 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxibj
Papers and Code
PredFormer: Transformers Are Effective Spatial-Temporal Predictive Learners
Oct 07, 2024



Spatiotemporal predictive learning methods generally fall into two categories: recurrent-based approaches, which face challenges in parallelization and performance, and recurrent-free methods, which employ convolutional neural networks (CNNs) as encoder-decoder architectures. These methods benefit from strong inductive biases but often at the expense of scalability and generalization. This paper proposes PredFormer, a pure transformer-based framework for spatiotemporal predictive learning. Motivated by the Vision Transformers (ViT) design, PredFormer leverages carefully designed Gated Transformer blocks, following a comprehensive analysis of 3D attention mechanisms, including full-, factorized-, and interleaved- spatial-temporal attention. With its recurrent-free, transformer-based design, PredFormer is both simple and efficient, significantly outperforming previous methods by large margins. Extensive experiments on synthetic and real-world datasets demonstrate that PredFormer achieves state-of-the-art performance. On Moving MNIST, PredFormer achieves a 51.3% reduction in MSE relative to SimVP. For TaxiBJ, the model decreases MSE by 33.1% and boosts FPS from 533 to 2364. Additionally, on WeatherBench, it reduces MSE by 11.1% while enhancing FPS from 196 to 404. These performance gains in both accuracy and efficiency demonstrate PredFormer's potential for real-world applications. The source code will be released at https://github.com/yyyujintang/PredFormer.
Multiple Areal Feature Aware Transportation Demand Prediction
Aug 23, 2024



A reliable short-term transportation demand prediction supports the authorities in improving the capability of systems by optimizing schedules, adjusting fleet sizes, and generating new transit networks. A handful of research efforts incorporate one or a few areal features while learning spatio-temporal correlation, to capture similar demand patterns between similar areas. However, urban characteristics are polymorphic, and they need to be understood by multiple areal features such as land use, sociodemographics, and place-of-interest (POI) distribution. In this paper, we propose a novel spatio-temporal multi-feature-aware graph convolutional recurrent network (ST-MFGCRN) that fuses multiple areal features during spatio-temproal understanding. Inside ST-MFGCRN, we devise sentinel attention to calculate the areal similarity matrix by allowing each area to take partial attention if the feature is not useful. We evaluate the proposed model on two real-world transportation datasets, one with our constructed BusDJ dataset and one with benchmark TaxiBJ. Results show that our model outperforms the state-of-the-art baselines up to 7\% on BusDJ and 8\% on TaxiBJ dataset.
SwinLSTM:Improving Spatiotemporal Prediction Accuracy using Swin Transformer and LSTM
Aug 19, 2023Integrating CNNs and RNNs to capture spatiotemporal dependencies is a prevalent strategy for spatiotemporal prediction tasks. However, the property of CNNs to learn local spatial information decreases their efficiency in capturing spatiotemporal dependencies, thereby limiting their prediction accuracy. In this paper, we propose a new recurrent cell, SwinLSTM, which integrates Swin Transformer blocks and the simplified LSTM, an extension that replaces the convolutional structure in ConvLSTM with the self-attention mechanism. Furthermore, we construct a network with SwinLSTM cell as the core for spatiotemporal prediction. Without using unique tricks, SwinLSTM outperforms state-of-the-art methods on Moving MNIST, Human3.6m, TaxiBJ, and KTH datasets. In particular, it exhibits a significant improvement in prediction accuracy compared to ConvLSTM. Our competitive experimental results demonstrate that learning global spatial dependencies is more advantageous for models to capture spatiotemporal dependencies. We hope that SwinLSTM can serve as a solid baseline to promote the advancement of spatiotemporal prediction accuracy. The codes are publicly available at https://github.com/SongTang-x/SwinLSTM.
Fast Fourier Inception Networks for Occluded Video Prediction
Jun 17, 2023Video prediction is a pixel-level task that generates future frames by employing the historical frames. There often exist continuous complex motions, such as object overlapping and scene occlusion in video, which poses great challenges to this task. Previous works either fail to well capture the long-term temporal dynamics or do not handle the occlusion masks. To address these issues, we develop the fully convolutional Fast Fourier Inception Networks for video prediction, termed \textit{FFINet}, which includes two primary components, \ie, the occlusion inpainter and the spatiotemporal translator. The former adopts the fast Fourier convolutions to enlarge the receptive field, such that the missing areas (occlusion) with complex geometric structures are filled by the inpainter. The latter employs the stacked Fourier transform inception module to learn the temporal evolution by group convolutions and the spatial movement by channel-wise Fourier convolutions, which captures both the local and the global spatiotemporal features. This encourages generating more realistic and high-quality future frames. To optimize the model, the recovery loss is imposed to the objective, \ie, minimizing the mean square error between the ground-truth frame and the recovery frame. Both quantitative and qualitative experimental results on five benchmarks, including Moving MNIST, TaxiBJ, Human3.6M, Caltech Pedestrian, and KTH, have demonstrated the superiority of the proposed approach. Our code is available at GitHub.
MS-RNN: A Flexible Multi-Scale Framework for Spatiotemporal Predictive Learning
Jun 07, 2022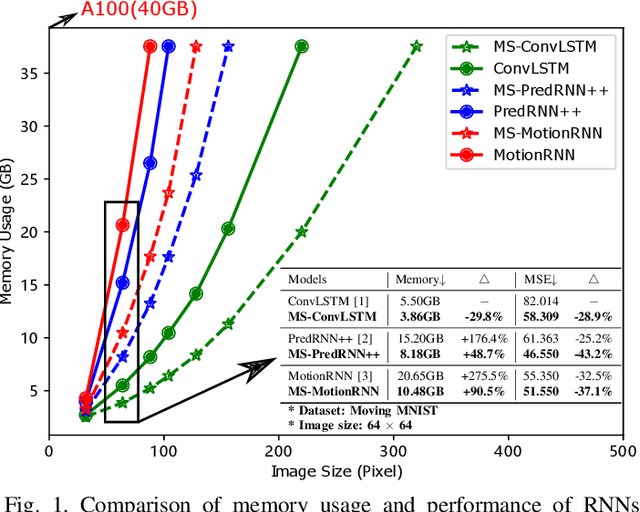
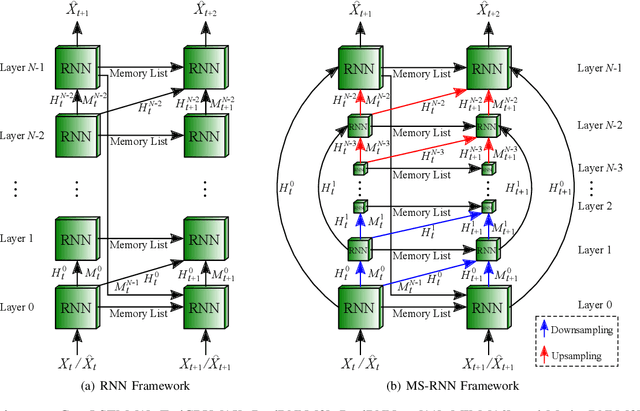


Spatiotemporal predictive learning is to predict future frames changes through historical prior knowledge. Previous work improves prediction performance by making the network wider and deeper, but this also brings huge memory overhead, which seriously hinders the development and application of the technology. Scale is another dimension to improve model performance in common computer vision task, which can decrease the computing requirements and better sense of context. Such an important improvement point has not been considered and explored by recent RNN models. In this paper, learning from the benefit of multi-scale, we propose a general framework named Multi-Scale RNN (MS-RNN) to boost recent RNN models. We verify the MS-RNN framework by exhaustive experiments on 4 different datasets (Moving MNIST, KTH, TaxiBJ, and HKO-7) and multiple popular RNN models (ConvLSTM, TrajGRU, PredRNN, PredRNN++, MIM, and MotionRNN). The results show the efficiency that the RNN models incorporating our framework have much lower memory cost but better performance than before. Our code is released at \url{https://github.com/mazhf/MS-RNN}.
Taylor saves for later: disentanglement for video prediction using Taylor representation
May 24, 2021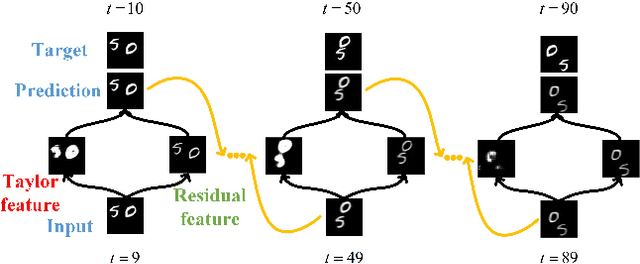
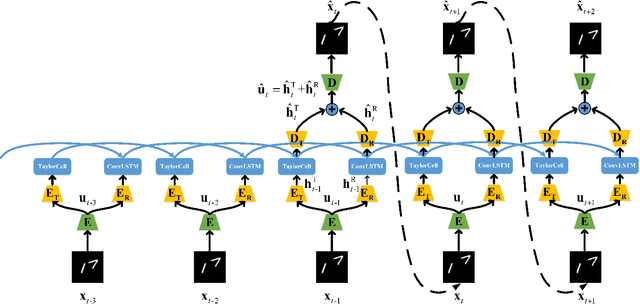
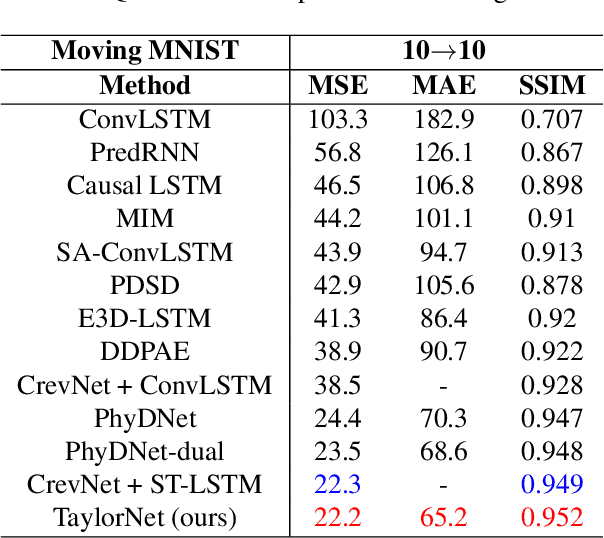
Video prediction is a challenging task with wide application prospects in meteorology and robot systems. Existing works fail to trade off short-term and long-term prediction performances and extract robust latent dynamics laws in video frames. We propose a two-branch seq-to-seq deep model to disentangle the Taylor feature and the residual feature in video frames by a novel recurrent prediction module (TaylorCell) and residual module. TaylorCell can expand the video frames' high-dimensional features into the finite Taylor series to describe the latent laws. In TaylorCell, we propose the Taylor prediction unit (TPU) and the memory correction unit (MCU). TPU employs the first input frame's derivative information to predict the future frames, avoiding error accumulation. MCU distills all past frames' information to correct the predicted Taylor feature from TPU. Correspondingly, the residual module extracts the residual feature complementary to the Taylor feature. On three generalist datasets (Moving MNIST, TaxiBJ, Human 3.6), our model outperforms or reaches state-of-the-art models, and ablation experiments demonstrate the effectiveness of our model in long-term prediction.
CMS-LSTM: Context-Embedding and Multi-Scale Spatiotemporal-Expression LSTM for Video Prediction
Feb 06, 2021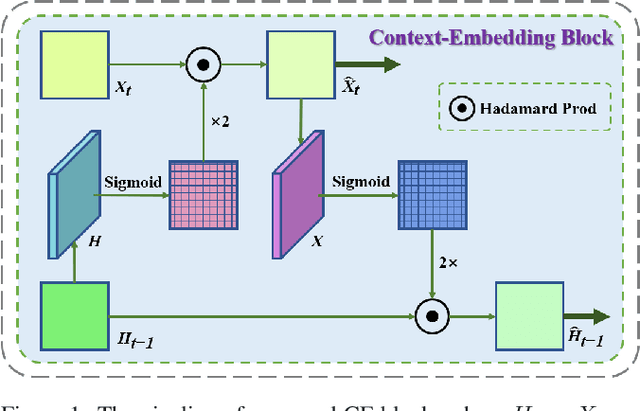
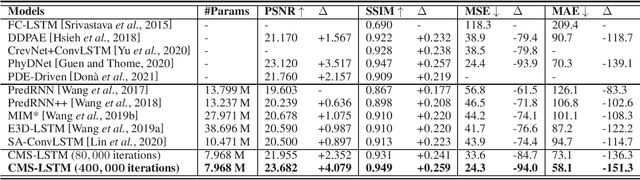
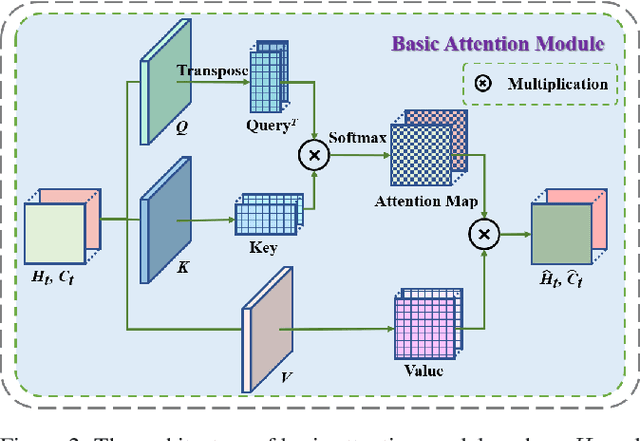
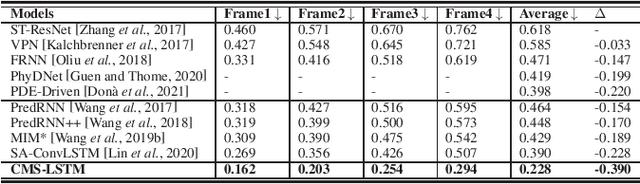
Extracting variation and spatiotemporal features via limited frames remains as an unsolved and challenging problem in video prediction. Inherent uncertainty among consecutive frames exacerbates the difficulty in long-term prediction. To tackle the problem, we focus on capturing context correlations and multi-scale spatiotemporal flows, then propose CMS-LSTM by integrating two effective and lightweight blocks, namely Context-Embedding (CE) and Spatiotemporal-Expression (SE) block, into ConvLSTM backbone. CE block is designed for abundant context interactions, while SE block focuses on multi-scale spatiotemporal expression in hidden states. The newly introduced blocks also facilitate other spatiotemporal models (e.g., PredRNN, SA-ConvLSTM) to produce representative implicit features for video prediction. Qualitative and quantitative experiments demonstrate the effectiveness and flexibility of our proposed method. We use fewer parameters to reach markedly state-of-the-art results on Moving MNIST and TaxiBJ datasets in numbers of metrics. All source code is available at https://github.com/czh-98/CMS-LSTM.
UrbanFM: Inferring Fine-Grained Urban Flows
Feb 06, 2019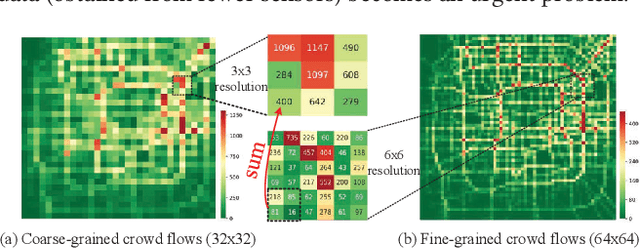
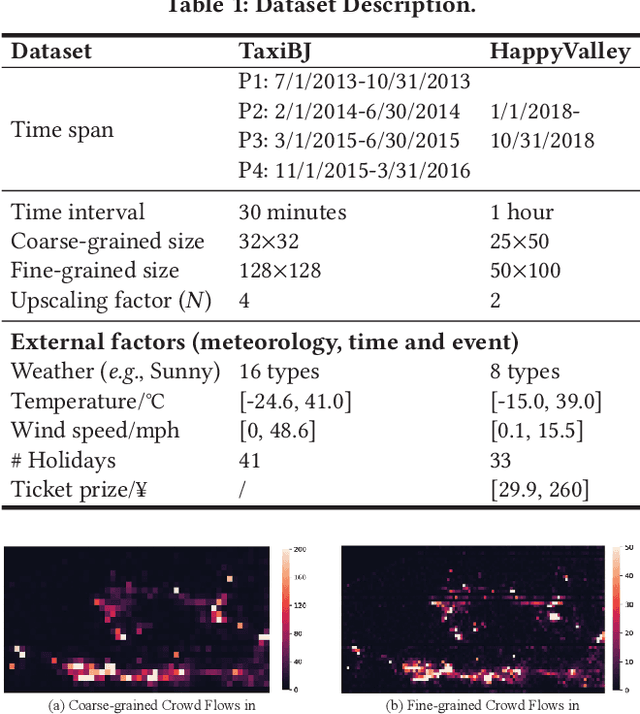
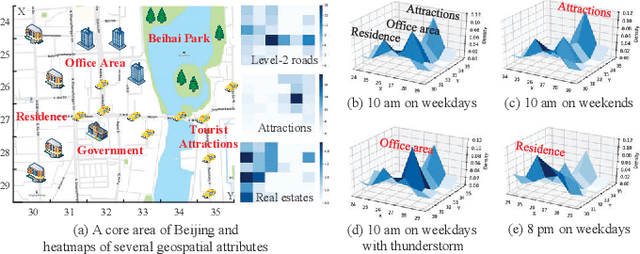
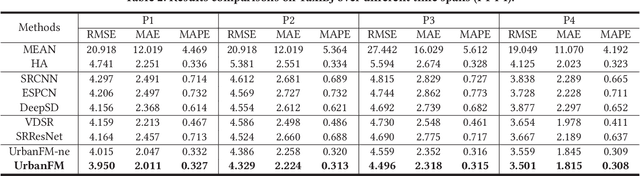
Urban flow monitoring systems play important roles in smart city efforts around the world. However, the ubiquitous deployment of monitoring devices, such as CCTVs, induces a long-lasting and enormous cost for maintenance and operation. This suggests the need for a technology that can reduce the number of deployed devices, while preventing the degeneration of data accuracy and granularity. In this paper, we aim to infer the real-time and fine-grained crowd flows throughout a city based on coarse-grained observations. This task is challenging due to two reasons: the spatial correlations between coarse- and fine-grained urban flows, and the complexities of external impacts. To tackle these issues, we develop a method entitled UrbanFM based on deep neural networks. Our model consists of two major parts: 1) an inference network to generate fine-grained flow distributions from coarse-grained inputs by using a feature extraction module and a novel distributional upsampling module; 2) a general fusion subnet to further boost the performance by considering the influences of different external factors. Extensive experiments on two real-world datasets, namely TaxiBJ and HappyValley, validate the effectiveness and efficiency of our method compared to seven baselines, demonstrating the state-of-the-art performance of our approach on the fine-grained urban flow inference problem.