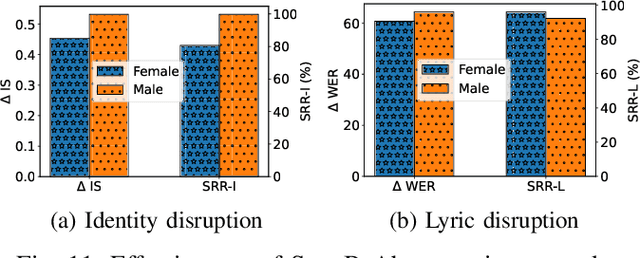
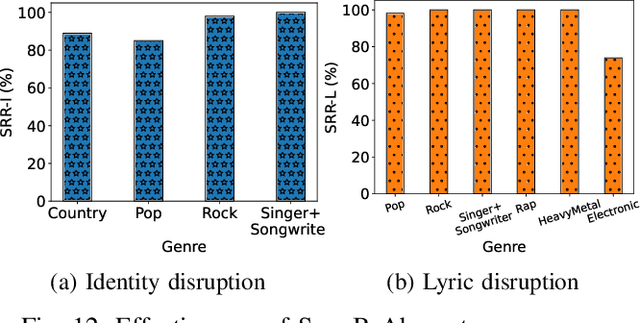
Singing voice conversion (SVC) automates song covers by converting one singer's singing voice into another target singer's singing voice with the original lyrics and melody. However, it raises serious concerns about copyright and civil right infringements to multiple entities. This work proposes SongBsAb, the first proactive approach to mitigate unauthorized SVC-based illegal song covers. SongBsAb introduces human-imperceptible perturbations to singing voices before releasing them, so that when they are used, the generation process of SVC will be interfered, resulting in unexpected singing voices. SongBsAb features a dual prevention effect by causing both (singer) identity disruption and lyric disruption, namely, the SVC-covered singing voice neither imitates the target singer nor preserves the original lyrics. To improve the imperceptibility of perturbations, we refine a psychoacoustic model-based loss with the backing track as an additional masker, a unique accompanying element for singing voices compared to ordinary speech voices. To enhance the transferability, we propose to utilize a frame-level interaction reduction-based loss. We demonstrate the prevention effectiveness, utility, and robustness of SongBsAb on three SVC models and two datasets using both objective and human study-based subjective metrics. Our work fosters an emerging research direction for mitigating illegal automated song covers.
SLMIA-SR: Speaker-Level Membership Inference Attacks against Speaker Recognition Systems
Sep 14, 2023Membership inference attacks allow adversaries to determine whether a particular example was contained in the model's training dataset. While previous works have confirmed the feasibility of such attacks in various applications, none has focused on speaker recognition (SR), a promising voice-based biometric recognition technique. In this work, we propose SLMIA-SR, the first membership inference attack tailored to SR. In contrast to conventional example-level attack, our attack features speaker-level membership inference, i.e., determining if any voices of a given speaker, either the same as or different from the given inference voices, have been involved in the training of a model. It is particularly useful and practical since the training and inference voices are usually distinct, and it is also meaningful considering the open-set nature of SR, namely, the recognition speakers were often not present in the training data. We utilize intra-closeness and inter-farness, two training objectives of SR, to characterize the differences between training and non-training speakers and quantify them with two groups of features driven by carefully-established feature engineering to mount the attack. To improve the generalizability of our attack, we propose a novel mixing ratio training strategy to train attack models. To enhance the attack performance, we introduce voice chunk splitting to cope with the limited number of inference voices and propose to train attack models dependent on the number of inference voices. Our attack is versatile and can work in both white-box and black-box scenarios. Additionally, we propose two novel techniques to reduce the number of black-box queries while maintaining the attack performance. Extensive experiments demonstrate the effectiveness of SLMIA-SR.
QFA2SR: Query-Free Adversarial Transfer Attacks to Speaker Recognition Systems
May 23, 2023Current adversarial attacks against speaker recognition systems (SRSs) require either white-box access or heavy black-box queries to the target SRS, thus still falling behind practical attacks against proprietary commercial APIs and voice-controlled devices. To fill this gap, we propose QFA2SR, an effective and imperceptible query-free black-box attack, by leveraging the transferability of adversarial voices. To improve transferability, we present three novel methods, tailored loss functions, SRS ensemble, and time-freq corrosion. The first one tailors loss functions to different attack scenarios. The latter two augment surrogate SRSs in two different ways. SRS ensemble combines diverse surrogate SRSs with new strategies, amenable to the unique scoring characteristics of SRSs. Time-freq corrosion augments surrogate SRSs by incorporating well-designed time-/frequency-domain modification functions, which simulate and approximate the decision boundary of the target SRS and distortions introduced during over-the-air attacks. QFA2SR boosts the targeted transferability by 20.9%-70.7% on four popular commercial APIs (Microsoft Azure, iFlytek, Jingdong, and TalentedSoft), significantly outperforming existing attacks in query-free setting, with negligible effect on the imperceptibility. QFA2SR is also highly effective when launched over the air against three wide-spread voice assistants (Google Assistant, Apple Siri, and TMall Genie) with 60%, 46%, and 70% targeted transferability, respectively.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022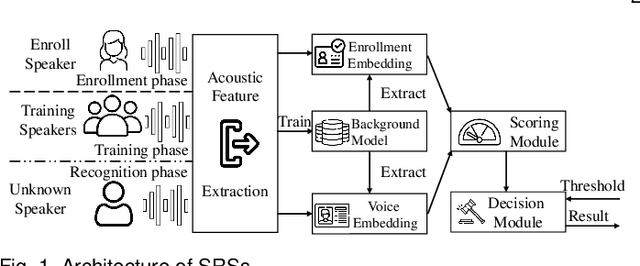
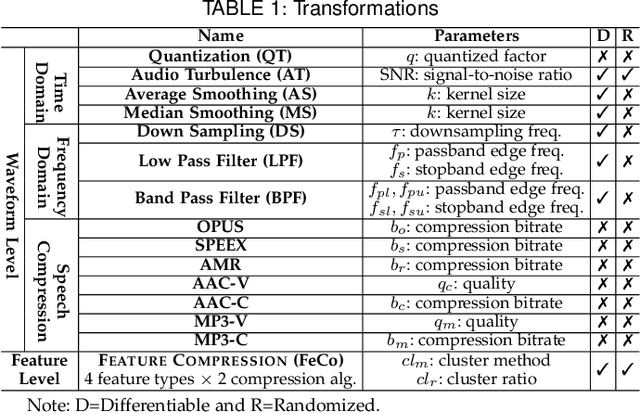
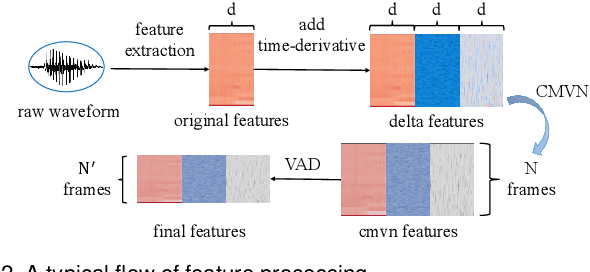
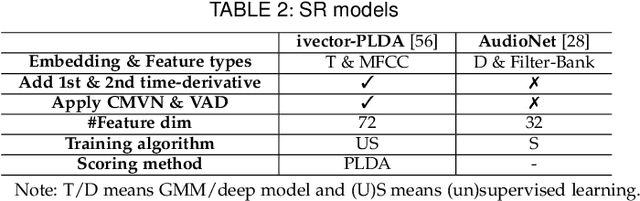
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
AS2T: Arbitrary Source-To-Target Adversarial Attack on Speaker Recognition Systems
Jun 07, 2022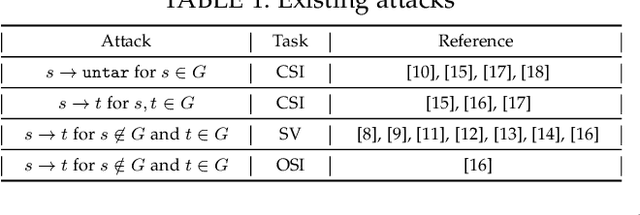
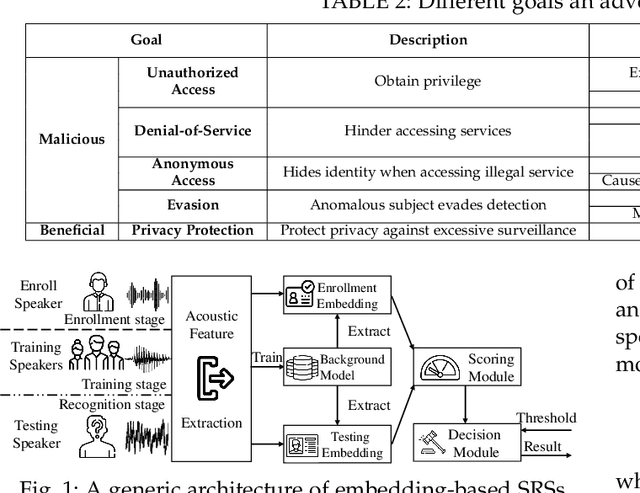
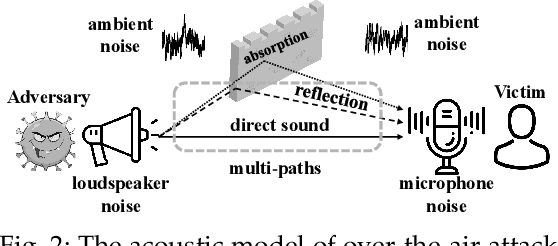
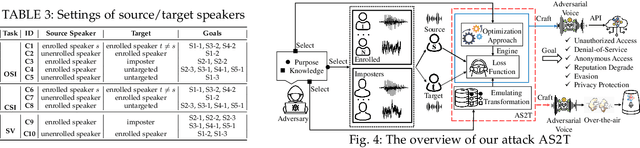
Recent work has illuminated the vulnerability of speaker recognition systems (SRSs) against adversarial attacks, raising significant security concerns in deploying SRSs. However, they considered only a few settings (e.g., some combinations of source and target speakers), leaving many interesting and important settings in real-world attack scenarios alone. In this work, we present AS2T, the first attack in this domain which covers all the settings, thus allows the adversary to craft adversarial voices using arbitrary source and target speakers for any of three main recognition tasks. Since none of the existing loss functions can be applied to all the settings, we explore many candidate loss functions for each setting including the existing and newly designed ones. We thoroughly evaluate their efficacy and find that some existing loss functions are suboptimal. Then, to improve the robustness of AS2T towards practical over-the-air attack, we study the possible distortions occurred in over-the-air transmission, utilize different transformation functions with different parameters to model those distortions, and incorporate them into the generation of adversarial voices. Our simulated over-the-air evaluation validates the effectiveness of our solution in producing robust adversarial voices which remain effective under various hardware devices and various acoustic environments with different reverberation, ambient noises, and noise levels. Finally, we leverage AS2T to perform thus far the largest-scale evaluation to understand transferability among 14 diverse SRSs. The transferability analysis provides many interesting and useful insights which challenge several findings and conclusion drawn in previous works in the image domain. Our study also sheds light on future directions of adversarial attacks in the speaker recognition domain.
SEC4SR: A Security Analysis Platform for Speaker Recognition
Sep 04, 2021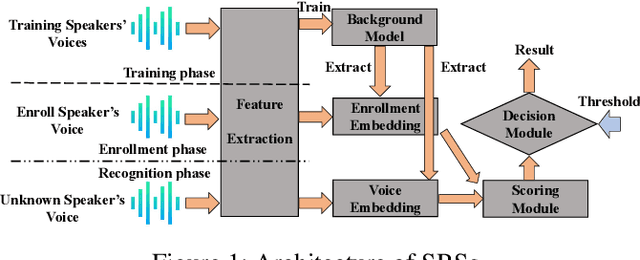
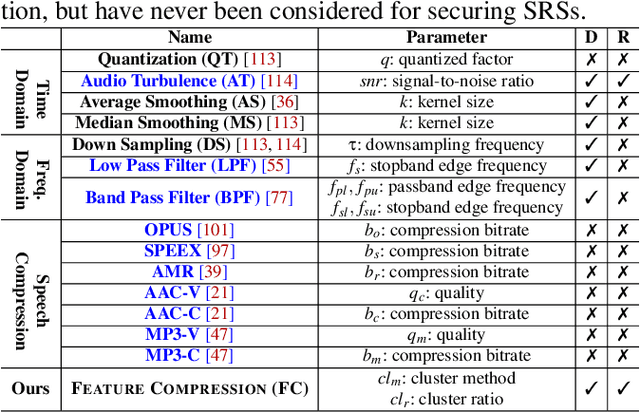
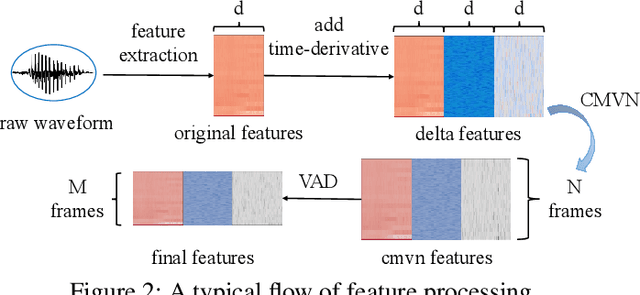
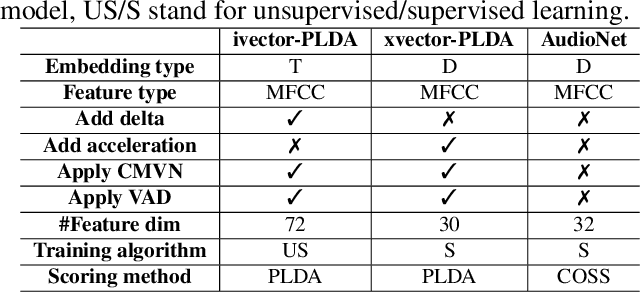
Adversarial attacks have been expanded to speaker recognition (SR). However, existing attacks are often assessed using different SR models, recognition tasks and datasets, and only few adversarial defenses borrowed from computer vision are considered. Yet,these defenses have not been thoroughly evaluated against adaptive attacks. Thus, there is still a lack of quantitative understanding about the strengths and limitations of adversarial attacks and defenses. More effective defenses are also required for securing SR systems. To bridge this gap, we present SEC4SR, the first platform enabling researchers to systematically and comprehensively evaluate adversarial attacks and defenses in SR. SEC4SR incorporates 4 white-box and 2 black-box attacks, 24 defenses including our novel feature-level transformations. It also contains techniques for mounting adaptive attacks. Using SEC4SR, we conduct thus far the largest-scale empirical study on adversarial attacks and defenses in SR, involving 23 defenses, 15 attacks and 4 attack settings. Our study provides lots of useful findings that may advance future research: such as (1) all the transformations slightly degrade accuracy on benign examples and their effectiveness vary with attacks; (2) most transformations become less effective under adaptive attacks, but some transformations become more effective; (3) few transformations combined with adversarial training yield stronger defenses over some but not all attacks, while our feature-level transformation combined with adversarial training yields the strongest defense over all the attacks. Extensive experiments demonstrate capabilities and advantages of SEC4SR which can benefit future research in SR.
Attack as Defense: Characterizing Adversarial Examples using Robustness
Mar 13, 2021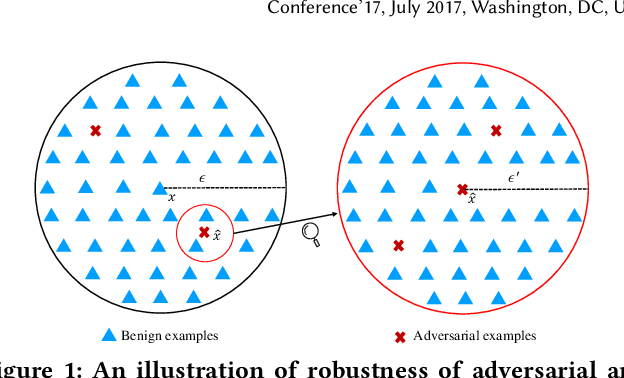
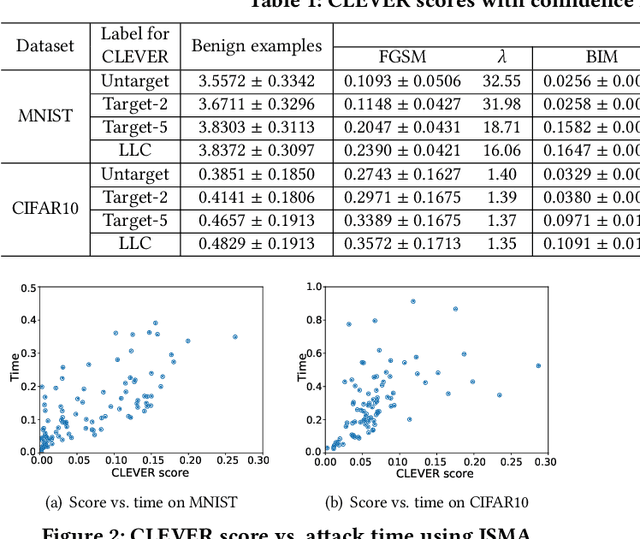
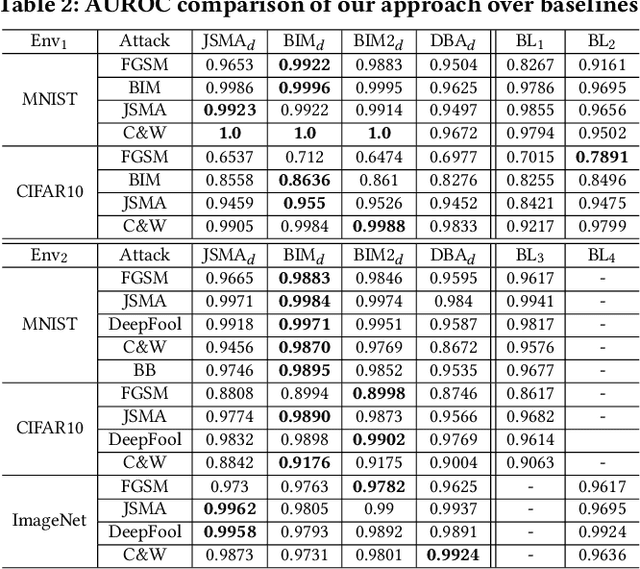
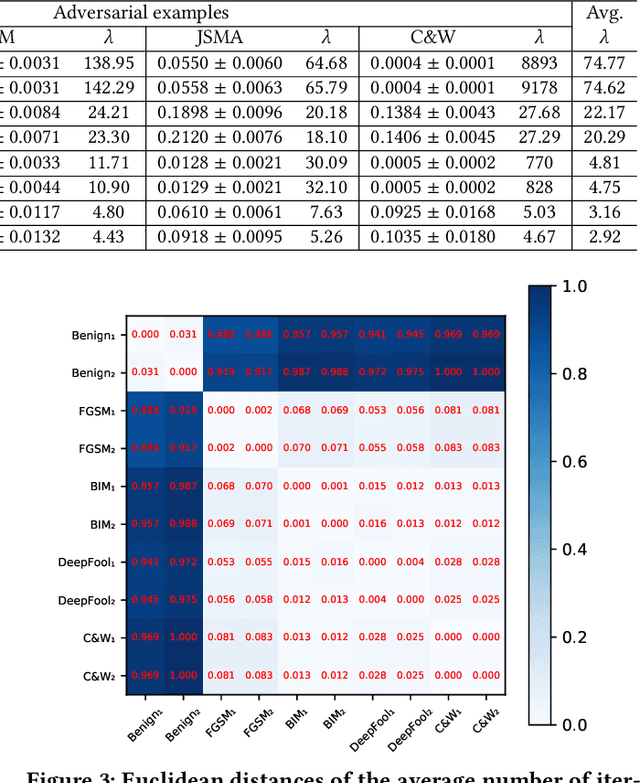
As a new programming paradigm, deep learning has expanded its application to many real-world problems. At the same time, deep learning based software are found to be vulnerable to adversarial attacks. Though various defense mechanisms have been proposed to improve robustness of deep learning software, many of them are ineffective against adaptive attacks. In this work, we propose a novel characterization to distinguish adversarial examples from benign ones based on the observation that adversarial examples are significantly less robust than benign ones. As existing robustness measurement does not scale to large networks, we propose a novel defense framework, named attack as defense (A2D), to detect adversarial examples by effectively evaluating an example's robustness. A2D uses the cost of attacking an input for robustness evaluation and identifies those less robust examples as adversarial since less robust examples are easier to attack. Extensive experiment results on MNIST, CIFAR10 and ImageNet show that A2D is more effective than recent promising approaches. We also evaluate our defence against potential adaptive attacks and show that A2D is effective in defending carefully designed adaptive attacks, e.g., the attack success rate drops to 0% on CIFAR10.