 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpelling Correction
Spelling correction is the process of automatically correcting misspelled words in text data.
Papers and Code
Beyond Detection: Ethical Foundations for Automated Dyslexic Error Attribution
Apr 02, 2026Dyslexic spelling errors exhibit systematic phonological and orthographic patterns that distinguish them from the errors produced by typically developing writers. While this observation has motivated dyslexic-specific spell-checking and assistive writing tools, prior work has focused predominantly on error correction rather than attribution, and has largely neglected the ethical risks. The risk of harmful labelling, covert screening, algorithmic bias, and institutional misuse that automated classification of learners entails requires the development of robust ethical and legal frameworks for research in this area. This paper addresses both gaps. We formulate dyslexic error attribution as a binary classification task. Given a misspelt word and its correct target form, determine whether the error pattern is characteristic of a dyslexic or non-dyslexic writer. We develop a comprehensive feature set capturing orthographic, phonological, and morphological properties of each error, and propose a twin-input neural model evaluated against traditional machine learning baselines under writer-independent conditions. The neural model achieves 93.01% accuracy and an F1-score of 94.01%, with phonetically plausible errors and vowel confusions emerging as the strongest attribution signals. We situate these technical results within an explicit ethics-first framework, analysing fairness across subgroups, the interpretability requirements of educational deployment, and the conditions, consent, transparency, human oversight, and recourse, under which a system could be responsibly used. We provide concrete guidelines for ethical deployment and an open discussion of the systems limitations and misuse potential. Our results demonstrate that dyslexic error attribution is feasible at high accuracy while underscoring that feasibility alone is insufficient for deployment in high-stakes educational contexts.
Efficient Domain Adaptation for Text Line Recognition via Decoupled Language Models
Mar 30, 2026Optical character recognition remains critical infrastructure for document digitization, yet state-of-the-art performance is often restricted to well-resourced institutions by prohibitive computational barriers. End-to-end transformer architectures achieve strong accuracy but demand hundreds of GPU hours for domain adaptation, limiting accessibility for practitioners and digital humanities scholars. We present a modular detection-and-correction framework that achieves near-SOTA accuracy with single-GPU training. Our approach decouples lightweight visual character detection (domain-agnostic) from domain-specific linguistic correction using pretrained sequence models including T5, ByT5, and BART. By training the correctors entirely on synthetic noise, we enable annotation-free domain adaptation without requiring labeled target images. Evaluating across modern clean handwriting, cursive script, and historical documents, we identify a critical "Pareto frontier" in architecture selection: T5-Base excels on modern text with standard vocabulary, whereas ByT5-Base dominates on historical documents by reconstructing archaic spellings at the byte level. Our results demonstrate that this decoupled paradigm matches end-to-end transformer accuracy while reducing compute by approximately 95%, establishing a viable, resource-efficient alternative to monolithic OCR architectures.
CLFEC: A New Task for Unified Linguistic and Factual Error Correction in paragraph-level Chinese Professional Writing
Feb 27, 2026Chinese text correction has traditionally focused on spelling and grammar, while factual error correction is usually treated separately. However, in paragraph-level Chinese professional writing, linguistic (word/grammar/punctuation) and factual errors frequently co-occur and interact, making unified correction both necessary and challenging. This paper introduces CLFEC (Chinese Linguistic & Factual Error Correction), a new task for joint linguistic and factual correction. We construct a mixed, multi-domain Chinese professional writing dataset spanning current affairs, finance, law, and medicine. We then conduct a systematic study of LLM-based correction paradigms, from prompting to retrieval-augmented generation (RAG) and agentic workflows. The analysis reveals practical challenges, including limited generalization of specialized correction models, the need for evidence grounding for factual repair, the difficulty of mixed-error paragraphs, and over-correction on clean inputs. Results further show that handling linguistic and factual Error within the same context outperform decoupled processes, and that agentic workflows can be effective with suitable backbone models. Overall, our dataset and empirical findings provide guidance for building reliable, fully automatic proofreading systems in industrial settings.
The Potential of CoT for Reasoning: A Closer Look at Trace Dynamics
Feb 16, 2026Chain-of-thought (CoT) prompting is a de-facto standard technique to elicit reasoning-like responses from large language models (LLMs), allowing them to spell out individual steps before giving a final answer. While the resemblance to human-like reasoning is undeniable, the driving forces underpinning the success of CoT reasoning still remain largely unclear. In this work, we perform an in-depth analysis of CoT traces originating from competition-level mathematics questions, with the aim of better understanding how, and which parts of CoT actually contribute to the final answer. To this end, we introduce the notion of a potential, quantifying how much a given part of CoT increases the likelihood of a correct completion. Upon examination of reasoning traces through the lens of the potential, we identify surprising patterns including (1) its often strong non-monotonicity (due to reasoning tangents), (2) very sharp but sometimes tough to interpret spikes (reasoning insights and jumps) as well as (3) at times lucky guesses, where the model arrives at the correct answer without providing any relevant justifications before. While some of the behaviours of the potential are readily interpretable and align with human intuition (such as insights and tangents), others remain difficult to understand from a human perspective. To further quantify the reliance of LLMs on reasoning insights, we investigate the notion of CoT transferability, where we measure the potential of a weaker model under the partial CoT from another, stronger model. Indeed aligning with our previous results, we find that as little as 20% of partial CoT can ``unlock'' the performance of the weaker model on problems that were previously unsolvable for it, highlighting that a large part of the mechanics underpinning CoT are transferable.
CEC-Zero: Zero-Supervision Character Error Correction with Self-Generated Rewards
Dec 30, 2025Large-scale Chinese spelling correction (CSC) remains critical for real-world text processing, yet existing LLMs and supervised methods lack robustness to novel errors and rely on costly annotations. We introduce CEC-Zero, a zero-supervision reinforcement learning framework that addresses this by enabling LLMs to correct their own mistakes. CEC-Zero synthesizes errorful inputs from clean text, computes cluster-consensus rewards via semantic similarity and candidate agreement, and optimizes the policy with PPO. It outperforms supervised baselines by 10--13 F$_1$ points and strong LLM fine-tunes by 5--8 points across 9 benchmarks, with theoretical guarantees of unbiased rewards and convergence. CEC-Zero establishes a label-free paradigm for robust, scalable CSC, unlocking LLM potential in noisy text pipelines.
HELIOS: Hierarchical Graph Abstraction for Structure-Aware LLM Decompilation
Jan 21, 2026Large language models (LLMs) have recently been applied to binary decompilation, yet they still treat code as plain text and ignore the graphs that govern program control flow. This limitation often yields syntactically fragile and logically inconsistent output, especially for optimized binaries. This paper presents \textsc{HELIOS}, a framework that reframes LLM-based decompilation as a structured reasoning task. \textsc{HELIOS} summarizes a binary's control flow and function calls into a hierarchical text representation that spells out basic blocks, their successors, and high-level patterns such as loops and conditionals. This representation is supplied to a general-purpose LLM, along with raw decompiler output, optionally combined with a compiler-in-the-loop that returns error messages when the generated code fails to build. On HumanEval-Decompile for \texttt{x86\_64}, \textsc{HELIOS} raises average object file compilability from 45.0\% to 85.2\% for Gemini~2.0 and from 71.4\% to 89.6\% for GPT-4.1~Mini. With compiler feedback, compilability exceeds 94\% and functional correctness improves by up to 5.6 percentage points over text-only prompting. Across six architectures drawn from x86, ARM, and MIPS, \textsc{HELIOS} reduces the spread in functional correctness while keeping syntactic correctness consistently high, all without fine-tuning. These properties make \textsc{HELIOS} a practical building block for reverse engineering workflows in security settings where analysts need recompilable, semantically faithful code across diverse hardware targets.
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025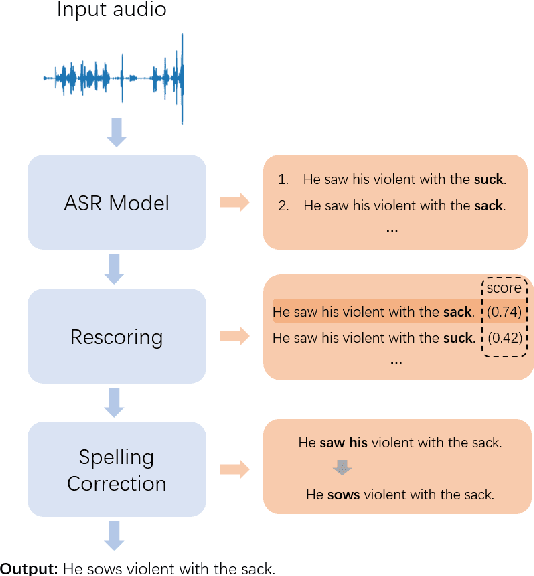



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
OTSNet: A Neurocognitive-Inspired Observation-Thinking-Spelling Pipeline for Scene Text Recognition
Nov 11, 2025Scene Text Recognition (STR) remains challenging due to real-world complexities, where decoupled visual-linguistic optimization in existing frameworks amplifies error propagation through cross-modal misalignment. Visual encoders exhibit attention bias toward background distractors, while decoders suffer from spatial misalignment when parsing geometrically deformed text-collectively degrading recognition accuracy for irregular patterns. Inspired by the hierarchical cognitive processes in human visual perception, we propose OTSNet, a novel three-stage network embodying a neurocognitive-inspired Observation-Thinking-Spelling pipeline for unified STR modeling. The architecture comprises three core components: (1) a Dual Attention Macaron Encoder (DAME) that refines visual features through differential attention maps to suppress irrelevant regions and enhance discriminative focus; (2) a Position-Aware Module (PAM) and Semantic Quantizer (SQ) that jointly integrate spatial context with glyph-level semantic abstraction via adaptive sampling; and (3) a Multi-Modal Collaborative Verifier (MMCV) that enforces self-correction through cross-modal fusion of visual, semantic, and character-level features. Extensive experiments demonstrate that OTSNet achieves state-of-the-art performance, attaining 83.5% average accuracy on the challenging Union14M-L benchmark and 79.1% on the heavily occluded OST dataset-establishing new records across 9 out of 14 evaluation scenarios.
TextPixs: Glyph-Conditioned Diffusion with Character-Aware Attention and OCR-Guided Supervision
Jul 08, 2025The modern text-to-image diffusion models boom has opened a new era in digital content production as it has proven the previously unseen ability to produce photorealistic and stylistically diverse imagery based on the semantics of natural-language descriptions. However, the consistent disadvantage of these models is that they cannot generate readable, meaningful, and correctly spelled text in generated images, which significantly limits the use of practical purposes like advertising, learning, and creative design. This paper introduces a new framework, namely Glyph-Conditioned Diffusion with Character-Aware Attention (GCDA), using which a typical diffusion backbone is extended by three well-designed modules. To begin with, the model has a dual-stream text encoder that encodes both semantic contextual information and explicit glyph representations, resulting in a character-aware representation of the input text that is rich in nature. Second, an attention mechanism that is aware of the character is proposed with a new attention segregation loss that aims to limit the attention distribution of each character independently in order to avoid distortion artifacts. Lastly, GCDA has an OCR-in-the-loop fine-tuning phase, where a full text perceptual loss, directly optimises models to be legible and accurately spell. Large scale experiments to benchmark datasets, such as MARIO-10M and T2I-CompBench, reveal that GCDA sets a new state-of-the-art on all metrics, with better character based metrics on text rendering (Character Error Rate: 0.08 vs 0.21 for the previous best; Word Error Rate: 0.15 vs 0.25), human perception, and comparable image synthesis quality on high-fidelity (FID: 14.3).
Leveraging LLM-Assisted Query Understanding for Live Retrieval-Augmented Generation
Jun 26, 2025


Real-world live retrieval-augmented generation (RAG) systems face significant challenges when processing user queries that are often noisy, ambiguous, and contain multiple intents. While RAG enhances large language models (LLMs) with external knowledge, current systems typically struggle with such complex inputs, as they are often trained or evaluated on cleaner data. This paper introduces Omni-RAG, a novel framework designed to improve the robustness and effectiveness of RAG systems in live, open-domain settings. Omni-RAG employs LLM-assisted query understanding to preprocess user inputs through three key modules: (1) Deep Query Understanding and Decomposition, which utilizes LLMs with tailored prompts to denoise queries (e.g., correcting spelling errors) and decompose multi-intent queries into structured sub-queries; (2) Intent-Aware Knowledge Retrieval, which performs retrieval for each sub-query from a corpus (i.e., FineWeb using OpenSearch) and aggregates the results; and (3) Reranking and Generation, where a reranker (i.e., BGE) refines document selection before a final response is generated by an LLM (i.e., Falcon-10B) using a chain-of-thought prompt. Omni-RAG aims to bridge the gap between current RAG capabilities and the demands of real-world applications, such as those highlighted by the SIGIR 2025 LiveRAG Challenge, by robustly handling complex and noisy queries.