 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlane Instance Segmentation
Papers and Code
RoofSeg: An edge-aware transformer-based network for end-to-end roof plane segmentation
Aug 26, 2025Roof plane segmentation is one of the key procedures for reconstructing three-dimensional (3D) building models at levels of detail (LoD) 2 and 3 from airborne light detection and ranging (LiDAR) point clouds. The majority of current approaches for roof plane segmentation rely on the manually designed or learned features followed by some specifically designed geometric clustering strategies. Because the learned features are more powerful than the manually designed features, the deep learning-based approaches usually perform better than the traditional approaches. However, the current deep learning-based approaches have three unsolved problems. The first is that most of them are not truly end-to-end, the plane segmentation results may be not optimal. The second is that the point feature discriminability near the edges is relatively low, leading to inaccurate planar edges. The third is that the planar geometric characteristics are not sufficiently considered to constrain the network training. To solve these issues, a novel edge-aware transformer-based network, named RoofSeg, is developed for segmenting roof planes from LiDAR point clouds in a truly end-to-end manner. In the RoofSeg, we leverage a transformer encoder-decoder-based framework to hierarchically predict the plane instance masks with the use of a set of learnable plane queries. To further improve the segmentation accuracy of edge regions, we also design an Edge-Aware Mask Module (EAMM) that sufficiently incorporates planar geometric prior of edges to enhance its discriminability for plane instance mask refinement. In addition, we propose an adaptive weighting strategy in the mask loss to reduce the influence of misclassified points, and also propose a new plane geometric loss to constrain the network training.
SPPSFormer: High-quality Superpoint-based Transformer for Roof Plane Instance Segmentation from Point Clouds
May 30, 2025



Transformers have been seldom employed in point cloud roof plane instance segmentation, which is the focus of this study, and existing superpoint Transformers suffer from limited performance due to the use of low-quality superpoints. To address this challenge, we establish two criteria that high-quality superpoints for Transformers should satisfy and introduce a corresponding two-stage superpoint generation process. The superpoints generated by our method not only have accurate boundaries, but also exhibit consistent geometric sizes and shapes, both of which greatly benefit the feature learning of superpoint Transformers. To compensate for the limitations of deep learning features when the training set size is limited, we incorporate multidimensional handcrafted features into the model. Additionally, we design a decoder that combines a Kolmogorov-Arnold Network with a Transformer module to improve instance prediction and mask extraction. Finally, our network's predictions are refined using traditional algorithm-based postprocessing. For evaluation, we annotated a real-world dataset and corrected annotation errors in the existing RoofN3D dataset. Experimental results show that our method achieves state-of-the-art performance on our dataset, as well as both the original and reannotated RoofN3D datasets. Moreover, our model is not sensitive to plane boundary annotations during training, significantly reducing the annotation burden. Through comprehensive experiments, we also identified key factors influencing roof plane segmentation performance: in addition to roof types, variations in point cloud density, density uniformity, and 3D point precision have a considerable impact. These findings underscore the importance of incorporating data augmentation strategies that account for point cloud quality to enhance model robustness under diverse and challenging conditions.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
JanusNet: Hierarchical Slice-Block Shuffle and Displacement for Semi-Supervised 3D Multi-Organ Segmentation
Aug 06, 2025



Limited by the scarcity of training samples and annotations, weakly supervised medical image segmentation often employs data augmentation to increase data diversity, while randomly mixing volumetric blocks has demonstrated strong performance. However, this approach disrupts the inherent anatomical continuity of 3D medical images along orthogonal axes, leading to severe structural inconsistencies and insufficient training in challenging regions, such as small-sized organs, etc. To better comply with and utilize human anatomical information, we propose JanusNet}, a data augmentation framework for 3D medical data that globally models anatomical continuity while locally focusing on hard-to-segment regions. Specifically, our Slice-Block Shuffle step performs aligned shuffling of same-index slice blocks across volumes along a random axis, while preserving the anatomical context on planes perpendicular to the perturbation axis. Concurrently, the Confidence-Guided Displacement step uses prediction reliability to replace blocks within each slice, amplifying signals from difficult areas. This dual-stage, axis-aligned framework is plug-and-play, requiring minimal code changes for most teacher-student schemes. Extensive experiments on the Synapse and AMOS datasets demonstrate that JanusNet significantly surpasses state-of-the-art methods, achieving, for instance, a 4% DSC gain on the Synapse dataset with only 20% labeled data.
PlaneSAM: Multimodal Plane Instance Segmentation Using the Segment Anything Model
Oct 21, 2024
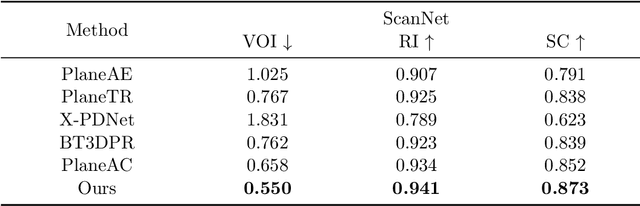


Plane instance segmentation from RGB-D data is a crucial research topic for many downstream tasks. However, most existing deep-learning-based methods utilize only information within the RGB bands, neglecting the important role of the depth band in plane instance segmentation. Based on EfficientSAM, a fast version of SAM, we propose a plane instance segmentation network called PlaneSAM, which can fully integrate the information of the RGB bands (spectral bands) and the D band (geometric band), thereby improving the effectiveness of plane instance segmentation in a multimodal manner. Specifically, we use a dual-complexity backbone, with primarily the simpler branch learning D-band features and primarily the more complex branch learning RGB-band features. Consequently, the backbone can effectively learn D-band feature representations even when D-band training data is limited in scale, retain the powerful RGB-band feature representations of EfficientSAM, and allow the original backbone branch to be fine-tuned for the current task. To enhance the adaptability of our PlaneSAM to the RGB-D domain, we pretrain our dual-complexity backbone using the segment anything task on large-scale RGB-D data through a self-supervised pretraining strategy based on imperfect pseudo-labels. To support the segmentation of large planes, we optimize the loss function combination ratio of EfficientSAM. In addition, Faster R-CNN is used as a plane detector, and its predicted bounding boxes are fed into our dual-complexity network as prompts, thereby enabling fully automatic plane instance segmentation. Experimental results show that the proposed PlaneSAM sets a new SOTA performance on the ScanNet dataset, and outperforms previous SOTA approaches in zero-shot transfer on the 2D-3D-S, Matterport3D, and ICL-NUIM RGB-D datasets, while only incurring a 10% increase in computational overhead compared to EfficientSAM.
You Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
Planar Gaussian Splatting
Dec 02, 2024



This paper presents Planar Gaussian Splatting (PGS), a novel neural rendering approach to learn the 3D geometry and parse the 3D planes of a scene, directly from multiple RGB images. The PGS leverages Gaussian primitives to model the scene and employ a hierarchical Gaussian mixture approach to group them. Similar Gaussians are progressively merged probabilistically in the tree-structured Gaussian mixtures to identify distinct 3D plane instances and form the overall 3D scene geometry. In order to enable the grouping, the Gaussian primitives contain additional parameters, such as plane descriptors derived by lifting 2D masks from a general 2D segmentation model and surface normals. Experiments show that the proposed PGS achieves state-of-the-art performance in 3D planar reconstruction without requiring either 3D plane labels or depth supervision. In contrast to existing supervised methods that have limited generalizability and struggle under domain shift, PGS maintains its performance across datasets thanks to its neural rendering and scene-specific optimization mechanism, while also being significantly faster than existing optimization-based approaches.
RETR: Multi-View Radar Detection Transformer for Indoor Perception
Nov 15, 2024



Indoor radar perception has seen rising interest due to affordable costs driven by emerging automotive imaging radar developments and the benefits of reduced privacy concerns and reliability under hazardous conditions (e.g., fire and smoke). However, existing radar perception pipelines fail to account for distinctive characteristics of the multi-view radar setting. In this paper, we propose Radar dEtection TRansformer (RETR), an extension of the popular DETR architecture, tailored for multi-view radar perception. RETR inherits the advantages of DETR, eliminating the need for hand-crafted components for object detection and segmentation in the image plane. More importantly, RETR incorporates carefully designed modifications such as 1) depth-prioritized feature similarity via a tunable positional encoding (TPE); 2) a tri-plane loss from both radar and camera coordinates; and 3) a learnable radar-to-camera transformation via reparameterization, to account for the unique multi-view radar setting. Evaluated on two indoor radar perception datasets, our approach outperforms existing state-of-the-art methods by a margin of 15.38+ AP for object detection and 11.77+ IoU for instance segmentation, respectively.
Training-free CryoET Tomogram Segmentation
Jul 08, 2024



Cryogenic Electron Tomography (CryoET) is a useful imaging technology in structural biology that is hindered by its need for manual annotations, especially in particle picking. Recent works have endeavored to remedy this issue with few-shot learning or contrastive learning techniques. However, supervised training is still inevitable for them. We instead choose to leverage the power of existing 2D foundation models and present a novel, training-free framework, CryoSAM. In addition to prompt-based single-particle instance segmentation, our approach can automatically search for similar features, facilitating full tomogram semantic segmentation with only one prompt. CryoSAM is composed of two major parts: 1) a prompt-based 3D segmentation system that uses prompts to complete single-particle instance segmentation recursively with Cross-Plane Self-Prompting, and 2) a Hierarchical Feature Matching mechanism that efficiently matches relevant features with extracted tomogram features. They collaborate to enable the segmentation of all particles of one category with just one particle-specific prompt. Our experiments show that CryoSAM outperforms existing works by a significant margin and requires even fewer annotations in particle picking. Further visualizations demonstrate its ability when dealing with full tomogram segmentation for various subcellular structures. Our code is available at: https://github.com/xulabs/aitom
Multi-Object RANSAC: Efficient Plane Clustering Method in a Clutter
Mar 19, 2024



In this paper, we propose a novel method for plane clustering specialized in cluttered scenes using an RGB-D camera and validate its effectiveness through robot grasping experiments. Unlike existing methods, which focus on large-scale indoor structures, our approach -- Multi-Object RANSAC emphasizes cluttered environments that contain a wide range of objects with different scales. It enhances plane segmentation by generating subplanes in Deep Plane Clustering (DPC) module, which are then merged with the final planes by post-processing. DPC rearranges the point cloud by voting layers to make subplane clusters, trained in a self-supervised manner using pseudo-labels generated from RANSAC. Multi-Object RANSAC demonstrates superior plane instance segmentation performances over other recent RANSAC applications. We conducted an experiment on robot suction-based grasping, comparing our method with vision-based grasping network and RANSAC applications. The results from this real-world scenario showed its remarkable performance surpassing the baseline methods, highlighting its potential for advanced scene understanding and manipulation.