 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Weaknesses: Automated Domain Specialization for Small Computer-Use Agents
May 27, 2026Computer-use agents (CUAs) have recently made substantial progress, but deploying a separate large expert for each software domain remains expensive. Small open computer-use agents are more practical specialization targets, but they remain substantially weaker and exhibit uneven domain-specific failures. A straightforward remedy is to synthesize large-scale training data for the target domain, yet we find that this naive approach yields only marginal improvements. Building on this observation, we introduce LearnWeak, an annotation-free specialization framework for small computer-use agents that uses a stronger reference agent to identify the student's weaknesses in the target domain, synthesize targeted tasks, and construct supervision automatically. LearnWeak further introduces an error-aware specialization objective that disentangles planning and execution errors, enabling more behaviorally precise updates than broad uniform supervision. On OSWorld, LearnWeak achieves average gains of 11.6 and 11.1 percentage points over EvoCUA-8B and OpenCUA-7B, respectively, across eight domains. We also validate that our student-aware dataset generation and training approaches outperform existing autonomous trajectory generation and training baselines. Our work highlights the importance of student awareness in both data synthesis and agent training, pointing toward a more principled and efficient path for specializing small computer-use agents in diverse domains.
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Mar 11, 2026As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
Efficient Neural Video Representation with Temporally Coherent Modulation
May 01, 2025Implicit neural representations (INR) has found successful applications across diverse domains. To employ INR in real-life, it is important to speed up training. In the field of INR for video applications, the state-of-the-art approach employs grid-type parametric encoding and successfully achieves a faster encoding speed in comparison to its predecessors. However, the grid usage, which does not consider the video's dynamic nature, leads to redundant use of trainable parameters. As a result, it has significantly lower parameter efficiency and higher bitrate compared to NeRV-style methods that do not use a parametric encoding. To address the problem, we propose Neural Video representation with Temporally coherent Modulation (NVTM), a novel framework that can capture dynamic characteristics of video. By decomposing the spatio-temporal 3D video data into a set of 2D grids with flow information, NVTM enables learning video representation rapidly and uses parameter efficiently. Our framework enables to process temporally corresponding pixels at once, resulting in the fastest encoding speed for a reasonable video quality, especially when compared to the NeRV-style method, with a speed increase of over 3 times. Also, it remarks an average of 1.54dB/0.019 improvements in PSNR/LPIPS on UVG (Dynamic) (even with 10% fewer parameters) and an average of 1.84dB/0.013 improvements in PSNR/LPIPS on MCL-JCV (Dynamic), compared to previous grid-type works. By expanding this to compression tasks, we demonstrate comparable performance to video compression standards (H.264, HEVC) and recent INR approaches for video compression. Additionally, we perform extensive experiments demonstrating the superior performance of our algorithm across diverse tasks, encompassing super resolution, frame interpolation and video inpainting. Project page is https://sujiikim.github.io/NVTM/.
Multiple Areal Feature Aware Transportation Demand Prediction
Aug 23, 2024



A reliable short-term transportation demand prediction supports the authorities in improving the capability of systems by optimizing schedules, adjusting fleet sizes, and generating new transit networks. A handful of research efforts incorporate one or a few areal features while learning spatio-temporal correlation, to capture similar demand patterns between similar areas. However, urban characteristics are polymorphic, and they need to be understood by multiple areal features such as land use, sociodemographics, and place-of-interest (POI) distribution. In this paper, we propose a novel spatio-temporal multi-feature-aware graph convolutional recurrent network (ST-MFGCRN) that fuses multiple areal features during spatio-temproal understanding. Inside ST-MFGCRN, we devise sentinel attention to calculate the areal similarity matrix by allowing each area to take partial attention if the feature is not useful. We evaluate the proposed model on two real-world transportation datasets, one with our constructed BusDJ dataset and one with benchmark TaxiBJ. Results show that our model outperforms the state-of-the-art baselines up to 7\% on BusDJ and 8\% on TaxiBJ dataset.
ForecastQA: Machine Comprehension of Temporal Text for Answering Forecasting Questions
May 02, 2020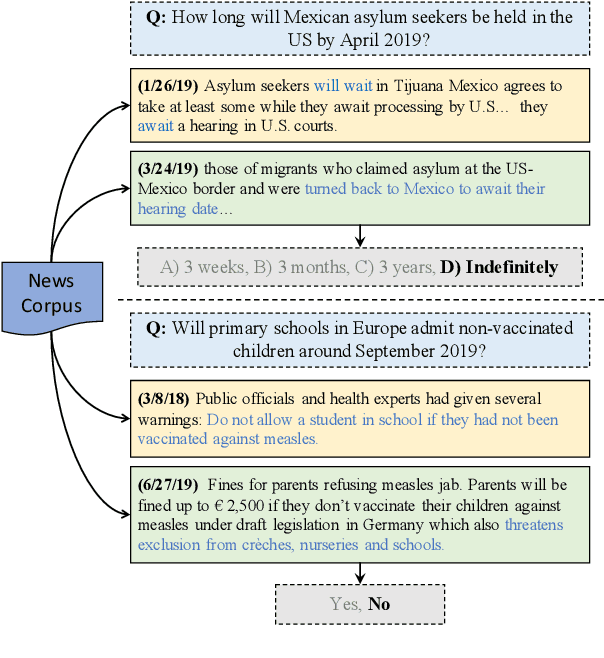
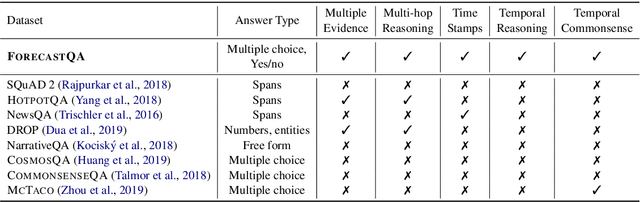

Textual data are often accompanied by time information (e.g., dates in news articles), but the information is easily overlooked on existing question answering datasets. In this paper, we introduce ForecastQA, a new open-domain question answering dataset consisting of 10k questions which requires temporal reasoning. ForecastQA is collected via a crowdsourcing effort based on news articles, where workers were asked to come up with yes-no or multiple-choice questions. We also present baseline models for our dataset, which is based on a pre-trained language model. In our study, our baseline model achieves 61.6% accuracy on the ForecastQA dataset. We expect that our new data will support future research efforts. Our data and code are publicly available at https://inklab.usc.edu/ForecastQA/.