 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Editing Request Dataset
Papers and Code
ChatUMM: Robust Context Tracking for Conversational Interleaved Generation
Feb 06, 2026Unified multimodal models (UMMs) have achieved remarkable progress yet remain constrained by a single-turn interaction paradigm, effectively functioning as solvers for independent requests rather than assistants in continuous dialogue. To bridge this gap, we present ChatUMM. As a conversational unified model, it excels at robust context tracking to sustain interleaved multimodal generation. ChatUMM derives its capabilities from two key innovations: an interleaved multi-turn training strategy that models serialized text-image streams as a continuous conversational flow, and a systematic conversational data synthesis pipeline. This pipeline transforms a diverse set of standard single-turn datasets into fluid dialogues through three progressive stages: constructing basic stateful dialogues, enforcing long-range dependency resolution via ``distractor'' turns with history-dependent query rewriting, and synthesizing naturally interleaved multimodal responses. Extensive evaluations demonstrate that ChatUMM achieves state-of-the-art performance among open-source unified models on visual understanding and instruction-guided editing benchmarks, while maintaining competitive fidelity in text-to-image generation. Notably, ChatUMM exhibits superior robustness in complex multi-turn scenarios, ensuring fluid, context-aware dialogues.
Aesthetic Alignment Risks Assimilation: How Image Generation and Reward Models Reinforce Beauty Bias and Ideological "Censorship"
Dec 09, 2025Over-aligning image generation models to a generalized aesthetic preference conflicts with user intent, particularly when ``anti-aesthetic" outputs are requested for artistic or critical purposes. This adherence prioritizes developer-centered values, compromising user autonomy and aesthetic pluralism. We test this bias by constructing a wide-spectrum aesthetics dataset and evaluating state-of-the-art generation and reward models. We find that aesthetic-aligned generation models frequently default to conventionally beautiful outputs, failing to respect instructions for low-quality or negative imagery. Crucially, reward models penalize anti-aesthetic images even when they perfectly match the explicit user prompt. We confirm this systemic bias through image-to-image editing and evaluation against real abstract artworks.
Affective Image Editing: Shaping Emotional Factors via Text Descriptions
May 24, 2025In daily life, images as common affective stimuli have widespread applications. Despite significant progress in text-driven image editing, there is limited work focusing on understanding users' emotional requests. In this paper, we introduce AIEdiT for Affective Image Editing using Text descriptions, which evokes specific emotions by adaptively shaping multiple emotional factors across the entire images. To represent universal emotional priors, we build the continuous emotional spectrum and extract nuanced emotional requests. To manipulate emotional factors, we design the emotional mapper to translate visually-abstract emotional requests to visually-concrete semantic representations. To ensure that editing results evoke specific emotions, we introduce an MLLM to supervise the model training. During inference, we strategically distort visual elements and subsequently shape corresponding emotional factors to edit images according to users' instructions. Additionally, we introduce a large-scale dataset that includes the emotion-aligned text and image pair set for training and evaluation. Extensive experiments demonstrate that AIEdiT achieves superior performance, effectively reflecting users' emotional requests.
R-Genie: Reasoning-Guided Generative Image Editing
May 23, 2025While recent advances in image editing have enabled impressive visual synthesis capabilities, current methods remain constrained by explicit textual instructions and limited editing operations, lacking deep comprehension of implicit user intentions and contextual reasoning. In this work, we introduce a new image editing paradigm: reasoning-guided generative editing, which synthesizes images based on complex, multi-faceted textual queries accepting world knowledge and intention inference. To facilitate this task, we first construct a comprehensive dataset featuring over 1,000 image-instruction-edit triples that incorporate rich reasoning contexts and real-world knowledge. We then propose R-Genie: a reasoning-guided generative image editor, which synergizes the generation power of diffusion models with advanced reasoning capabilities of multimodal large language models. R-Genie incorporates a reasoning-attention mechanism to bridge linguistic understanding with visual synthesis, enabling it to handle intricate editing requests involving abstract user intentions and contextual reasoning relations. Extensive experimental results validate that R-Genie can equip diffusion models with advanced reasoning-based editing capabilities, unlocking new potentials for intelligent image synthesis.
REALEDIT: Reddit Edits As a Large-scale Empirical Dataset for Image Transformations
Feb 05, 2025



Existing image editing models struggle to meet real-world demands. Despite excelling in academic benchmarks, they have yet to be widely adopted for real user needs. Datasets that power these models use artificial edits, lacking the scale and ecological validity necessary to address the true diversity of user requests. We introduce REALEDIT, a large-scale image editing dataset with authentic user requests and human-made edits sourced from Reddit. REALEDIT includes a test set of 9300 examples to evaluate models on real user requests. Our results show that existing models fall short on these tasks, highlighting the need for realistic training data. To address this, we introduce 48K training examples and train our REALEDIT model, achieving substantial gains - outperforming competitors by up to 165 Elo points in human judgment and 92 percent relative improvement on the automated VIEScore metric. We deploy our model on Reddit, testing it on new requests, and receive positive feedback. Beyond image editing, we explore REALEDIT's potential in detecting edited images by partnering with a deepfake detection non-profit. Finetuning their model on REALEDIT data improves its F1-score by 14 percentage points, underscoring the dataset's value for broad applications.
PlotEdit: Natural Language-Driven Accessible Chart Editing in PDFs via Multimodal LLM Agents
Jan 20, 2025

Chart visualizations, while essential for data interpretation and communication, are predominantly accessible only as images in PDFs, lacking source data tables and stylistic information. To enable effective editing of charts in PDFs or digital scans, we present PlotEdit, a novel multi-agent framework for natural language-driven end-to-end chart image editing via self-reflective LLM agents. PlotEdit orchestrates five LLM agents: (1) Chart2Table for data table extraction, (2) Chart2Vision for style attribute identification, (3) Chart2Code for retrieving rendering code, (4) Instruction Decomposition Agent for parsing user requests into executable steps, and (5) Multimodal Editing Agent for implementing nuanced chart component modifications - all coordinated through multimodal feedback to maintain visual fidelity. PlotEdit outperforms existing baselines on the ChartCraft dataset across style, layout, format, and data-centric edits, enhancing accessibility for visually challenged users and improving novice productivity.
Label Critic: Design Data Before Models
Nov 05, 2024

As medical datasets rapidly expand, creating detailed annotations of different body structures becomes increasingly expensive and time-consuming. We consider that requesting radiologists to create detailed annotations is unnecessarily burdensome and that pre-existing AI models can largely automate this process. Following the spirit don't use a sledgehammer on a nut, we find that, rather than creating annotations from scratch, radiologists only have to review and edit errors if the Best-AI Labels have mistakes. To obtain the Best-AI Labels among multiple AI Labels, we developed an automatic tool, called Label Critic, that can assess label quality through tireless pairwise comparisons. Extensive experiments demonstrate that, when incorporated with our developed Image-Prompt pairs, pre-existing Large Vision-Language Models (LVLM), trained on natural images and texts, achieve 96.5% accuracy when choosing the best label in a pair-wise comparison, without extra fine-tuning. By transforming the manual annotation task (30-60 min/scan) into an automatic comparison task (15 sec/scan), we effectively reduce the manual efforts required from radiologists by an order of magnitude. When the Best-AI Labels are sufficiently accurate (81% depending on body structures), they will be directly adopted as the gold-standard annotations for the dataset, with lower-quality AI Labels automatically discarded. Label Critic can also check the label quality of a single AI Label with 71.8% accuracy when no alternatives are available for comparison, prompting radiologists to review and edit if the estimated quality is low (19% depending on body structures).
DocEdit-v2: Document Structure Editing Via Multimodal LLM Grounding
Oct 21, 2024



Document structure editing involves manipulating localized textual, visual, and layout components in document images based on the user's requests. Past works have shown that multimodal grounding of user requests in the document image and identifying the accurate structural components and their associated attributes remain key challenges for this task. To address these, we introduce the DocEdit-v2, a novel framework that performs end-to-end document editing by leveraging Large Multimodal Models (LMMs). It consists of three novel components: (1) Doc2Command, which simultaneously localizes edit regions of interest (RoI) and disambiguates user edit requests into edit commands; (2) LLM-based Command Reformulation prompting to tailor edit commands originally intended for specialized software into edit instructions suitable for generalist LMMs. (3) Moreover, DocEdit-v2 processes these outputs via Large Multimodal Models like GPT-4V and Gemini, to parse the document layout, execute edits on grounded Region of Interest (RoI), and generate the edited document image. Extensive experiments on the DocEdit dataset show that DocEdit-v2 significantly outperforms strong baselines on edit command generation (2-33%), RoI bounding box detection (12-31%), and overall document editing (1-12\%) tasks.
Specify and Edit: Overcoming Ambiguity in Text-Based Image Editing
Jul 29, 2024



Text-based editing diffusion models exhibit limited performance when the user's input instruction is ambiguous. To solve this problem, we propose $\textit{Specify ANd Edit}$ (SANE), a zero-shot inference pipeline for diffusion-based editing systems. We use a large language model (LLM) to decompose the input instruction into specific instructions, i.e. well-defined interventions to apply to the input image to satisfy the user's request. We benefit from the LLM-derived instructions along the original one, thanks to a novel denoising guidance strategy specifically designed for the task. Our experiments with three baselines and on two datasets demonstrate the benefits of SANE in all setups. Moreover, our pipeline improves the interpretability of editing models, and boosts the output diversity. We also demonstrate that our approach can be applied to any edit, whether ambiguous or not. Our code is public at https://github.com/fabvio/SANE.
CLIP4IDC: CLIP for Image Difference Captioning
Jun 01, 2022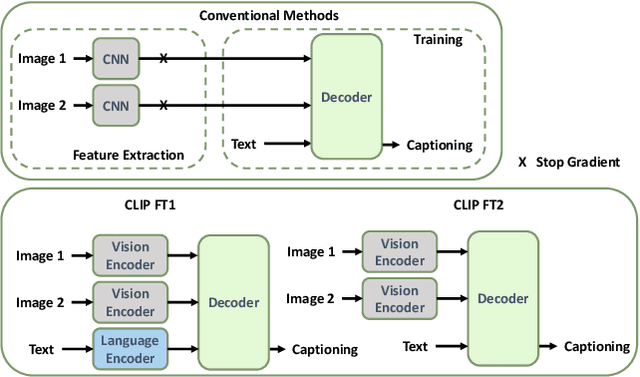
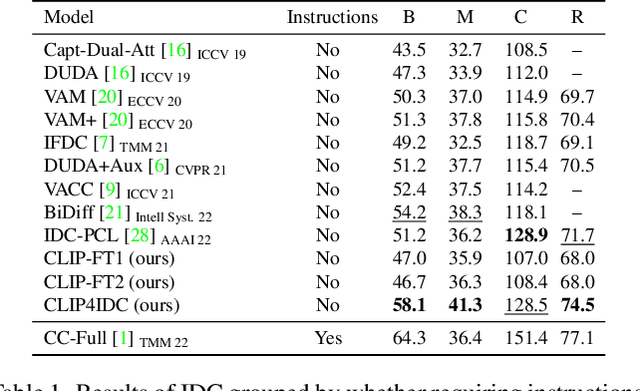
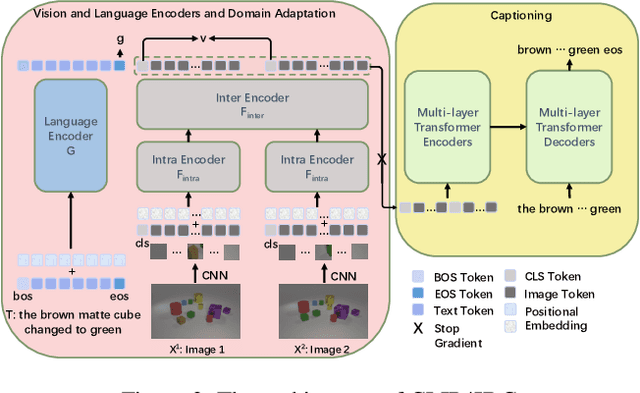
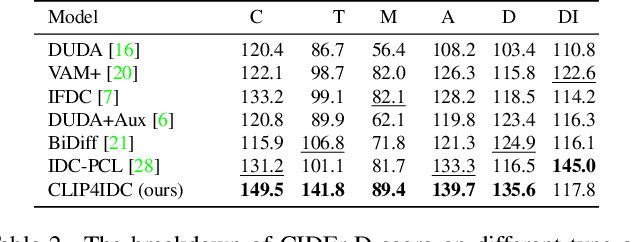
Image Difference Captioning (IDC) aims at generating sentences to describe the differences between two similar-looking images. The conventional approaches learn captioning models on the offline-extracted visual features and the learning can not be propagated back to the fixed feature extractors pre-trained on image classification datasets. Accordingly, potential improvements can be made by fine-tuning the visual features for: 1) narrowing the gap when generalizing the visual extractor trained on image classification to IDC, and 2) relating the extracted visual features to the descriptions of the corresponding changes. We thus propose CLIP4IDC to transfer a CLIP model for the IDC task to attain these improvements. Different from directly fine-tuning CLIP to generate sentences, a task-specific domain adaptation is used to improve the extracted features. Specifically, the target is to train CLIP on raw pixels to relate the image pairs to the described changes. Afterwards, a vanilla Transformer is trained for IDC on the features extracted by the vision encoder of CLIP. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC. Our code and models will be released at https://github.com/sushizixin/CLIP4IDC.